Graph RAG: 知识图谱结合 LLM 的检索增强
本文为大家揭示 NebulaGraph 率先提出的 Graph RAG 方法,这种结合知识图谱、图数据库作为大模型结合私有知识系统的最新技术栈,是 LLM+ 系列的第三篇,加上之前的图上下文学习、Text2Cypher 这两篇文章,目前 NebulaGraph + LLM 相关的文章一共有 3 篇。
Graph RAG
在第一篇关于上下文学习的博客中我们介绍过,RAG(Retrieval Argumented Generation)这种基于特定任务/问题的文档检索范式中,我们通常先收集必要的上下文,然后利用具有认知能力的机器学习模型进行上下文学习(in-context learning),来合成任务的答案。
借助 LLM 这个只需要”说话“就可以灵活处理复杂问题的感知层,只需要两步,就能搭建一个基于私有知识的智能应用:
- 利用各种搜索方式(比如 Embedding 与向量数据库)从给定的文档中检索相关知识。
- 利用 LLM 理解并智能地合成答案。
而这篇博客中,我们结合最新的探索进展和思考,尝试把 Graph RAG 和其他方法进行比较,说得更透一点。此外,我们决定开始用 Graph RAG 这个叫法来描述它。
实际上,Graph RAG,是最先由我和 Jerry Liu 的直播研讨会讨论和相关的讨论的 Twitter Thread 中提到的,差不多的内容我在 NebulaGraph 社区直播 中也用中文介绍过。
在 RAG 中知识图谱的价值
这部分内容我们在第一篇文章中阐述过,比如一个查询:“告诉我所有关于苹果和乔布斯的事”,基于乔布斯自传这本书进行问答,而这个问题涉及到的上下文分布在自传这本书的 30 页(分块)的时候,传统的“分割数据,Embedding 再向量搜索”方法在多个文档块里用 TOP-K 去搜索的方法很难得到这种分散,细粒的完整信息。而且,这种方法还很容易遗漏互相关联的文档块,从而导致信息检索不完整。
除此之外,在之后一次技术会议中,我有幸和 leadscloud.com 的徐旭讨论之后(他们因为有知识图谱的技术背景,也做了和我们类似的探索和尝试!),让我意识到知识图谱可以减少基于嵌入的语义搜索所导致的不准确性。徐旭给出的一个有趣的例子是“保温大棚”与“保温杯”,尽管在语义上两者是存在相关性的,但在大多数场景下,这种通用语义(Embedding)下的相关性常常是我们不希望产生的,进而作为错误的上下文而引入“幻觉”。
这时候,保有领域知识的知识图谱则是非常直接可以缓解、消除这种幻觉的手段。
用 NebulaGraph 实现 Graph RAG
一个简单的 Graph RAG 可以如下去简单实现:
- 使用 LLM(或其他)模型从问题中提取关键实体
- 根据这些实体检索子图,深入到一定的深度(例如,2)
- 利用获得的上下文利用 LLM 产生答案。
对应的伪代码可能是这样:
# 伪代码
def _get_key_entities(query_str, llm=None ,with_llm=True):
...
return _expand_synonyms(entities)
def _retrieve_subgraph_context(entities, depth=2, limit=30):
...
return nebulagraph_store.get_relations(entities, depth, limit)
def _synthesize_answer(query_str, graph_rag_context, llm):
return llm.predict(PROMPT_SYNTHESIZE_AND_REFINE, query_str, graph_rag_context)
def simple_graph_rag(query_str, nebulagraph_store, llm):
entities = _get_key_entities(query_str, llm)
graph_rag_context = _retrieve_subgraph_context(entities)
return _synthesize_answer(
query_str, graph_rag_context, llm)
然而,有了像 LlamaIndex 这样方便的 LLM 编排工具,开发者可以专注于 LLM 的编排逻辑和 pipeline 设计,而不用亲自处理很多细节的抽象与实现。
所以,用 LlamaIndex,我们可以轻松搭建 Graph RAG,甚至整合更复杂的 RAG 逻辑,比如 Graph + Vector RAG。
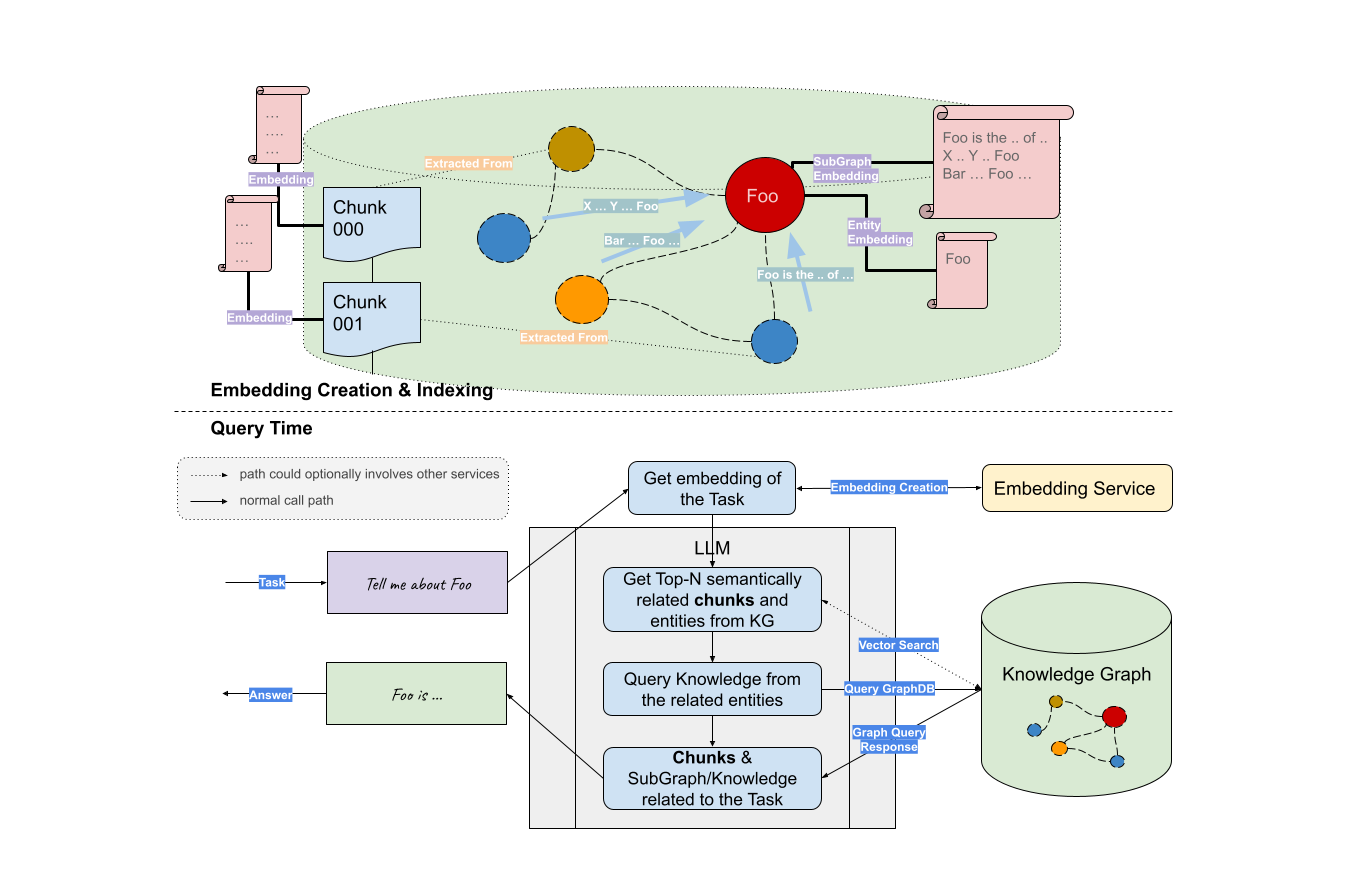
在 LlamaIndex 中,我们有两种方法实现 Graph RAG:
KnowledgeGraphIndex只用来对任何私有数据从零构建知识图谱(基于 LLM 或者其他语言模型),再 4 行代码进行 Graph RAG:
graph_store = NebulaGraphStore(
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
# Build KG
kg_index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
max_triplets_per_chunk=10,
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
kg_query_engine = kg_index.as_query_engine()
KnowledgeGraphRAGQueryEngine则可以在任何已经存在的知识图谱上进行 Graph RAG。不过,我还没有完成这个 PR。
graph_store = NebulaGraphStore(
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
graph_rag_query_engine = KnowledgeGraphRAGQueryEngine(
storage_context=storage_context,
)
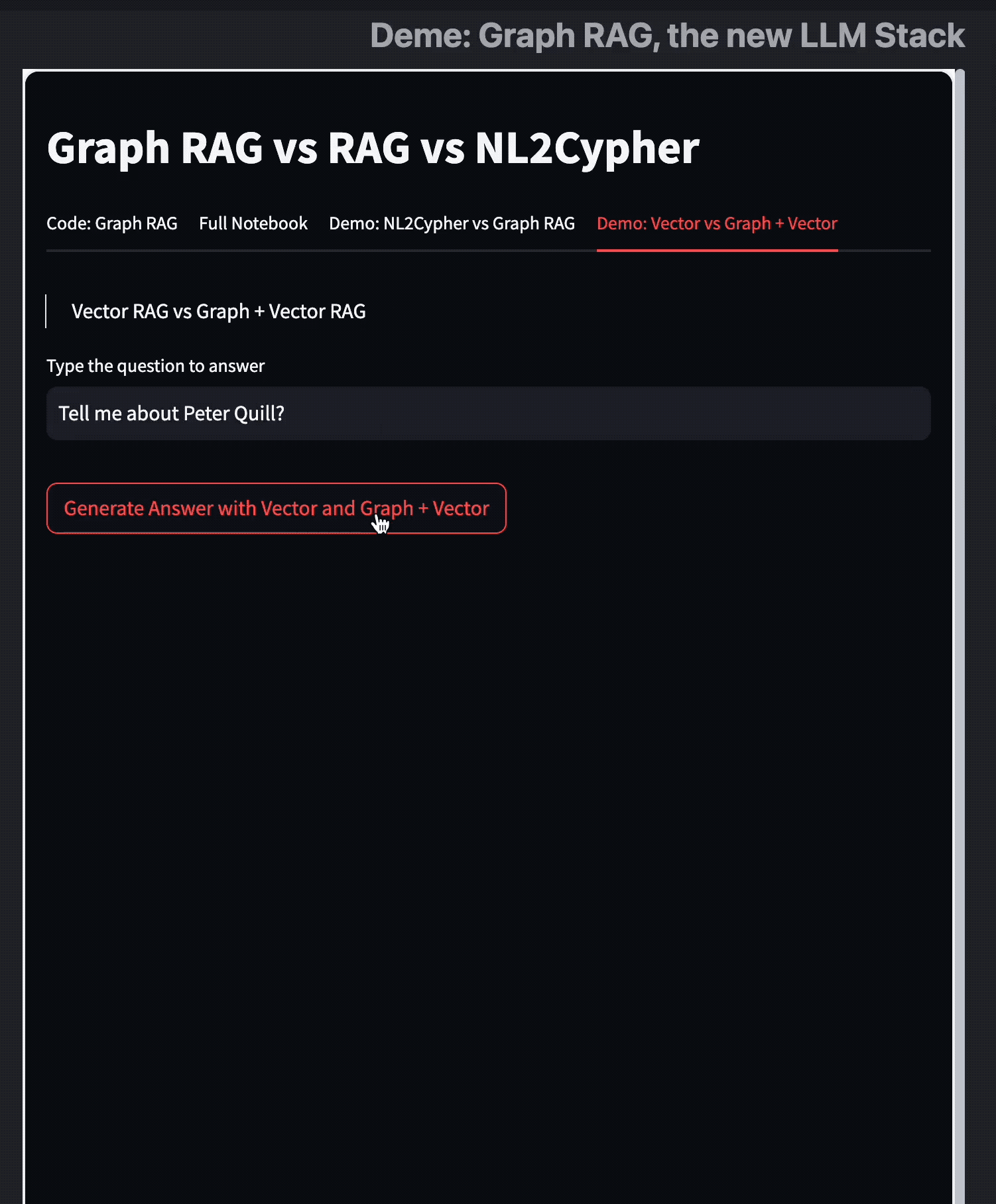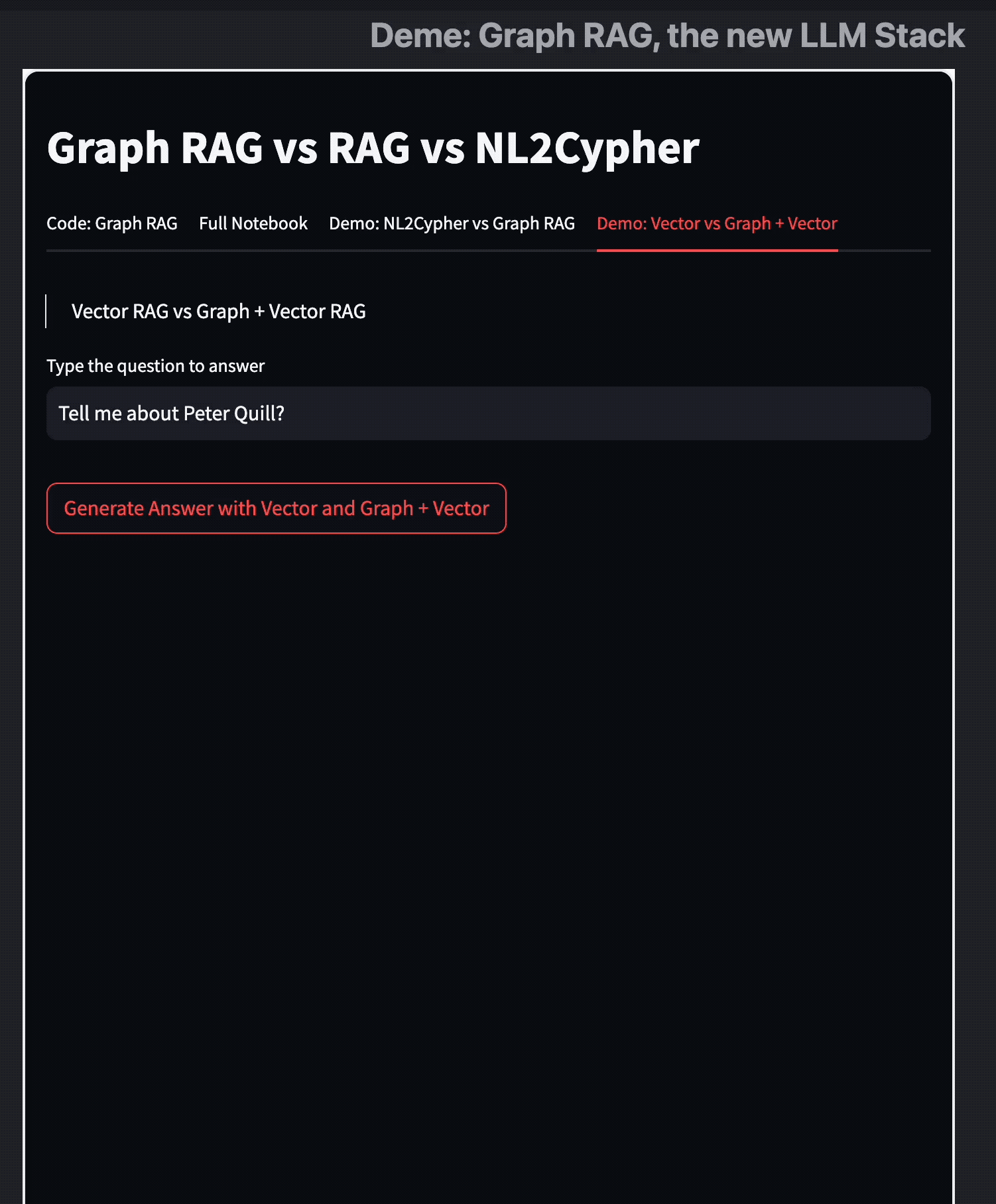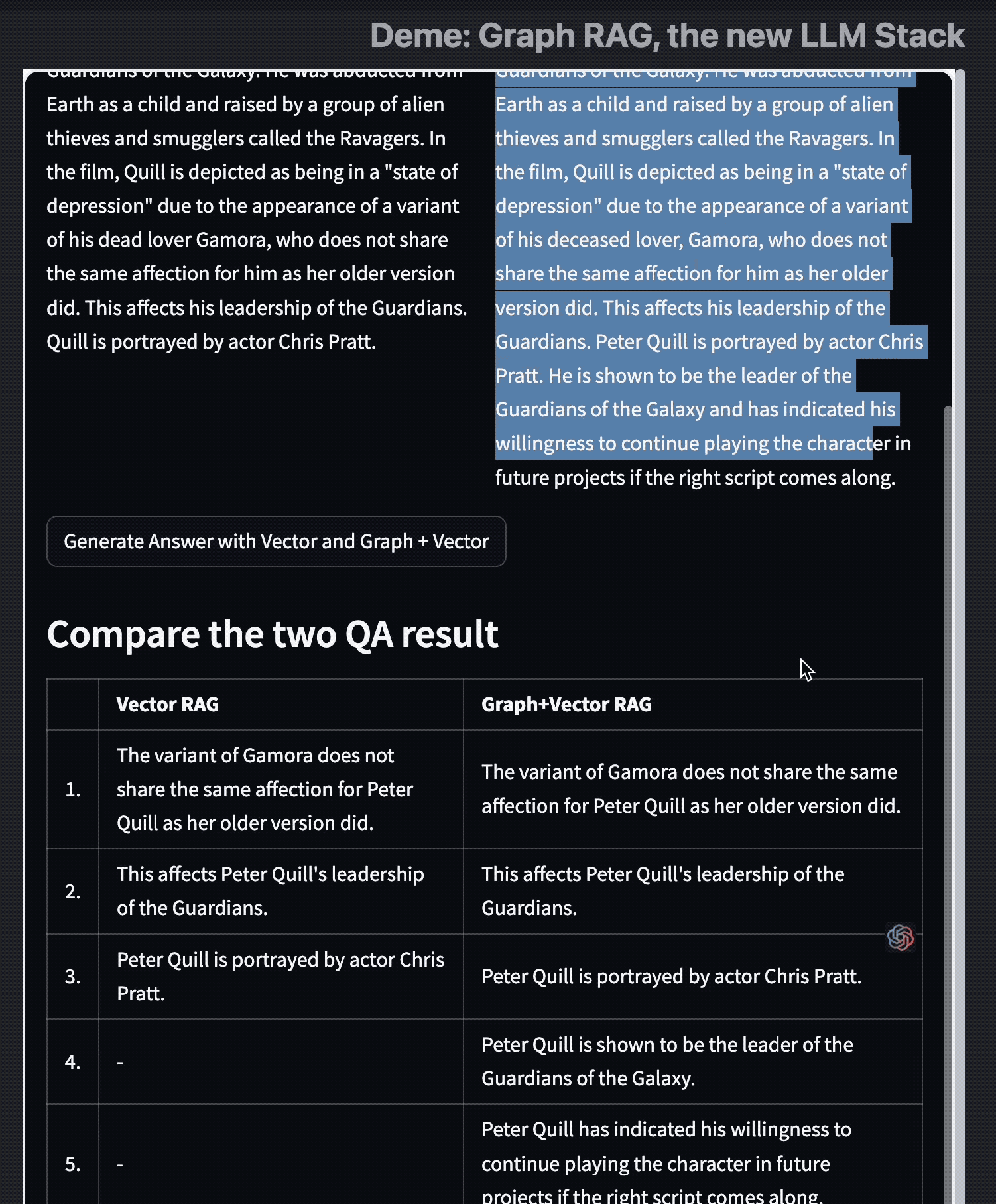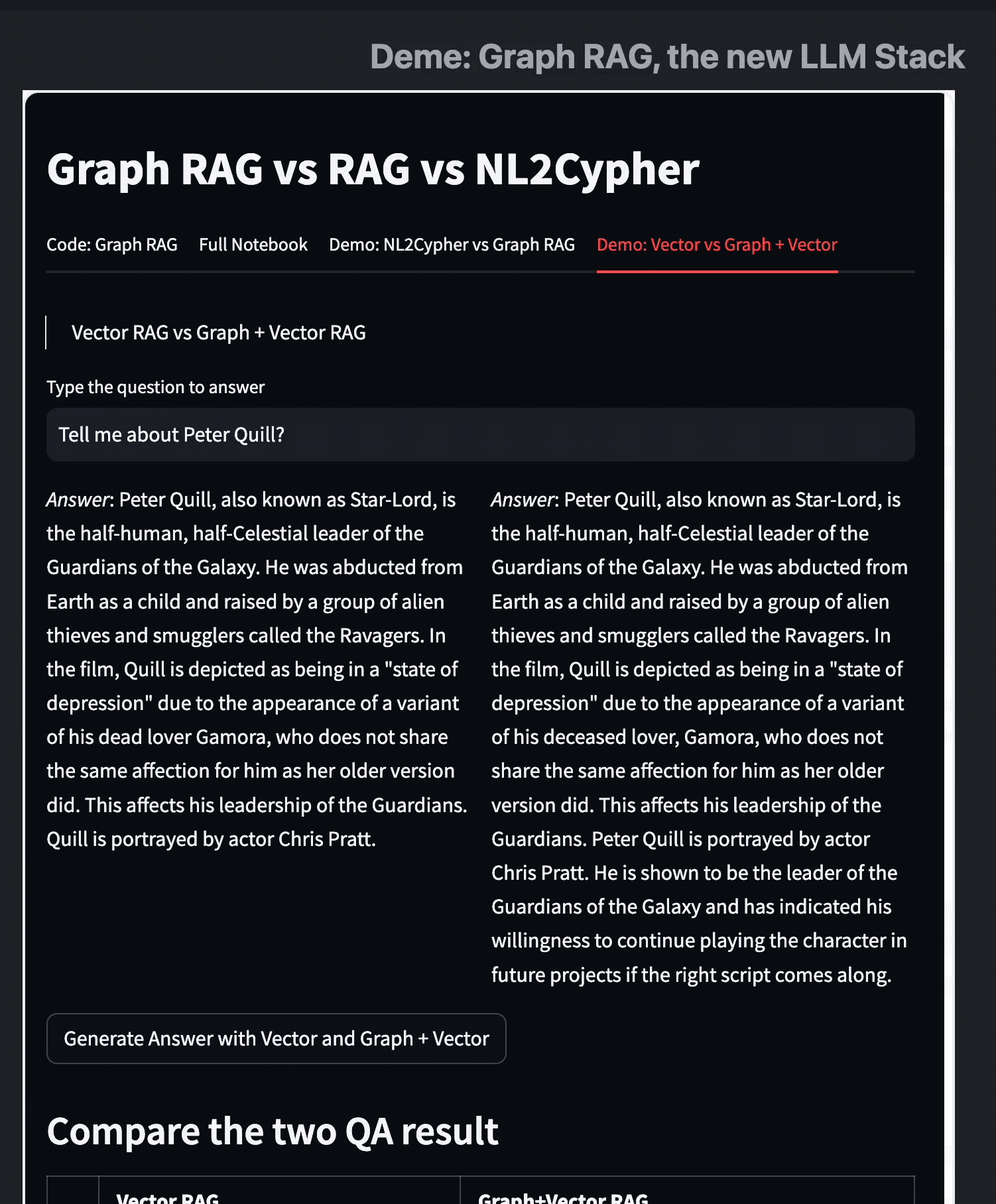
最后,我做了一个 Streamlit 的 Demo 来比较 Graph RAG 与 Vector RAG,从中我们可以看到 Graph RAG 并没有取代 Embedding、向量搜索的方法,而是增强了/补充了它的不足。
Text2Cypher
基于图谱的 LLM 的另一种有趣方法是 Text2Cypher。这种方法不依赖于实体的子图检索,而是将任务/问题翻译成一个面向答案的特定图查询,和我们常说的 Text2SQL 方法本质是一样的。
在 NebulaGraph 上进行 Text2Cypher
在之前的文章中我们已经介绍过,得益于 LLM,实现 Text2Cypher 比传统的 ML 方法更为简单和便宜。
比如,LangChain: NebulaGraphQAChain 和 Llama Index: KnowledgeGraphQueryEngine 让我们 3 行代码就能跑起来 Text2Cypher。
比较 Text2Cypher 和 (Sub)Graph RAG
这两种方法主要在其检索机制上有所不同。Text2Cypher 根据 KG 的 Schema 和给定的任务生成图形模式查询,而 SubGraph RAG 获取相关的子图以提供上下文。
两者都有其优点,为了大家更直观理解他们的特点,我做了这个 Demo 视频:
我们可以看到两者的图查询模式在可视化下是有非常清晰的差异的。
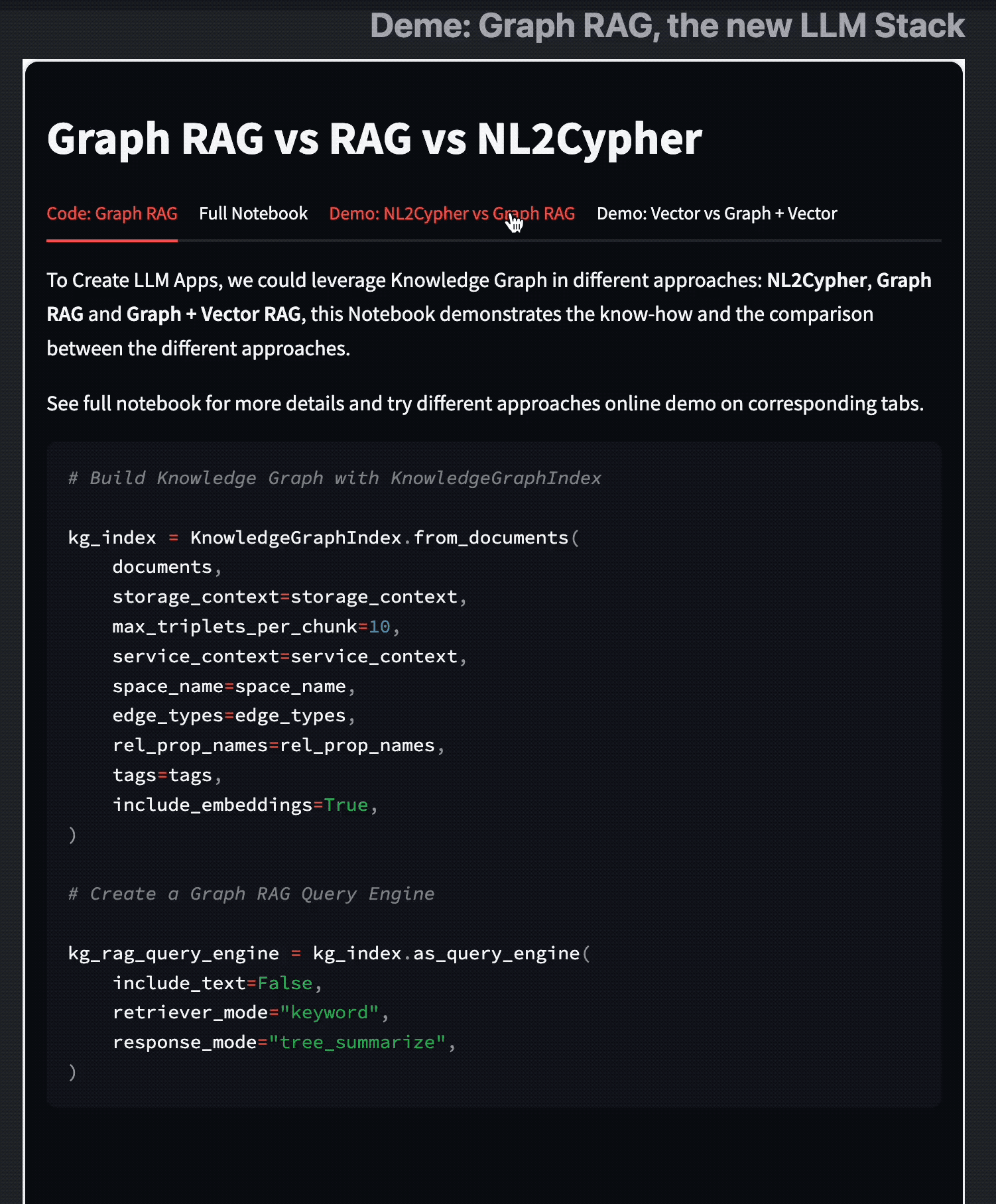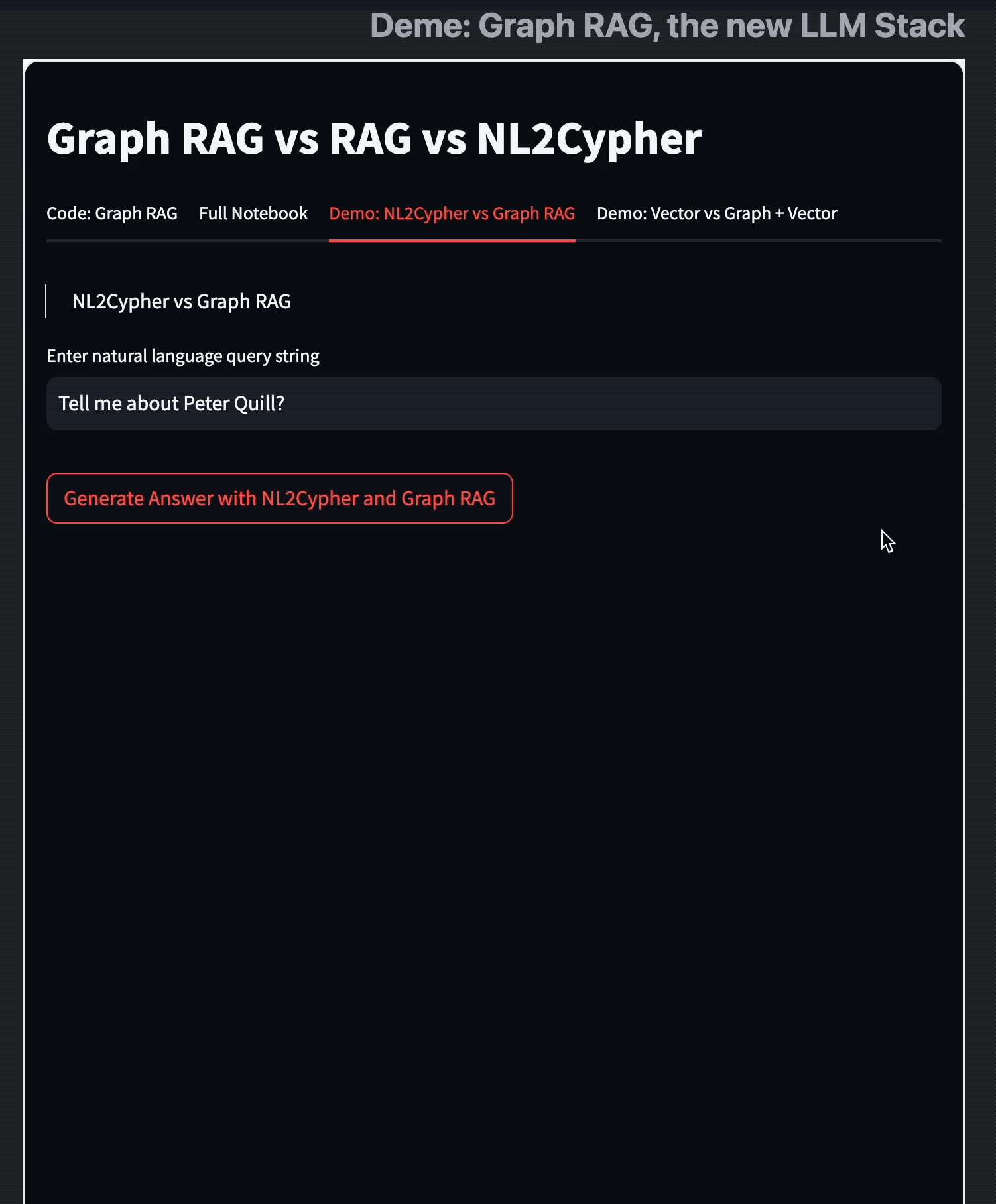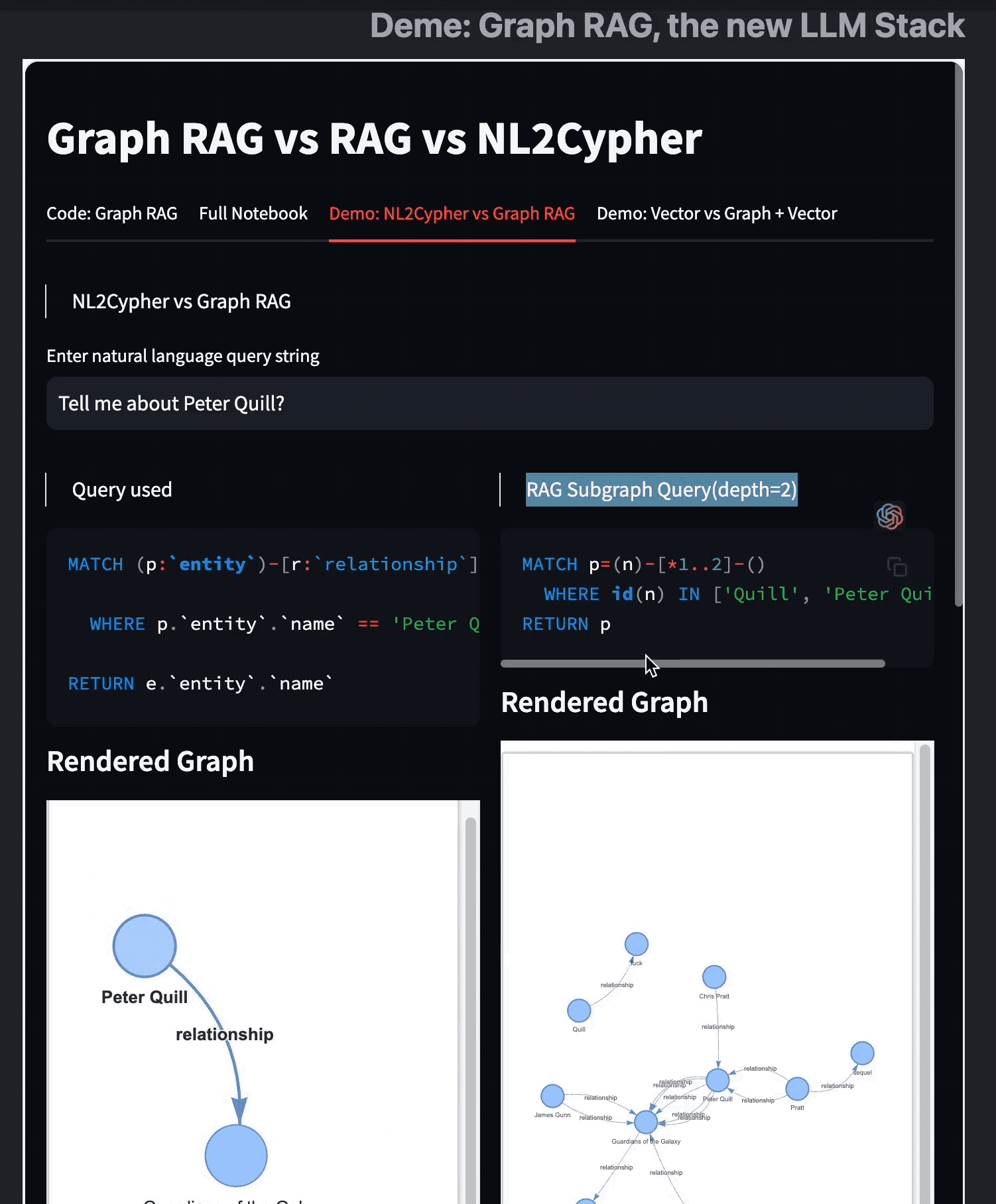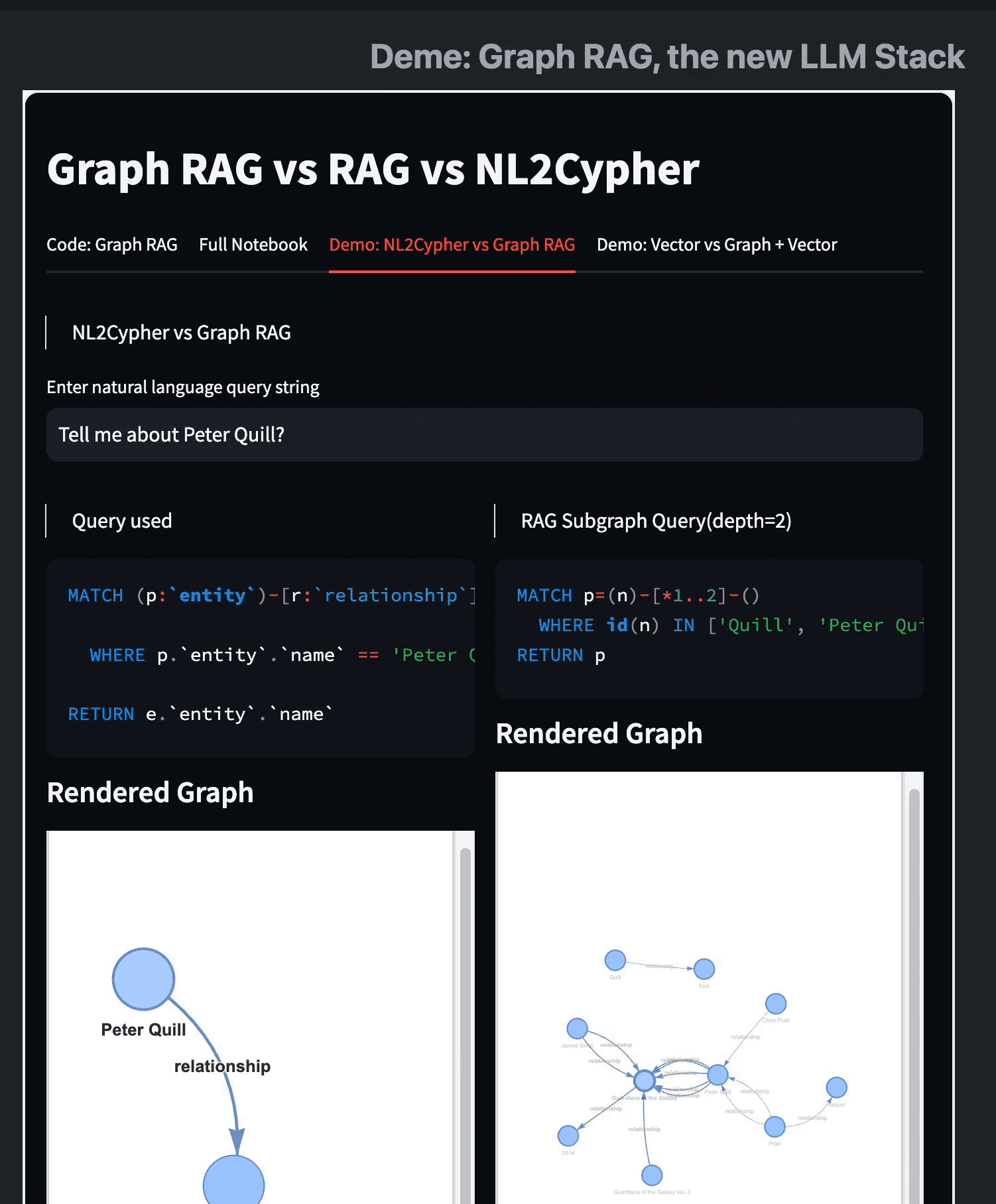
结合 Text2Cypher 的 Graph RAG
然而,两者并没有绝对的好与坏,不同场景下,它们各有优劣。
在现实世界中,我们可能并不总是知道哪种方法更有效(用来区分应该用哪一种),因此,我倾向于考虑同时利用两者,这样获取的两种检索结果作为上下文,一起来生成最终答案的效果可能是最好的。
具体的实现方法在这个 PR中已经可以做到了,只需要设置 with_text2cypher=True,Graph RAG 就会包含 Text2Cypher 上下文,敬请期待它的合并。
结论
通过将知识图谱、图存储集成到 LLM 技术栈中,Graph RAG 把 RAG 的上下文学习推向了一个新的高度。它能在 LLM 应用中,通过利用现有(或新建)的知识图谱,提取细粒度、精确调整、领域特定且互联的知识。
请继续关注图谱和 LLM 领域的更深入的探索和进一步的发展。
相关阅读
- Text2Cypher:大语言模型驱动的图查询生成
- 关于 LLM 和图、图数据库的那些事
- LLM:知识图谱的另类实践
- 图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index
- 利用 ChatGLM 构建知识图谱
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~
2023 年 NebulaGraph 技术社区年度征文活动正在进行中,来这里领取华为 Meta 60 Pro、Switch 游戏机、小米扫地机器人等等礼品哟~ 活动链接:https://discuss.nebula-graph.com.cn/t/topic/13970


 浙公网安备 33010602011771号
浙公网安备 33010602011771号