用图技术搞定附近好友、时空交集等 7 个典型社交网络应用

两个月之前,我的同事拿了一张推特的互动关系图(下图,由 STRRL 授权)来问我能不能搞一篇图技术来探索社交互动关系的文章,看看这些图是如何通过技术实现的。

我想了想,自己玩推特以来也跟随大部队生成了不少的社交关系组图,当中有复杂的社交群体划分:
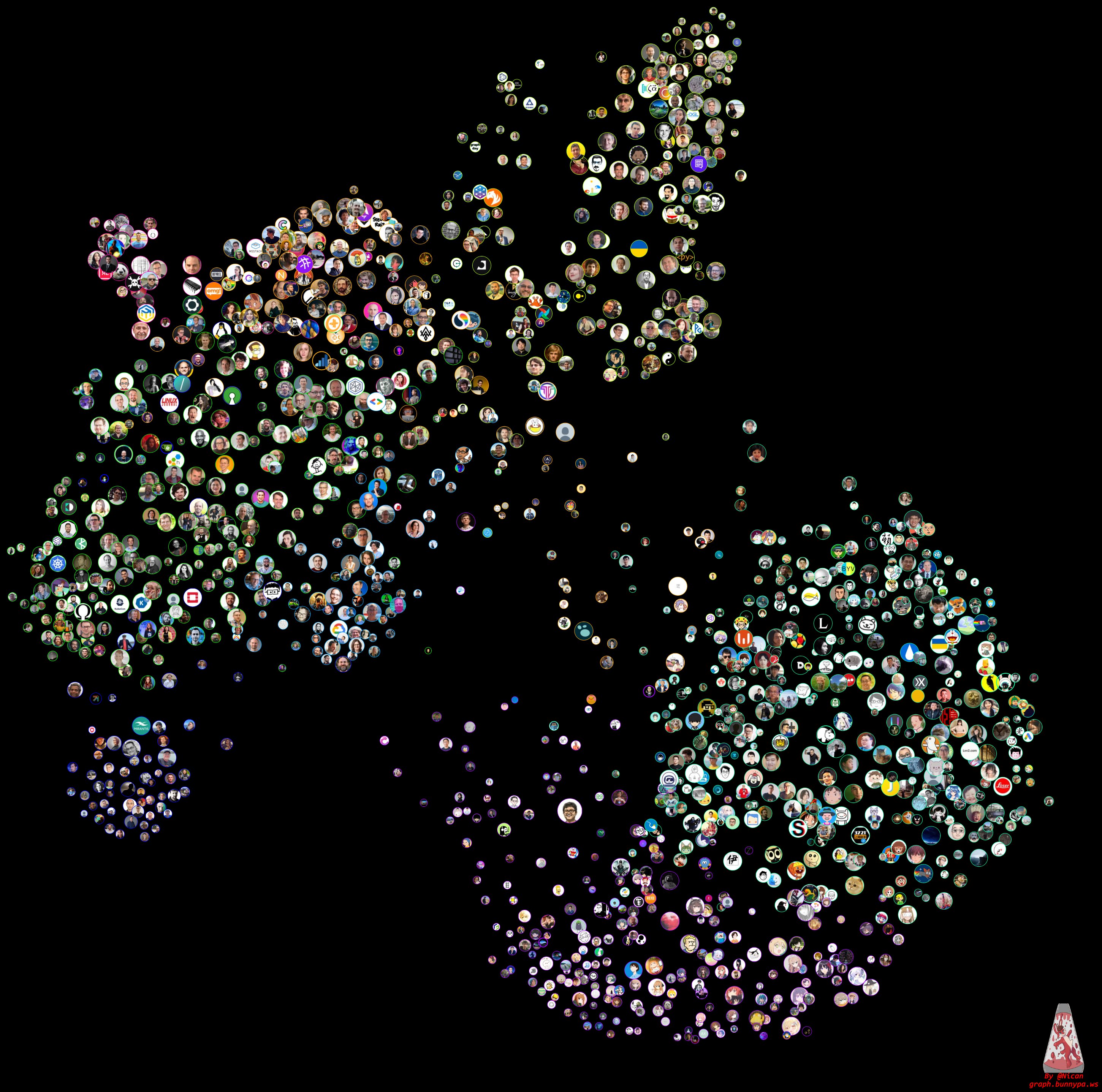
我在技术圈,看在金融、数学圈的大佬在彼岸紧密贴贴。当然也有比较简单的关系图:

看谁和你互动比较多,而他们又和谁关系比较密切。那么问题来了,像上面这种常见的社交关系图,甚至是别的更复杂的基于社交网络的图是如何生成的呢?在本文我将用图数据库 NebulaGraph 来解决社交网络问题,而上面的社交关系组图也被包含在其中。btw,文中介绍的方法提供都了 Playground 供大家学习、玩耍。
简单剖析社交网络的选型
从上面的图我们可以知道,一个典型的社交网络拓扑图便是用户的点和关系的边组成的网状结构。
因此,我们可以用图数据库来表示用户和他们的连接关系,来完成这个社交网络的数据模型。基于图数据库,我们可以对用户间的关系进行查询,让各类基于社交网络连接关系的查找、统计、分析需求变得更便捷、高效。
例如,利用图形数据库来识别网络中的“有影响力的用户”;根据用户之间的共同点对新的连接(好友关系、感兴趣的信息)进行推荐;更甚者寻找社群中聚集的不同人群、社区,进行用户画像。
以 NebulaGraph 为代表的图数据库不仅能支撑复杂的多跳查询,同时也支持实时写入、更新数据,因此非常适合用来探索用户关系不断变化的社交网络系统。
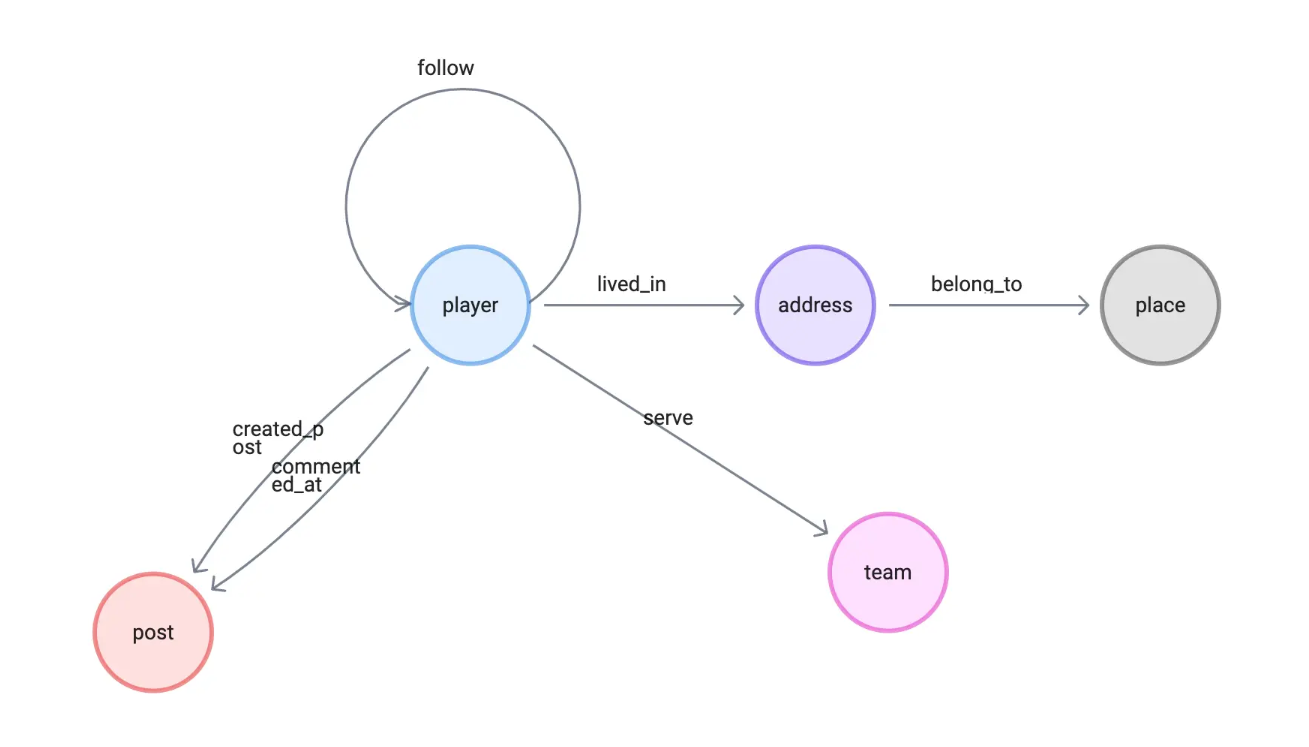
图建模
上文说过社交网络天然就是一种网络、图的结构形态,为了分析常见社交场景的应用示例,本文的例子采用了典型的小型社交网络。因此,我在 NebulaGraph 官方数据集 basketballplayer 之上,增加了:
三种点:
- 地址
- 地点
- 文章
四种边:
- 发文
- 评论
- 住在
- 属于(地点)
它的建模非常自然:
数据导入
导入数据集
首先,我们加载默认的 basketballplayer 数据集,导入对应的 schema 和数据。
如果你使用的是命令行,那你在 console 之中执行 :play basketballplayer 就可以导入数据。如果你使用了可视化图探索工具 NebulaGraph Studio / NebulaGraph Explorer,我们需要在欢迎页点击下载、部署这份基础数据集。
创建社交网络 schema
通过下面语句创建新加入的点、边类型 schema:
CREATE TAG IF NOT EXISTS post(title string NOT NULL);
CREATE EDGE created_post(post_time timestamp);
CREATE EDGE commented_at(post_time timestamp);
CREATE TAG address(address string NOT NULL, `geo_point` geography(point));
CREATE TAG place(name string NOT NULL, `geo_point` geography(point));
CREATE EDGE belong_to();
CREATE EDGE lived_in();
写入新数据
在等待两个心跳(20秒)以上时间之后,我们可以执行数据插入:
INSERT VERTEX post(title) values \
"post1":("a beautify flower"), "post2":("my first bike"), "post3":("I can swim"), \
"post4":("I love you, Dad"), "post5":("I hate coriander"), "post6":("my best friend, tom"), \
"post7":("my best friend, jerry"), "post8":("Frank, the cat"), "post9":("sushi rocks"), \
"post10":("I love you, Mom"), "post11":("Let's have a party!");
INSERT EDGE created_post(post_time) values \
"player100"->"post1":(timestamp("2019-01-01 00:30:06")), \
"player111"->"post2":(timestamp("2016-11-23 10:04:50")), \
"player101"->"post3":(timestamp("2019-11-11 10:44:06")), \
"player103"->"post4":(timestamp("2014-12-01 20:45:11")), \
"player102"->"post5":(timestamp("2015-03-01 00:30:06")), \
"player104"->"post6":(timestamp("2017-09-21 23:30:06")), \
"player125"->"post7":(timestamp("2018-01-01 00:44:23")), \
"player106"->"post8":(timestamp("2019-01-01 00:30:06")), \
"player117"->"post9":(timestamp("2022-01-01 22:23:30")), \
"player108"->"post10":(timestamp("2011-01-01 10:00:30")), \
"player100"->"post11":(timestamp("2021-11-01 11:10:30"));
INSERT EDGE commented_at(post_time) values \
"player105"->"post1":(timestamp("2019-01-02 00:30:06")), \
"player109"->"post1":(timestamp("2016-11-24 10:04:50")), \
"player113"->"post3":(timestamp("2019-11-13 10:44:06")), \
"player101"->"post4":(timestamp("2014-12-04 20:45:11")), \
"player102"->"post1":(timestamp("2015-03-03 00:30:06")), \
"player103"->"post1":(timestamp("2017-09-23 23:30:06")), \
"player102"->"post7":(timestamp("2018-01-04 00:44:23")), \
"player101"->"post8":(timestamp("2019-01-04 00:30:06")), \
"player106"->"post9":(timestamp("2022-01-02 22:23:30")), \
"player105"->"post10":(timestamp("2011-01-11 10:00:30")), \
"player130"->"post1":(timestamp("2019-01-02 00:30:06")), \
"player131"->"post2":(timestamp("2016-11-24 10:04:50")), \
"player131"->"post3":(timestamp("2019-11-13 10:44:06")), \
"player133"->"post4":(timestamp("2014-12-04 20:45:11")), \
"player132"->"post5":(timestamp("2015-03-03 00:30:06")), \
"player134"->"post6":(timestamp("2017-09-23 23:30:06")), \
"player135"->"post7":(timestamp("2018-01-04 00:44:23")), \
"player136"->"post8":(timestamp("2019-01-04 00:30:06")), \
"player137"->"post9":(timestamp("2022-01-02 22:23:30")), \
"player138"->"post10":(timestamp("2011-01-11 10:00:30")), \
"player141"->"post1":(timestamp("2019-01-03 00:30:06")), \
"player142"->"post2":(timestamp("2016-11-25 10:04:50")), \
"player143"->"post3":(timestamp("2019-11-14 10:44:06")), \
"player144"->"post4":(timestamp("2014-12-05 20:45:11")), \
"player145"->"post5":(timestamp("2015-03-04 00:30:06")), \
"player146"->"post6":(timestamp("2017-09-24 23:30:06")), \
"player147"->"post7":(timestamp("2018-01-05 00:44:23")), \
"player148"->"post8":(timestamp("2019-01-05 00:30:06")), \
"player139"->"post9":(timestamp("2022-01-03 22:23:30")), \
"player140"->"post10":(timestamp("2011-01-12 10:01:30")), \
"player141"->"post1":(timestamp("2019-01-04 00:34:06")), \
"player102"->"post2":(timestamp("2016-11-26 10:06:50")), \
"player103"->"post3":(timestamp("2019-11-15 10:45:06")), \
"player104"->"post4":(timestamp("2014-12-06 20:47:11")), \
"player105"->"post5":(timestamp("2015-03-05 00:32:06")), \
"player106"->"post6":(timestamp("2017-09-25 23:31:06")), \
"player107"->"post7":(timestamp("2018-01-06 00:46:23")), \
"player118"->"post8":(timestamp("2019-01-06 00:35:06")), \
"player119"->"post9":(timestamp("2022-01-04 22:26:30")), \
"player110"->"post10":(timestamp("2011-01-15 10:00:30")), \
"player111"->"post1":(timestamp("2019-01-06 00:30:06")), \
"player104"->"post11":(timestamp("2022-01-15 10:00:30")), \
"player125"->"post11":(timestamp("2022-02-15 10:00:30")), \
"player113"->"post11":(timestamp("2022-03-15 10:00:30")), \
"player102"->"post11":(timestamp("2022-04-15 10:00:30")), \
"player108"->"post11":(timestamp("2022-05-15 10:00:30"));
INSERT VERTEX `address` (`address`, `geo_point`) VALUES \
"addr_0":("Brittany Forge Apt. 718 East Eric WV 97881", ST_Point(1,2)),\
"addr_1":("Richard Curve Kingstad AZ 05660", ST_Point(3,4)),\
"addr_2":("Schmidt Key Lake Charles AL 36174", ST_Point(13.13,-87.65)),\
"addr_3":("5 Joanna Key Suite 704 Frankshire OK 03035", ST_Point(5,6)),\
"addr_4":("1 Payne Circle Mitchellfort LA 73053", ST_Point(7,8)),\
"addr_5":("2 Klein Mission New Annetteton HI 05775", ST_Point(9,10)),\
"addr_6":("1 Vanessa Stravenue Suite 184 Baileyville NY 46381", ST_Point(11,12)),\
"addr_7":("John Garden Port John LA 54602", ST_Point(13,14)),\
"addr_8":("11 Webb Groves Tiffanyside MN 14566", ST_Point(15,16)),\
"addr_9":("70 Robinson Locks Suite 113 East Veronica ND 87845", ST_Point(17,18)),\
"addr_10":("24 Mcknight Port Apt. 028 Sarahborough MD 38195", ST_Point(19,20)),\
"addr_11":("0337 Mason Corner Apt. 900 Toddmouth FL 61464", ST_Point(21,22)),\
"addr_12":("7 Davis Station Apt. 691 Pittmanfort HI 29746", ST_Point(23,24)),\
"addr_13":("1 Southport Street Apt. 098 Westport KY 85907", ST_Point(120.12,30.16)),\
"addr_14":("Weber Unions Eddieland MT 64619", ST_Point(25,26)),\
"addr_15":("1 Amanda Freeway Lisaland NJ 94933", ST_Point(27,28)),\
"addr_16":("2 Klein HI 05775", ST_Point(9,10)),\
"addr_17":("Schmidt Key Lake Charles AL 13617", ST_Point(13.12, -87.60)),\
"addr_18":("Rodriguez Track East Connorfort NC 63144", ST_Point(29,30));
INSERT VERTEX `place` (`name`, `geo_point`) VALUES \
"WV":("West Virginia", ST_Point(1,2.5)),\
"AZ":("Arizona", ST_Point(3,4.5)),\
"AL":("Alabama", ST_Point(13.13,-87)),\
"OK":("Oklahoma", ST_Point(5,6.1)),\
"LA":("Louisiana", ST_Point(7,8.1)),\
"HI":("Hawaii", ST_Point(9,10.1)),\
"NY":("New York", ST_Point(11,12.1)),\
"MN":("Minnesota", ST_Point(15,16.1)),\
"ND":("North Dakota", ST_Point(17,18.1)),\
"FL":("Florida", ST_Point(21,22.1)),\
"KY":("Kentucky", ST_Point(120.12,30)),\
"MT":("Montana", ST_Point(25,26.1)),\
"NJ":("New Jersey", ST_Point(27,28.1)),\
"NC":("North Carolina", ST_Point(29,30.1));
INSERT EDGE `belong_to`() VALUES \
"addr_0"->"WV":(),\
"addr_1"->"AZ":(),\
"addr_2"->"AL":(),\
"addr_3"->"OK":(),\
"addr_4"->"LA":(),\
"addr_5"->"HI":(),\
"addr_6"->"NY":(),\
"addr_7"->"LA":(),\
"addr_8"->"MN":(),\
"addr_9"->"ND":(),\
"addr_10"->"MD":(),\
"addr_11"->"FL":(),\
"addr_12"->"HI":(),\
"addr_13"->"KY":(),\
"addr_14"->"MT":(),\
"addr_15"->"NJ":(),\
"addr_16"->"HI":(),\
"addr_17"->"AL":(),\
"addr_18"->"NC":();
INSERT EDGE `lived_in`() VALUES \
"player100"->"addr_4":(),\
"player101"->"addr_7":(),\
"player102"->"addr_2":(),\
"player103"->"addr_3":(),\
"player104"->"addr_0":(),\
"player105"->"addr_5":(),\
"player106"->"addr_6":(),\
"player107"->"addr_1":(),\
"player108"->"addr_8":(),\
"player109"->"addr_9":(),\
"player110"->"addr_10":(),\
"player111"->"addr_11":(),\
"player112"->"addr_12":(),\
"player113"->"addr_13":(),\
"player114"->"addr_14":(),\
"player115"->"addr_15":(),\
"player116"->"addr_16":(),\
"player117"->"addr_17":(),\
"player118"->"addr_18":();
数据初探
完成 schema 创建和数据导入之后,我们来看看数据统计:
[basketballplayer]> SUBMIT JOB STATS;
+------------+
| New Job Id |
+------------+
| 10 |
+------------+
[basketballplayer]> SHOW STATS;
+---------+----------------+-------+
| Type | Name | Count |
+---------+----------------+-------+
| "Tag" | "address" | 19 |
| "Tag" | "place" | 14 |
| "Tag" | "player" | 51 |
| "Tag" | "post" | 10 |
| "Tag" | "team" | 30 |
| "Edge" | "belong_to" | 19 |
| "Edge" | "commented_at" | 40 |
| "Edge" | "created_post" | 10 |
| "Edge" | "follow" | 81 |
| "Edge" | "lived_in" | 19 |
| "Edge" | "serve" | 152 |
| "Space" | "vertices" | 124 |
| "Space" | "edges" | 321 |
+---------+----------------+-------+
Got 13 rows (time spent 1038/51372 us)
查一下所有的数据:
MATCH ()-[e]->() RETURN e LIMIT 10000
因为数据量太小了,这里可以把所有数据在 NebulaGraph Explorer 中进行渲染出来:
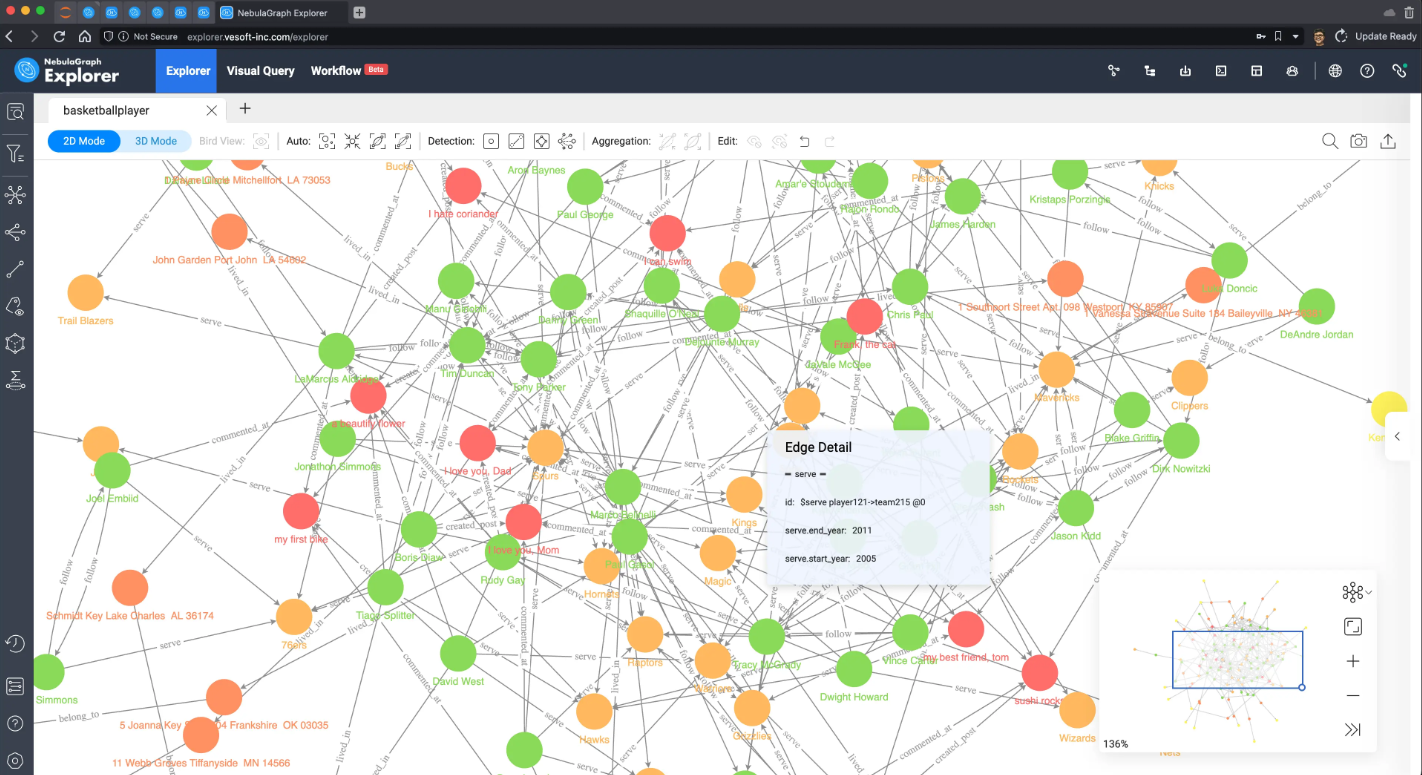
社交网络典型应用
找出网络中的关键人物
要识别社交网络中的有影响力的关键人物们(Influencer)需要使用上各种指标和方法,而 KOL 的识别对很多业务场景都有帮助,比如:用于营销或研究网络中的信息传播。
识别他们的方法有很多,具体的方法和考量信息、关系、角度也取决于这些关键人物的类型和获取他们的目的。
识别 Influencer 常见的方法包括看他们的粉丝数、内容浏览量,内容(包括帖子、视频)上读者的参与度,以及他们的内容影响力(转发、引用)。这些思路如果用图数据库实现也没啥问题,不过太普通太普通了,我们搞点高科技的——用评估、计算节点重要性的图算法,在图上得出这些关键人物。
PageRank
PageRank 是一个非常“古老的”图算法,它计算图上点之间的关系数量得到每个点的得分(Rank),最初由 Google 的创始人 Larry Page 和 Sergey Brin 提出并应用在早期的 Google 搜索引擎中,用来排序搜索结果,这里的 Page 可以是 Larry Page 的姓和 Web Page 的双关了。
在现代、复杂的搜索引擎中,PageRank 早就因为其过于简单的设计而被弃用,但是在部分图结构网络场景中,PageRank 算法仍然在发光发热。在社交网络中,我们姑且粗略地认为所有连接的重要程度相同,去运行 PageRank 算法找到那些 Influencer。
在 NebulaGraph 中,我们可以利用图计算工具 NebulaGraph Algorithm、NebulaGraph Analytics 在全图上运行 PageRank,这是因为数据量小。但在日常的分析、验证、设计截断时,我们不需要在全量数据上跑结果,在一些很小的子图上(最多上万个节点),我们可以轻松地在浏览器里边运行各种图算法得到业务可用的数据。
这里,我们就用 NebulaGraph Explorer 内置的图算法功能,在浏览器上点击一下鼠标执行 PageRank 看看,具体方法这里略去,可以参考文档。
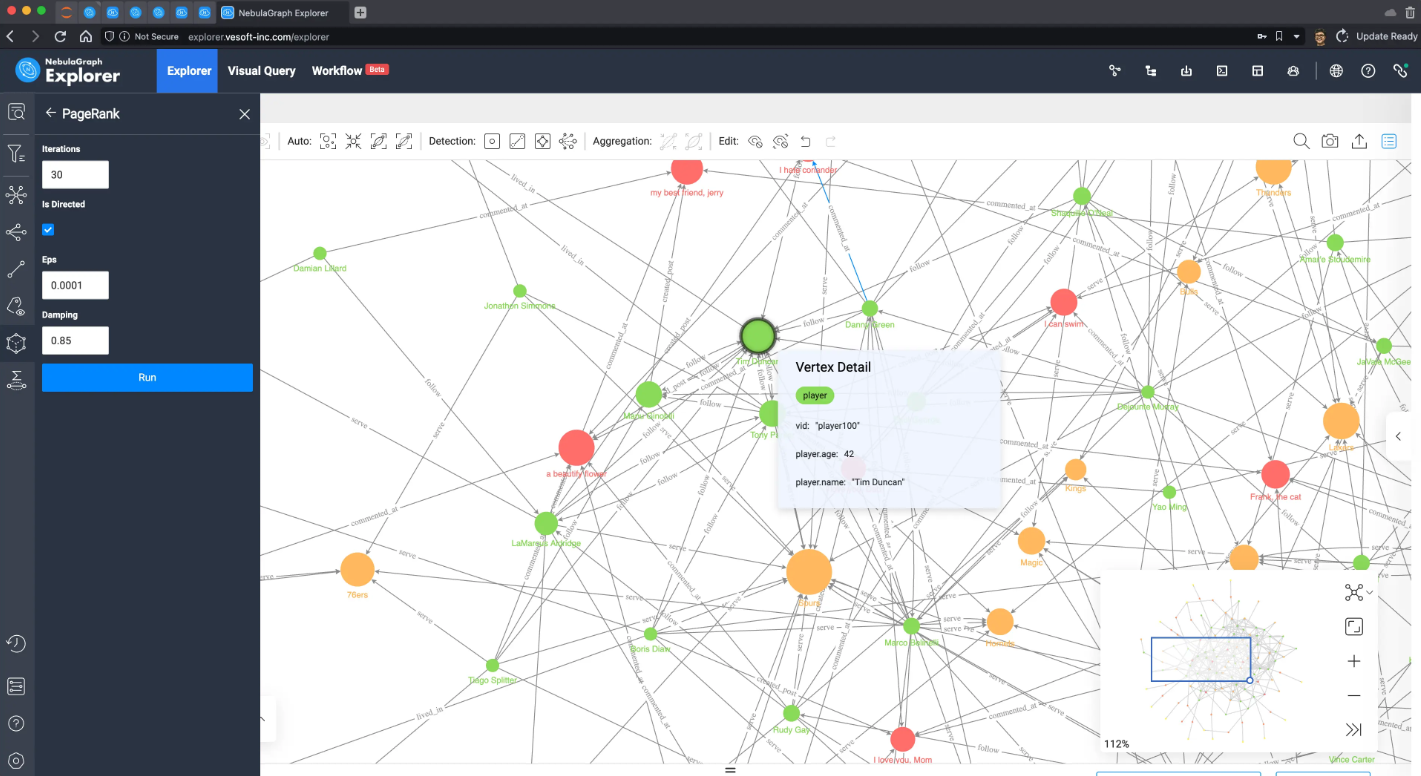
如图所示,PageRank 计算之后所有绿色的 player(人)中,"player.name: Tim Duncan" 是最大的一个点。与之相关联的关系看起来的确不少,我们在图上选择他,再右键反选,选择除了 Tim Duncan 之外的所有点,用退格键删除所有其他的点,再以他作为起点双向探索出 1 到 5 步,可以得到 Tim Duncan 的子图:
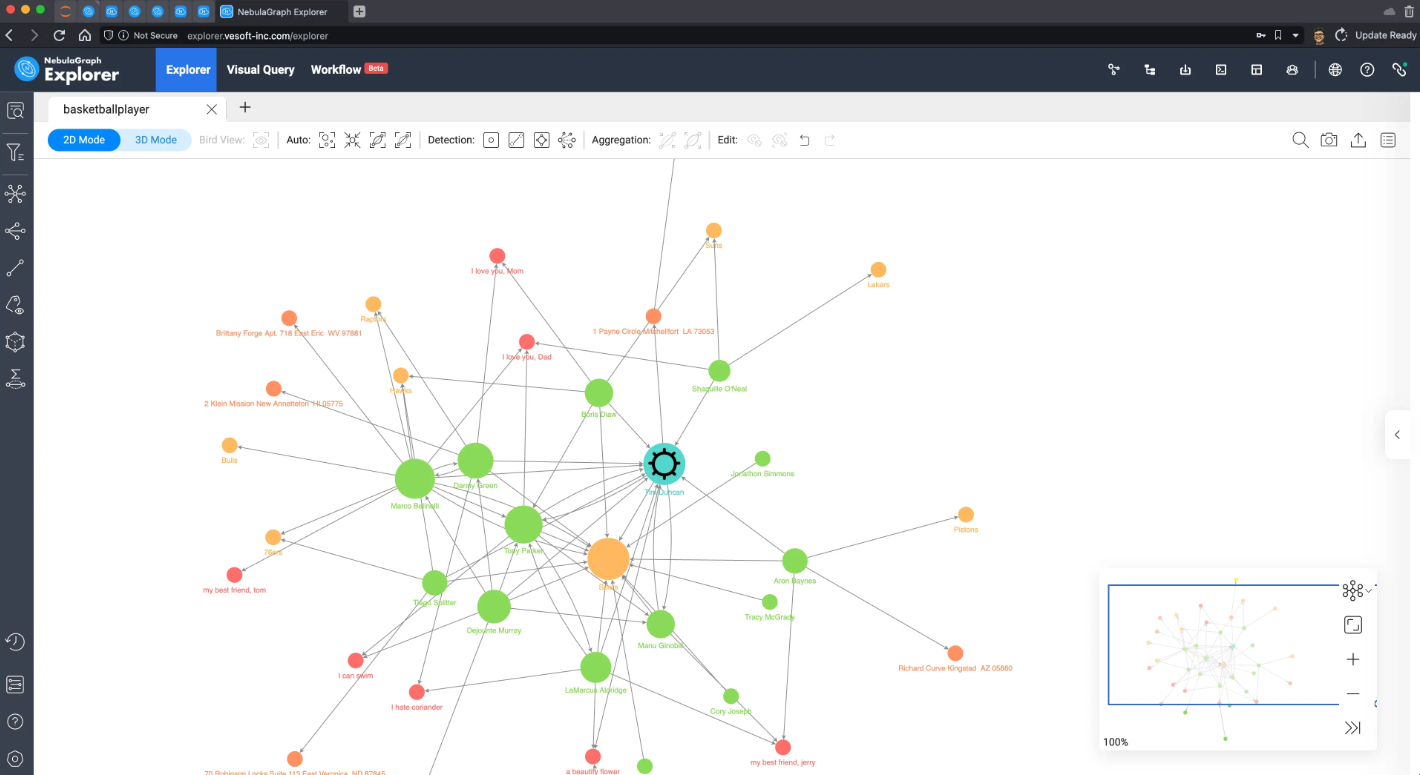
除了可以看到 Tim Duncan 是个 Influener 之外,我们还可以看到其他受欢迎的队员和他一样服役过知名球队的热刺(Spurs),这些都印证了 PageRank 的评估方式。
现在,我们再看看其他判定维度下的算法会不会得出一样的结论呢?
Betweenness Centrality
作为另一个流行的节点重要性算法,通过计算一个节点在图中起到多少桥梁作用来衡量节点的重要性。这里的桥梁作用是有数学定义的量化算法,这里就不展开说了。不过从感官上,可以看出它是另一个符合直觉去评估节点重要性的方法。
我们重新在画布上查询所有的点边之后,在浏览器里运行 Betweenness Centrality 算法,这次的结果是:
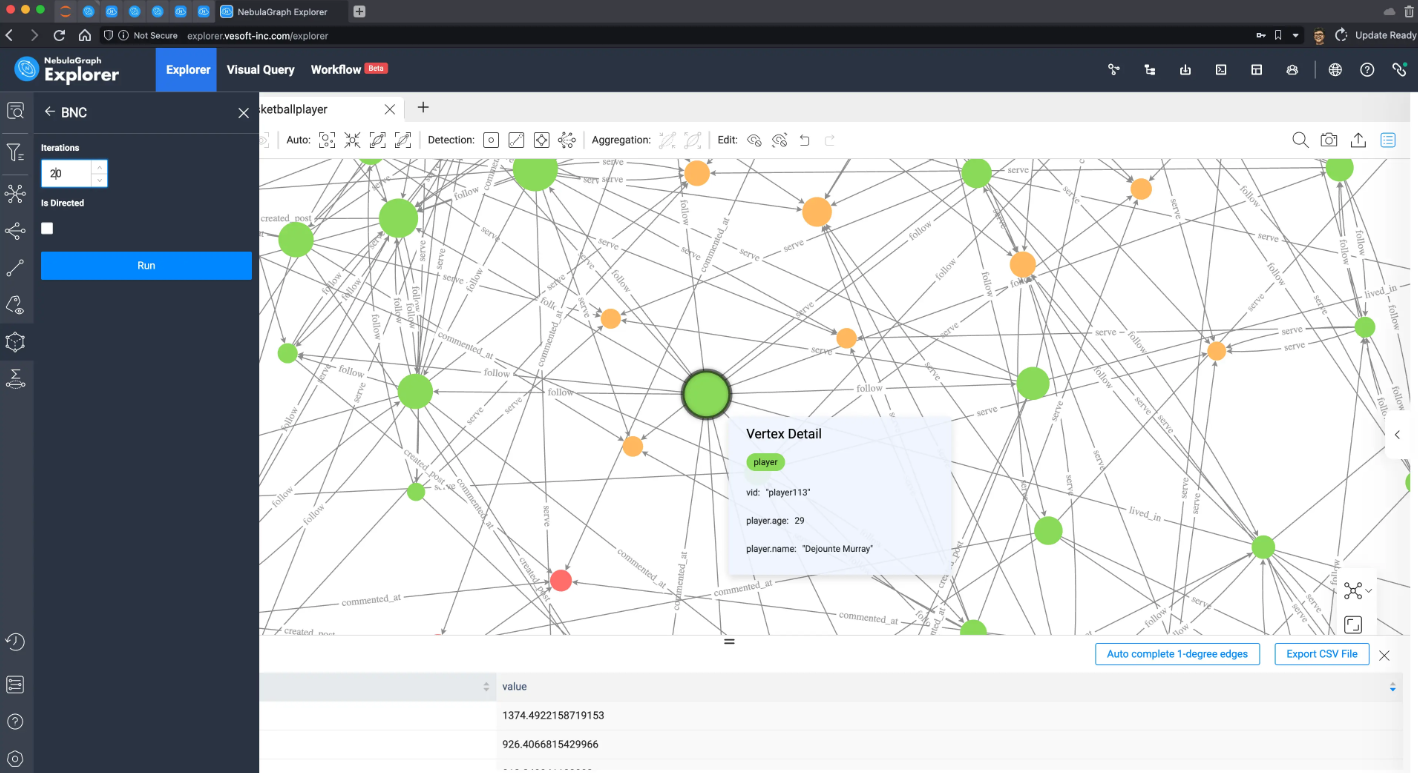
从它的五跳内子图可以看出,与之前 PageRank 所得的关键人物 Tim Duncan 呈现的星状不同,Dejounte Murray 的子图呈现簇状,在感官、直觉上可以想象 Dejounte Murray 真的在很多节点之间的最小路径上,而 Tim Duncan 则似乎和更多的重要连接者产生了关联。
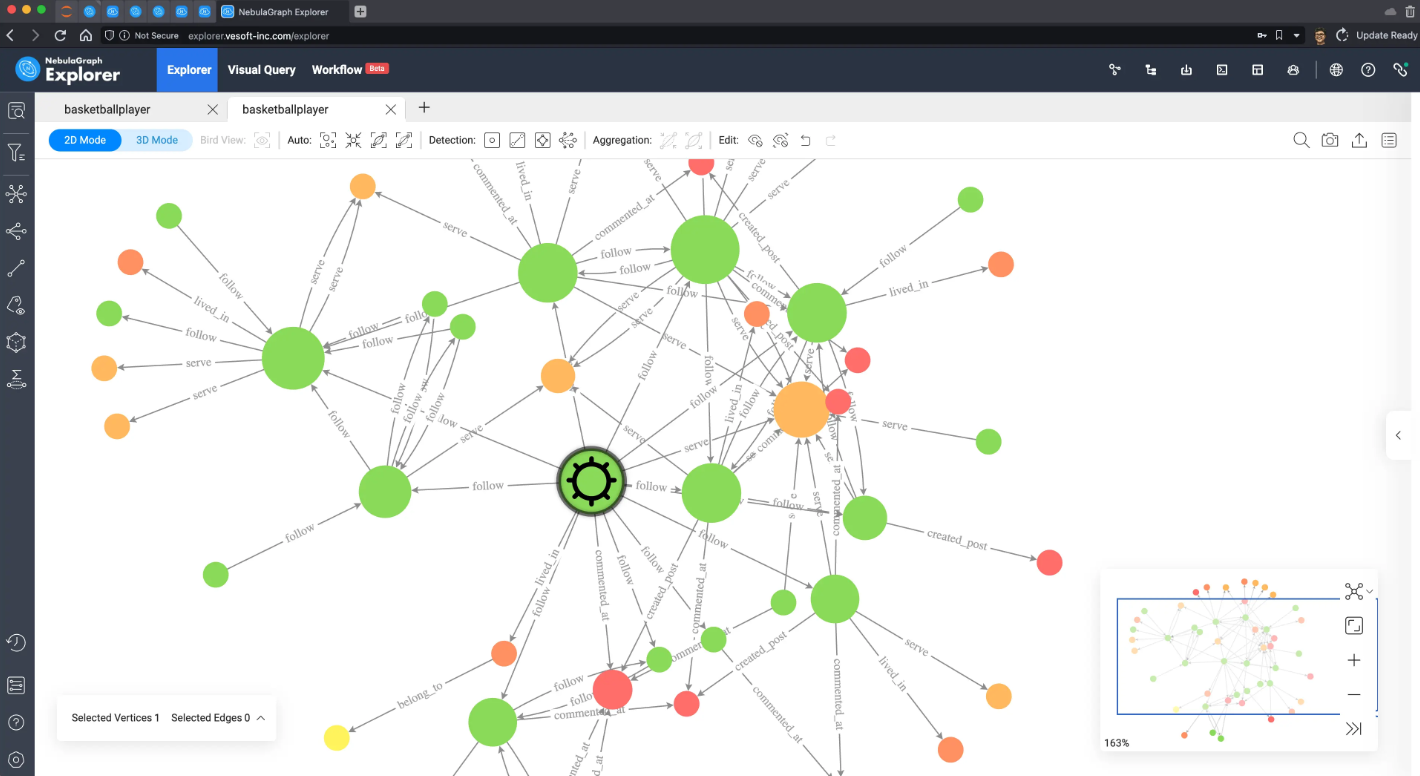
在实际的应用场景中,针对不同需求我们会选择不同的算法。一般来说,要尝试各种定义、试验各种执行结果,以便分析去找到我们关注的关键人物产生影响的结构特征。
找出社区、聚集群体
社交网络中的社区检测是一种通过分析社交关系来发现社区结构的技术。社区结构是指在社交网络、图谱中互相联系密切的一组节点,这些节点通常具有相似的特征。例如,社区结构其中一种表现形式为:都对某类的话题或内容感兴趣而聚集的一组用户。
社区检测的目的是通过对社交网络进行分析,找出不同社区的边界,并确定每个社区中的节点。这个过程可以通过各种算法来完成,例如:标签传播算法、弱联通分量算法和 Louvain 算法等。通过发现社区结构,可以更好地了解社交网络的结构和特征,并有助于社交网络服务方更好地推断和预测社交网络中的行为,协助治理社交网络、广告投放、市场营销等行为。
由于我们的数据集是模拟的,在不同的算法之下得出的结果未必能展现其真实的面貌,所以本章只是简单地展示下利用若干图算法进行社区识别之后的结果。在真实世界的案例中,我们应该在此基础之上结合领域知识或者其他技术手段协同给出不同群体、社区的画像、标签。
标签传播算法效果:
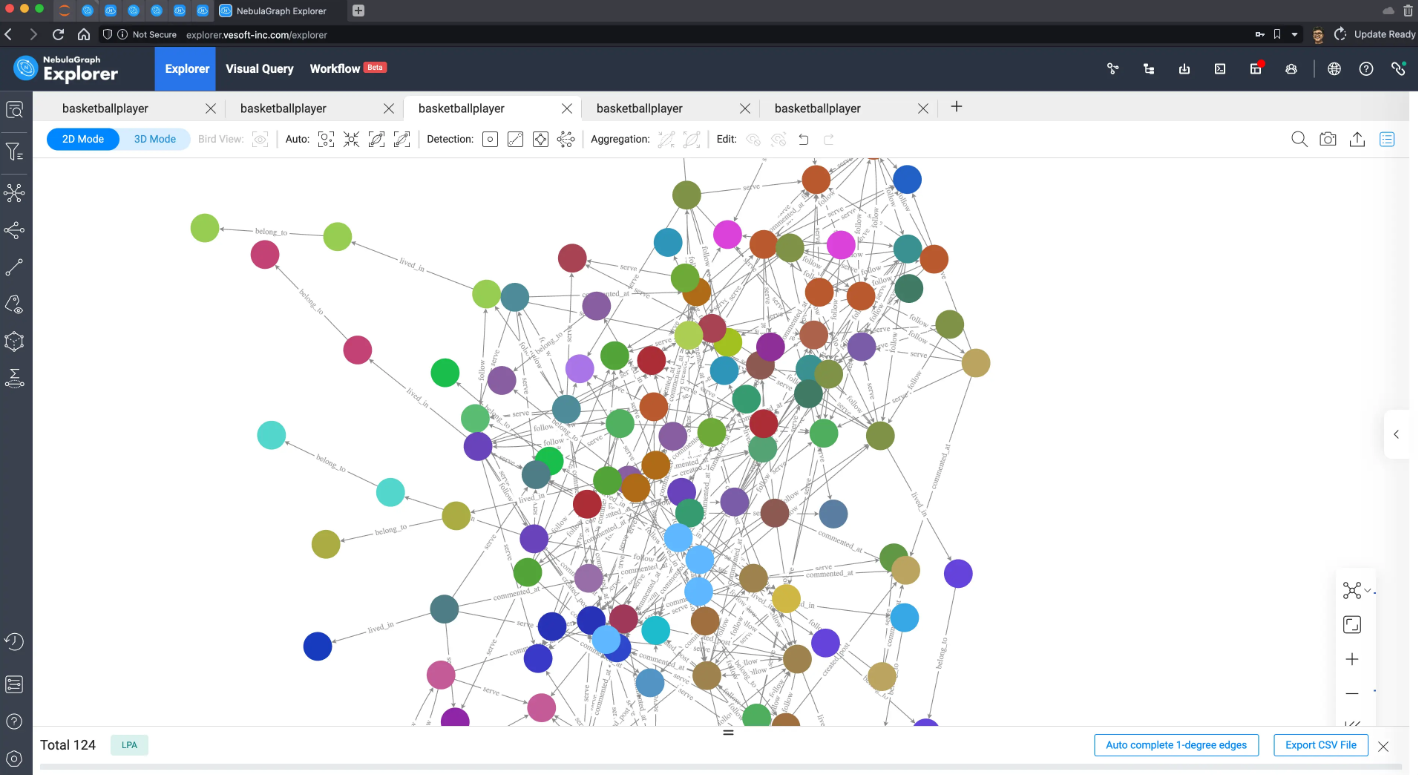
Louvain 算法效果:
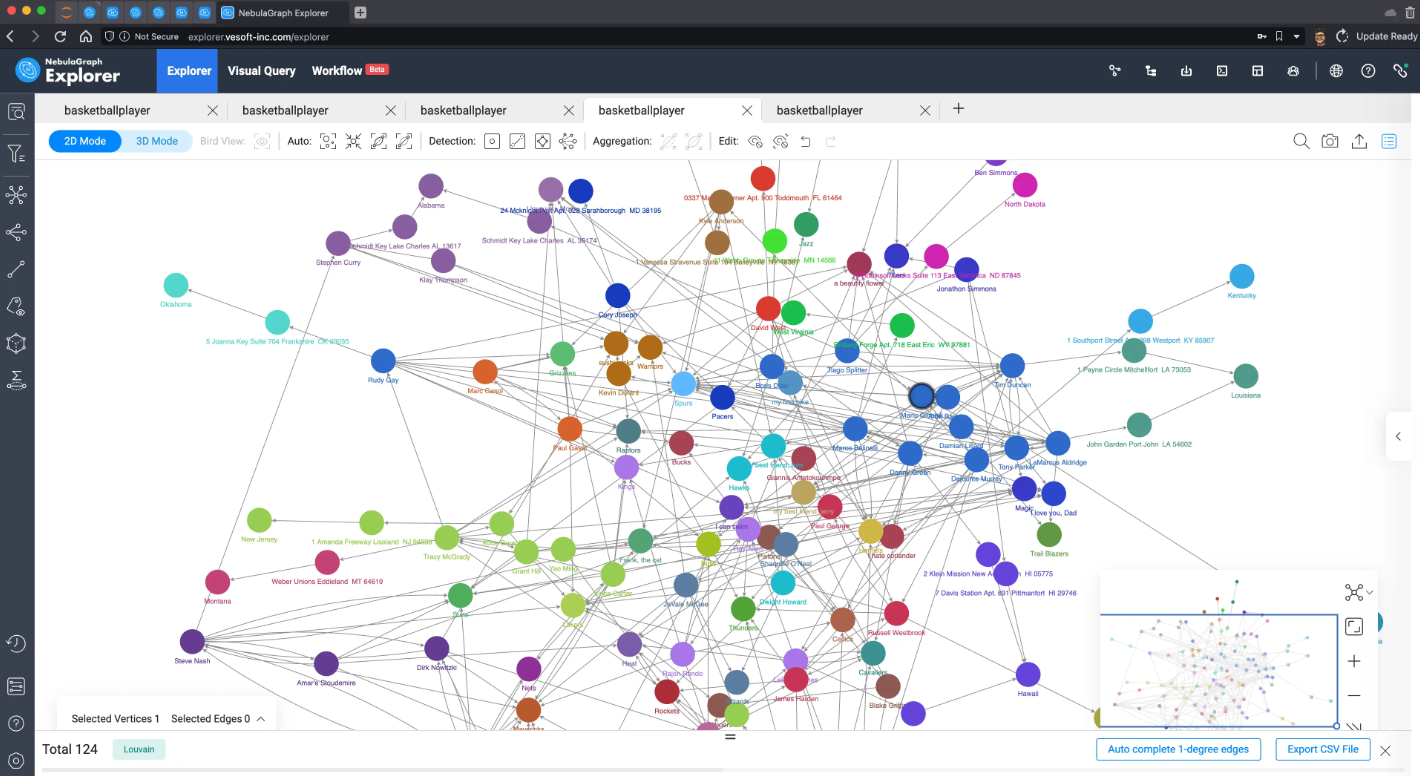
弱联通分量算法效果:
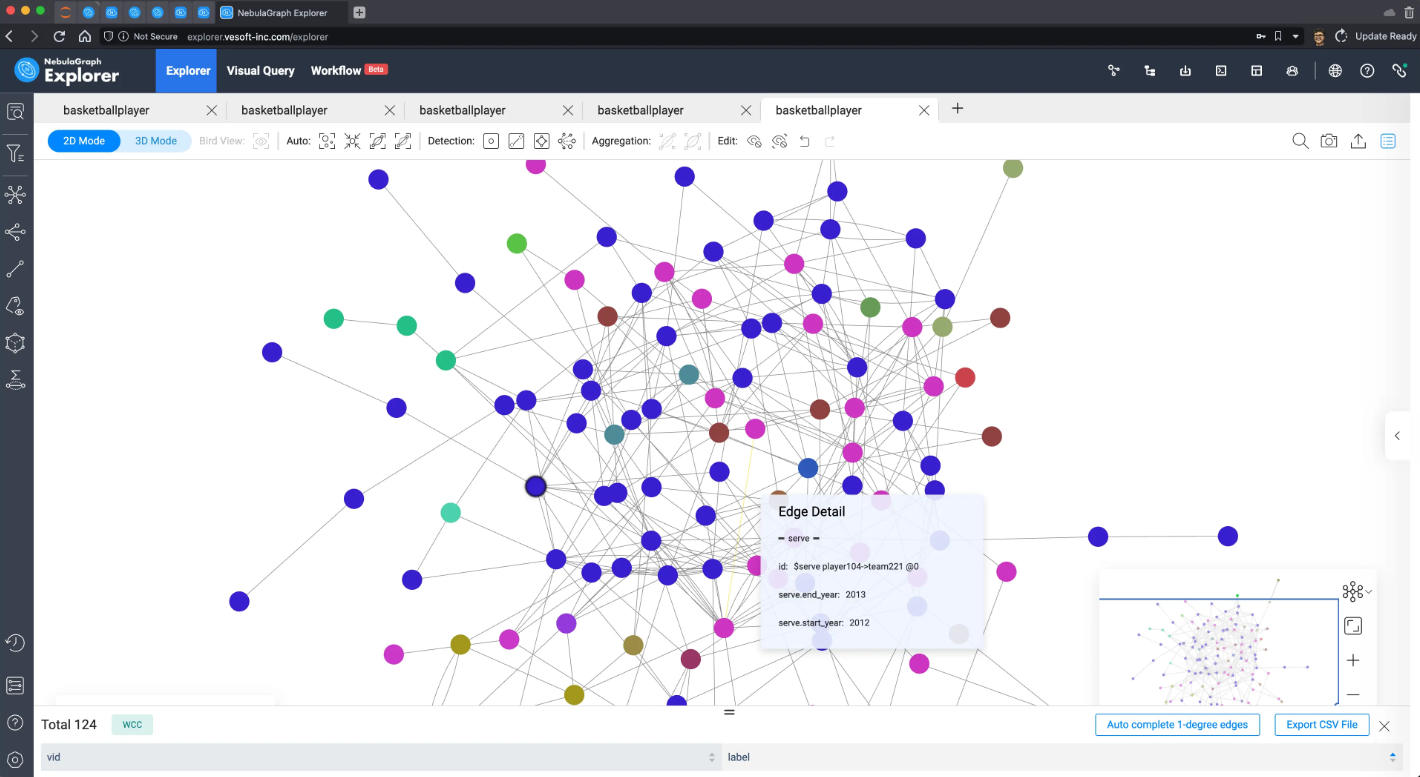
在后面的章节,我们会在更小、更简单的子图上再次验证这几个算法,结果会更具有可解释性。
好友亲密度
通过社区识别算法,其实能在一定程度上在全局计算中获得兴趣相近、关联紧密的好友。那么,如何获得一个指定用户的其他亲密好友呢?
我们可以通过计算得到这个用户的好友,根据该好友和用户拥有的共同好友数进行排序,最后得到结果。
这里以 "Tim Duncan" 举例,他的两度好友(好友的好友)相关语句是 (:player{name: "Tim Duncan"})-[:follow]-(f:player)-[:follow]-(fof:player)。如果 Tim Duncan 的两度好友同时也是他的好友的话,那么这个中间好友就是 Tim Duncan 和这个两度好友的共同好友 Mutual Friend。我们有理由相信那些和 Tim Duncan 有更多共同好友的人可能跟他有更高的亲密度:
MATCH (start:`player`{name: "Tim Duncan"})-[:`follow`]-(f:`player`)-[:`follow`]-(fof:`player`),
(start:`player`)-[:`follow`]-(fof:`player`)
RETURN fof.`player`.name, count(DISTINCT f) AS NrOfMutualF ORDER BY NrOfMutualF DESC;
这个计算结果是,"Tony Parker" 和 Tim 有 5 个共同好友,最为亲密。
| fof.player.name | NrOfMutualF |
|---|---|
| Tony Parker | 5 |
| Dejounte Murray | 4 |
| Manu Ginobili | 3 |
| Marco Belinelli | 3 |
| Danny Green | 2 |
| Boris Diaw | 1 |
| LaMarcus Aldridge | 1 |
| Tiago Splitter | 1 |
下面,咱们通过可视化来验证一下这个结果吧!
先看看每一个好友的共同好友 (f:) 都是谁?
MATCH (start:player{name: "Tim Duncan"})-[:`follow`]-(f:player)-[:`follow`]-(fof:player),
(start:player)-[:`follow`]-(fof:player)
RETURN fof.player.name, collect(DISTINCT f.player.name);
结果如下:
| fof.player.name | collect(distinct f.player.name) |
|---|---|
| Boris Diaw | ["Tony Parker"] |
| Manu Ginobili | ["Dejounte Murray", "Tiago Splitter", "Tony Parker"] |
| LaMarcus Aldridge | ["Tony Parker"] |
| Tiago Splitter | ["Manu Ginobili"] |
| Tony Parker | ["Dejounte Murray", "Boris Diaw", "Manu Ginobili", "Marco Belinelli", "LaMarcus Aldridge"] |
| Dejounte Murray | ["Danny Green", "Tony Parker", "Manu Ginobili", "Marco Belinelli"] |
| Danny Green | ["Dejounte Murray", "Marco Belinelli"] |
| Marco Belinelli | ["Dejounte Murray", "Danny Green", "Tony Parker"] |
下面,我们上可视化工具——NebulaGraph Explorer 搞一搞这个结果:
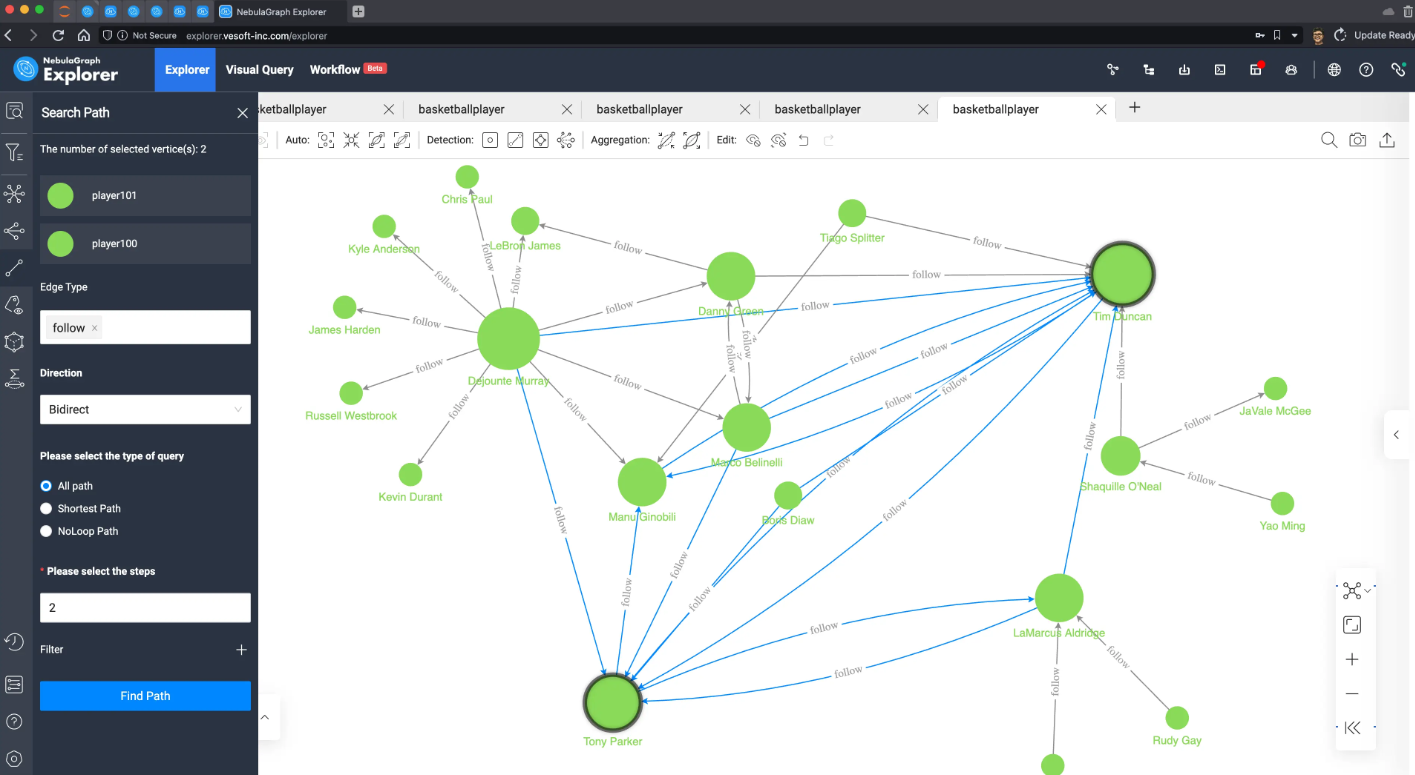
首先,我们把 Tim 的两度好友路径全查出来
MATCH p=(start:player{name: "Tim Duncan"})-[:`follow`]-(f:player)-[:follow]-(fof:player)
RETURN p
再按照出入度去渲染节点大小,并选中 Tim 和 Tony,并在两者之间查询 follow 类型边、双向、最多 2 跳的全部路径:
可以看出 Tim 和 Tony 是最亲密的朋友没跑了,而且他们的共同好友也在路径之中:
["Dejounte Murray", "Boris Diaw", "Manu Ginobili", "Marco Belinelli", "LaMarcus Aldridge"]
朋友圈子里的小群体
上面提过由于这份数据集非真实,使得社区发现算法的结果不能得到其中洞察的内涵。现在我们可以接着这个小的子图,来看看 Tim 的好友中可以如何区分群组、社区呢?
咱们先跑一个 Louvain 、弱联通分量、标签传播看看:
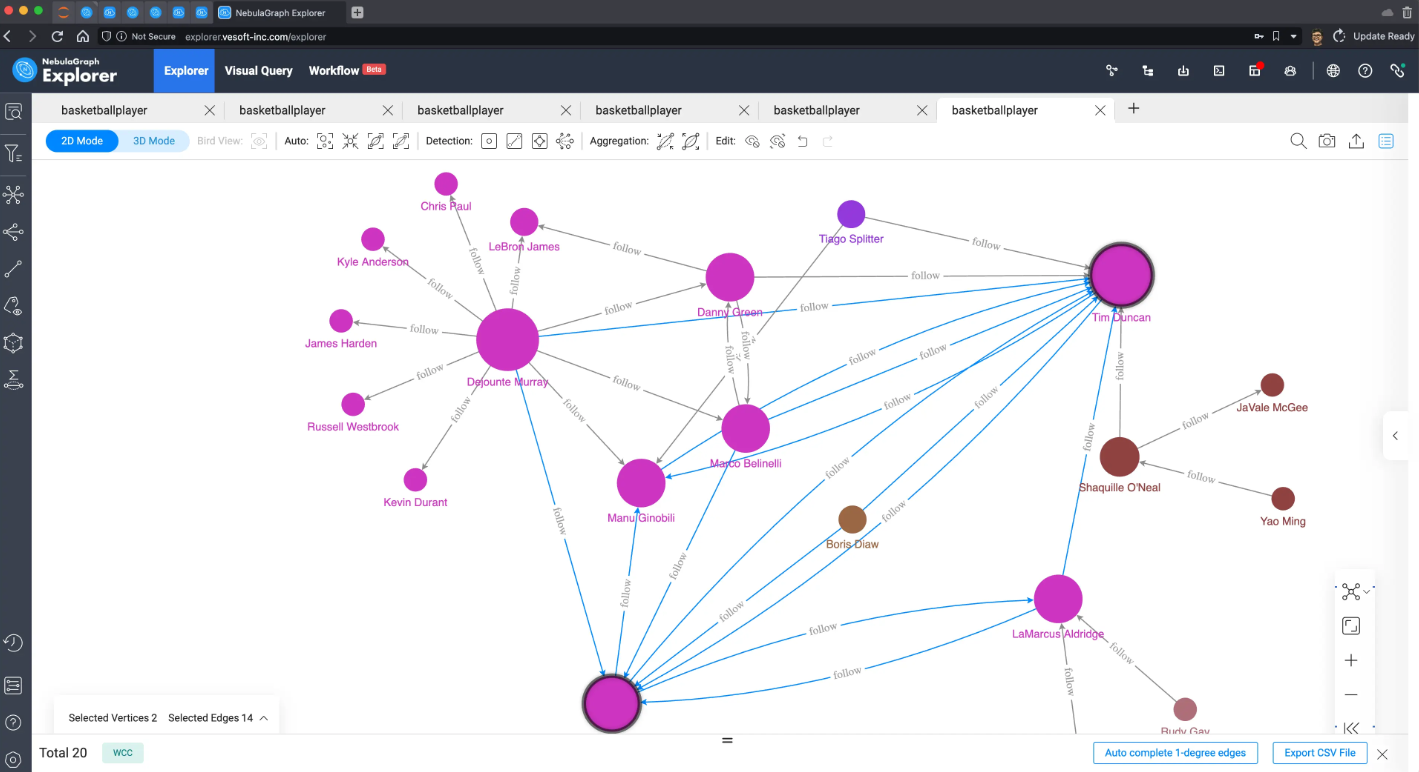
弱联通分量
弱联通分量,可以把 Tim 的朋友们大体分割出两、三个相互不连通的部分,非常符合连通分量的直观理解和定义。
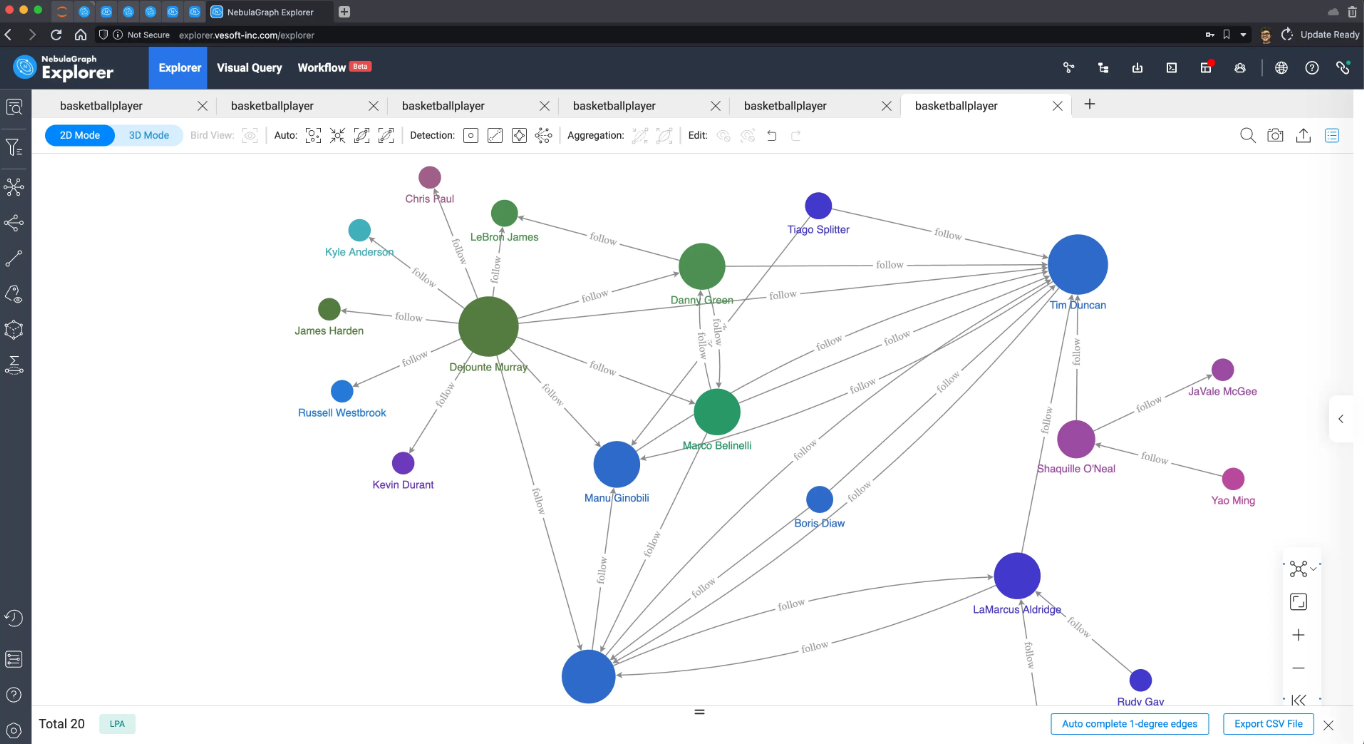
标签传播
标签传播,我们可以通过控制迭代次数按需去通过随机的传播划定出不同的划分度,结果可以有一定的区分度:
这是 20 次迭代的图:
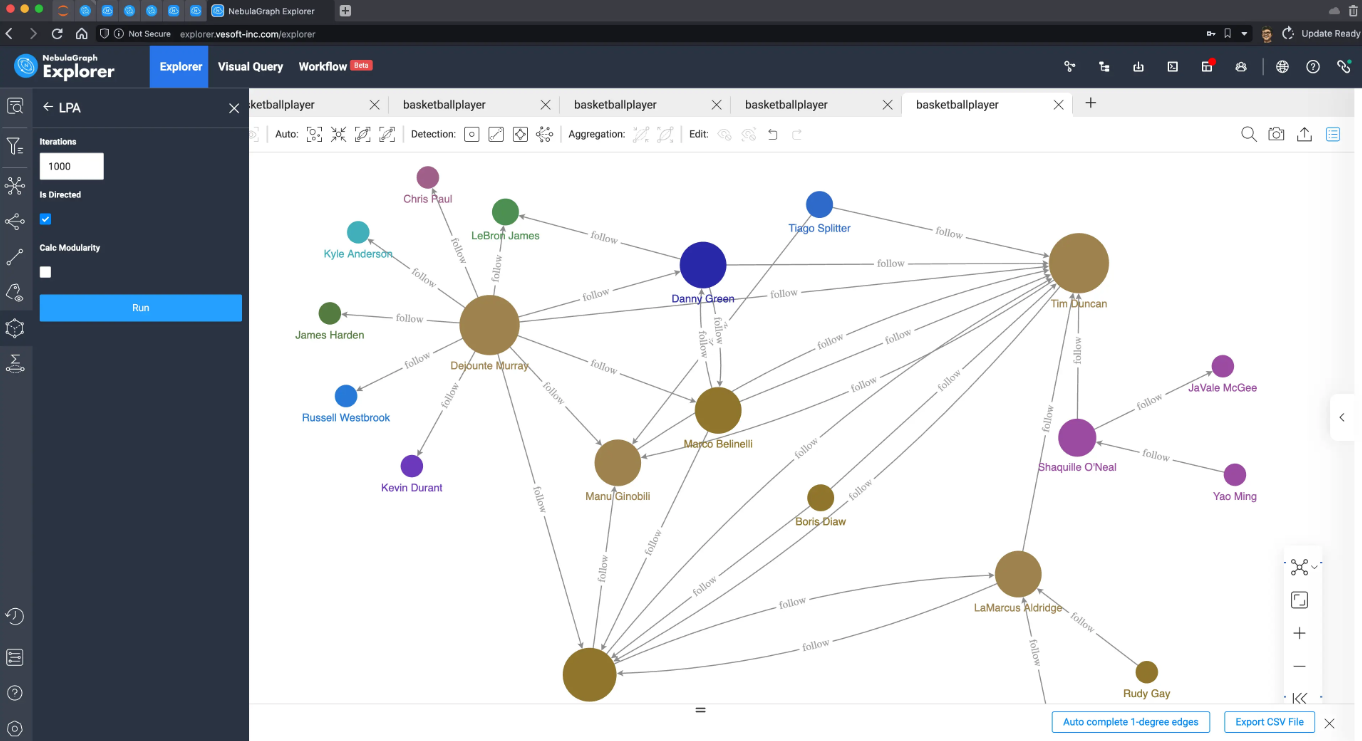
这是 1,000 次迭代
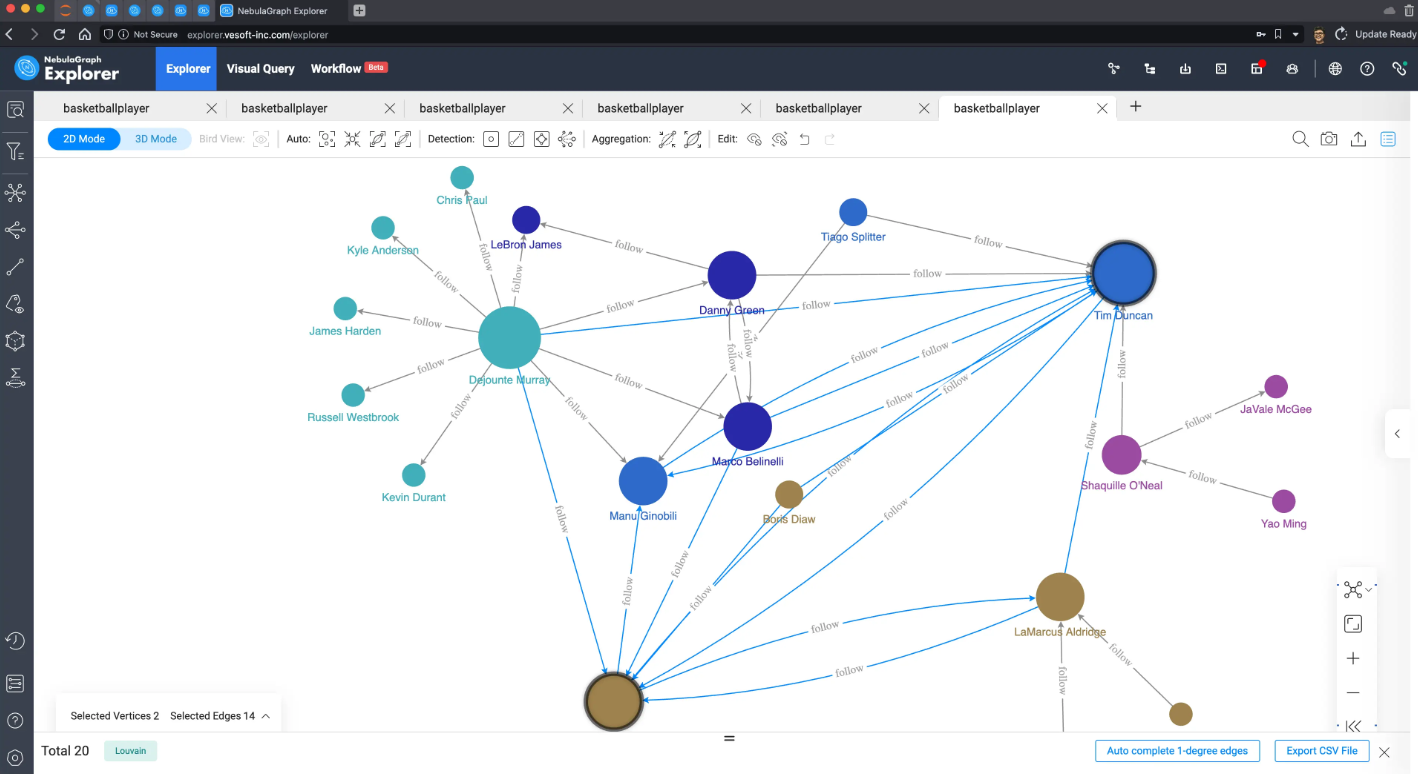
Louvain
Louvain,是一个比较高效、稳定的算法,基本上在这个子图下我们可以在很小的迭代次数下得到很符合直觉的划分:
新朋友推荐
接着前面两度朋友(朋友的朋友)的思路,我们可以很容易把那些还不是朋友的两度朋友作为推荐添加的好友,而排序规则是他们之间的共同好友数量:
MATCH (start:player{name: "Tim Duncan"})-[:`follow`]-(f:player)-[:`follow`]-(fof:player)
WHERE NOT (start:player)-[:`follow`]-(fof:player) AND fof != start
RETURN fof.player.name, count(DISTINCT f) AS NrOfMutualF ORDER BY NrOfMutualF DESC;
| fof.player.name | NrOfMutualF |
|---|---|
| LeBron James | 2 |
| James Harden | 1 |
| Chris Paul | 1 |
| Yao Ming | 1 |
| Damian Lillard | 1 |
| JaVale McGee | 1 |
| Kevin Durant | 1 |
| Kyle Anderson | 1 |
| Rudy Gay | 1 |
| Russell Westbrook | 1 |
显然,LeBron 最值得推荐!再看看这些共同好友都是谁?
| fof.player.name | collect(distinct f.player.name) |
|---|---|
| James Harden | ["Dejounte Murray"] |
| LeBron James | ["Danny Green", "Dejounte Murray"] |
| Chris Paul | ["Dejounte Murray"] |
| Yao Ming | ["Shaquille O'Neal"] |
| Damian Lillard | ["LaMarcus Aldridge"] |
| JaVale McGee | ["Shaquille O'Neal"] |
| Kevin Durant | ["Dejounte Murray"] |
| Kyle Anderson | ["Dejounte Murray"] |
| Rudy Gay | ["LaMarcus Aldridge"] |
| Russell Westbrook | ["Dejounte Murray"] |
同样,我们在刚才的子图里找找 LeBron James 吧!我们把他俩之间的两步、双向路径找出来,果然只会经过 ["Danny Green", "Dejounte Murray"] 并且,没有直接的连接:
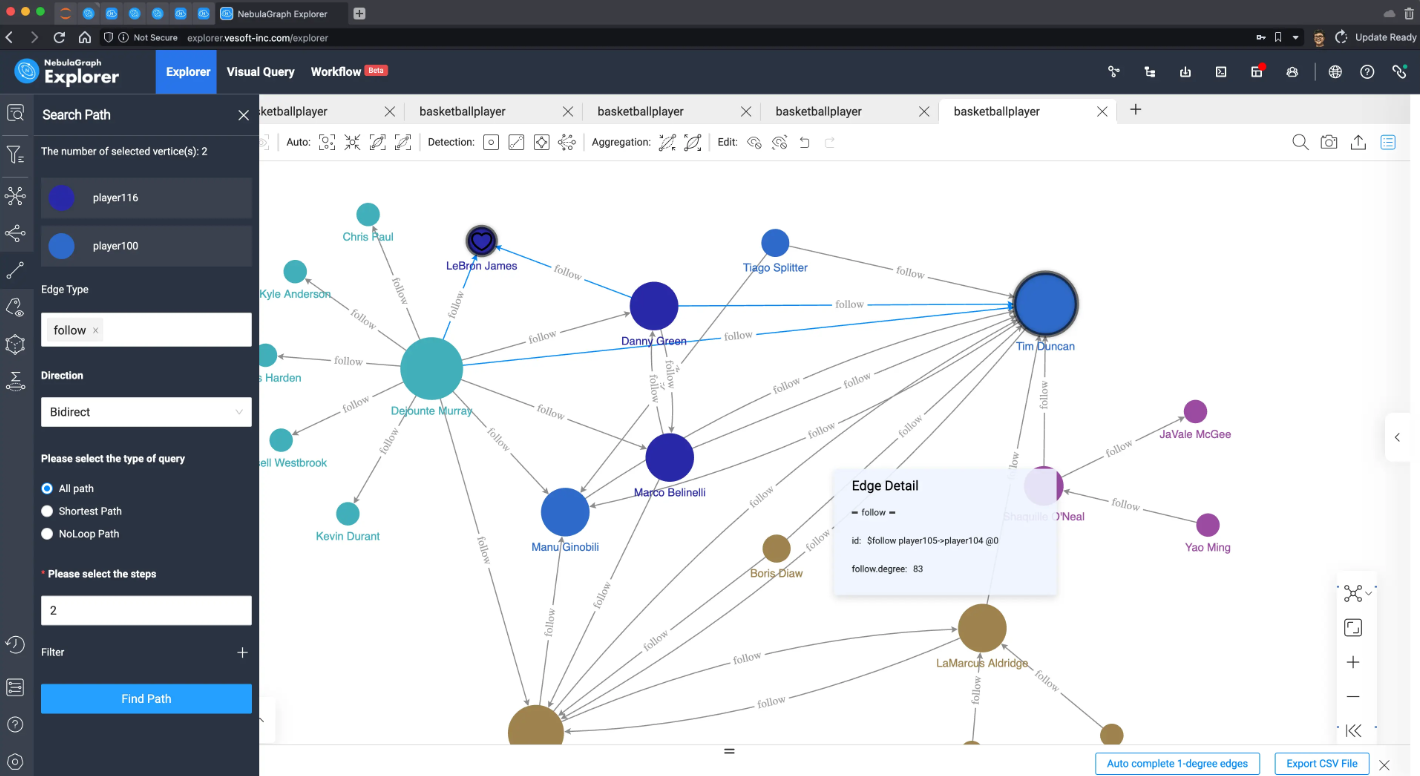
现在,系统应该给两边发提醒:“hey,也许你们应该交个朋友!”
共同邻居
查找共同邻居是一个很常见的图查询,它的场景可能根据不同的邻居关系、节点类型,同构、异构,带来不同的场景。前面两个场景的共同好友本质上是两点之间的共同邻居,直接查询这样的关系用 openCypher 的表达非常简单。
两点之间的共同邻居
这个表达可以查询两个用户之间的共性、交集,结果可能是共同团队、去过的地方、兴趣爱好、共同参与的帖子回复等等:
MATCH p = (`v0`)--()--(`v1`)
WHERE id(`v0`) == "player100" AND id(`v1`) == "player104"
RETURN p
而限定了边的类型之后,这个查询就限定在共同好友的查询了。
MATCH p = (v0)--(:`follow`)--(v1)
WHERE id(v0) == "player100" AND id(v1) == "player104"
RETURN p
多点之间的共同邻居:内容推送
下面,我们给出一个多点共同邻居的场景:我们从一个文章出发,查出所有在这个文章上有互动的用户,找到这一群体中的共同邻居。
这个共同邻居有什么用处呢?很自然,如果这个共同邻居还没有和这个文章有任何交互,我们可以把这个文章推荐给他。
这个查询的实现很有意思:
- 第一个
MATCH是查到所有 post11 文章下留言、点赞之类的同作者交互的总人数 - 第二个
MATCH里我们查询这群人的一度好友中哪些人同互动用户的共同好友数量刚好等于文章互动人数,即这些所有参与互动的用户的共同好友。
MATCH (blog:post)<-[e]-(:player) WHERE id(blog) == "post11"
WITH blog, count(e) AS invoved_user_count
MATCH (blog:post)<-[]-(users:player)-[:`follow`]-(common_neighbor:player)
WITH toSet(collect(users)) AS users, common_neighbor, invoved_user_count
WHERE size(users) == invoved_user_count
RETURN common_neighbor
而这个人就是...Tony!
+-----------------------------------------------------+
| common_neighbor |
+-----------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+-----------------------------------------------------+
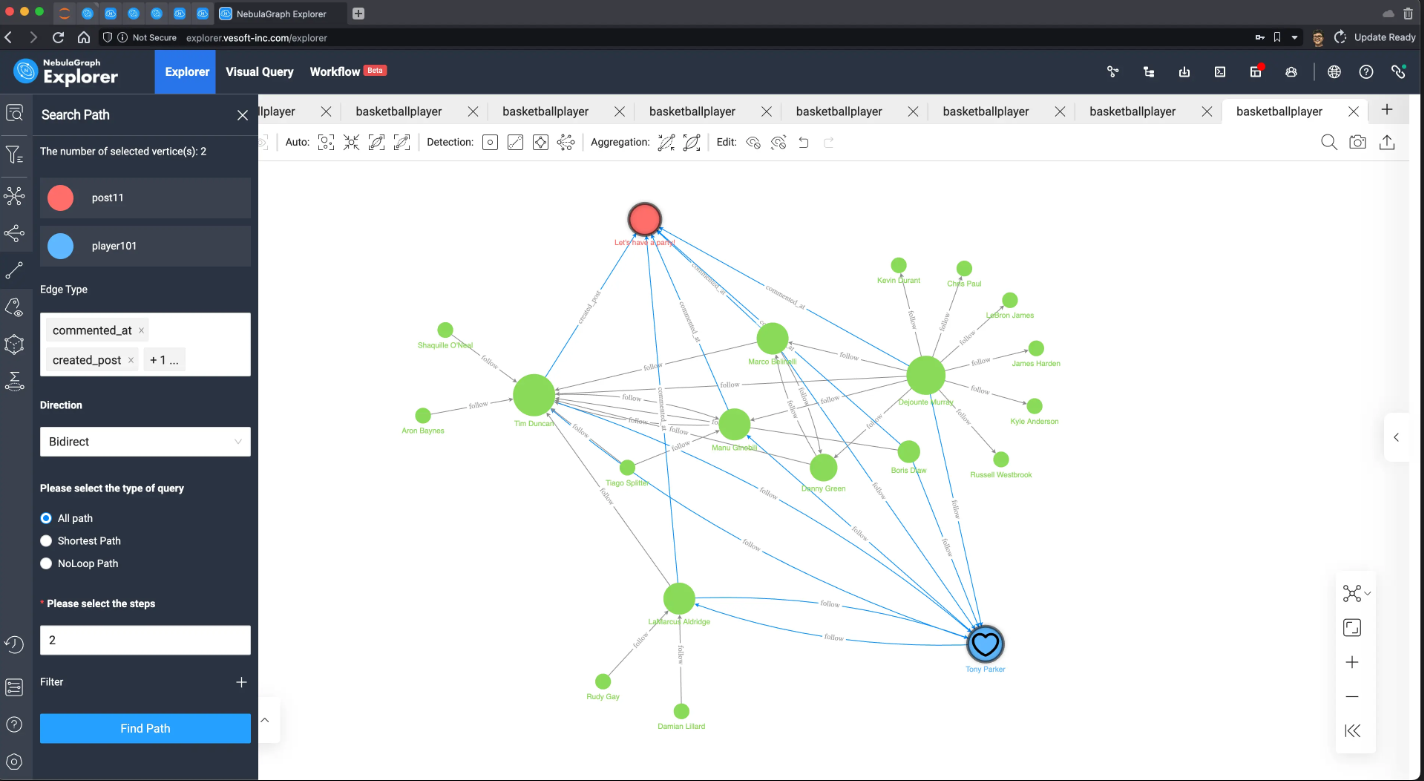
而我们可以很容易在可视化中验证它:
MATCH p=(blog:post)<-[]-(users:player)-[:`follow`]-(common_neighbor:player)
WHERE id(blog) == "post11"
RETURN p
渲染这个查询结果,再在这篇叫做 "Let's have a party!" 的文章与 Tony 之间查找评论、发帖、关注三类边的双向、两跳查询,就可以看到这些参与文章的人们无一例外,都是 Tony 的好友,而只有 Tony 自己还没去文章里留言!
而 Party 怎么可以少了 Tony 呢?难道是他的惊喜生日 Party,Opps,我们是不是不应该告诉他?
信息流
我在之前写过《基于图技术的推荐系统实现方法》,其中讲述了在图谱上实现现代推荐系统中基于内容和协同的过滤,而类似的原理应用在社交网络可以实现个性推荐信息流。
好友参与的内容
最简单的信息流,可能就是朋友圈、微博 feed 上刷到的关注的人创建、参与的内容。先不考虑排序的问题,这些内容一定是:
- 一定时间段内好友创建的内容
- 一定时间段内好友评论的内容
我们可以用 Cypher 表达这个查询用户 id 为 player100 的信息流:
MATCH (feed_owner:player)-[:`follow`]-(friend:player) WHERE id(feed_owner) == "player100"
OPTIONAL MATCH (friend:player)-[newly_commented:commented_at]->(:post)<-[:created_post]-(feed_owner:player)
WHERE newly_commented.post_time > timestamp("2010-01-01 00:00:00")
OPTIONAL MATCH (friend:player)-[newly_created:created_post]->(po:post)
WHERE newly_created.post_time > timestamp("2010-01-01 00:00:00")
WITH DISTINCT friend,
collect(DISTINCT po.post.title) + collect("comment of " + dst(newly_commented))
AS feeds WHERE size(feeds) > 0
RETURN friend.player.name, feeds
| friend.player.name | feeds |
|---|---|
| Boris Diaw | ["I love you, Mom", "comment of post11"] |
| Marco Belinelli | ["my best friend, tom", "comment of post11"] |
| Danny Green | ["comment of post1"] |
| Tiago Splitter | ["comment of post1"] |
| Dejounte Murray | ["comment of post11"] |
| Tony Parker | ["I can swim"] |
| LaMarcus Aldridge | ["I hate coriander", "comment of post11", "comment of post1"] |
| Manu Ginobili | ["my best friend, jerry", "comment of post11", "comment of post11"] |
于是,我们可以把这些评论、文章呈现到用户的 feed。
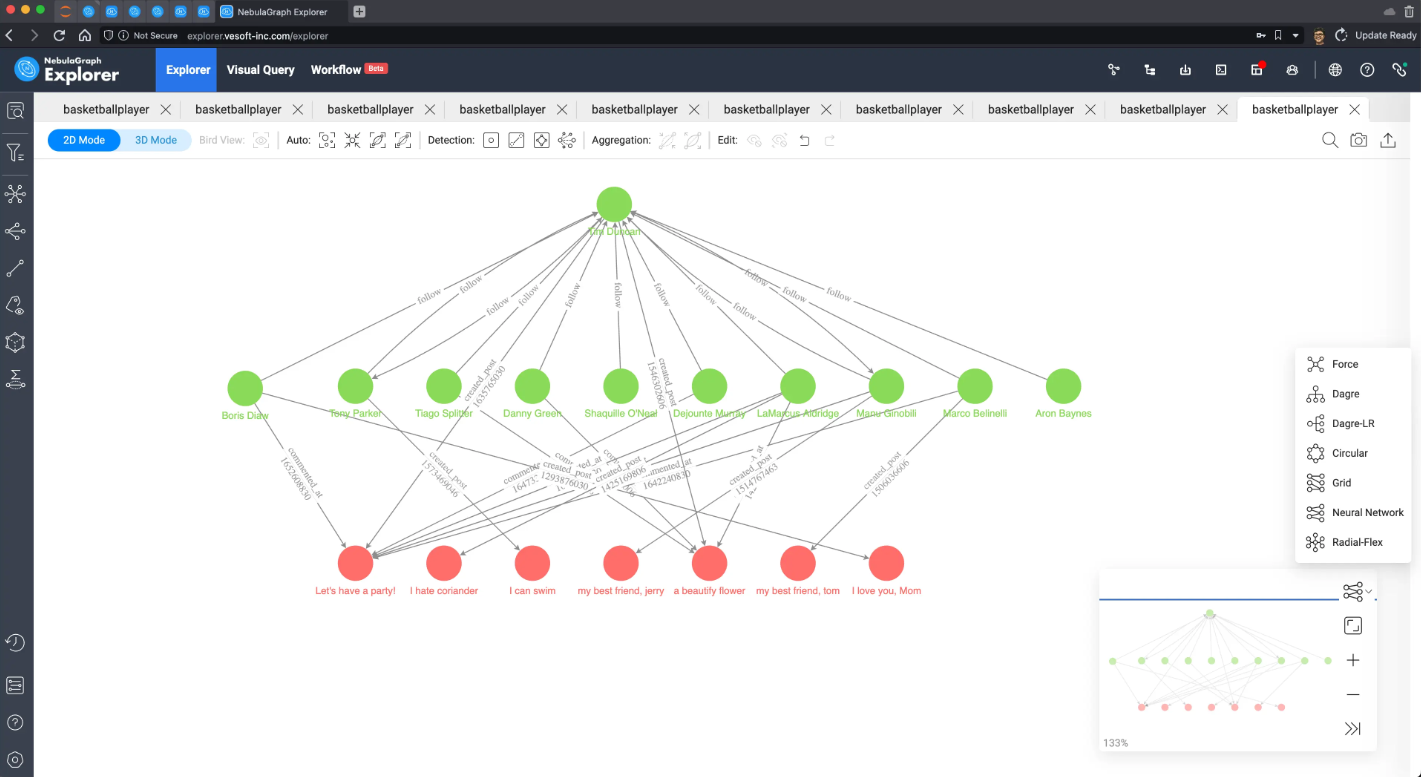
一样的,我们来看看可视化效果。输出所有查到的路径:
MATCH p=(feed_owner:player)-[:`follow`]-(friend:player) WHERE id(feed_owner) == "player100"
OPTIONAL MATCH p_comment=(friend:player)-[newly_commented:commented_at]->(:post)<-[:created_post]-(feed_owner:player)
WHERE newly_commented.post_time > timestamp("2010-01-01 00:00:00")
OPTIONAL MATCH p_post=(friend:player)-[newly_created:created_post]->(po:post)
WHERE newly_created.post_time > timestamp("2010-01-01 00:00:00")
RETURN p, p_comment, p_post
在 Explorer 上进行渲染,选择“神经网络”这个布局,可以很清晰地看出这些红色的文章节点,还有代表评论的边。
附近好友的内容
我们再进一步,把地理信息考虑进来,获取那些在指定距离范围内的朋友的相关内容。
这里,我们用到了 NebulaGraph 的 GeoSpatial 地理功能,ST_Distance(home.address.geo_point, friend_addr.address.geo_point) AS distance WHERE distance < 1000000 的约束条件帮我们表达了距离的限制。
MATCH (home:address)-[:lived_in]-(feed_owner:player)-[:`follow`]-(friend:player)-[:lived_in]-(friend_addr:address)
WHERE id(feed_owner) == "player100"
WITH feed_owner, friend, ST_Distance(home.address.geo_point, friend_addr.address.geo_point) AS distance WHERE distance < 1000000
OPTIONAL MATCH (friend:player)-[newly_commented:commented_at]->(:post)<-[:created_post]-(feed_owner:player)
WHERE newly_commented.post_time > timestamp("2010-01-01 00:00:00")
OPTIONAL MATCH (friend:player)-[newly_created:created_post]->(po:post)
WHERE newly_created.post_time > timestamp("2010-01-01 00:00:00")
WITH DISTINCT friend,
collect(DISTINCT po.post.title) + collect("comment of " + dst(newly_commented))
AS feeds WHERE size(feeds) > 0
RETURN friend.player.name, feeds
| friend.player.name | feeds |
|---|---|
| Marco Belinelli | ["my best friend, tom", "comment of post11"] |
| Tony Parker | ["I can swim"] |
| Danny Green | ["comment of post1"] |
这时候,从可视化这个结果也可以看到住址,以及它们的经纬度信息。我手动按经纬度把地址的节点在画布上进行排列(下图右侧橙色部分),可以看到这个 feed 的主人 Tim(player100) 的住址(7,8)刚好在其他好友住址的中间位置,这些邻近好友的相关的文章和参与评论的内容将被作为信息流推送给 Tim:
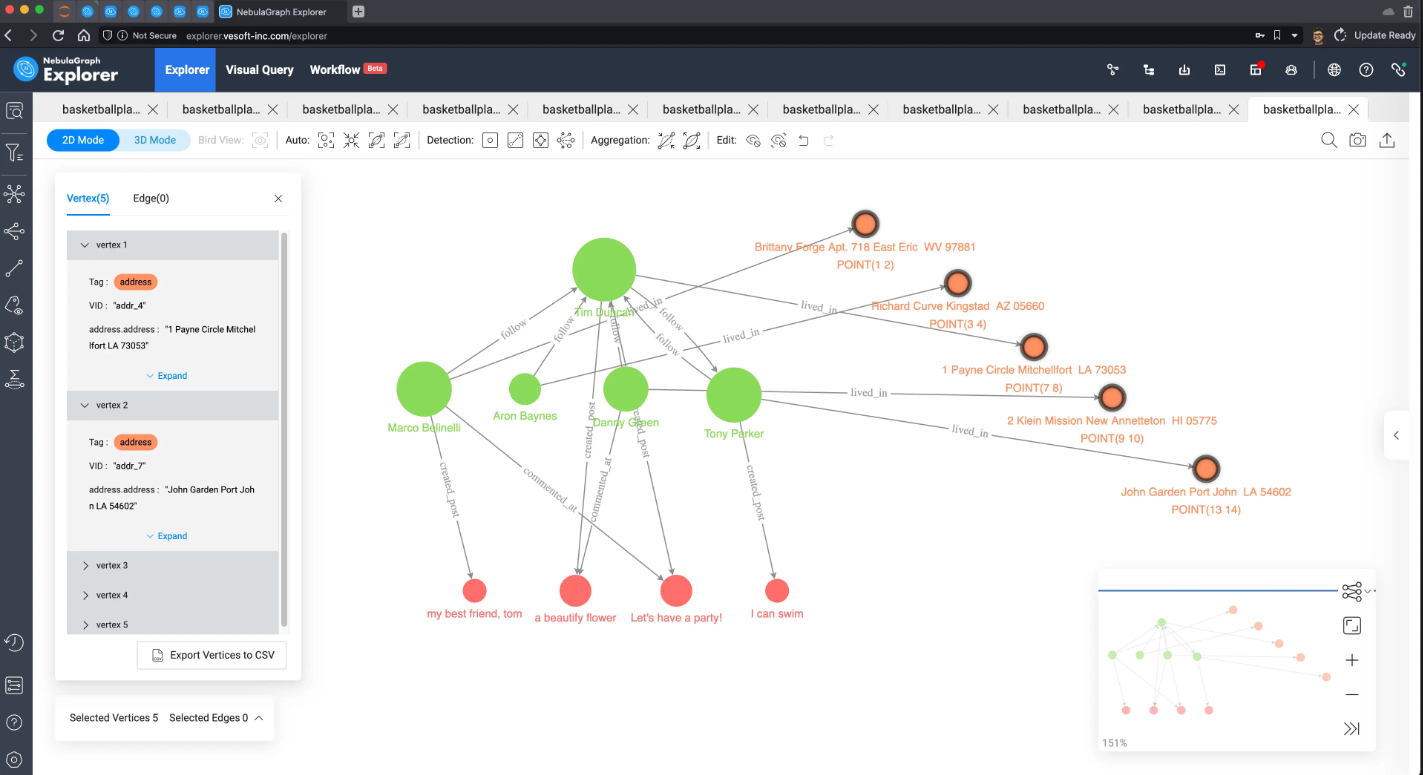
时空关系追踪
时空关系追踪,这个图谱应用是在公共安全、物流、疫情防控等场景下,利用图遍历将繁杂、凌乱的信息充分利用起来的典型应用。当我们建立起这样的图谱之后,往往只需要简单的图查询就可以获得非常有用的洞察。本章节我给大家近距离讲下这个应用场景。
数据集
我创建了一个虚拟数据集来构建时空关系图谱,数据集的生成程序和拿来即用的文件都放在了 GitHub 上,仓库地址是:https://github.com/wey-gu/covid-track-graph-datagen。
它的数据建模如下:
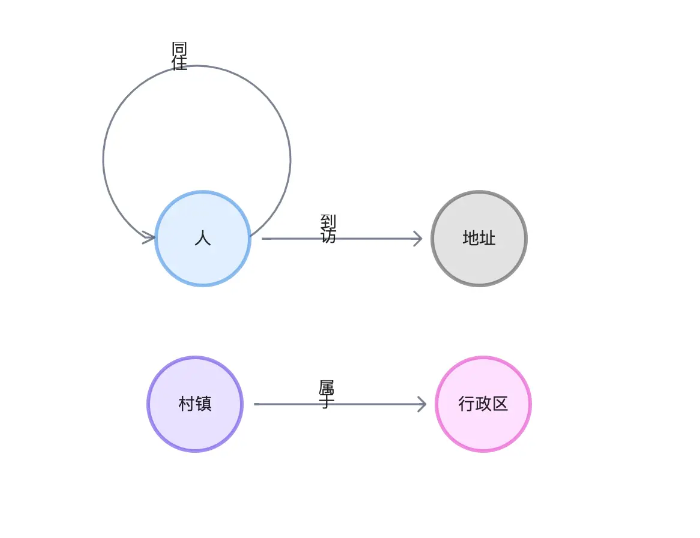
在一个全新的环境里,仅用下面的 3 行命令就能准备好这个图谱:
# 安装 NebulaGraph + NebulaGraph Studio
curl -fsSL nebula-up.siwei.io/install.sh | bash -s -- v3
# 下载数据集
git clone https://github.com/wey-gu/covid-track-graph-datagen && cd covid-track-graph-datagen
# 导入数据集
docker run --rm -ti \
--network=nebula-net \
-v ${PWD}/:/root \
vesoft/nebula-importer:v3.2.0 \
--config /root/nebula-importer-config.yaml
我们在 console 里查看一下数据:
~/.nebula-up/console.sh
# 进入 console 了,进到 covid_trace 图空间(刚才创建的)
USE covid_trace;
# 执行数据统计的任务
SHOW JOB STATS
结果:
(root@nebula) [covid_trace]> SHOW STATS
+---------+------------+--------+
| Type | Name | Count |
+---------+------------+--------+
| "Tag" | "人" | 10000 |
| "Tag" | "地址" | 1000 |
| "Tag" | "城市" | 341 |
| "Tag" | "村镇" | 42950 |
| "Tag" | "省份" | 32 |
| "Tag" | "联系方式" | 0 |
| "Tag" | "行政区" | 3134 |
| "Tag" | "街道" | 667911 |
| "Edge" | "住址" | 0 |
| "Edge" | "到访" | 19986 |
| "Edge" | "同住" | 19998 |
| "Edge" | "属于" | 715336 |
| "Space" | "vertices" | 725368 |
| "Space" | "edges" | 755320 |
+---------+------------+--------+
Got 14 rows (time spent 1087/46271 us)
两人之间的关联
很自然,利用路径查询就可以了:
# 最短
FIND SHORTEST PATH FROM "p_100" TO "p_101" OVER * BIDIRECT YIELD PATH AS paths
# 所有路径
FIND ALL PATH FROM "p_100" TO "p_101" OVER * BIDIRECT YIELD PATH AS paths | LIMIT 10
最短路径结果:
| paths |
|---|
| <("p_100")<-[:同住@0 {}]-("p_2136")<-[:同住@0 {}]-("p_3708")-[:到访@0 {}]->("a_125")<-[:到访@0 {}]-("p_101")> |
所有路径结果:
| paths |
|---|
| <("p_100")<-[:同住@0 {}]-("p_2136")<-[:同住@0 {}]-("p_3708")-[:到访@0 {}]->("a_125")<-[:到访@0 {}]-("p_101")> |
| <("p_100")-[:到访@0 {}]->("a_328")<-[:到访@0 {}]-("p_6976")<-[:同住@0 {}]-("p_261")-[:到访@0 {}]->("a_352")<-[:到访@0 {}]-("p_101")> |
| <("p_100")-[:同住@0 {}]->("p_8709")-[:同住@0 {}]->("p_9315")-[:同住@0 {}]->("p_261")-[:到访@0 {}]->("a_352")<-[:到访@0 {}]-("p_101")> |
| <("p_100")-[:到访@0 {}]->("a_328")<-[:到访@0 {}]-("p_6311")-[:同住@0 {}]->("p_3941")-[:到访@0 {}]->("a_345")<-[:到访@0 {}]-("p_101")> |
| <("p_100")-[:到访@0 {}]->("a_328")<-[:到访@0 {}]-("p_5046")-[:同住@0 {}]->("p_3993")-[:到访@0 {}]->("a_144")<-[:到访@0 {}]-("p_101")> |
| <("p_100")-[:同住@0 {}]->("p_3457")-[:到访@0 {}]->("a_199")<-[:到访@0 {}]-("p_6771")-[:到访@0 {}]->("a_458")<-[:到访@0 {}]-("p_101")> |
| <("p_100")<-[:同住@0 {}]-("p_1462")-[:到访@0 {}]->("a_922")<-[:到访@0 {}]-("p_5869")-[:到访@0 {}]->("a_345")<-[:到访@0 {}]-("p_101")> |
| <("p_100")<-[:同住@0 {}]-("p_9489")-[:到访@0 {}]->("a_985")<-[:到访@0 {}]-("p_2733")-[:到访@0 {}]->("a_458")<-[:到访@0 {}]-("p_101")> |
| <("p_100")<-[:同住@0 {}]-("p_9489")-[:到访@0 {}]->("a_905")<-[:到访@0 {}]-("p_2733")-[:到访@0 {}]->("a_458")<-[:到访@0 {}]-("p_101")> |
| <("p_100")-[:到访@0 {}]->("a_89")<-[:到访@0 {}]-("p_1333")<-[:同住@0 {}]-("p_1683")-[:到访@0 {}]->("a_345")<-[:到访@0 {}]-("p_101")> |
我们把所有路径进行可视化渲染,标记出起点、终点的两人,并在其中查到他们的最短路径。他们之间的千丝万缕关系就一目了然了,无论是商业洞察、公共安全还是疫情防控,有了这个信息,相应的工作都可以如虎添翼了。
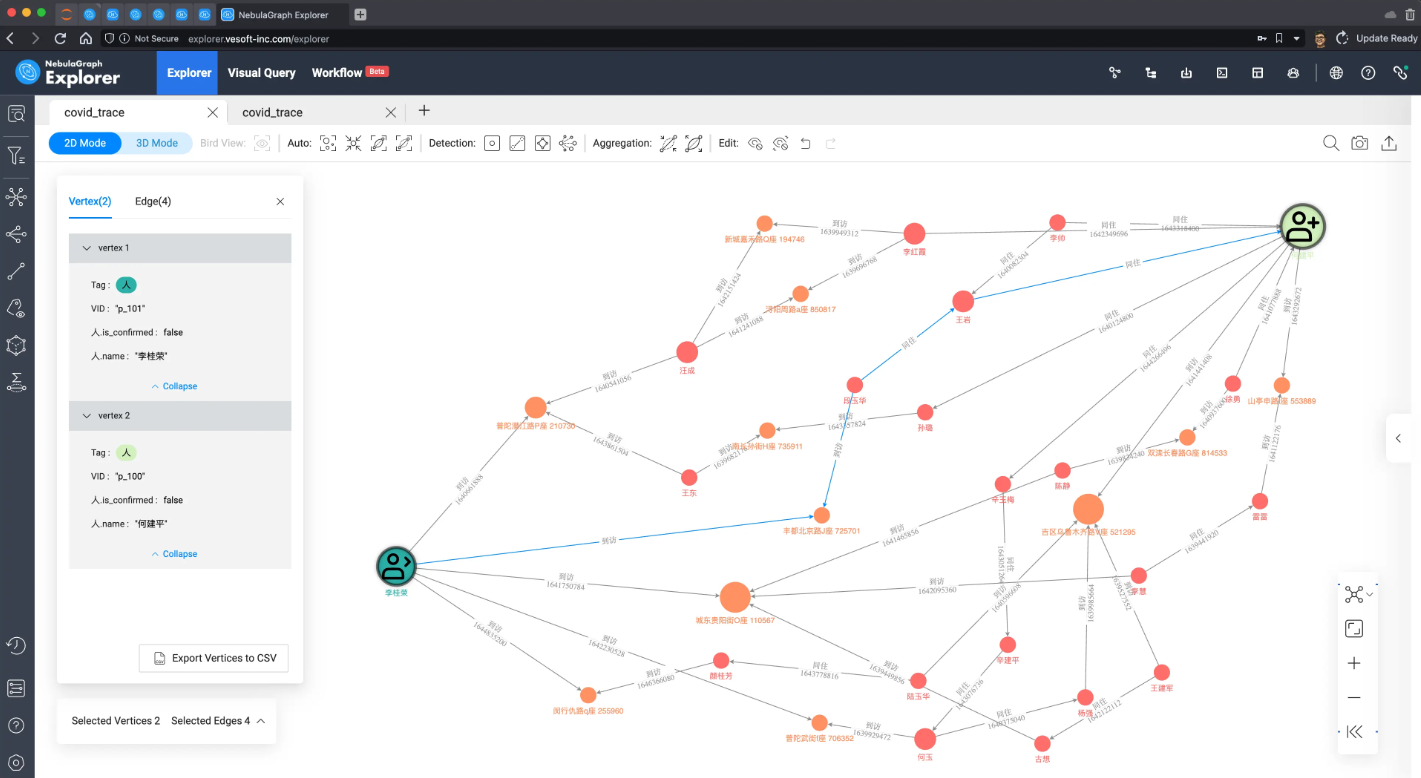
当然,在真实的系统上,可能我们只需要关心两个用户之间的关系远近,得出量化的评估:
FIND SHORTEST PATH FROM "p_100" TO "p_101" OVER * BIDIRECT YIELD PATH AS paths |
YIELD collect(length($-.paths)) AS len | YIELD coalesce($-.len[0], -1) AS len
比如,下面只关心两点之间最短路径的长度为:4。
| len |
|---|
| 4 |
时空相交的人
再深入一点,我们可以用图语义勾勒出任何带有时间与空间信息的模式,在图谱中实时查询出来。比如,找寻 id 为 p_101 的指定用户在特定时间内有时空相交的人,这意味着那些人在 p_101 访问某个地方的某段时间内也逗留过:
MATCH (p:人)-[`visit0`:到访]->(`addr`:地址)<-[`visit1`:到访]-(p1:人)
WHERE id(p) == "p_101" AND `visit0`.`start_time` < `visit1`.`end_time` AND `visit0`.`end_time` > `visit1`.`start_time`
RETURN paths;
我们得到了用户每一个到访地点,与他时空相交的人的列表。如下:
| addr.地址.name | collect(p1.人.name) |
|---|---|
| 闵行仇路q座 255960 | ["徐畅", "王佳", "曾亮", "姜桂香", "邵秀英", "韦婷婷", "陶玉", "马坤", "黄想", "张秀芳", "颜桂芳", "张洋"] |
| 丰都北京路J座 725701 | ["陈春梅", "施婷婷", "井成", "范文", "王楠", "尚明", "薛秀珍", "宋金凤", "杨雪", "邓丽华", "李杨", "温佳", "叶玉", "周明", "王桂珍", "段玉华", "金成", "黄鑫", "邬兵", "魏柳", "王兰英", "杨柳"] |
| 普陀潜江路P座 210730 | ["储平", "洪红霞", "沈玉英", "王洁", "董玉英", "邓凤英", "谢海燕", "梁雷", "张畅", "任玉兰", "贾宇", "汪成", "孙琴", "纪红梅", "王欣", "陈兵", "张成", "王东", "谷霞", "林成"] |
| 普陀武街f座 706352 | ["邢成", "张建军", "张鑫", "戴涛", "蔡洋", "汪燕", "尹亮", "何利", "何玉", "周波", "金秀珍", "杨波", "张帅", "周柳", "马云", "张建华", "王丽丽", "陈丽", "万萍"] |
| 城东贵阳街O座 110567 | ["李洁", "陈静", "王建国", "方淑华", "古想", "漆萍", "詹桂花", "王成", "李慧", "孙娜", "马伟", "谢杰", "王鹏", "鞠桂英", "莫桂英", "汪雷", "黄彬", "李玉梅", "祝红梅"] |
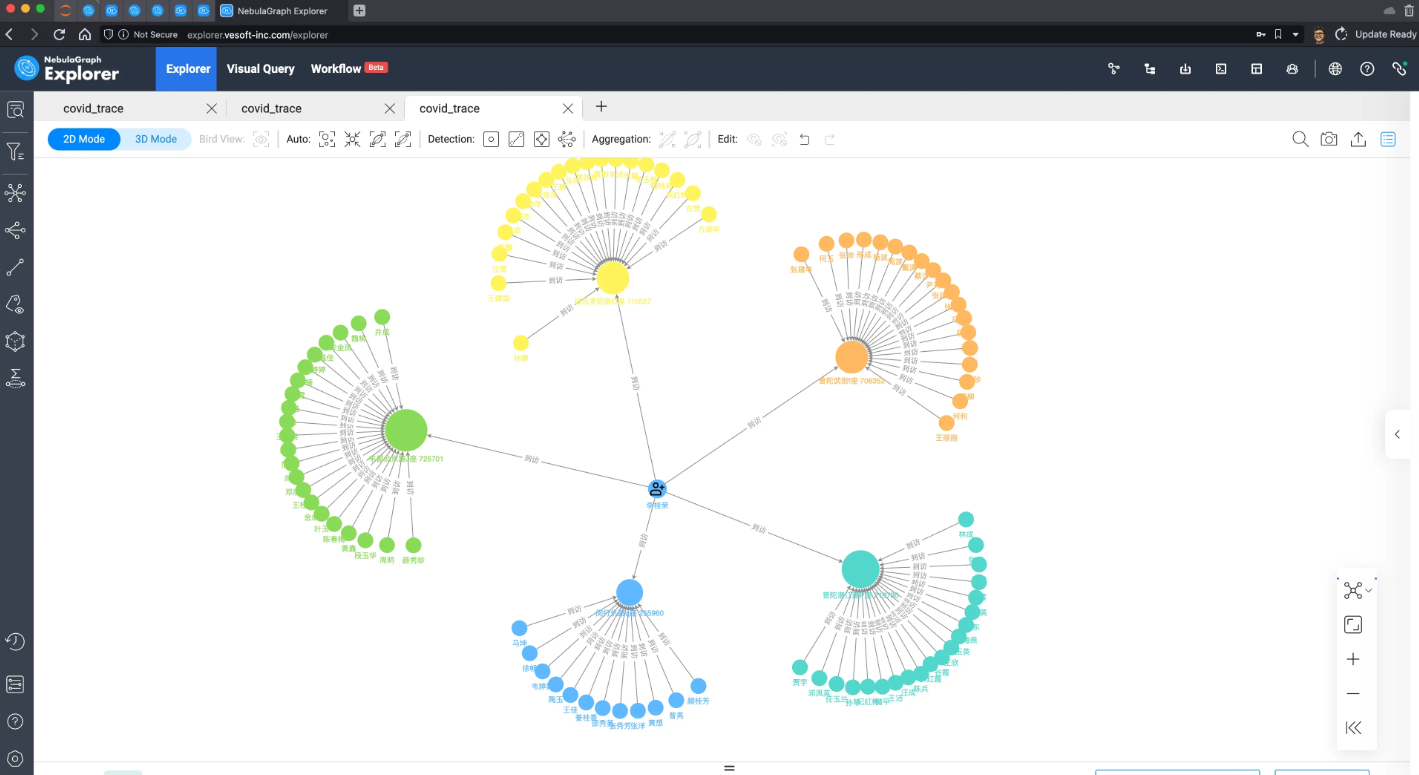
现在,我们在图上可视化这个结果看看:
MATCH (p:人)-[`visit0`:到访]->(`addr`:地址)<-[`visit1`:到访]-(p1:人)
WHERE id(p) == "p_101" AND `visit0`.`start_time` < `visit1`.`end_time` AND `visit0`.`end_time` > `visit1`.`start_time`
RETURN paths;
结果中我们标记 p_101 为不同的图标,再用标签传播算法识别一下聚集社区,是不是一图胜千言呢?
最近去过的省份
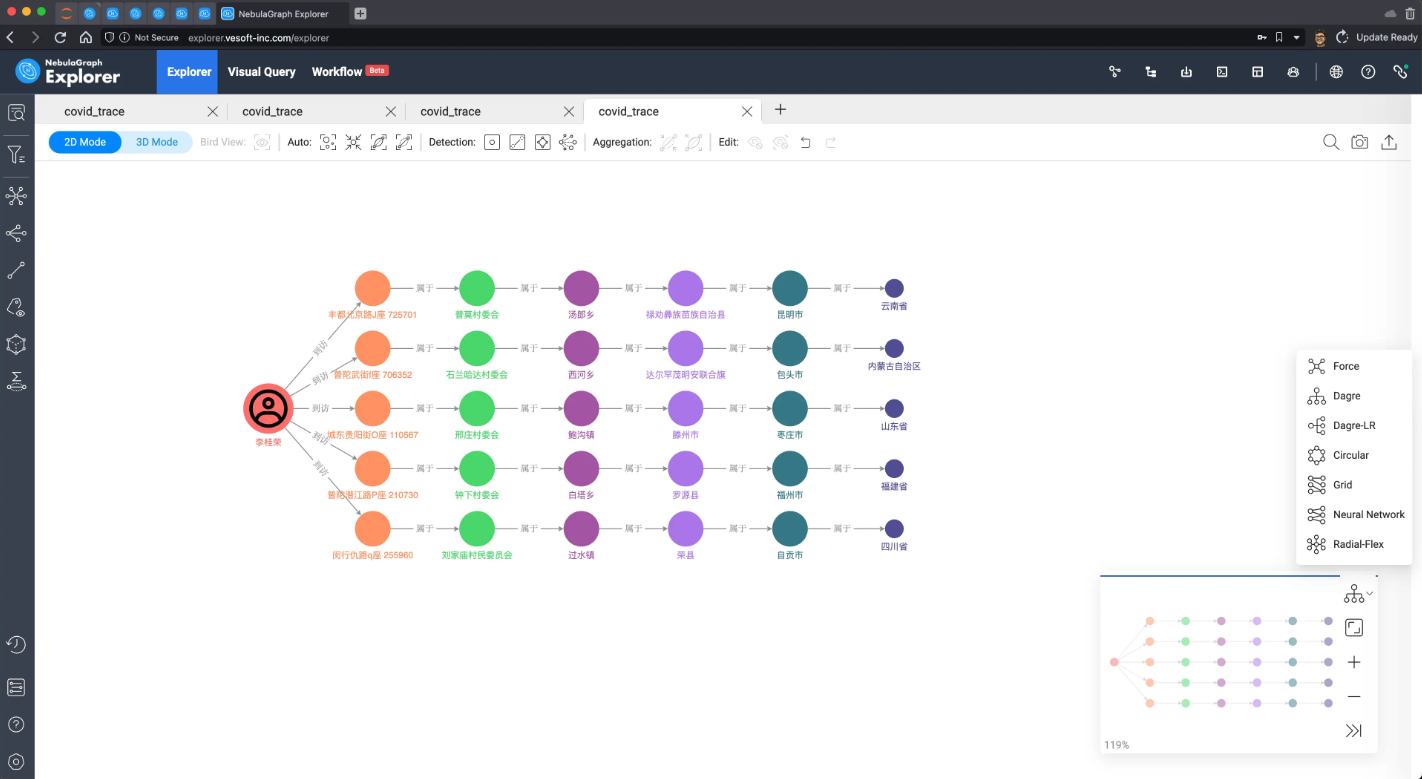
最后,我们再用简单的查询模式表达出一个人在给定时间内的行为路径。比如:从一个时间点开始,到访过的所有省份
MATCH (p:人)-[visit:到访]->(`addr`:地址)-[:属于*5]-(province:省份)
WHERE id(p) == "p_101" AND visit.start_time > 1625469000
RETURN province.省份.name, collect(addr.地址.name);
看起来他/她去过不少地方呢:
| province.省份.name | collect(addr.地址.name) |
|---|---|
| 四川省 | ["闵行仇路q座 255960"] |
| 山东省 | ["城东贵阳街O座 110567"] |
| 云南省 | ["丰都北京路J座 725701"] |
| 福建省 | ["普陀潜江路P座 210730"] |
| 内蒙古自治区 | ["普陀武街f座 706352"] |
老规矩,我们在图上看看这个结果吧。这次,我们选择 Dagre-LR 这个布局渲染,结果是不是非常清晰呢?
总结
社交网络作为天然的图结构,真的非常适合用图技术来存储、查询、计算、分析与可视化去解决各式各样的问题。NebulaGraph 强大的数据处理和可视化能力,使得它被百家企业采用来处理社交网络问题,这其中包括:网易游戏、微信、Line、Soul、快手和知乎等等很多行业领先的团队。希望大家通过本章能对社交领域的图技术应有有一个初步的认识。
谢谢你读完本文 (///▽///)
NebulaGraph Desktop,Windows 和 macOS 用户安装图数据库的绿色通道,10s 拉起搞定海量数据的图服务。通道传送门:http://c.nxw.so/c0svX
想看源码的小伙伴可以前往 GitHub 阅读、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号