在 Nebula K8s 集群中使用 nebula-spark-connector 和 nebula-algorithm

解决思路
解决 K8s 部署 Nebula Graph 集群后连接不上集群问题最方便的方法是将 nebula-algorithm / nebula-spark 运行在与 nebula-operator 相同的网络命名空间里,将 show hosts meta 的 MetaD 域名:端口 格式的地址填进配置里就可以了。
注:这里需要 2.6.2 或者更新的版本,nebula-spark-connector / nebula-algorithm 才支持域名形式的 MetaD 地址。
这里来具体实操下网络配置:
- 获取 MetaD 地址
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 08:22:33 UTC
这里需要记录 Host 名以便后续的配置文件中使用该名称。
- 填写 nebula-algorithm 的配置文件
参考文档 https://github.com/vesoft-inc/nebula-algorithm/blob/master/nebula-algorithm/src/main/resources/application.conf。填写配置文件有两种方法:修改 TOML 文件或者在 nebula-spark-connector 代码中添加配置信息。
方法一:修改 TOML 文件
# ...
nebula: {
# algo's data source from Nebula. If data.source is nebula, then this nebula.read config can be valid.
read: {
# 这里填上刚获得到的 meta 的 Host 名,多个地址的话用英文字符下的逗号隔开;
metaAddress: "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559"
#...
方法二:调用 nebula-spark-connector 的代码
val config = NebulaConnectionConfig
.builder()
// 这里填上刚获得到的 meta 的 Host 名
.withMetaAddress("nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("foo_bar_space")
.withLabel("person")
.withNoColumn(false)
.withReturnCols(List("birthday"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
好的,到现在为止,过程看起来非常简单。那么,为什么这么简单的过程却值得一篇文章呢?
配置信息容易忽略的问题
刚才我们讲了具体的实际操作,但当中有一些理论小知识在这里:
a. MetaD 隐含地需要保证 StorageD 的地址能被 Spark 环境访问;
b. StorageD 地址是从 MetaD 获取的;
c. Nebula K8s Operator 里,MetaD 中存储的 StorageD 地址(服务发现)的来源是 StorageD 的配置文件,而它是 K8s 的内部地址。
背景知识
a. 的理由比较直接,和 Nebula 的架构有关:图的数据都存在 Storage Service 之中,通常用语句的查询是透过 Graph Service 来透传,只需要 GraphD 的连接就足够,而 nebula-spark-connector 使用 Nebula Graph 的场景是扫描全图或者子图,这时候计算存储分离的设计使得我们可以绕过查询、计算层直接高效读取图数据。
那么问题来了,为什么需要且只要 MetaD 的地址呢?
这也是和架构有关,Meta Service 里包含了全图的分布数据与分布式的 Storage Service 的各个分片和实例的分布,所以一方面因为只有 Meta 才有全图的信息(需要),另一方面因为从 Meta 可以获得这部分信息(只要)。到这里 b. 的答案也有了。
- 详细的 Nebula Graph 架构信息可以参考架构三部曲系列
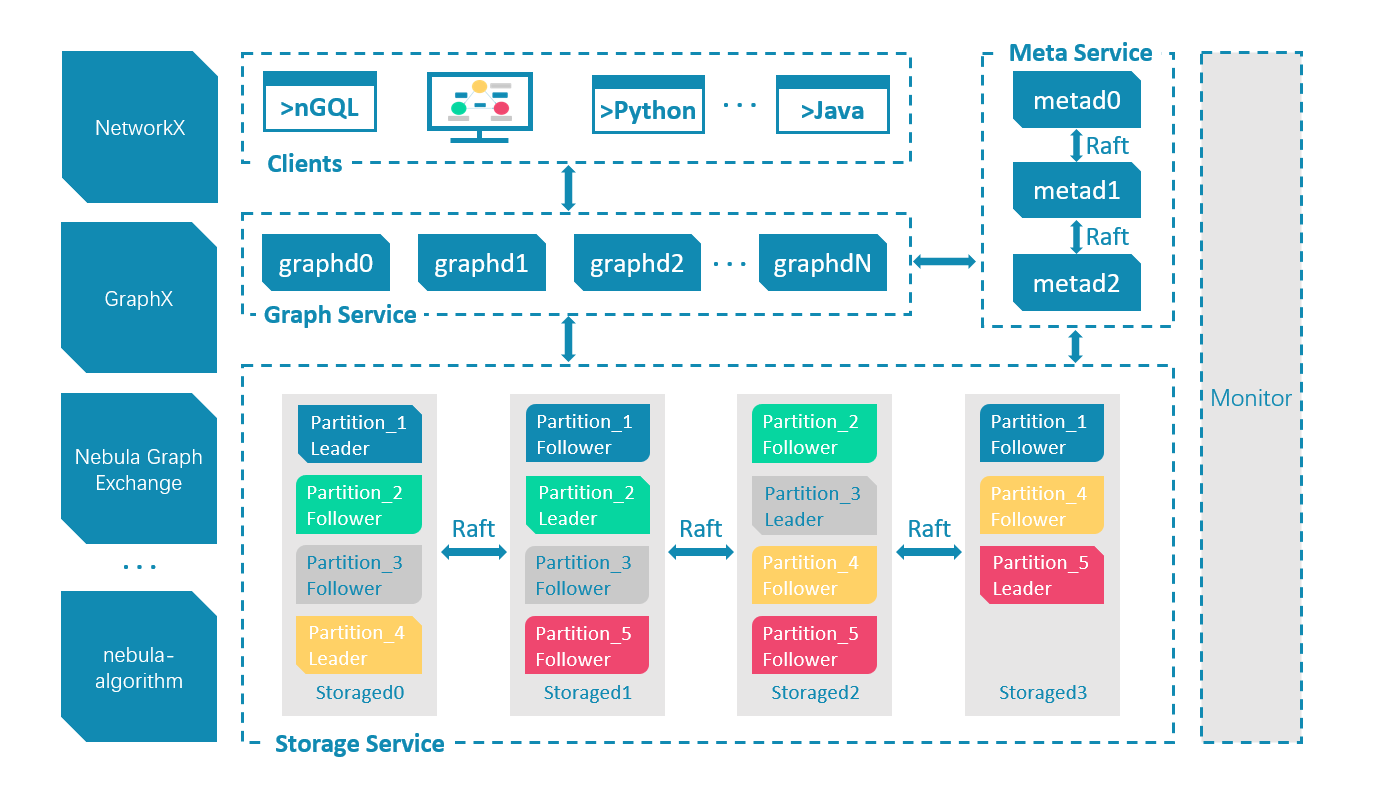
下面我们看看 c. 背后的逻辑:
c. Nebula K8s Operator 里,MetaD 中存储的 StorageD 地址(服务发现)的来源是 StorageD 的配置文件,而它是 k8s 的内部地址。
这和 Nebula Graph 里的服务发现机制有关:在 Nebula Graph 集群中,Graph Service 和 Storage Service 都是通过心跳将自己的信息上报给 Meta Service 的,而这其中服务自身的地址的来源则来自于他们相应的配置文件中的网络配置。
-
关于服务自身的地址配置请参考文档:Storage networking 配置
-
关于服务发现详细的信息请参考四王的文章:图数据库 Nebula Graph 集群通信:从心跳说起。

最后,我们知道 Nebula Operator 是一个在 K8s 集群中按照配置,自动创建、维护、扩缩容 Nebula 集群的 K8s 控制面的应用,它需要抽象一部分内部资源相关的配置,这就包括了 GraphD 和 StorageD 实例的实际地址,他们是被配置的地址实际上是 headless service 地址。
而这些地址(如下)默认是没法被 K8s 外部网络访问的,所以针对 GraphD、MetaD 我们可以方便创建服务将其暴露出来。
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 09:22:33 UTC
(root@nebula) [(none)]> show hosts graph
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| "nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local" | 9669 | "ONLINE" | "GRAPH" | "d113f4a" | "2.6.2" |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
Got 1 rows (time spent 2072/3403 us)
Mon, 14 Feb 2022 10:03:58 UTC
(root@nebula) [(none)]> show hosts storage
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| "nebula-storaged-0.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-1.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-2.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
Got 3 rows (time spent 1603/2979 us)
Mon, 14 Feb 2022 10:05:24 UTC
然而,因为前边提到的 nebula-spark-connector 通过 Meta Service 去获取 StorageD 的地址,且这个地址是服务发现而得,所以 nebula-spark-connector 实际上获取的 StorageD 地址就是上边的这种 headless 的服务地址,没法直接从外部访问。
所以,我们在有条件的情况下,只需要让 Spark 运行在和 Nebula Cluster 相同的 K8s 网络里,一切就迎刃而解了,否则,我们需要:
-
将 MetaD 和 StorageD 的地址利用 Ingress 等方式将其 L4(TCP)暴露出来。
可以参考 Nebula Operator 的文档:https://github.com/vesoft-inc/nebula-operator
-
通过反向代理和DNS让这些 headless 服务能被解析到相应的 StorageD。
那么,有没有更方便的方式?
非常抱歉的是,目前最方便的方式依然是如文章最开头所介绍:让 Spark 运行在 Nebula Cluster 内部。实际上,我在努力推进 Nebula Spark 社区去支持可以配置的 StorageAddresses 选项,有了它之后,前边提到的 2. 就是不必要的了。
更便捷的 nebula-algorithm + nebula-operator 体验
为了方便在 K8s 上尝鲜 nebula-graph、nebula-algorithm 的同学,这里安利下本人写的一个小工具 Neubla-Operator-KinD,它是个一键在 Docker 环境内部单独部署一个 K8s 集群,并在其中部署 Nebula Operator 以及所有依赖(包括 storage provider)的小工具。不仅如此,它还会自动部署一个小的 Nebula 集群。可以看下边的步骤哈:
第一步,部署 K8s + nebula-operator + Nebula Cluster:
curl -sL nebula-kind.siwei.io/install.sh | bash
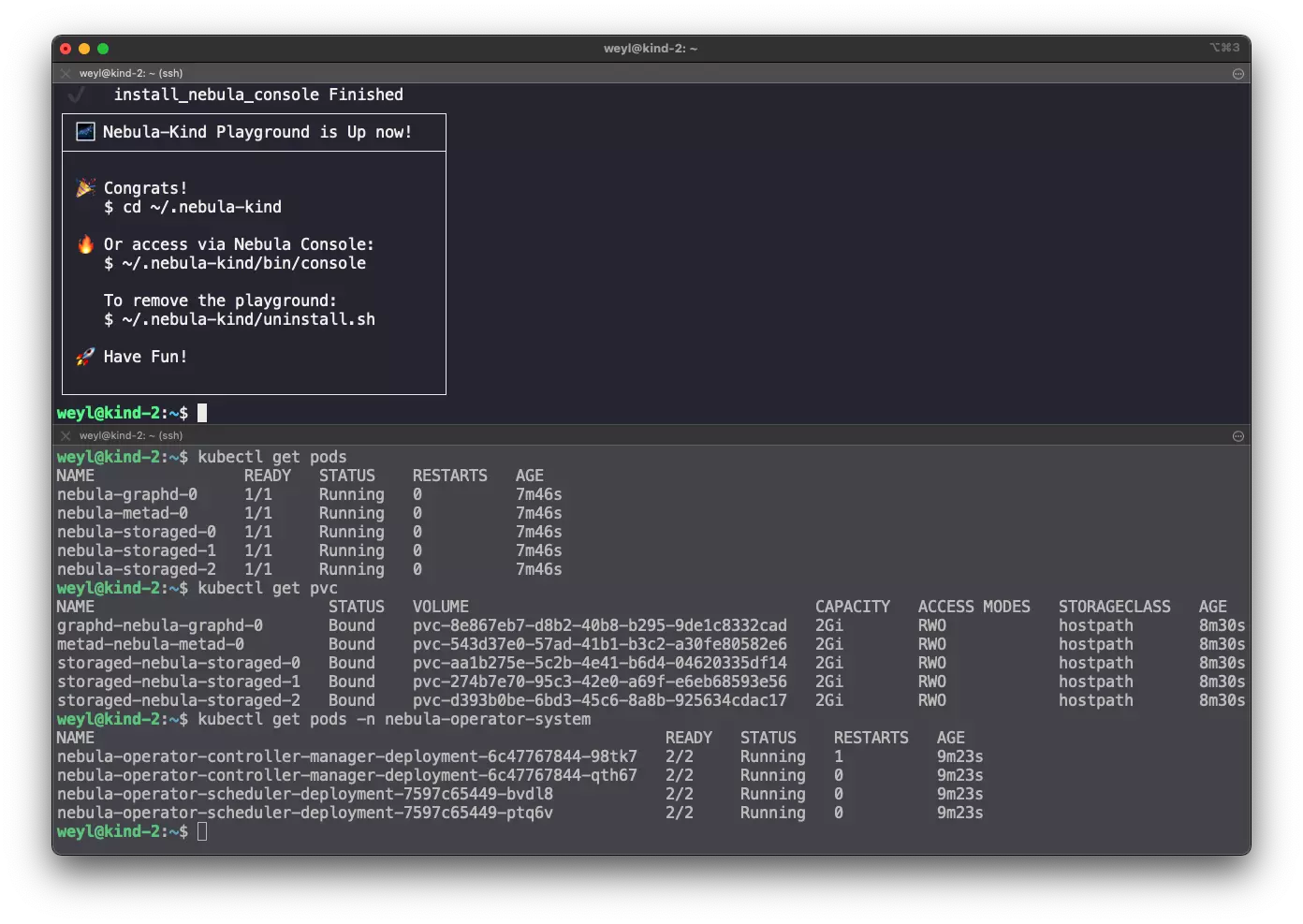
第二步,照着工具文档里的 what's next
a. 用 console 连接集群,并加载示例数据集
- 创建一个 Spark 环境
kubectl create -f http://nebula-kind.siwei.io/deployment/spark.yaml
kubectl wait pod --timeout=-1s --for=condition=Ready -l '!job-name'
- 等上边的 wait 都 ready 之后,进入 spark 的 pod。
kubectl exec -it deploy/spark-deployment -- bash
- 下载 nebula-algorithm 比如
2.6.2这个版本,更多版本请参考 https://github.com/vesoft-inc/nebula-algorithm/。
注意事项:
- 官方发布的版本在这里可以获取:https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/
- 因为这个问题:https://github.com/vesoft-inc/nebula-algorithm/issues/42 只有
2.6.2或者更新的版本才支持域名访问 MetaD。
# 下载 nebula-algorithm-2.6.2.jar
wget https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/2.6.2/nebula-algorithm-2.6.2.jar
# 下载 nebula-algorthm 配置文件
wget https://github.com/vesoft-inc/nebula-algorithm/raw/v2.6/nebula-algorithm/src/main/resources/application.conf
- 修改 nebula-algorithm 中的 mete 和 graph 地址信息。
sed -i '/^ metaAddress/c\ metaAddress: \"nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559\"' application.conf
sed -i '/^ graphAddress/c\ graphAddress: \"nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local:9669\"' application.conf
##### change space
sed -i '/^ space/c\ space: basketballplayer' application.conf
##### read data from nebula graph
sed -i '/^ source/c\ source: nebula' application.conf
##### execute algorithm: labelpropagation
sed -i '/^ executeAlgo/c\ executeAlgo: labelpropagation' application.conf
- 在 basketballplayer 图空间执行 LPA 算法
/spark/bin/spark-submit --master "local" --conf spark.rpc.askTimeout=6000s \
--class com.vesoft.nebula.algorithm.Main \
nebula-algorithm-2.6.2.jar \
-p application.conf
- 结果如下:
bash-5.0# ls /tmp/count/
_SUCCESS part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
bash-5.0# head /tmp/count/part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
_id,lpa
1100,1104
2200,2200
2201,2201
1101,1104
2202,2202
下面,你就可以 Happy Graphing 啦!
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号