

Nebula 在 Akulaku 智能风控的实践:图模型的训练与部署
本文整理自 Akulaku 反欺诈团队在 nMeetup·深圳场的演讲,B站视频见:https://www.bilibili.com/video/BV1nQ4y1B7Qd

这次主要来介绍下 Nebula 在 Akulaku 智能风控的实践。分为以下 6 个部分内容:
- 图的基本概念与应用场景概述
- 图数据库选型
- 图数据库平台建设
- Nebula 应用案例
- 图模型的训练与部署
- 总结与展望
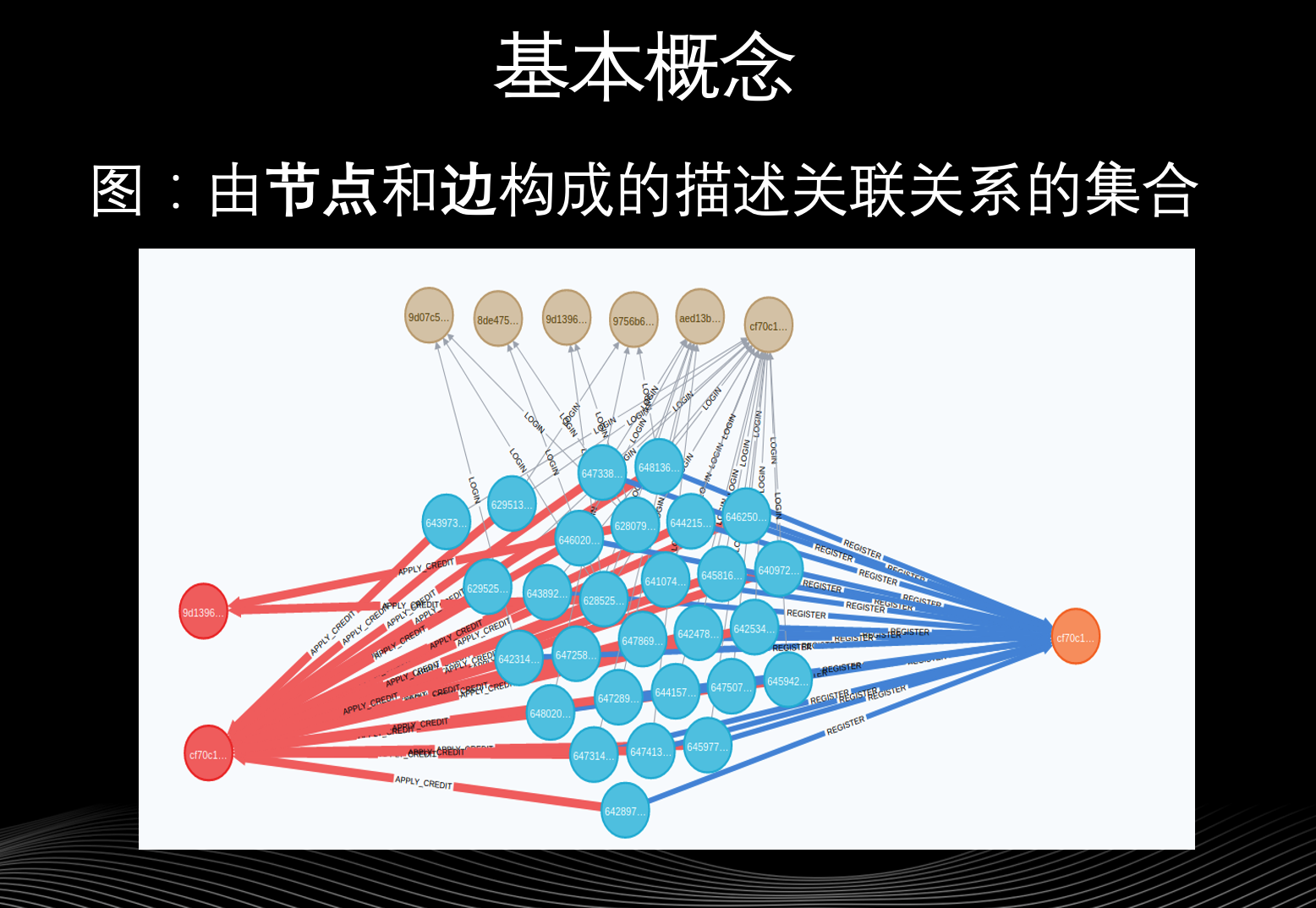
先来讲解下图的基本概念,图是由节点和边构成的描述关联关系的集合。图最大的优势就是比较形象,比如上图便是一个脱敏之后的欺诈团伙的图结构,可以看到某个用户和其他节点的关联关系是否存在异常。如果我们使用的是单纯的行式数据库(关系型数据库)是看不出来异常的,但是从图的角度就可以很容易地发现数据的异常。
再来讲解下图的应用场景,在 Akulaku 的场景中主要是图谱关系挖掘和可视化分析,以及图查询替代复杂查询。这里解释下图查询替代复杂查询,你的应用背景可能和图无关,但是涉及的后端操作具有一定的深度,用图的关系进行查询建模,就比较容易理解查询语句和维护操作。

再者是图数据库选型这块,先来讲一下 Akulaku 在图数据库选型上踩过的坑。刚开始我们使用 Neo4j,主要做一些关联性特征,Neo4j 查询效率较高但是可扩展性是短板,分布式的 Neo4j 性能和单机版效率相差不大。我们也尝试过其他图数据库,这里要说下我们的业务需求:
- 良好的可扩展性
- 快速的数据导入
- 良好的查询效率
展开来讲,Neo4j 不具备良好的可扩展性,所以 pass。由于我们的图规模非常大,主要是面向金融风控场景,图的规模能达到十亿节点、百亿级别边,所以需要快速的数据导入来做初始化。这里要说下我们尝试用过 Dgraph,之前我们阅读过它的相关学术论文,论文写得非常的好但是工程实现欠佳。尤其是批量导入这块,当你导入的数据超过一定量级之后会产生类似内存泄漏的问题,所以 Dgraph pass。
最后一点是良好的查询效率,这里要讲下 JanusGraph,它的优点是后端可以集成其他存储引擎,这也是当时测试 JanusGraph 的主要原因。但是当我们导入和初始化数据之后,发现它的查询效率非常的糟糕。
这里看下 Akulaku 团队对 Nebula Graph 做的可扩展性和查询性能测试:
- 图规模:10亿点,100亿边
- 测试方式:nebula-bench https://github.com/vesoft-inc/nebula-bench
- 查询语句:
- 两个一度查询
- 两个二度查询
- 一个三度查询
- 随机源:注册手机号随机抽样 500 W个 phone
压测时从随机源 phone 随机查询其中 1 个数据。横轴为并发,纵轴为 QPS,不同颜色的曲线代表并发节点的个数,这里可以看到整个 Nebula Graph 的查询性能是比较好的。
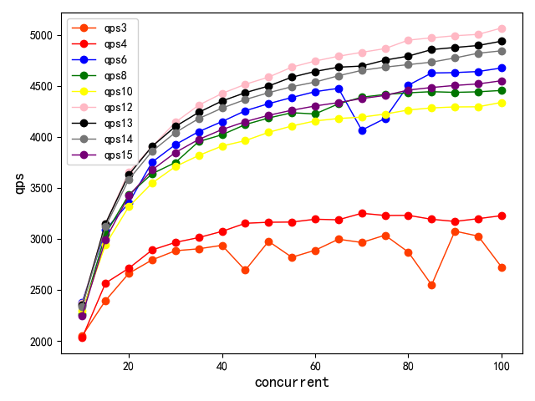
图上可以看到,可扩展性大概在 12 台机器的时达到较高的性能,后续再添加节点个数,分布式的开销就要开始大于并发带来的效益。所以你会看到这个节点个数提高,查询性能会有所下降。这里说下我们做的查询,随机抽取 500 万个节点,进行多批查询,每一批查询中包含两个一度查询,两个二度查询和一个三度查询。测试过程中,我们还遇到热点问题,上图是最后验证的结果。
压测时,使用的 Nebula 版本是 v1.x,后来 Nebula v2.x 发布之后,Akulaku 团队开始尝试升级。但刚升级尝试 2.0.1 时,发现一些问题:
- Leader change
- 导入数据的时候频繁出现 leader change,导致写入失败
- 查询数据的时候没有发现
- 观察到 CPU 负载较高,主要是超大子图导致
第一个问题主要发生在导入数据的时候,会频繁出现 leader change,这个问题会影响到线上调用效率。还有个观察到的现象是,CPU 负载高,这是由部分超大节点导致的负载过高。所以就先回滚到了 v1.2 版本。在 v2.5.0 发布之后,Akulaku 团队又重新做了一个测试,和之前的压测方式差不多。
- 图规模:10亿点,100亿边
- 机器配置:7 台,256G,32 核
- 测试方式:nebula-bench https://github.com/vesoft-inc/nebula-bench
- 查询语句:
- 两个一度查询
- 两个二度查询
- 一个三度查询
- 随机源:注册手机号随机抽样 500 W个 phone
在这个版本中,之前遇到的 leader change 和 CPU 负载过高的问题解决了。所以 Akulaku 团队尝试将 v2.5.0 应用到业务中。
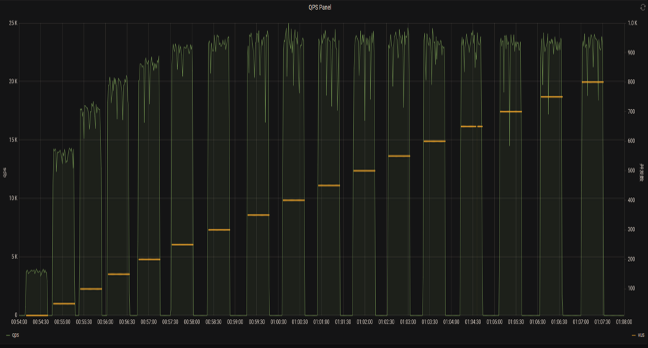
上图右侧是并发数,左侧是 QPS。
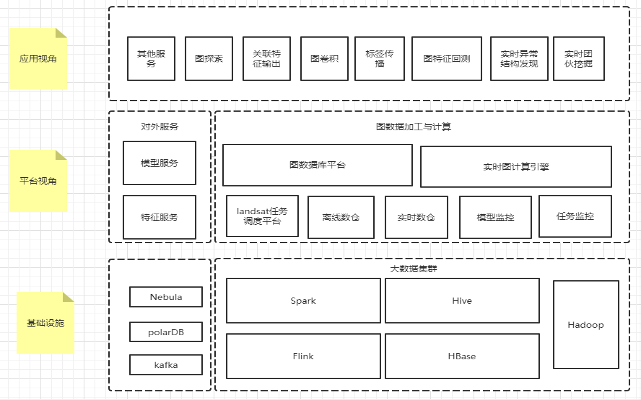
下面来讲下图分析平台,主要围绕两块引擎:图数据库平台 Nebula Graph 和实时图计算引擎。因为 Akulaku 这边主要对接的应用场景为反欺诈,对实效性要求高,所以需要一系列的实时图算法。为了开发图算法,图分析平台需要一个实时图计算引擎。这些引擎依赖于离线调度,比如:landsat 任务调度平台、离线数仓、实时数仓的监控和任务监控等等模块。这块内容底层又依赖于大数据集群,比如常见的 Spark、Hive、Hadoop、Flink、HBase 等等。
所以这张图从上到下就是应用-平台-基础设施。
如果我们单独看一个图数据库平台:
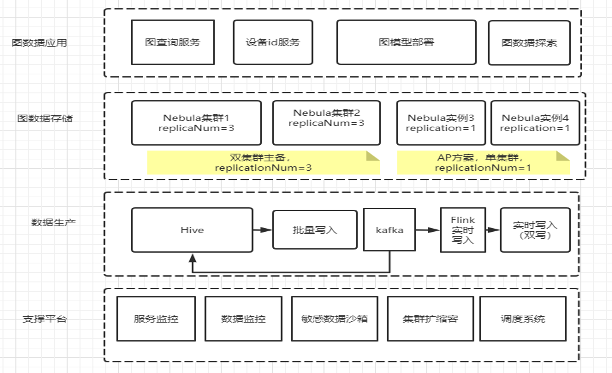
图数据库平台搭建这块,Akulaku 团队主要做了两件事情:一个是数据导入和高可用,数据导入的话它是基于离线数仓,它既有批量写入,也有基于实时数据源的实时写入。实时的数据源这块,图数据库存储有两种模式:
一种是双集群的主备,即线上服务由两个主从集群提供,实时数据源会对主从集群做双写;
另外一种是单集群的方案,即每个应用可以有单独实例。
这样构建图数据库存储,支撑平台需要监控(服务和数据)、敏感数据沙箱、集群扩缩容、调度系统等等这些支撑模块。
从业务角度,整个平台的建设是为了基于图关系进行探索和可视化展示,上图只是个示意图并非业务中实际使用的图。
上文说到应用场景,现在来具体讲下 Nebula 在 Akulaku 的具体应用案例。
首先,主要应用在可视化欺诈案例分析与深度关联挖掘。第二,设备 ID 关联计算。最后也是最常见的一个应用,用于各种图模型的部署,包括标签传播等等。下面详细来讲解下。
上图是图可视化的欺诈案例的分析,上图依旧是个示意图并非真实数据图。反欺诈的调查人员通过图关系,使用图数据库的可视化的工具,对关联关系进行展开分析,包括图谱的下段等等操作,去查看的节点属性。
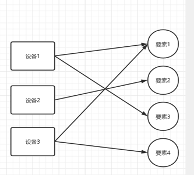
第二个案例,是设备 ID 关联计算,这属于刚才图概念部分说到的,它可能本身跟图没什么关系,只是用图来表示比较自然,而且也更加容易维护。具体展开来说,设备的 ID 需要通过一系列的要素来计算,但是欺诈分子会通过不停变更这些要素来试图绕过反欺诈策略。但其实变更要素时,它只能变更某一要素,其他要素和该要素还是保持着一定的关联。通过一定规则,用关联关系就能把它实际的映射关系找到。这个查询深度并不深,就是个一度的查询,其主要的难度并不在于逻辑,而是数据的一致性。举个例子,并发地操作计算设备的 ID 的话,那就会有数据一致性的问题。比如,删了一条不该删的边,加了一个不该加的数据,所以这个过程就需要对数据加锁。
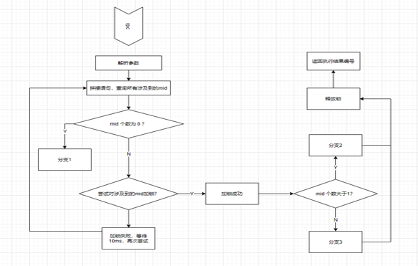
具体加锁的方法,就是加锁某批涉及计算设备 ID 信息的节点,等计算完成后再释放节点,然后其他进程才能够对这个数据进行修改。

第三大类应用是图模型训练与部署,比如像部署子图展开类的图模型。这里来解释下图模型,就是这个模型的结果是抽取的子图经过计算得到,这里的子图一般由中心节点展开得到。具体的子图展开的图模型有哪些?比如,以当前节点为中心的子图特征,基于当前子图的标签传播的结果,或者是图卷积的模型。下面说下这里的难点在哪?
第一,回测上逻辑复杂。回测,主要指的是数据回溯,根据场景要求需获取事件发生时的图关系,进行特征抽取和模型构建, 逻辑相对复杂。此外,在图模型的部署上时效性要求也很高。如果这个模型是反欺诈场景的话,一般要将模型部署在授信或者是下单环节,时效性要求较高。根据图模型训练与部署应用场景的不同特点,会有下列 4 个思考的角度:
- 业务环节的时效性要求。比如说,授信环节相对来说它的时效性要求会比下单环节要低一些;
- 子图规模。看部署模型涉及到的子图规模是多大,如果很大的话,允不允许取样?如果取样不允许的话,我们用什么方法处理?
- 图更新频率和模型调用量相比,谁比较多?
- 回测复杂度,它的数据量是大还是比较小?
下面举几个例子。

第一个例子,授信环节的子图特征。
具体来说,授信环节时,需要获得一个 uid 所属的子图的特征计算,比如说,N 度子图节点的占比或者是拓扑特征。这个业务环节的时效性要求相对低一些,这是第一个特点。第二个特点,子图规模可能大,可能会遇到爆炸节点的情况,但又不允许取样。第三个特点,子图更新数据量是远远大于模型的调用量。这代表什么呢?就是单位时间授信申请的授信额度申请量,是远小于图更新的频率。第四个特点,回测比较小。
针对上面的 4 个特点,采取什么方案呢?因为它更新的数据量远远大于模型的调用量,所以最好是在模型调用的时候直接去计算它的特征,而分数回测是可以基于图数据库的,就是说直接按照历史模型调用的事件来做分数的回测。由于模型计算是在业务环节调用时去做查询,所以需要确保这个图数据库集群的可用性。

第二个例子是下单环节的标签传播。
具体来说,标签传播是从节点上的一个标签,比如黑灰标签或者特定的业务属性标签,根据一定的规则做传播。那么,标签传播场景有什么特点?
第一点,业务环节的时效性要求会比较高,因为它是下单环节,不能有很大的延迟,否则就会卡单。第二点,子图规模和上面一样,存在爆炸子图的可能。比如说,三度子图可能是几百万的数量级,而且这个子图不能采样。为什么不能采样呢?因为标签传播涉及业务规则,采样可能会影响分数的稳定性,所以一般来说不允许采样。第三点,更新的数据量是远小于模型的调用量,即图更新的频率小,但是调用的次数多。那,什么时候做子图计算呢?在数据更新的时候进行计算,这样需要计算的数据量比较小。而下单环节的标签传播回测的数据量会比较大,单纯从数量来说,下单的数量会远大于授信申请的数量。
针对上述特点,更新数据量小于模型调用量(在业务环节调用分数的数量)的话,在图更新时去计算模型的结果。这样做有个好处,就是你调用结果和模型计算的过程,和调用分数的过程是解耦的。也就是说,业务环节直接调用分数,计算又不是实际环节的调用,只是这里需要允许一定的延迟。这样处理,相当于有两个流程,一个是离线流程,T+1 做分数校正;一个是实时流程,上图右侧实时图模型的部署。实时数据源的数据一更新,系统便去更新标签传播的值,而业务环节的分数调用是通过模型结果的查询服务来调取,而不是直接去查图数据库,这样就分离了查询和计算,甚至能做到无痛升级图数据库,也不影响线上服务。
上面的处理方案因为有两个数据流(离线数据流和实时数据流),所以系统复杂度较高,而且需要保持数据的同步。

第三个例子,下单环节的图卷积。
具体来说,基于属性图的节点属性计算图卷积,下单环节调用图卷积结果。它的特点和上一个例子有点相似,业务环节的时效性要求高。子图规模也可能存在爆炸子图,同样也不允许取样。这个场景下,它和前面第二个例子一样,更新的数据量会小于模型的调用量,下单环节下单量比较大,回测的数据量也是比较大。所有我们有一个上图右侧的架构处理,就是系统有一个 T+1 的校正。即每天有个整体的 T+1 的图卷积过程去更新图卷积结果,并且实时地通过实时数据源去驱动分数的局部更新。所以,它是一个 T+1 的全量刷新,加一个实时的局部刷新。
以上为 Nebula 在 Akulaku 团队的三个应用。

总的来说,Nebula 对 Akulaku 最大的价值是优异的导入性能,以及可扩展性。这里说下它的导入速度,非常的快,QPS 能够达到 11 万,当然是异步写入。这个数据比其他的图数据库好很多,当然可扩展性也非常好。具体应用上,Nebula Graph 其实应用到 Akulaku 图学习模型的部署的很多场景中,后续我们会着力于提高这个平台的稳定性,持续地反馈建议到社区来共建产品。此外,会进一步优化图分析的平台,降低图模型、回测和模型部署的难度。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!