Nebula Graph 源码解读系列|客户端的通信秘密——fbthrift

概述
Nebula Clients 给用户提供了多种编程语言的 API 用于和 Nebula Graph 交互,并且对服务端返回的数据结构进行了重新封装,便于用户使用。
目前 Nebula Clients 支持的语言有 C++、Java、Python、Golang 和 Rust。
通信框架
Nebula Clients 使用了 fbthrift https://github.com/facebook/fbthrift 作为服务端和客户端之间的 RPC 通信框架,实现了跨语言的交互。
fbthrift 提供了三方面的功能:
- 生成代码:fbthrift 可将不同语言序列化成数据结构
- 序列化:将生成的数据结构序列化
- 通信交互:在客户端、服务端之间传输消息,收到不同语言的客户端的请求时,调用相应的服务端函数
例子
这里以 Golang 客户端为例,展示 fbthrift 在 Nebula Graph 中的应用。
Vertex结构在服务端的定义:
struct Vertex {
Value vid;
std::vector<Tag> tags;
Vertex() = default;
};
- 首先, 在
src/interface/common.thrift中定义一些数据结构:
struct Tag {
1: binary name,
// List of <prop_name, prop_value>
2: map<binary, Value> (cpp.template = "std::unordered_map") props,
} (cpp.type = "nebula::Tag")
struct Vertex {
1: Value vid,
2: list<Tag> tags,
} (cpp.type = "nebula::Vertex")
在这里我们定义了一个 Vertex 的结构,其中 (cpp.type = "nebula::Vertex") 标注出了这个结构对应了服务端的 nebula::Vertex。
- fbthrift 会自动为我们生成 Golang 的数据结构:
// Attributes:
// - Vid
// - Tags
type Vertex struct {
Vid *Value `thrift:"vid,1" db:"vid" json:"vid"`
Tags []*Tag `thrift:"tags,2" db:"tags" json:"tags"`
}
func NewVertex() *Vertex {
return &Vertex{}
}
...
func (p *Vertex) Read(iprot thrift.Protocol) error { // 反序列化
...
}
func (p *Vertex) Write(oprot thrift.Protocol) error { // 序列化
...
}
- 在
MATCH (v:Person) WHERE id(v) == "ABC" RETURN v这条语句中:客户端向服务端请求了一个顶点(nebula::Vertex),服务端找到这个顶点后会进行序列化,通过 RPC 通信框架的transport发送到客户端,在客户端收到这份数据时,会进行反序列化,生成对应客户端中定义的数据结构(type Vertex struct)。
客户端模块
在这个章节会以 nebula-go 为例,介绍客户端的各个模块和其主要接口。
- 配置类 Configs,提供全局的配置选项。
type PoolConfig struct {
// 设置超时时间,0 代表不超时,单位 ms。默认是 0
TimeOut time.Duration
// 每个连接最大空闲时间,当连接超过该时间没有被使用将会被断开和删除,0 表示永久 idle,连接不会关闭。默认是 0
IdleTime time.Duration
// max_connection_pool_size: 设置最大连接池连接数量,默认 10
MaxConnPoolSize int
// 最小空闲连接数,默认 0
MinConnPoolSize int
}
- 客户端会话 Session,提供用户直接调用的接口。
//管理 Session 特有的信息
type Session struct {
// 用于执行命令的时候的身份校验或者消息重试
sessionID int64
// 当前持有的连接
connection *connection
// 当前使用的连接池
connPool *ConnectionPool
// 日志工具
log Logger
// 用于保存当前 Session 所用的时区
timezoneInfo
}
- 接口定义有以下
// 执行 nGQL,返回的数据类型为 ResultSet,该接口是非线程安全的。
func (session *Session) Execute(stmt string) (*ResultSet, error) {...}
// 重新为当前 Session 从连接池中获取连接
func (session *Session) reConnect() error {...}
// 做 signout,释放 Session ID,归还 connection 到 pool
func (session *Session) Release() {
- 连接池 ConnectionPool,管理所有的连接,主要接口有以下
// 创建新的连接池, 并用输入的服务地址完成初始化
func NewConnectionPool(addresses []HostAddress, conf PoolConfig, log Logger) (*ConnectionPool, error) {...}
// 验证并获取 Session 实例
func (pool *ConnectionPool) GetSession(username, password string) (*Session, error) {...}
- 连接 Connection,封装 thrift 的网络,提供以下接口
// 和指定的 ip 和端口的建立连接
func (cn *connection) open(hostAddress HostAddress, timeout time.Duration) error {...}
// 验证用户名和密码
func (cn *connection) authenticate(username, password string) (*graph.AuthResponse, error) {
// 执行 query
func (cn *connection) execute(sessionID int64, stmt string) (*graph.ExecutionResponse, error) {...}
// 通过 SessionId 为 0 发送 "YIELD 1" 来判断连接是否是可用的
func (cn *connection) ping() bool {...}
// 向 graphd 释放 sessionId
func (cn *connection) signOut(sessionID int64) error {...}
// 断开连接
func (cn *connection) close() {...}
- 负载均衡 LoadBalance,在连接池里面使用该模块
- 策略:轮询策略
模块交互解析
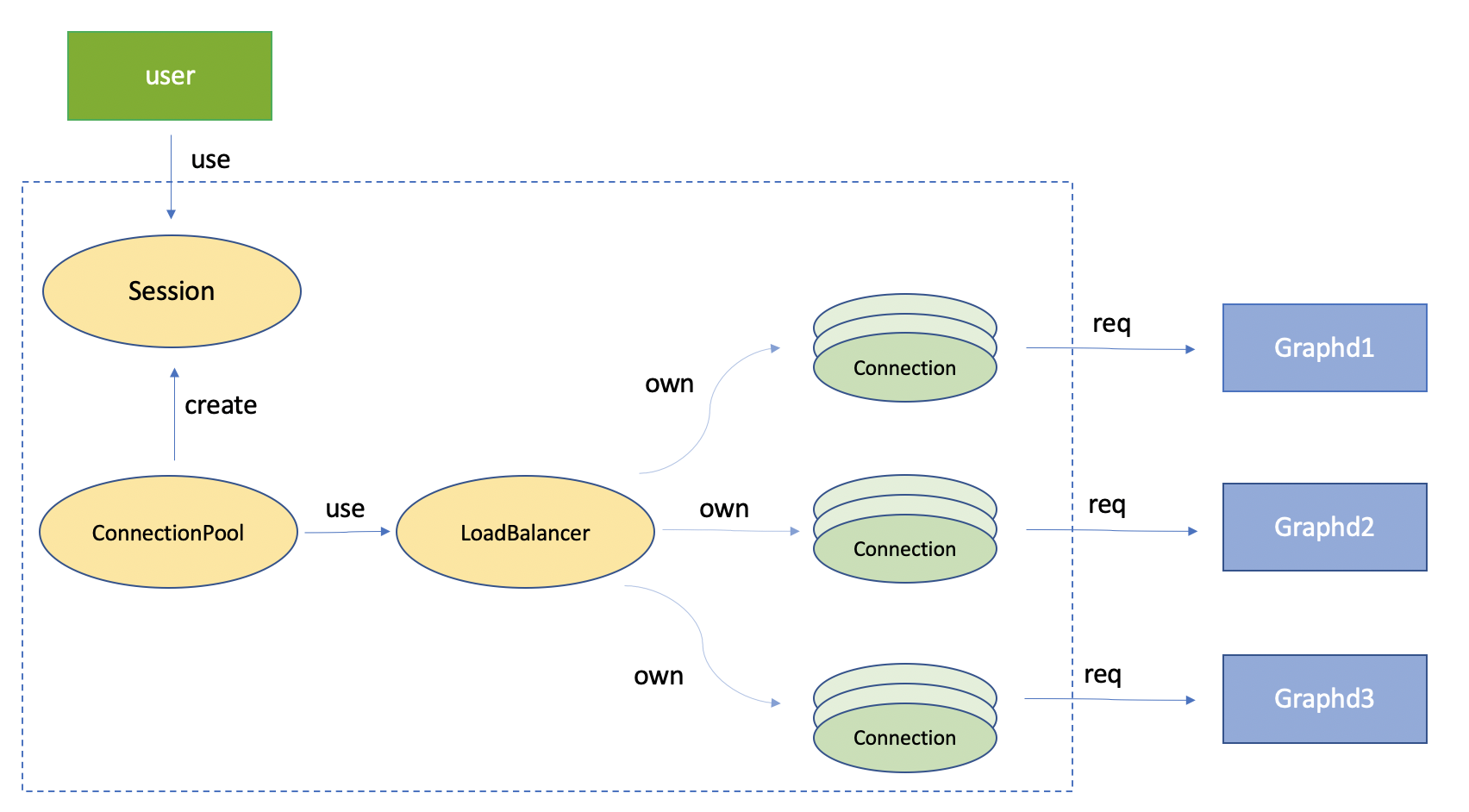
- 连接池
- 初始化:
- 在使用时用户需要先创建并初始化一个连接池 ConnectionPool,连接池会在初始化时会对用户指定的 Nebula 服务所在地址建立连接 Connection,如果在用集群部署方式部署了多个 Graph 服务,连接池会采用轮询的策略来平衡负载,对每个地址建立近乎等量的连接。
- 管理连接:
- 连接池内维护了两个队列,空闲连接队列 idleConnectionQueue 和使用中的连接队列 idleConnectionQueue,连接池会定期检测过期空闲的连接并将其关闭。这两个队列在增删元素的时候会通过读写锁来确保多线程执行的正确性。
- 当 Session 向连接池请求连接时,会检查空闲连接队列中是否有可用的连接,如果有则直接返回给 Session 供用户使用;如果没有可用连接并且当前的总连接数没有超过配置中限定的最大连接数,则新建一个连接给 Session;如果已经到达了最大连接数的限制,返回错误。
- 一般只有在程序退出时才需要关闭连接池, 在关闭时池中所有的连接都会被断开。
- 初始化:
- 客户端会话
- 客户端会话 Session 通过连接池生成,用户需要提供用户密码进行校验,在校验成功后用户会获得一个 Session 实例,并通过 Session 中的连接与服务端进行通信。最常用的接口是
execute(),如果在执行时发生错误,客户端会检查错误的类型,如果是网络原因则会自动重连并尝试再次执行语句。 - 需要注意,一个 Session 不支持被多个线程同时使用,正确的方式是用多个线程申请多个 Session,每个线程使用一个 Session。
- Session 被释放时,其持有的连接会被放回到连接池的空闲连接队列中,以便于之后被其他 Session 复用。
- 客户端会话 Session 通过连接池生成,用户需要提供用户密码进行校验,在校验成功后用户会获得一个 Session 实例,并通过 Session 中的连接与服务端进行通信。最常用的接口是
- 连接
- 每个连接实例都是等价的,可以被任意 Session 持有,这样设计的目的是这些连接可以被不同的 Session 复用,减少反复开关 Transport 的开销。
- 连接会将客户端的请求发送到服务端并将其结果返回给 Session。
- 用户使用示例
// Initialize connection pool
pool, err := nebula.NewConnectionPool(hostList, testPoolConfig, log)
if err != nil {
log.Fatal(fmt.Sprintf("Fail to initialize the connection pool, host: %s, port: %d, %s", address, port, err.Error()))
}
// Close all connections in the pool when program exits
defer pool.Close()
// Create session
session, err := pool.GetSession(username, password)
if err != nil {
log.Fatal(fmt.Sprintf("Fail to create a new session from connection pool, username: %s, password: %s, %s",
username, password, err.Error()))
}
// Release session and return connection back to connection pool when program exits
defer session.Release()
// Excute a query
resultSet, err := session.Execute(query)
if err != nil {
fmt.Print(err.Error())
}
返回数据结构
客户端对部分复杂的服务端返回的查询结果进行了封装并添加了接口,以便于用户使用。
| 查询结果基本类型 | 封装后的类型 |
|---|---|
| Null | |
| Bool | |
| Int64 | |
| Double | |
| String | |
| Time | TimeWrapper |
| Date | |
| DateTime | DateTimeWrapper |
| List | |
| Set | |
| Map | |
| Vertex | Node |
| Edge | Relationship |
| Path | PathWrraper |
| DateSet | ResultSet |
| - | Record(用于ResultSet 的行操作) |
对于 nebula::Value,在客户端会被包装成 ValueWrapper,并通过接口转换成其他结构。(i.g. node = ValueWrapper.asNode())
数据结构的解析
对于语句 MATCH p= (v:player{name:"Tim Duncan"})-[]->(v2) RETURN p,返回结果为:
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| p |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| <("Tim Duncan" :bachelor{name: "Tim Duncan", speciality: "psychology"} :player{age: 42, name: "Tim Duncan"})<-[:teammate@0 {end_year: 2016, start_year: 2002}]-("Manu Ginobili" :player{age: 41, name: "Manu Ginobili"})> |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Got 1 rows (time spent 11550/12009 us)
我们可以看到返回的结果包含了一行,类型是一条路径. 此时如果需要取得路径终点(v2)的属性,可以通过如下操作实现:
// Excute a query
resultSet, _ := session.Execute("MATCH p= (v:player{name:"\"Tim Duncan"\"})-[]->(v2) RETURN p")
// 获取结果的第一行, 第一行的 index 为0
record, err := resultSet.GetRowValuesByIndex(0)
if err != nil {
t.Fatalf(err.Error())
}
// 从第一行中取第一列那个 cell 的值
// 此时 valInCol0 的类型为 ValueWrapper
valInCol0, err := record.GetValueByIndex(0)
// 将 ValueWrapper 转化成 PathWrapper 对象
pathWrap, err = valInCol0.AsPath()
// 通过 PathWrapper 的 GetEndNode() 接口直接得到终点
node, err = pathWrap.GetEndNode()
// 通过 node 的 Properties() 得到所有属性
// props 的类型为 map[string]*ValueWrapper
props, err = node.Properties()
客户端地址
各语言客户端 GitHub 地址:
- https://github.com/vesoft-inc/nebula-cpp
- https://github.com/vesoft-inc/nebula-java
- https://github.com/vesoft-inc/nebula-python
- https://github.com/vesoft-inc/nebula-go
- https://github.com/vesoft-inc/nebula-rust
推荐阅读
- Nebula Graph 源码解读系列 | Vol.00 序言
- Nebula Graph 源码解读系列 | Vol.01 Nebula Graph Overview
- Nebula Graph 源码解读系列 |Vol.02 详解 Validator
- Nebula Graph 源码解读系列 |Vol.03 Planner 的实现
- Nebula Graph 源码解读系列 |Vol.04 基于 RBO 的 Optimizer 实现
- Nebula Graph 源码解读系列 |Vol.05 Scheduler 和 Executor 两兄弟
- Nebula Graph 源码解读 |Vol.06 MATCH 中变长 Pattern 的实现
《开源分布式图数据库Nebula Graph完全指南》,又名:Nebula 小书,里面详细记录了图数据库以及图数据库 Nebula Graph 的知识点以及具体的用法,阅读传送门:https://docs.nebula-graph.com.cn/site/pdf/NebulaGraph-book.pdf
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号