
图计算 on nLive:Nebula 的图计算实践

在 #图计算 on nLive# 直播活动中,来自 Nebula 研发团队的 nebula-plato 维护者郝彤和 nebula-algorithm 维护者 Nicole 分别同大家分享了他她眼中的图计算。
嘉宾们
- 王昌圆:论坛 ID:Nicole,nebula-algorithm 维护者;
- 郝彤:论坛 ID:caton-hpg,nebula-plato 维护者;
先开场的是 nebula-plato 的维护者郝彤。
图计算之 nebula-plato

nebula-plato 的分享主要由图计算系统概述、Gemini 图计算系统介绍、Plato 图计算系统介绍以及 Nebula 如何同 Plato 集成构成。
图计算系统
图的划分
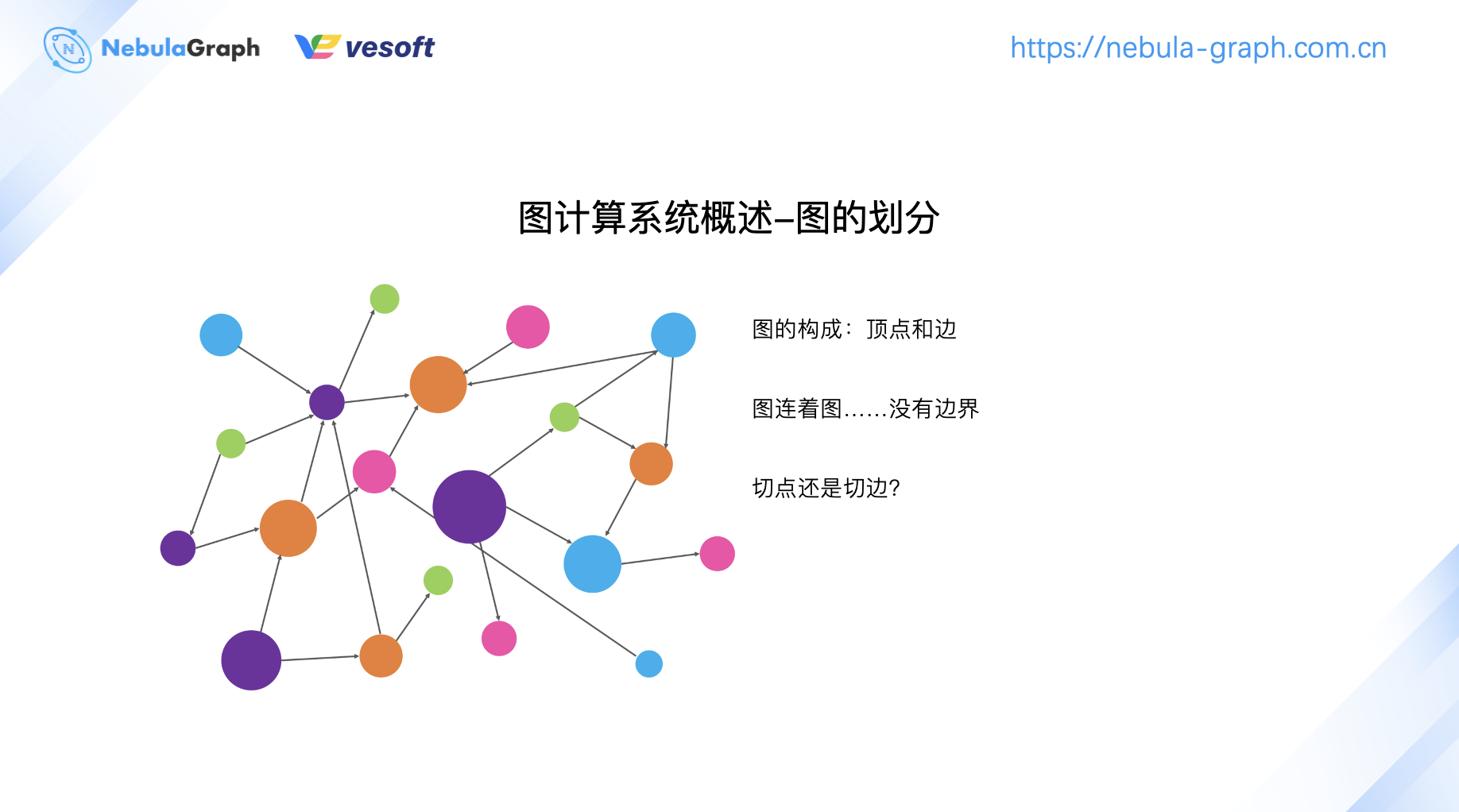
图计算系统概述部分,着重讲解下图的划分、分片、存储方式等内容。
图自身由顶点和边构成,而图结构本身是个发散性结构没有边界。要对图进行切分,必然是切顶点或者是切边二选一。
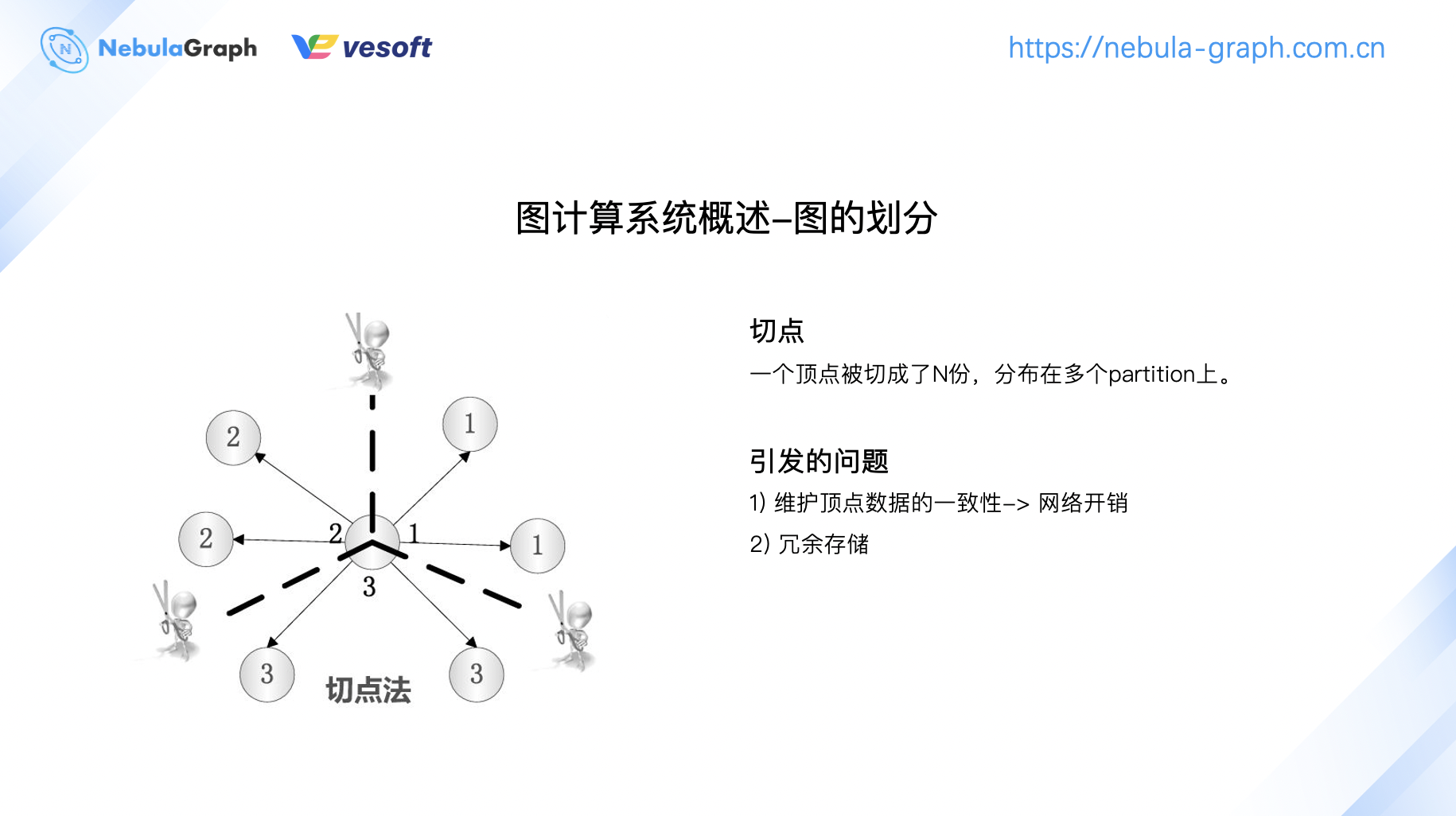
切顶点意味着一个顶点切成多份,每个 partition 上会存储部分顶点,这样会引发两个问题:顶点数据的一致性和网络开销的问题。此外,切点也存在一个顶点存储多份带来的数据冗余。
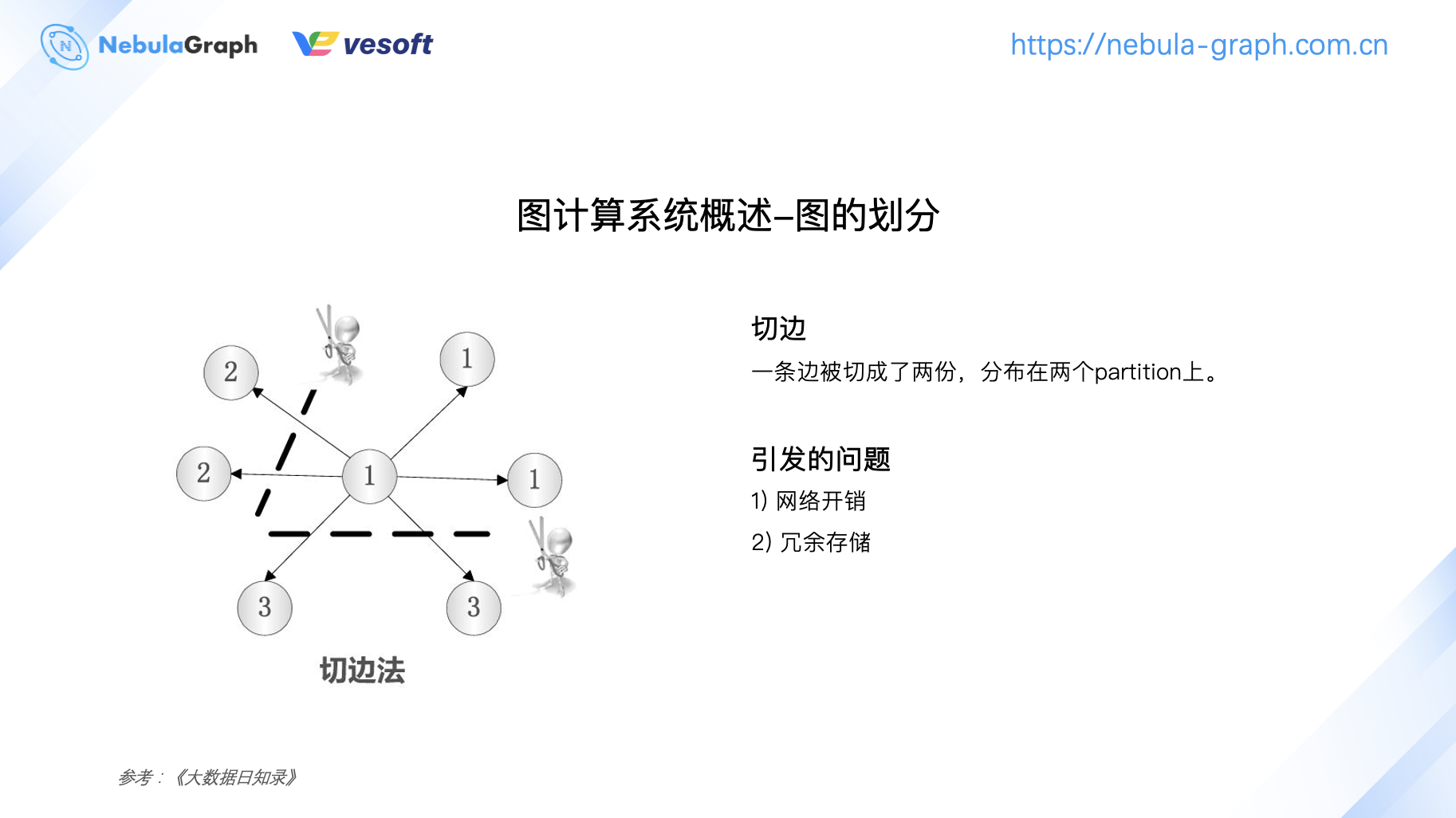
而切边则一条边会切成两份,分别存储在两个 partition 上。在计算(迭代计算)过程中就会存在网络开销。同样,切边也会引发数据冗余带来的存储危机。
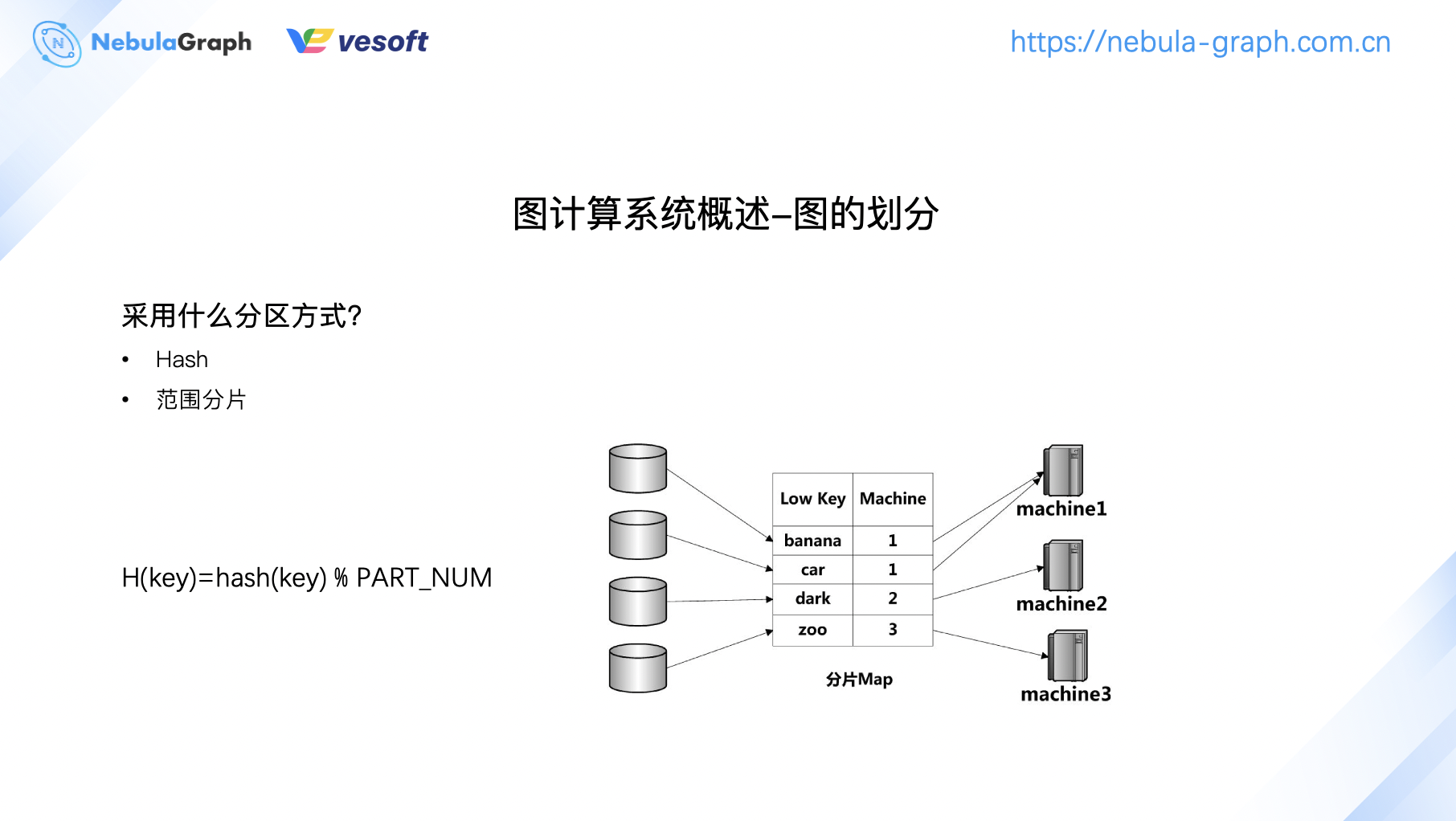
图的划分除了有图数据结构自身的切割问题,还有数据存储的分区问题。图数据分区通常有两种方式,一种是 Hash,还有一种是范围分片。范围分片指的是数据划分为由片键值确定的连续范围,比如说 machine 1 有 bannana、car 等 key,machine 2 有 dark 范围的 key,按照类似规定分片。
图存储的方式
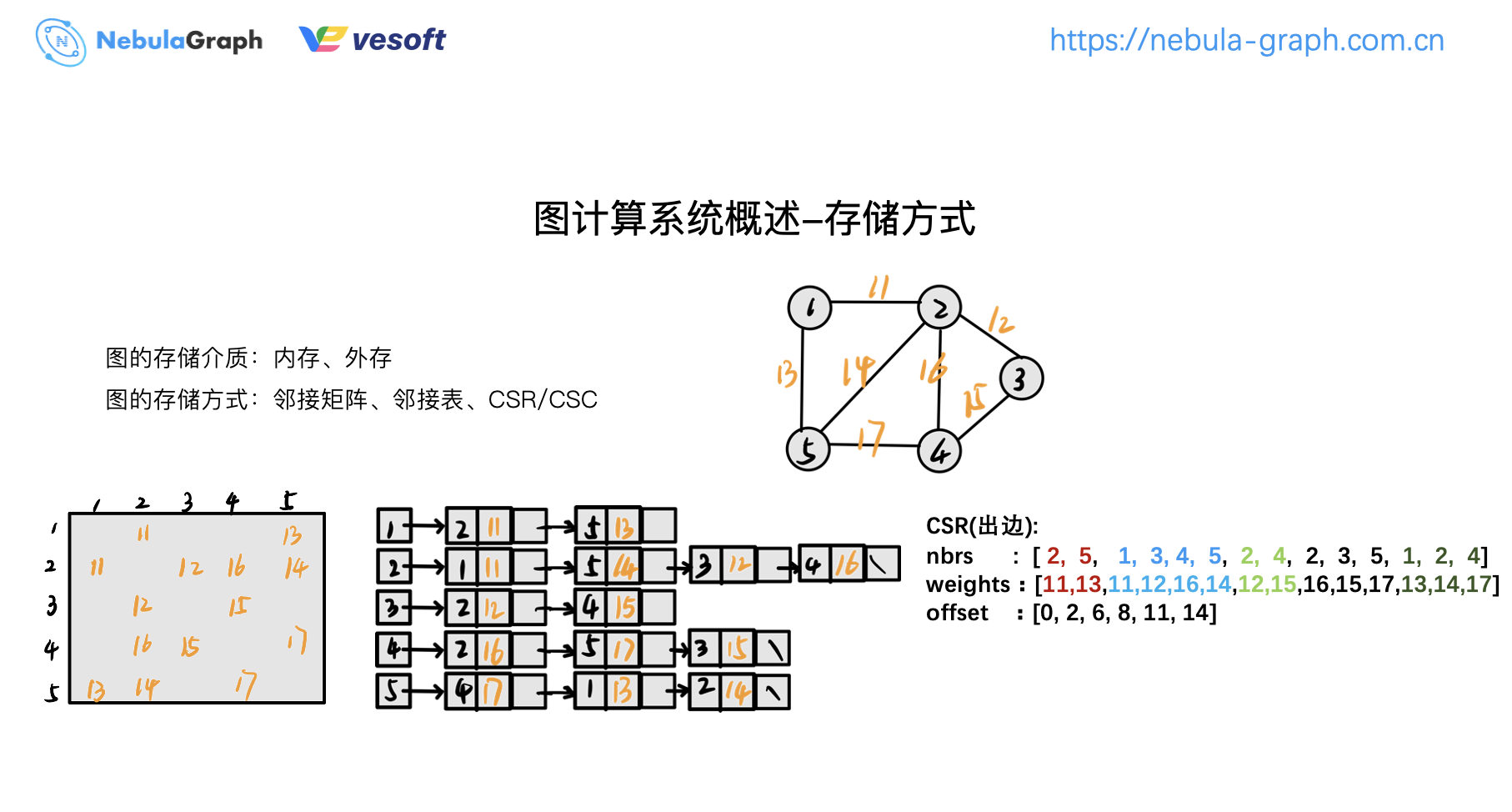
图计算系统的存储介质分为内存和外存,内存方式会把所有数据放内存中进行迭代计算;而外存存储则要不停地去读写磁盘,这种效率非常低。目前,主流图计算系统都是基于内存存储,但内存有个缺点,如果内存放不下数据会非常麻烦。
图计算的存储方式主要有:邻接矩阵、邻接表、CSR/CSC,前两者大家比较熟悉,这里简单讲下 CSR/CSC。CSR 是压缩稀疏行,存储顶点的出边信息。举个例子:
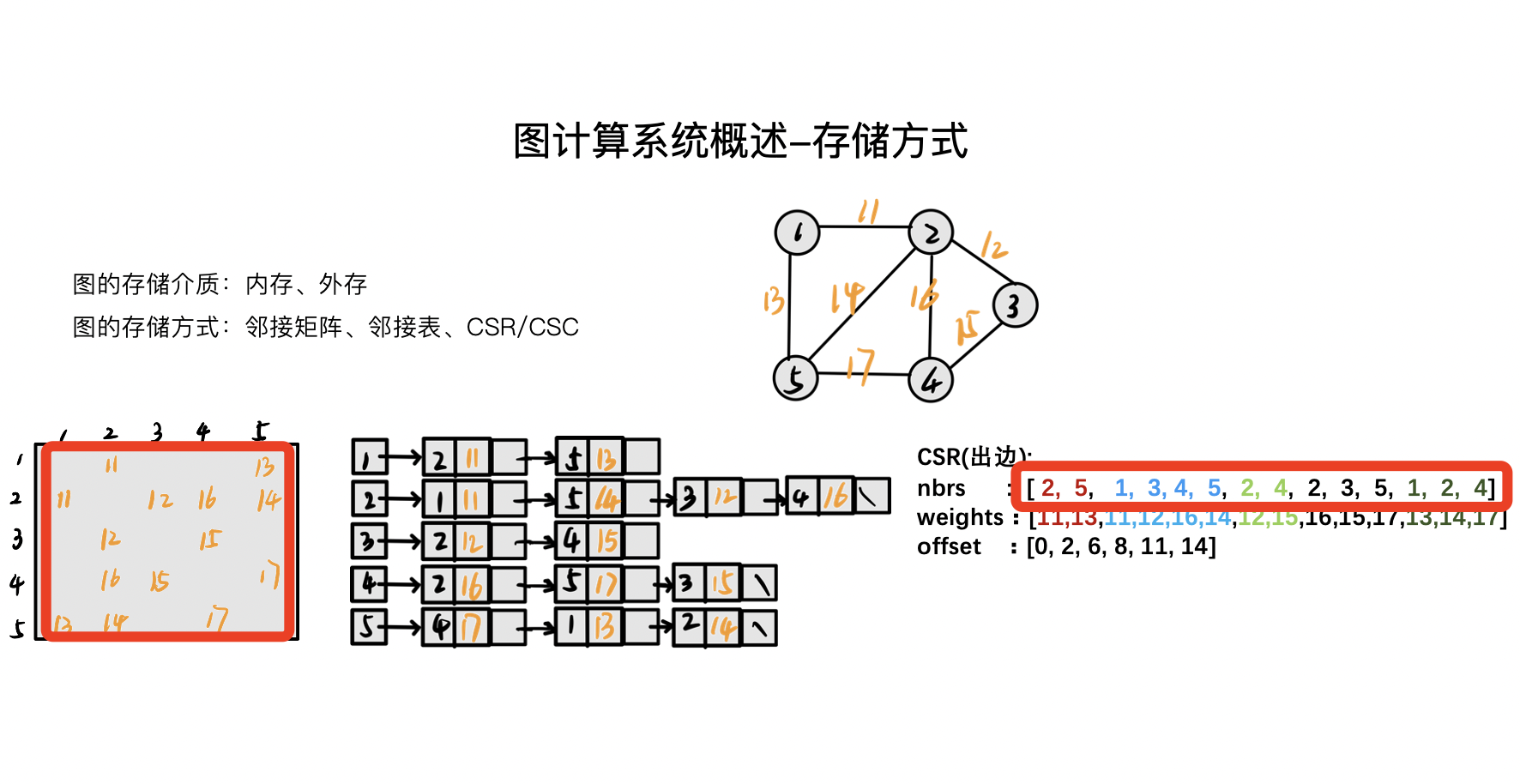
现在我们对这个矩阵(上图)进行压缩,只压存储中有数据的内容,剔除矩阵中没有数据的内容,这样会得到最右边的这张图。但是这种情况如何去判断 2 和 5 是哪个顶点的出边呢?这里引入一个字段 offset。
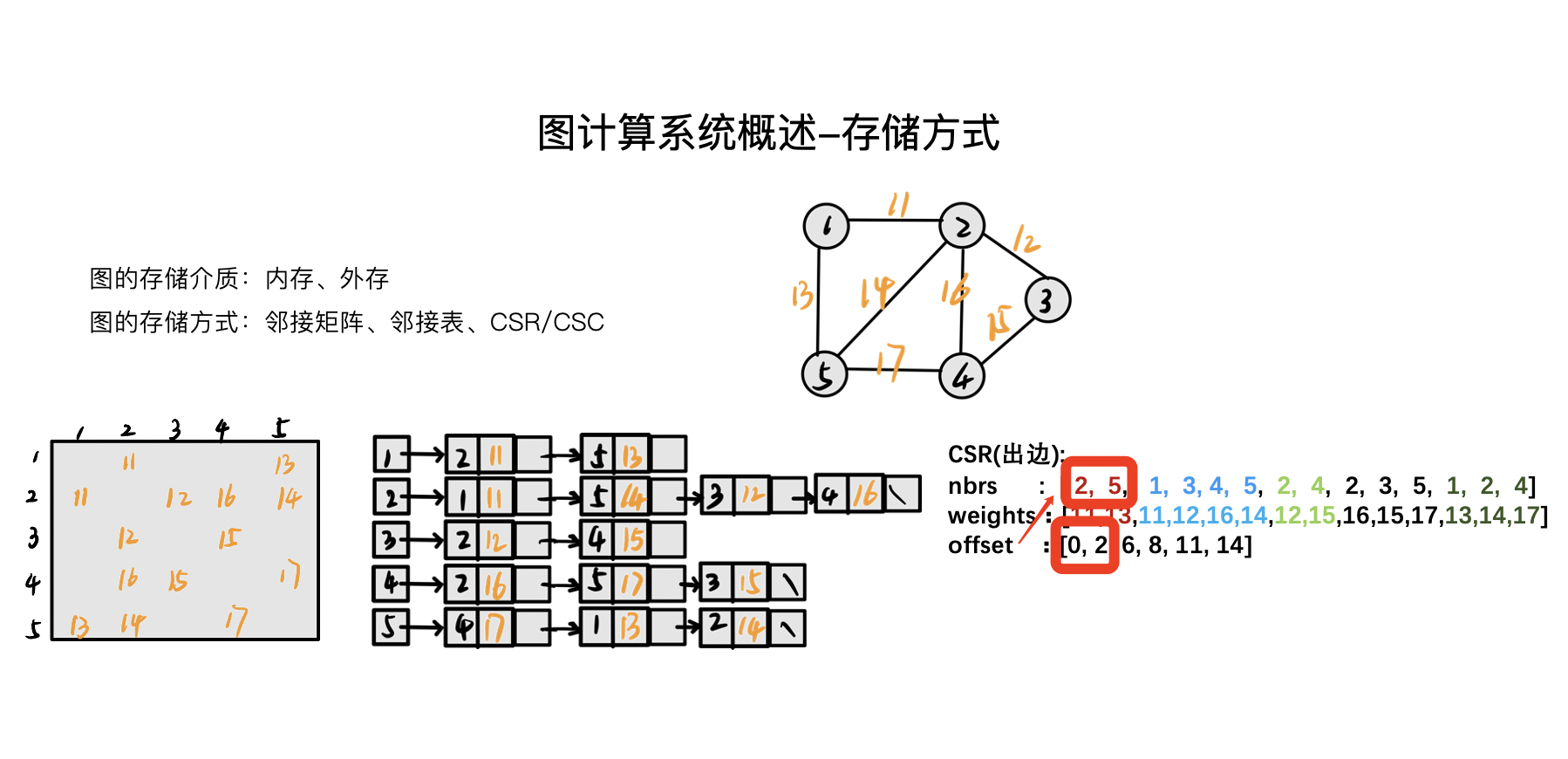
比如说,现在要取顶点 1 的邻居,顶点 1 在 offset 第一个,那它的邻居是什么区段?如上图,红色框所示:1 的 offset 是 0~2,但不包括 2,对应的邻居就是 2 和 5。
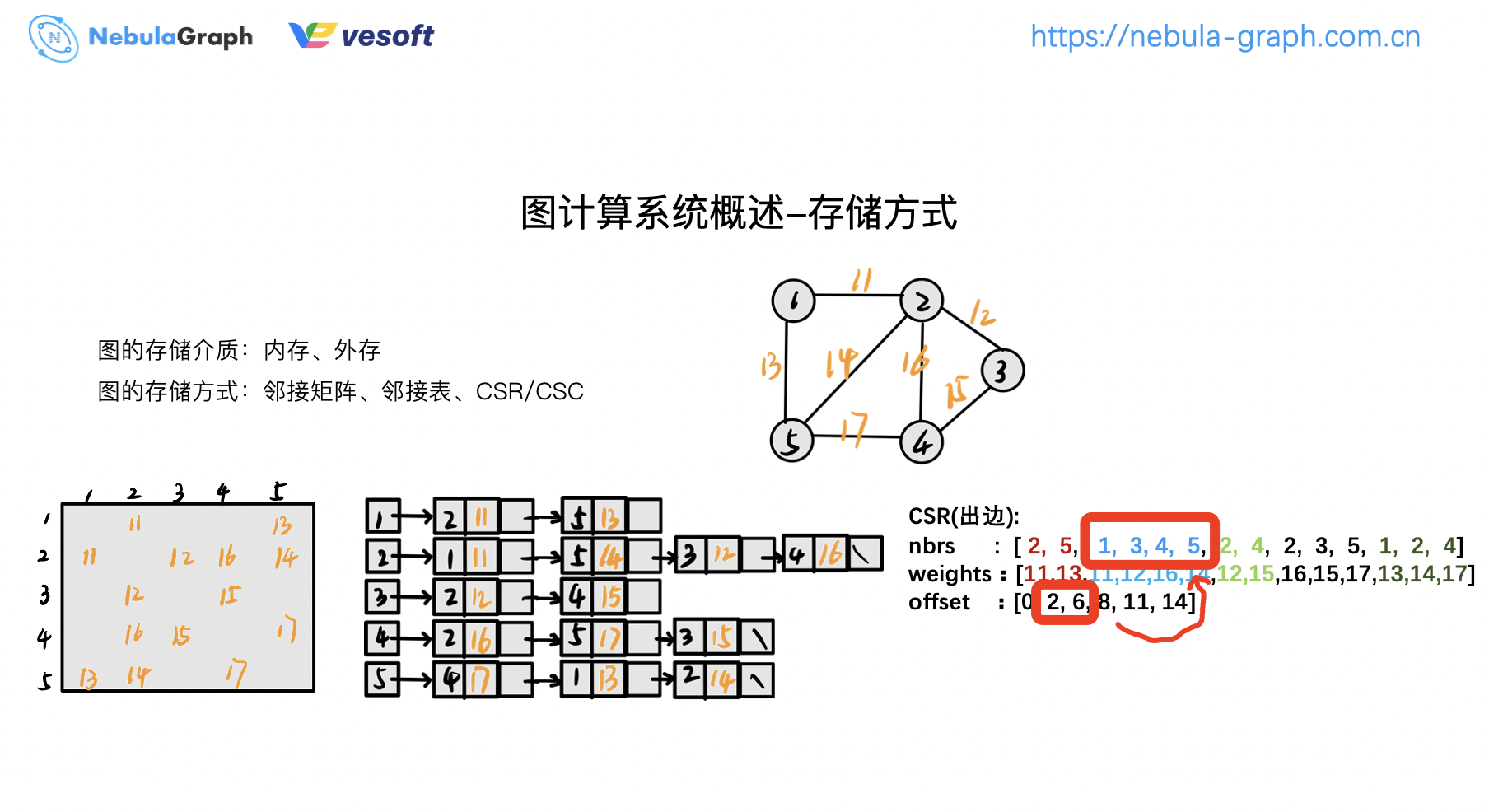
取节点 2 的邻居,节点 2 的邻居是范围是 2~6,这样对应的邻居就是 1、3、4、5,这就是 CSR。同理,CSC 为压缩稀疏列,同 CSR 类似,不过是按照列的方式进行压缩,它存的是入边信息。
图计算模式
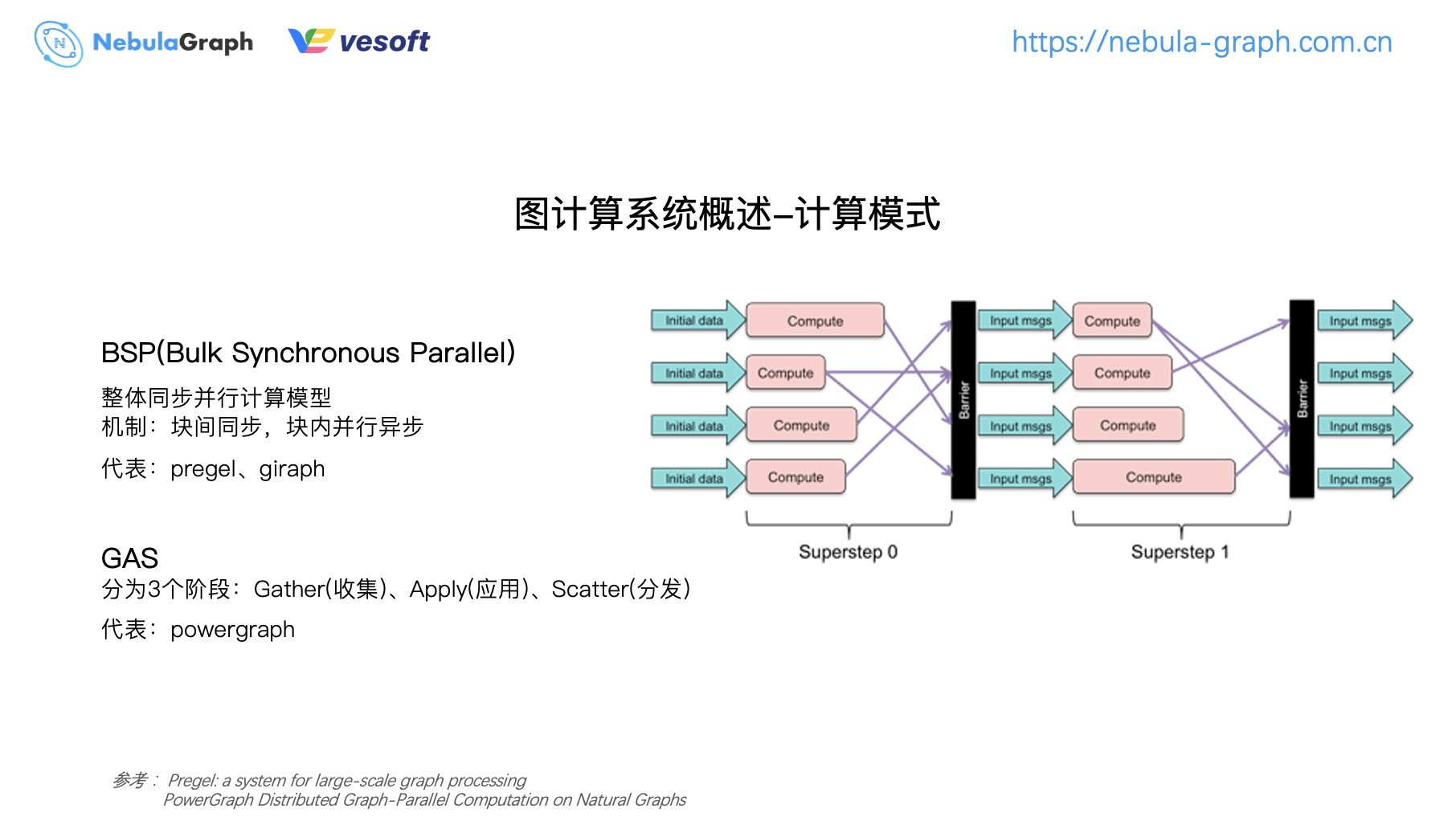
图计算模式通常有两种,一种是 BSP(Bulk Synchronous Parallel),一种是 GAS(Gather、Apply、Scatter)。 BSP 是一个整体同步的计算模式,块内部会进行并行计算,块与块之间会进行同步计算。像常见的图计算框架 Pregel、Giraph 都是采用的 BSP 编程模式。
再来说下 PowerGraph 它才用了 GAS 编程模型,相比 BSP,GAS 则细分成了 Gather 收集、Apply 应用、Scatter 分发等三个阶段,每次迭代都会经过这三个阶段。在 Gather 阶段先收集 1 度邻居的数据,再在本地进行一次计算(Apply),如果数据有变更将变更的结果 Scatter 分发出去,上面就是 GAS 编程模型的处理过程。
图计算的同步和异步
在图计算系统中,常会见到两个术语:同步、异步。同步意味着本轮产生的计算结果,在下一轮迭代生效。而本轮产生的计算结果,在本轮中立即生效则叫做异步。
异步方式的好处在于算法收敛速度特别快,但它有个问题。
因为异步的计算结果是在当轮立即生效的,所以同节点的不同的执行顺序会导致不同的结果。
此外,异步在并行执行的过程中会存在数据不一致的问题。
图计算系统的编程模式
图计算系统编程模型通常也分为两种,一种是以顶点为中心的编程模型,另外一种是以边为中心的编程模型。

(图:以顶点为中心的编程模型)

(图:以边为中心的编程模型)
这两种模式以顶点为中心的编程模型比较常见,以顶点为中心意味着所有的操作对象为顶点,例如上图的 vertex v 便是一个顶点变量 v,而所有诸如 scatter、gather 之类的操作都是针对这个顶点数据进行。
Gemini 图计算系统
Gemini 图计算系统是以计算为中心的分布式图计算系统,这里主要说下它的特点:
- CSR/CSC
- 稀疏图/稠密图
- push/pull
- master/mirror
- 计算/通信 协同工作
- 分区方式:chunk-base,并支持 NUMA 结构
Gemini 中文的含义是“双子座”,在 Gemini 论文中提到的很多技术是成双成对出现的。不仅在存储结构上 CSR 和 CSC 成双成对出现,在图划分上也分为了稀疏图和稠密图。
稀疏图采用 push 的方式,可以理解为将自己的数据发送出去,更改他人数据;对于稠密图,它采用 pull 的方式把 1 度邻居数据拉过来,更改自己的数据。
此外,Gemini 把顶点分为 master 和 mirror。在计算和通信方面进行协同工作,以便降低时间提升整体效率。最后是分区方式,采用 chunk-base分区,并支持 NUMA 结构。
下面来举个例子加速理解:
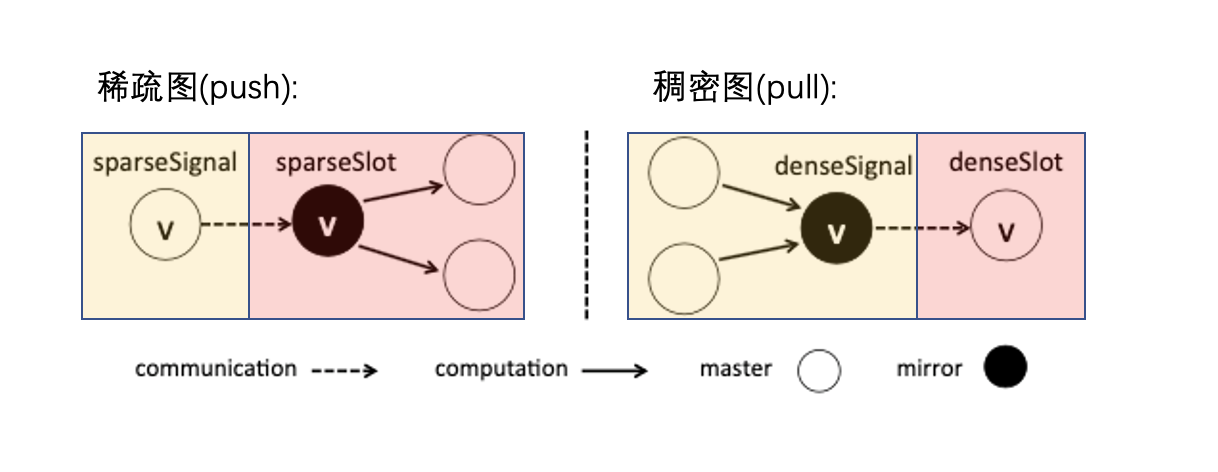
上图黄色和粉色是 2 个不同的 partition 分区。
- 在稀疏图的 push 操作时,master 顶点(上图左图黄色区域的 v 顶点)会通过网络将数据同步给所有的 mirror 顶点(上图左图粉色区域的 v 顶点),mirror 节点执行push,修改它的一度邻居节点数据。
- 在稠密图的 pull 操作中, mirror 顶点(上图右图黄色区域的 v 节点)会拉取它 一度邻居的数据,再通过网络同步给它的 master 顶点(上图右图粉色区域的 v 节点),修改它自己的数据。
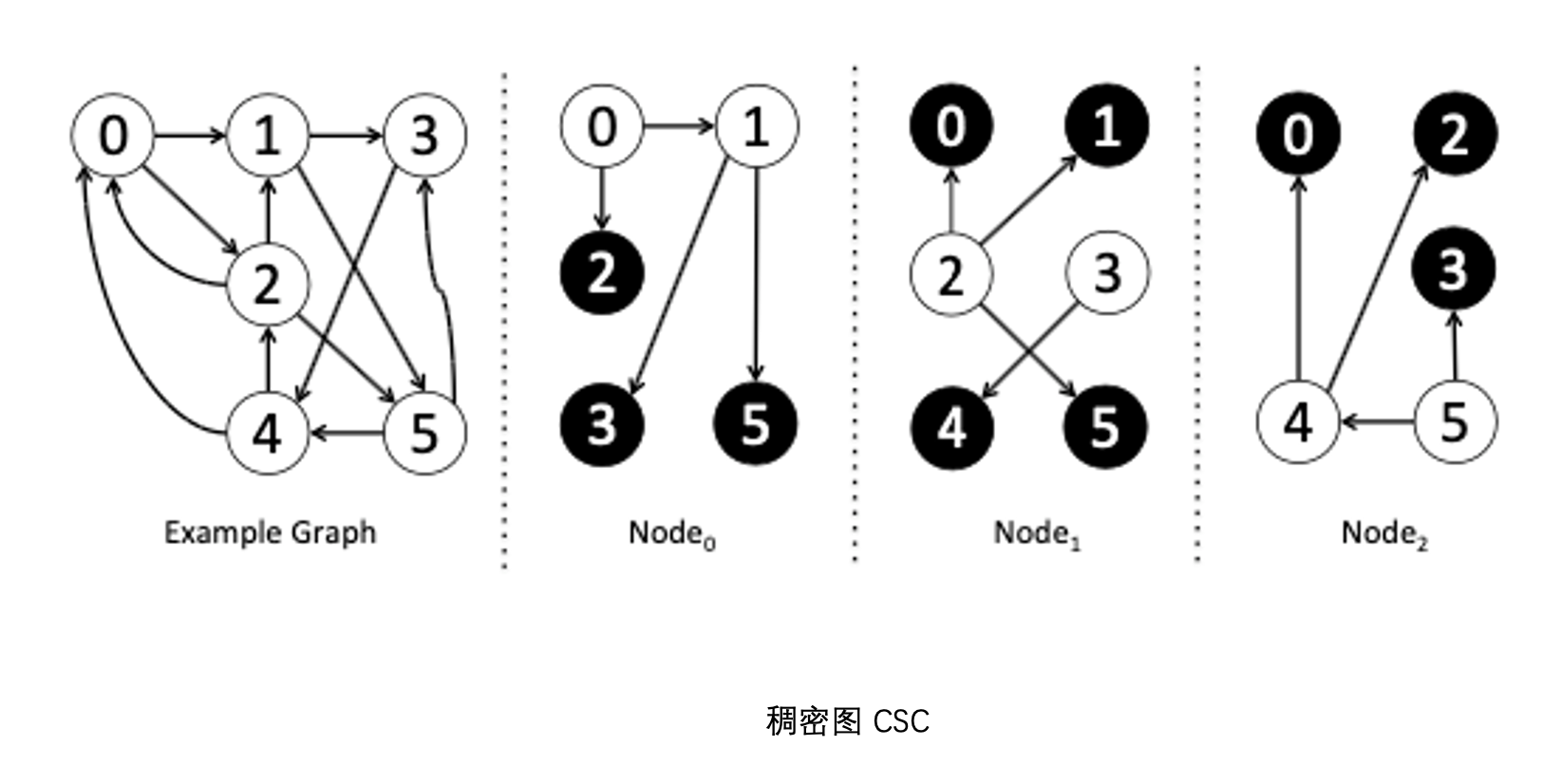
结合上图例子深入理解下,这是一个稠密图,采用 CSC 存储方式。这里上图左侧 Example Graph 中的顶点 0 要进行 pull 操作,这时候 0 的 mirror 节点(Node1 和 Node2)会拉取它的 一度邻居数据,然后同步给 master(Node0)更改自己的数据。
上述便是稠密图 0 对应的 pull 操作。
接着来简单介绍下 Plato。
图计算系统 Plato 介绍

Plato 是腾讯开源的图计算框架,这里着重讲下 Plato 和 Gemini 的不同点。
上面我们科普过 Gemini 的 pull/push 方式:csr: part_by_dst 适用于 push 模式以及csc: part_by_src 适用于 pull 模式。相比较 Gemini,Plato 在它 pull 和 push 方式基础上新增了适用于 pull 模式的 csr: part_by_src 和适用于 push 模式的 csc: part_by_dst。这是 Plato 在分区上同 Gemini 的不同,当然 Plato 还支持 Hash 的分区方式。
在编码方面,Gemini 是支持 int 类型的顶点 ID 并不支持 String ID,但 Plato 支持 String ID 的编码。Plato 通过对String ID进行 Hash 处理计算出对应的机器,将 String ID 发送给对应机器进行编码再传回进行编码数据聚合。在一个大的 map 映射之后,每台机器都能拿到一个全局的 String ID 编码。在系统计算结束的时候需要将结果输出,这时候全局编码就可以在本地将 int ID 转回 String ID。这便是 Plato String ID 编码的原理。
Nebula Graph 与 Plato 的集成
首先 Nebula 优化了 String ID 的编码,上面说到的全局编码映射是非常消耗内存的,尤其是在生产环境上。在 Nebula 这边每台机器只保存部分的 String ID,在结果输出时由对应的机器进行 Decode 再写入磁盘。
此外还支持了 Nebula Graph 的读取和写入,可以通过 scan 接口来读取数据,再通过 nGQL 写回到 Nebula Graph 中。
在算法上面,Nebula Graph 也进行了补充,sssp 单源最短路径、apsp 全对最短路径、jaccard similary 相似度、triangle count 三角计数、clustering coefficent 聚集系数等算法。
我们的 Plato 实践文章也将会在近期发布,会有更详细的集成介绍。
图计算之 nebula-algorithm
在开始 nebula-algorithm 介绍之前,先贴一个它的开源地址:https://github.com/vesoft-inc/nebula-algorithm。
Nebula 图计算
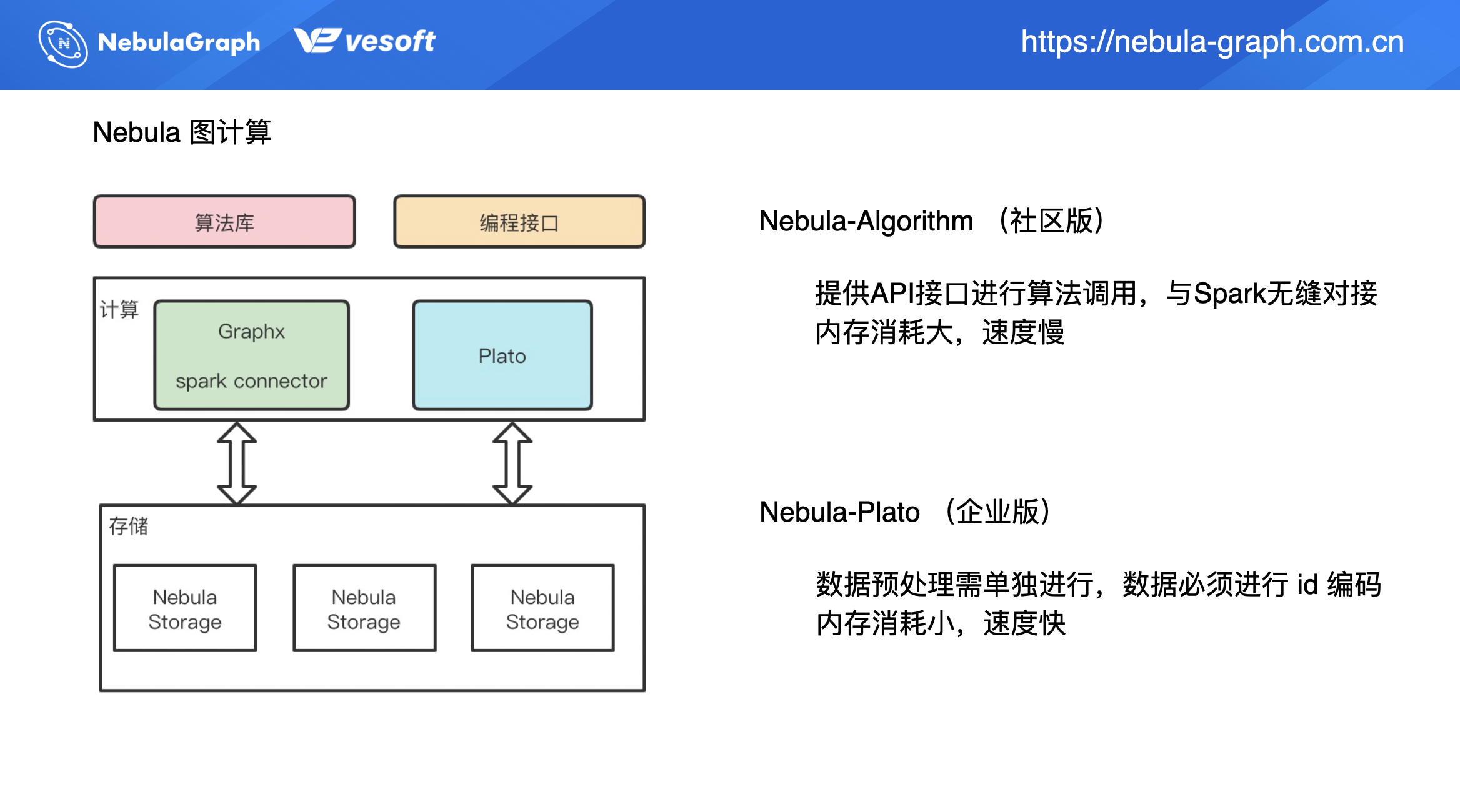
目前 Nebula 图计算集成了两种不同图计算框架,共有 2 款产品:nebula-algorithm 和 nebula-plato。
nebula-algorithm 是社区版本,同 nebula-plato 的不同之处在于,nebula-algorithm 提供了 API 接口来进行算法调用,最大的优势在于集成了 [GraphX](https://spark.apache.org/docs/latest/graphx-programming-guide.html),可无缝对接 Spark 生态。正是由于 nebula-algorithm 基于 GraphX 实现,所以底层的数据结构是 RDD 抽象,在计算过程中会有很大的内存消耗,相对的速度会比较慢。
nebula-plato 上面介绍过,数据内部要进行 ID 编码映射,即便是 int ID,但如果不是从 0 开始递增,都需要进行 ID 编码。nebula-plato 的优势就是内存消耗是比较小,所以它跑算法时,在相同数据和资源情况下,nebula-plato 速度是相对比较快的。
上图左侧是是 nebula-algorithm 和 nebula-plato 的架构,二者皆从存储层 Nebula Storage 中拉取数据。GraphX 这边(nebula-algorithm)主要是通过 Spark Connector 来拉取存储数据,写入也是通过 Spark Connector。
nebula-algorithm 使用方式
jar 包提交
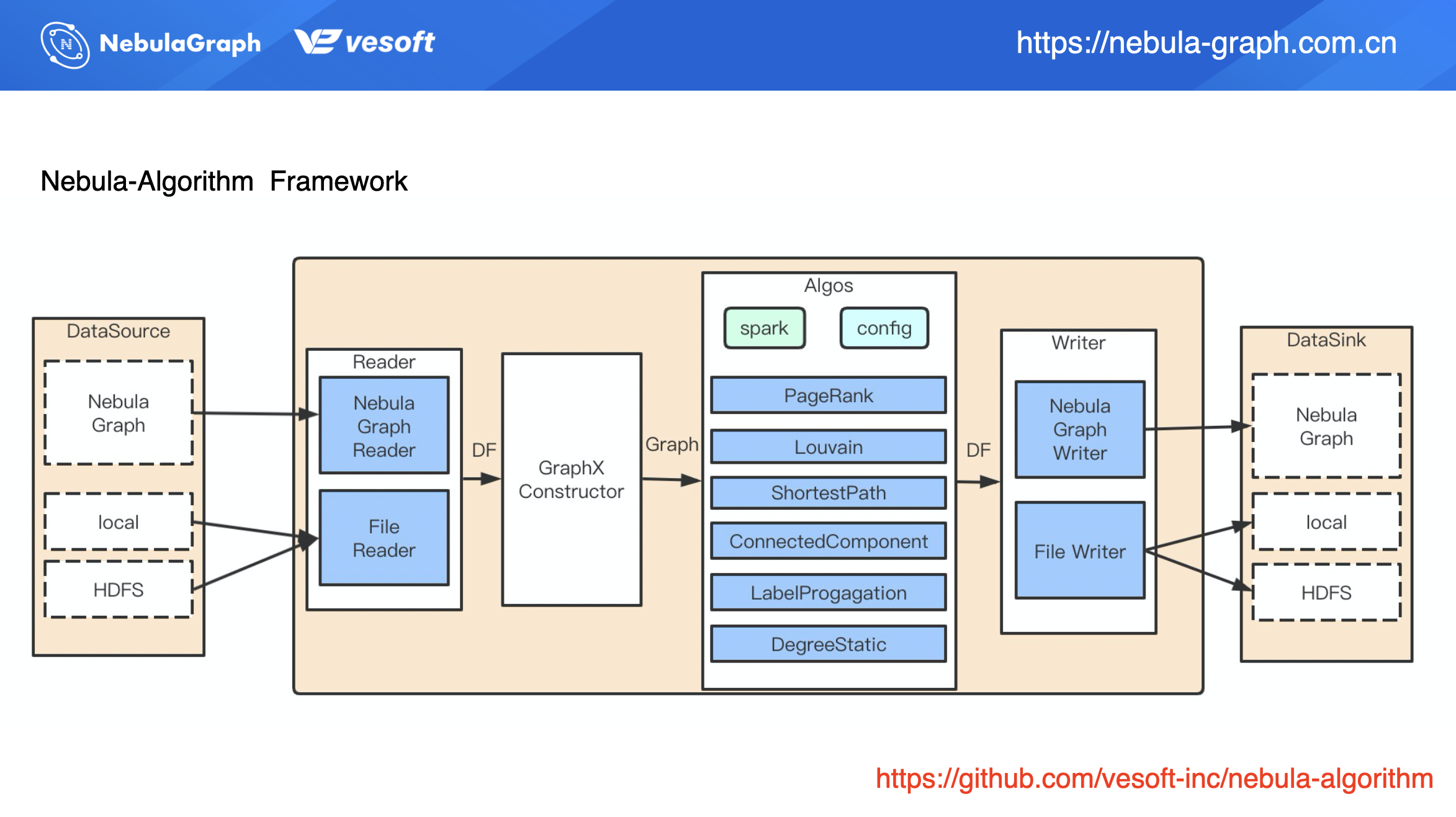
nebula-algorithm 目前是提供了两种使用方式,一种是通过直接提交 jar 包,另外一种是通过调用 API 方式。
通过 jar 包的方式整个流程如上图所示:通过配置文件配置数据来源,目前配置文件数据源支持 Nebula Graph、HDFS 上 CSV 文件以及本地文件。数据读取后被构造成一个 GraphX 的图,该图再调用** nebula-algorithm **的算法库。算法执行完成后会得到一个算法结果的 data frame(DF),其实是一张二维表,基于这张二维表,Spark Connector 再写入数据。这里的写入可以把结果写回到图数据库,也可以写入到 HDFS 上。
API 调用
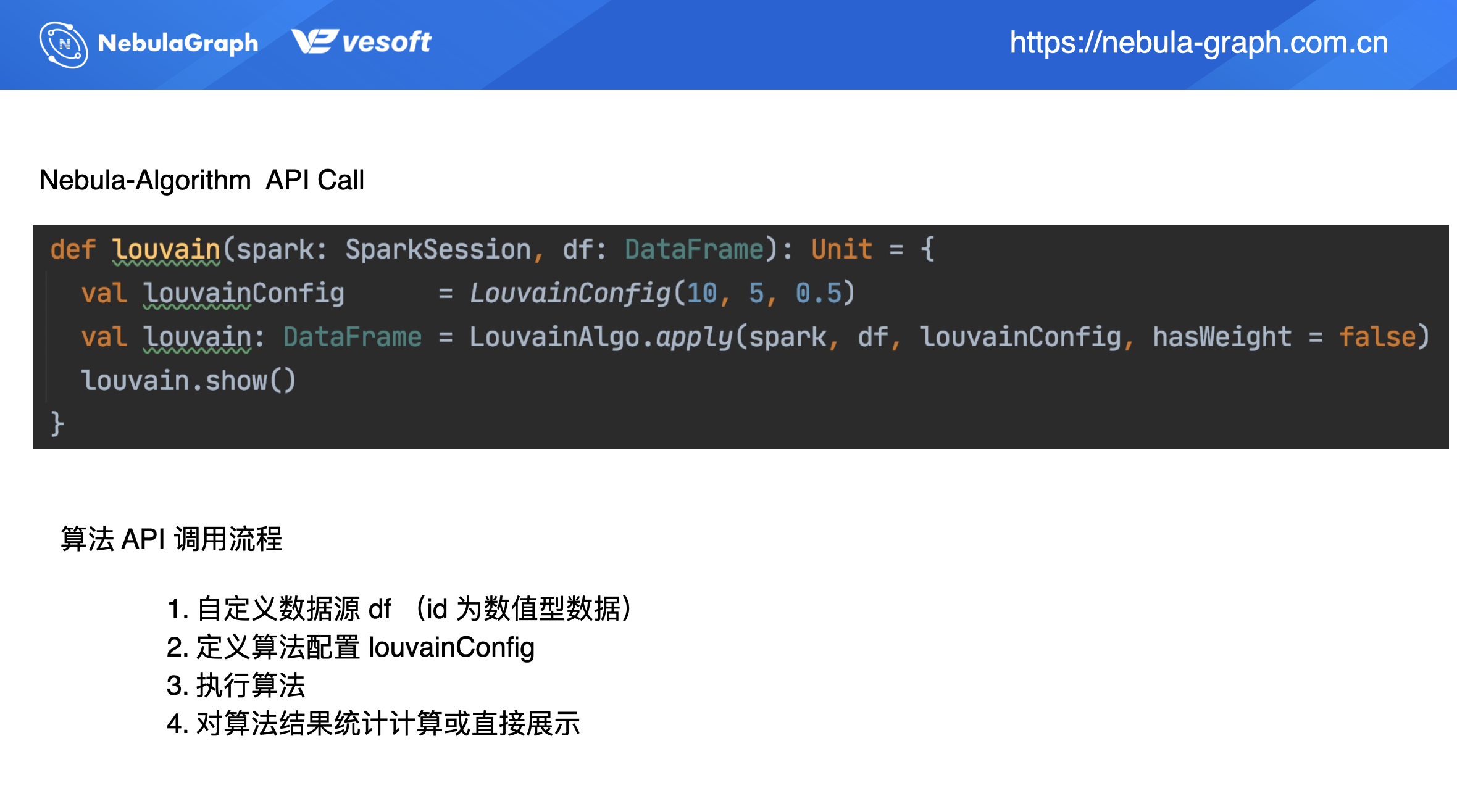
更推荐大家通过 API 调用的方式。像上面通过 jar 包形式在后面的数据写入部分是不处理数据的。而采用 API 调用方式,在数据写入部分可进行数据预处理,或是对算法结果进行统计分析。
API 调用的流程如上图所示,主要分为 4 步:
- 自定义数据源 df(id 为数值型数据)
- 定义算法配置 louvainConfig
- 执行算法
- 对算法结果统计计算或直接展示
上图的代码部分则为具体的调用示例。先定义个 Spark 入口:SparkSession,再通过 Spark 读取数据源 df,这种形式丰富了数据源,它不局限于读取 HDFS 上的 CSV,也支持读取 HBase 或者 Hive 数据。上述示例适用于顶点 ID 为数值类型的图数据,String 类型的 ID 在后面介绍。
回到数据读取之后的操作,数据读取之后将进行算法配置。上图示例调用 Louvain 算法,需要配置下 LouvainConfig 参数信息,即 Louvain 算法所需的参数,比如迭代次数、阈值等等。
算法执行完之后你可以自定义下一步操作结果统计分析或者是结果展示,上面示例为直接展示结果 louvain.show()。
ID Mapping 映射原理与实现
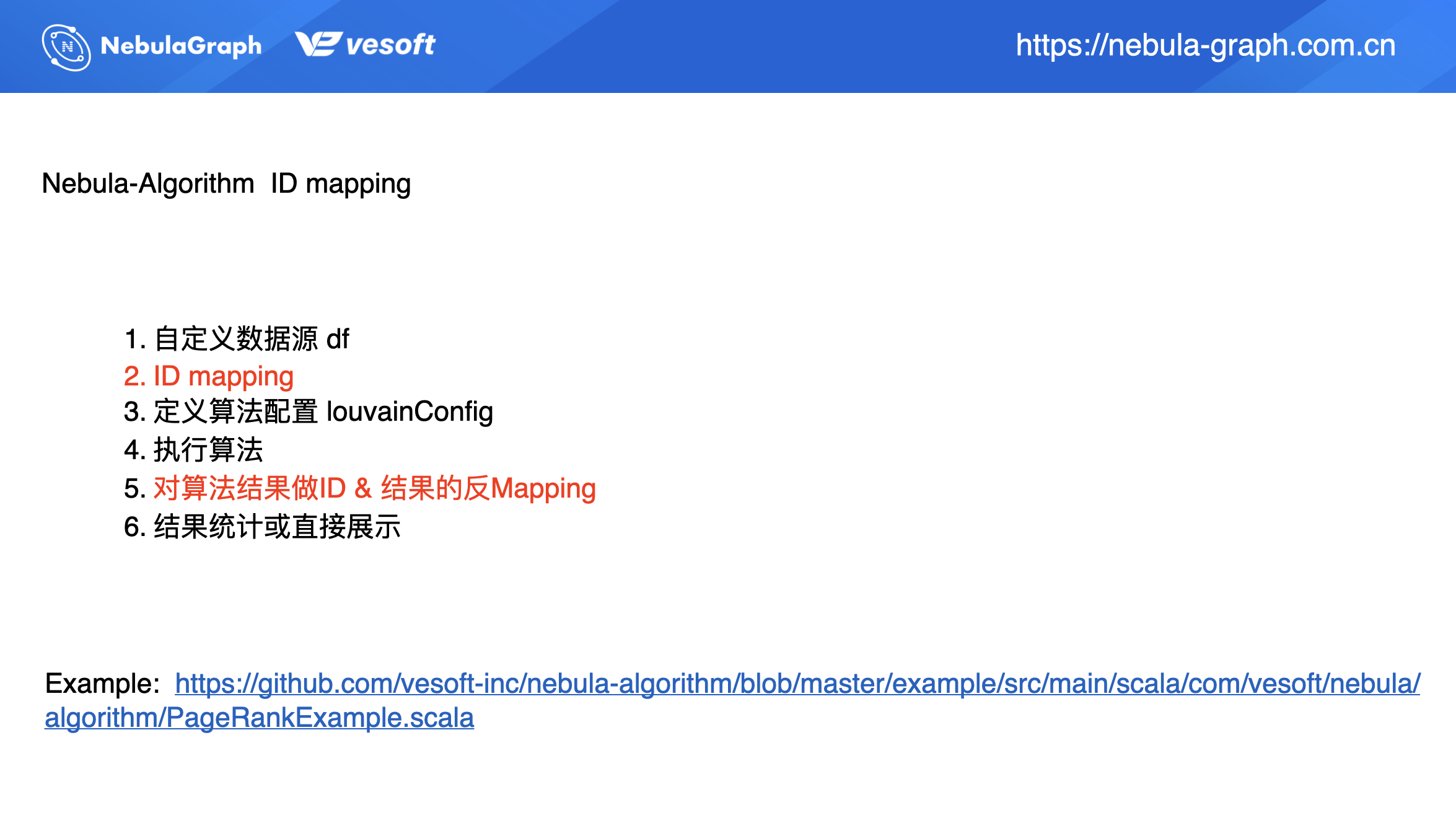
再来介绍下 ID 映射,String ID 的处理。
熟悉 GraphX 的小伙伴可能知道它是不支持 String ID 的,当我们的数据源 ID 是个 String 该如何处理呢?
同社区用户 GitHub issue 和论坛的日常交流中,许多用户都提到了这个问题。这里给出一个代码示例:https://github.com/vesoft-inc/nebula-algorithm/blob/master/example/src/main/scala/com/vesoft/nebula/algorithm/PageRankExample.scala
从上面的流程图上,我们可以看到其实同之前调用流程相同,只是多两步:ID Mapping 和 对结算结果做 ID & 结果的反 Mapping。因为算法运行结果是数值型,所以需要做一步反 Mapping 操作使得结果转化为 String 类型。
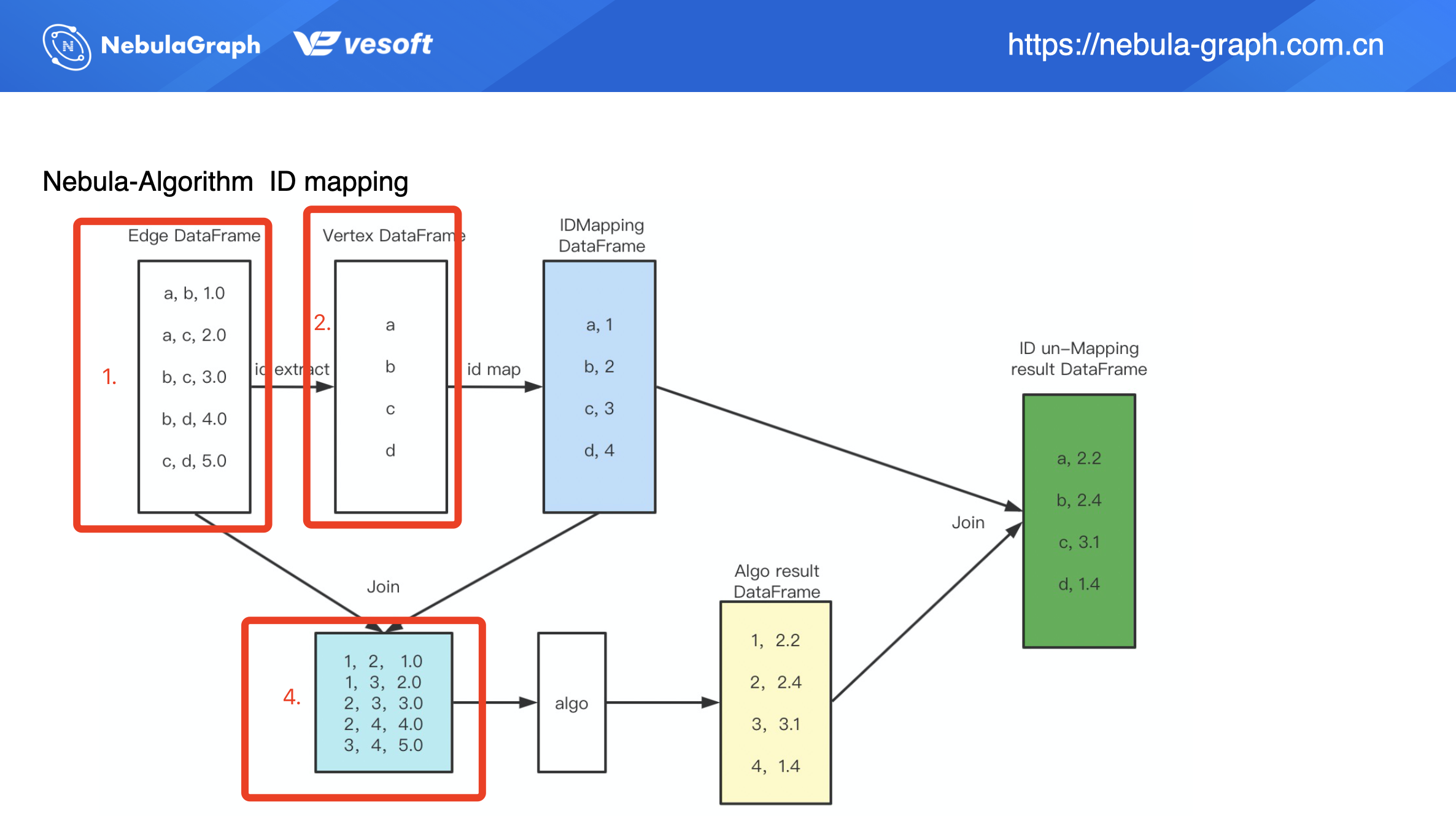
上图为 ID 映射(Mapping)的过程,在算法调用的数据源(方框 1)显示该数据为边数据,且为 String 类型(a、b、c、d),当中的 1.0、2.0 等等列数据为边权重。在第 2 步中将会从边数据中提取点数据,这里我们提取到了 a、b、c、d,提取到点数据之后通过 ID 映射生成 long 类型的数值 ID(上图蓝色框)。有了数值类型的 ID 之后,我们将映射之后的 ID 数据(蓝色框)和原始的边数据(方框 1)进行 Join 操作,得到一个编码之后的边数据(方框 4)。编码之后的数据集可用来做算法输入,算法执行之后得到数据结果(黄色框),我们可以看到这个结果是一个类似二维表的结构。
为了方便理解,我们假设现在这个是 PageRank 的算法执行过程,那我们得到的结果数据(黄色框)右列(2.2、2.4、3.1、1.4)则为计算出来的 PR 值。但这里的结果数据并非是最终结果,别忘了我们的原始数据是 String 类型的点数据,所以我们要再做下流程上的第 5 步:对结算结果做 ID & 结果的反 Mapping,这样我们可以得到最终的执行结果(绿色框)。
要注意的是,上图是以 PageRank 为例,因为 PageRank 的算法执行结果(黄框右列数据)为 double 类型数值,所以不需要做 ID 反映射,但是如果上面的流程执行的算法为连通分量或是标签传播,它的算法执行结果第二列数据是需要做 ID 反映射的。
节选下 PageRank 的代码中的实现
def pagerankWithIdMaping(spark: SparkSession, df: DataFrame): Unit = {
val encodedDF = convertStringId2LongId(df)
val pageRankConfig = PRConfig(3, 0.85)
val pr = PageRankAlgo.apply(spark, encodedDF, pageRankConfig, false)
val decodedPr = reconvertLongId2StringId(spark, pr)
decodedPr.show()
}
我们可以看到算法调用之前通过执行 val encodedDF = convertStringId2LongId(df) 来进行 String ID 到 Long 类型的映射,语句执行完之后,我们才会调用算法,算法执行之后再来进行反映射 val decodedPr = reconvertLongId2StringId(spark, pr)。
在直播视频(B站:https://www.bilibili.com/video/BV1rR4y1T73V)中,讲述了 PageRank 示例代码实现,有兴趣的小伙伴可以看下视频 24‘31 ~ 25'24 的代码讲解,当中也讲述了编码映射的实现。
nebula-algorithm 支持的算法
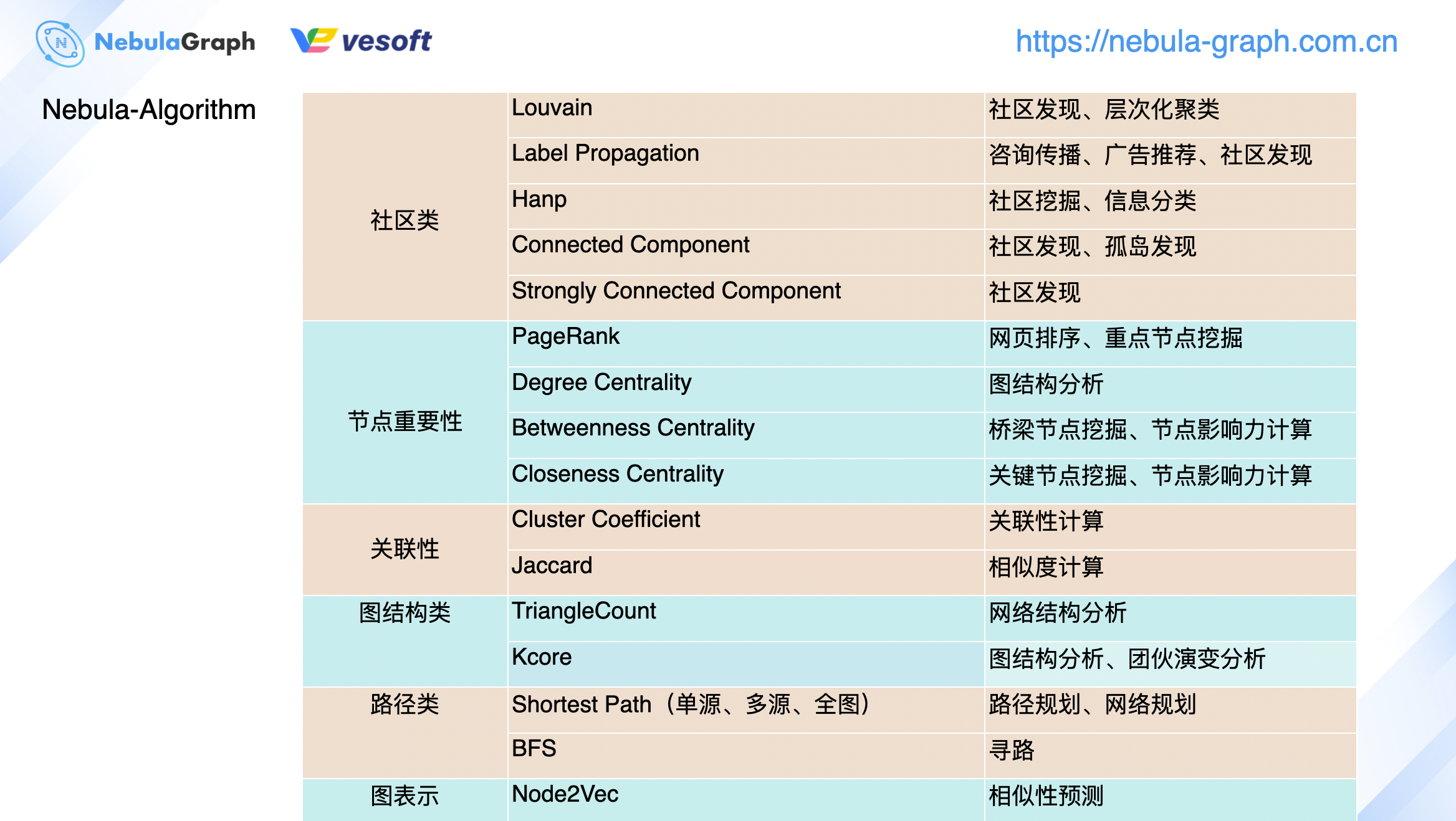
上图展示的是我们在 v3.0 版本中将会支持的图算法,当然当中部分的图算法在 v2.0 也是支持的,不过这里不做赘述具体的可以查看 GitHub 的文档:https://github.com/vesoft-inc/nebula-algorithm 。
按照分类,我们将现支持的算法分为了社区类、节点重要性、关联性、图结构类、路径类和图表示等 6 大类。虽然这里只是列举了 nebula-algorithm 的算法分类,但是企业版的 nebula-plato 的算法分类也是类似的,只不过各个大类中的内部算法会更丰富点。根据目前社区用户的提问反馈来讲,算法使用方便主要以上图的社区类和节点重要性两类为主,可以看到我们也是针对性的更加丰富这 2 大类的算法。如果你在 nebula-algorithm 使用过程中,开发了新的算法实现,记得来 GitHub 给 nebula-algorithm 提个 pr 丰富它的算法库。
下图是社区发现比较常见的 Louvain、标签传播算法的一个简单介绍:

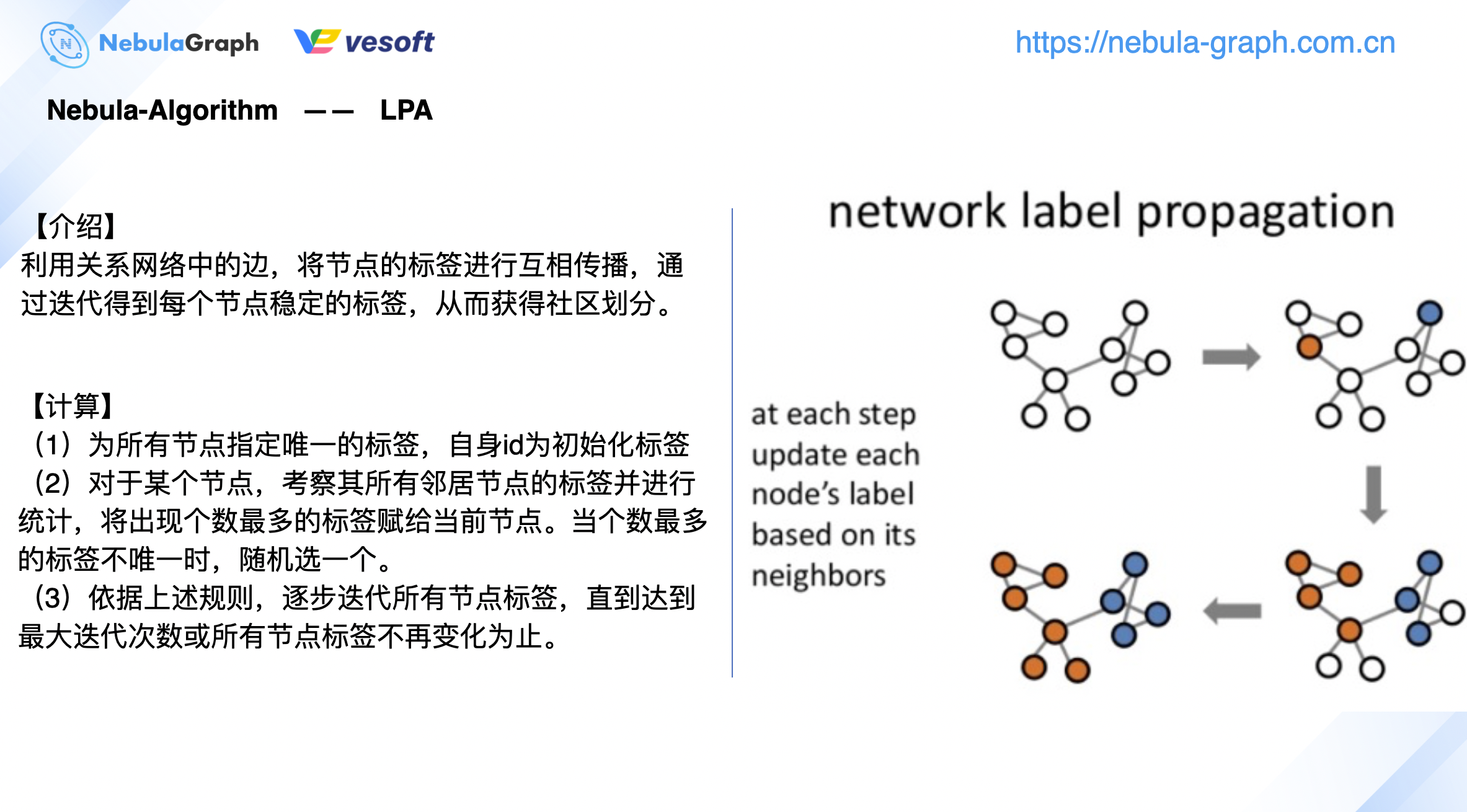
由于之前写过相关的算法介绍,这里不做赘述,可以阅读《GraphX 在图数据库 Nebula Graph 的图计算实践》。
这里简单介绍下连通分量算法
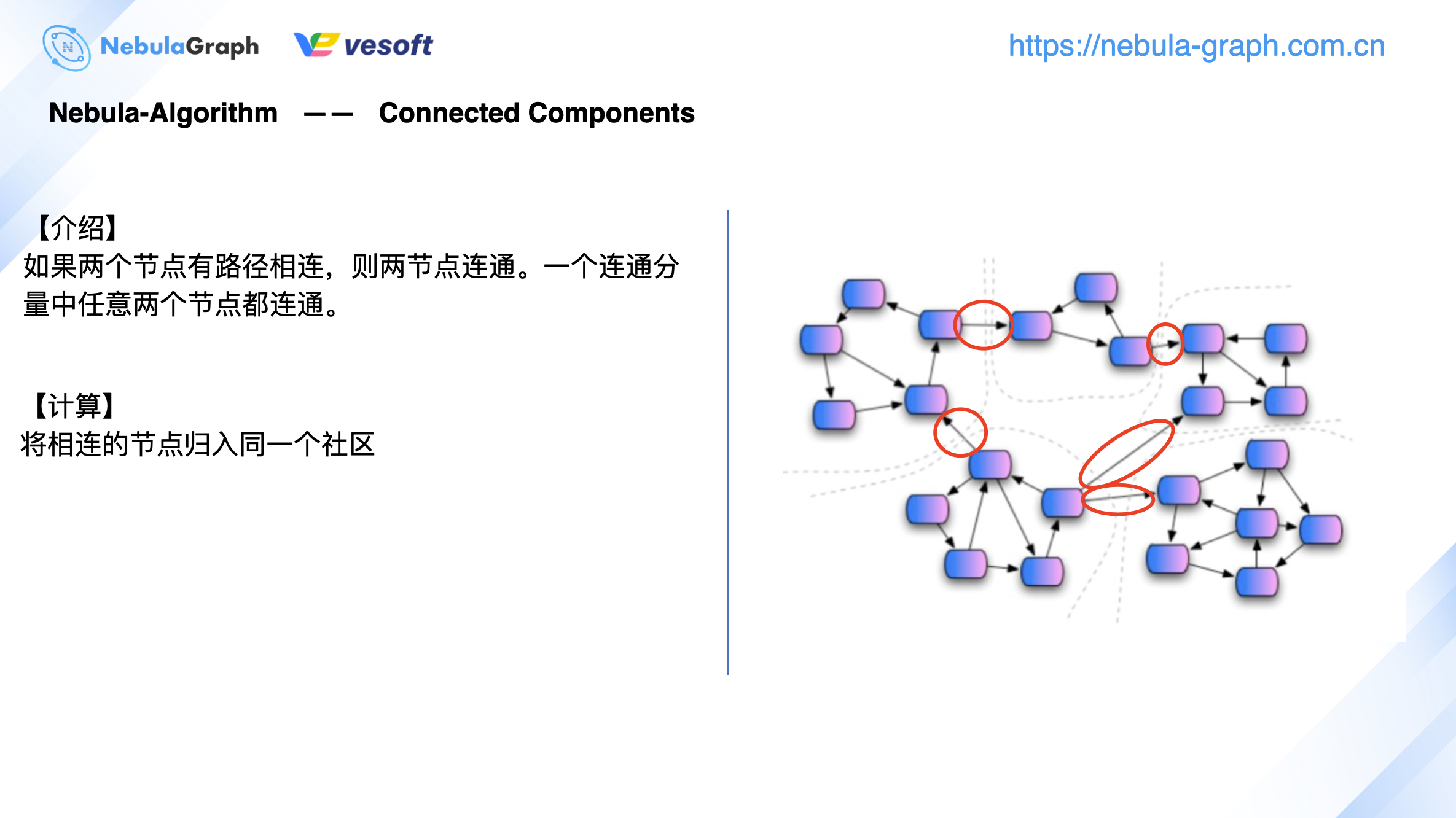
连通分量一般指的是弱连通分量,算法针对无向图,它的计算流程相对简单。如上图右侧所示,以虚线划分的 5 个小社区,在计算连通分量过程中,每个社区之间的连线(红色框)是不做计算的。你可理解为从图数据库中抽取出 1 个子图来进行 1 个联通分量的计算,计算出来有 5 个小连通分量。这时候基于全图去数据分析,不同的小社区之间又增加了连接边(红色框),将它们连接起来。
社区算法的应用场景
银行领域

再来看个具体的应用场景,在银行中存在这种情况,一个身份证号对应多个手机号、多台手机设备、多张借记卡、多张信用卡,还有多个 APP。而这些银行数据会分散存储,要做关联分析时,可以先通过联通分量来去计算小社区。举个例子:把同一个人所拥有的不同的设备、手机号等数据信息归到同一连通分量,把它们作为一个持卡人实体,再进行下一步计算。简单来说,将分散数据通过算法聚合成大节点统一分析。
安防领域
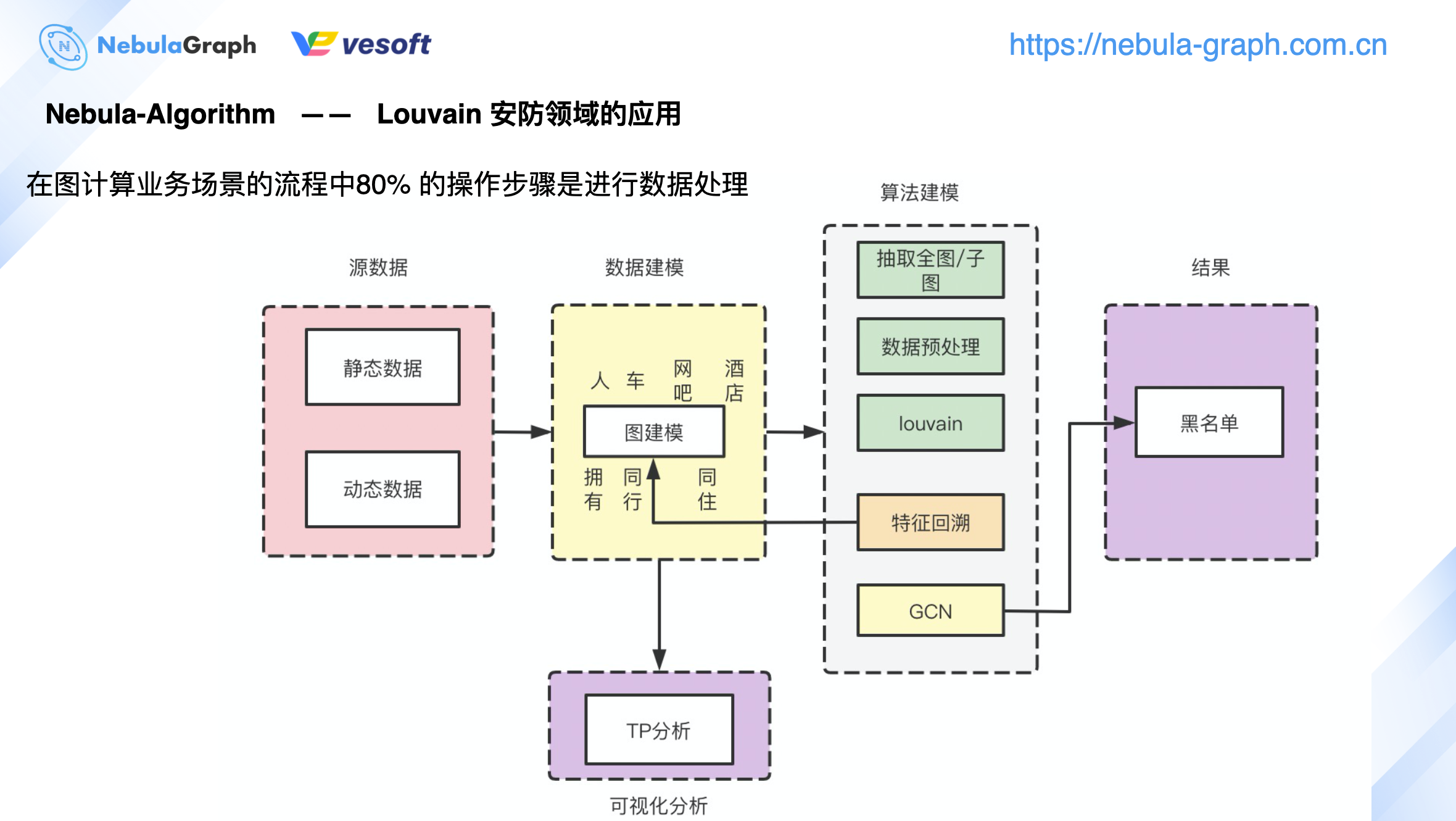
上图是 Louvain 算法在安防领域的应用,可以看到其实整个业务处理流程中,算法本身的比重占比并不高,整个处理流程 80% 左右是在对数据做预处理和后续结果进行统计分析。不同领域有不同的数据,领域源数据按业务场景进行实际的图建模。
以公安为例,通过公安数据进行人、车、网吧、酒店等实体抽取,即图数据库中可以分成这 4 个 tag(人、车、网吧、酒店),基于用户的动态数据抽象出拥有关系、同行关系、同住关系,即对应到图数据库中的 Edge Type。完成数据建模之后,再进行算法建模,根据业务场景选择抽取全图,还是抽取子图进行图计算。数据抽取后,需要进行数据预处理。数据预处理包括很多操作,比如将数据拆分成两类,一类进行模型训练,另外一类进行模型验证;或是对数据进行权重、特征方面的数值类转换,这些都称为数据的一个预处理。
数据预处理完之后,执行诸如 Louvain、节点重要程度之类的算法。计算完成后,通常会将基于点数据得到的新特征回溯到图数据库中,即图计算完成后,图数据库的 Tag 会新增一类属性,这个新属性就是 Tag 的新特征。计算结果写回到图数据库后,可将图数据库的数据读取到 Studio 画布进行可视化分析。这里需要领域专家针对具体业务需求进行可视化分析,或者数据完成计算后进入到 GCN 进行模型训练,最终得到黑名单。
以上为本次图计算的概述部分,下面为来自社区的一些相关提问。
社区提问
这里摘录了部分的社区用户提问,所有问题的提问可以观看直播视频 33‘05 开始的问题回复部分。
算法内部原理
dengchang:想了解下图计算各类成熟算法的内部原理,如果有结合实际场景跟数据的讲解那就更好了。
Nicole:赵老师可以看下之前的文章,比如:
一些相对比较复杂的算法,在直播中不便展开讲解,后续会发布文章来详细介绍。
图计算的规划
en,coder:目前我看到 Nebula Algorithm 计算要将数据库数据导出到 Spark,计算完再导入到数据库。后续是否考虑支持不导出,至少轻量级算法的计算,结果展示在 Studio。
Nicole:先回复前面的问题,其实用 nebula-algorithm 计算完不一定要将结果导入到图数据库,目前 nebula-algorithm 的 API 调用和jar 包提交两种方式均允许把结果写入到 HDFS。是否要将结果数据导入图数据库取决于你后续要针对图计算结果进行何种处理。至于“后续是否支持不导出,至少轻量级的计算”,我的理解轻量级的算法计算是不是先把数据从图数据库中查出来,在画布展示,再针对画布中所展示出来的一小部分数据进行轻量级计算,计算结果立马去通过 Studio 展示在画布中,而不是在写回到图数据库。如果是这样的话,其实后续 Nebula 有考虑去做个图计算平台,结合了 AP 和 TP,针对画布中的数据,也可以考虑进行简单的轻量级计算,计算结果是否要写回到图数据库由用户去配置。回到需求本身,是否进行画布数据的轻量级计算还是取决于你的具体场景,是否需要进行这种操作。
潮与虎:nebula-algorithm 打算支持 Flink 吗?
Nicole:这里可能指的是 Flink 的 Gelly 做图计算,目前暂时没有相关的打算。
繁凡:有计划做基于 nGQL 的模式匹配吗?全图的 OLAP 计算任务,实际场景有一些模式匹配的任务,一般自己开发代码,但是效率太低。
郝彤:模式匹配是个 OLTP 场景,TP 受限于磁盘的速度较慢,所以想用在 OLAP 上,但是 OLAP 通常是处理传统算法,不支持模式匹配。其实后续 AP 和 TP 融合之后,图数据放在内存中,速度会提升。
图计算的最佳实践案例
戚名钰:利用图计算能力做设备风险画像的问题,业界有哪些最佳实践?比如在群控识别、黑产团伙挖掘上面,有没有相关业界的最佳实践分享?
Nicole:具体业务问题需要依靠运营同学同社区用户约稿,从实际案例中讲解图计算更有价值。
图计算内存资源配置
刘翊:如何评估图计算所需的内存总量。
郝彤:因为不同的图计算系统设计不同,内存使用量也就不一样。即便是同一个图计算系统,不同的算法对于内存的需求也存在些差异,可以先通过 2、3 种不同数据进行测试,以便评估出最佳的资源配置。
以上为图计算 on nLive 的分享,你可以通过观看 B站视频:https://www.bilibili.com/video/BV1rR4y1T73V 查看完整的分享过程。如果你在使用 nebula-algorithm 和 nebula-plato 过程中遇到任何使用问题,欢迎来论坛同我们交流,论坛传送门:https://discuss.nebula-graph.com.cn/ 。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号