OPPO 图数据库平台建设及业务落地

本文首发于 OPPO 数智技术公众号,WeChat ID: OPPO_tech
1、什么是图数据库
图数据库(Graph database)是以图这种数据结构存储和查询的数据库。与其他数据库不同,关系在图数据库中占首要地位。这意味着应用程序不必使用外键或带外处理(如 MapReduce)来推断数据连接。与关系数据库或其他 NoSQL 数据库相比,图数据库的数据模型也更加简单,更具表现力。
图数据库在社交网络、知识图谱、金融风控、个性化推荐、网络安全等领域应用广泛。
2、图数据库调研
2.1、调研背景
随着知识图谱等业务数据的不断增长,现有图数据库 JanusGraph 应对已经比较吃力,导入时间已经无法满足业务的要求。因此寻找性能更好的开源属性图数据库已经成为了当前迫切要做的事情。
新图数据库应满足以下要求:
- 能够支持 10 亿节点 100 亿边 170 亿属性的大规模图谱
- 全量导入时间不超过 10h
- 二度查询平均响应时间不超过 50ms,QPS 能够达到 5000+
- 开源且支持分布式的属性图数据库
2.2、调研过程
第一步,搜集常见的开源分布式属性图数据库,如下表:
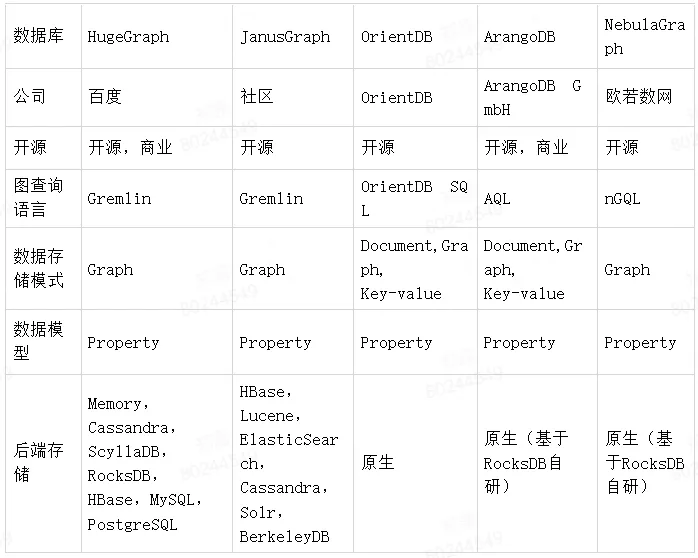
第二步,基于美团、LightGraph、TigerGraph、GalaxyBase 等图数据库测试报告,分析可得几个图数据库性能如下:
- 导入:Nebula Graph > HugeGraph > JanusGraph > ArangoDB > OrientDB
- 查询:Nebula Graph > HugeGraph > JanusGraph > ArangoDB > OrientDB
Nebula Graph不论是在导入还是在查询性能上都表现优异。
第三步,为了验证 Nebula Graph 的性能,对 Nebula Graph 和 JanusGraph 进行了一次性能对比测试,测试结果如下:
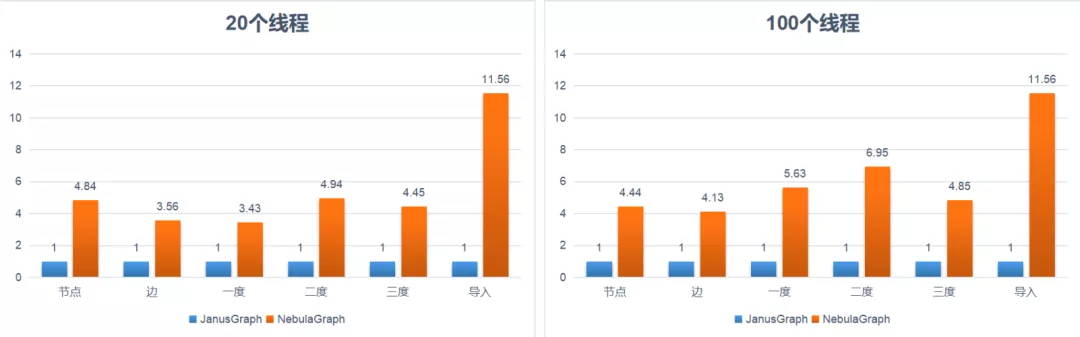
上图中,将 JanusGraph 性能看作 1,Nebula Graph 导入性能要比 JanusGraph 快一个数量级,查询性能是 JanusGraph 的 4-7 倍。而且随着并发量的增大,性能差距会进一步拉大,而且 JanusGraph 在从 20 个线程开始,三度邻居查询会有 error。而 Nebula Graph 没有任何 error。
Nebula Graph 全量导入 10 亿节点 100 亿边只需要 10h,满足要求,目前正在调研 SST 导入,可以大幅提升导入速度。
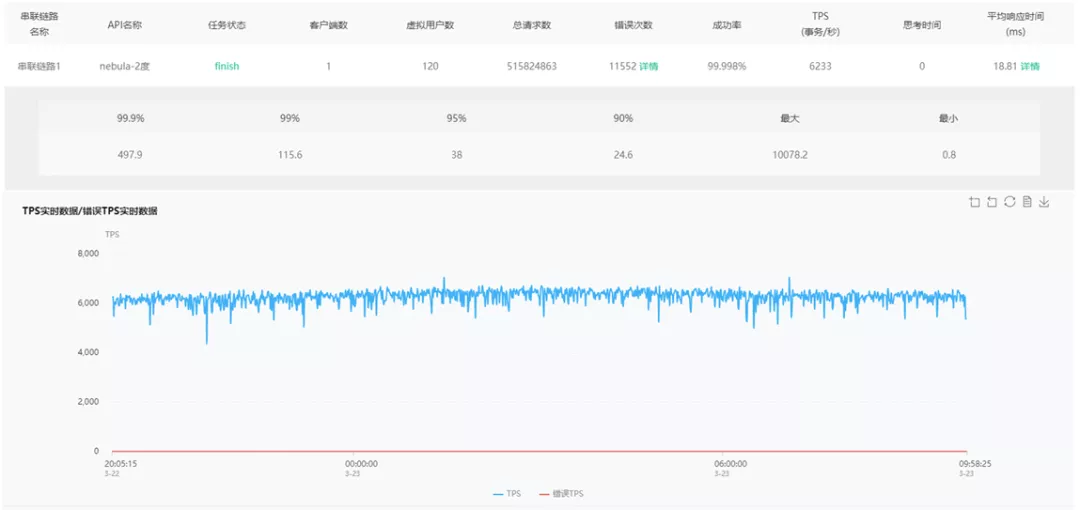
对 Nebula Graph 使用 120 个线程进行二度邻居查询压测,最终 QPS 在 6000+,相比单机有一些提升。成功率接近 5 个 9,而且响应时间比较稳定,平均 18.81ms,p95 38ms,p99 也才115.6ms,符合需求。
2.3、调研结论
Nebula Graph 导入性能、响应时间、以及稳定性均符合需求,支持数据切分,分布式版本免费开源,使用的企业也多,中文文档,文档全面,社区活跃,是开源图数据库的理想选择。
3、Nebula Graph 简介
图片来源于 Nebula Graph 文档站
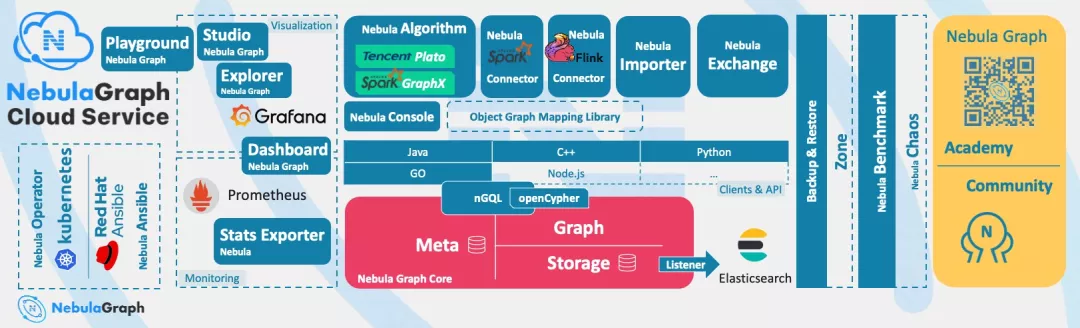
Nebula Graph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
Nebula Graph 基于图数据库的特性使用 C++ 编写,采用 shared-nothing 架构,支持在不停止数据库服务的情况下扩缩容,而且提供了非常多原生工具,例如 Nebula Graph Studio、Nebula Console、Nebula Exchange 等,可以大大降低使用图数据库的门槛。
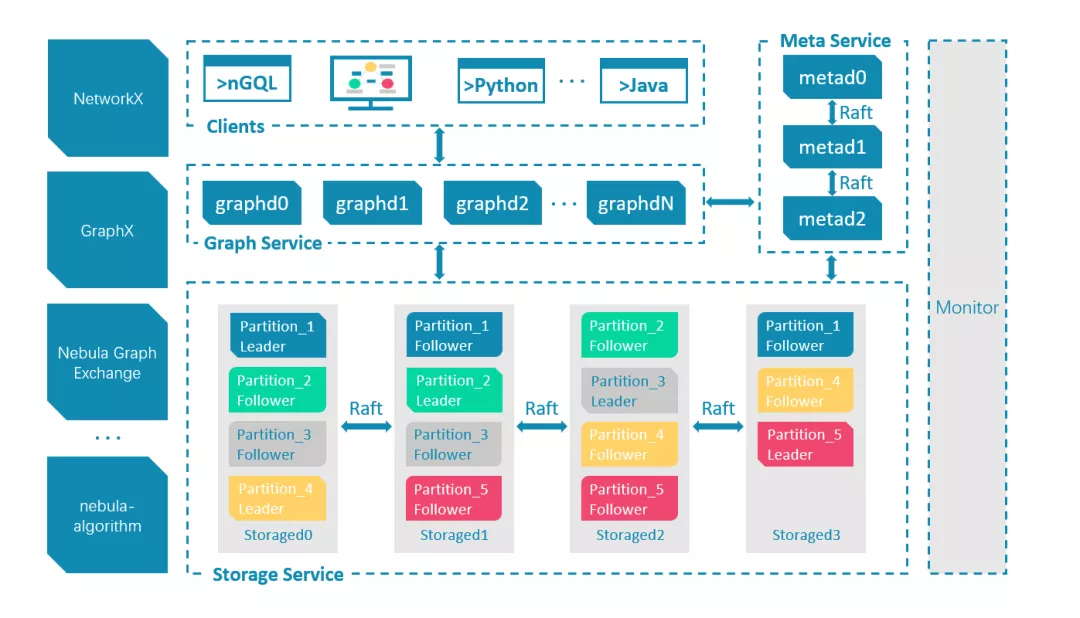
图片来源于 Nebula Graph 文档站
Nebula Graph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
Meta 服务负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。服务是由 nebula-metad 进程提供的,生产环境中,建议在 Nebula Graph 集群中部署3个 nebula-metad 进程。请将这些进程部署在不同的机器上以保证高可用。所有 nebula-metad 进程构成了基于 Raft 协议的集群,其中一个进程是 leader,其他进程都是 follower。
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤,服务是由 nebula-graphd 进程提供的,可以部署多个。
Storage 服务负责存储数据,服务是由 nebula-storaged 进程提供的,所有nebula-storaged 进程构成了基于 Raft 协议的集群,数据在 nebula-storaged 中分区存储,每个分区都有一个 leader,其它副本集构成该分区的 follower。
4、图数据库平台建设
之前在使用 JanusGraph 的时候,遇到过导入缓慢、查询慢、高并发 OOM(JanusGraph 线程池采用无界队列导致)、FULL GC(业务 Gremlin 语句中包含 Value 导致元空间不断膨胀导致)等问题,这些在切到 Nebula Graph 后基本得到了解决。
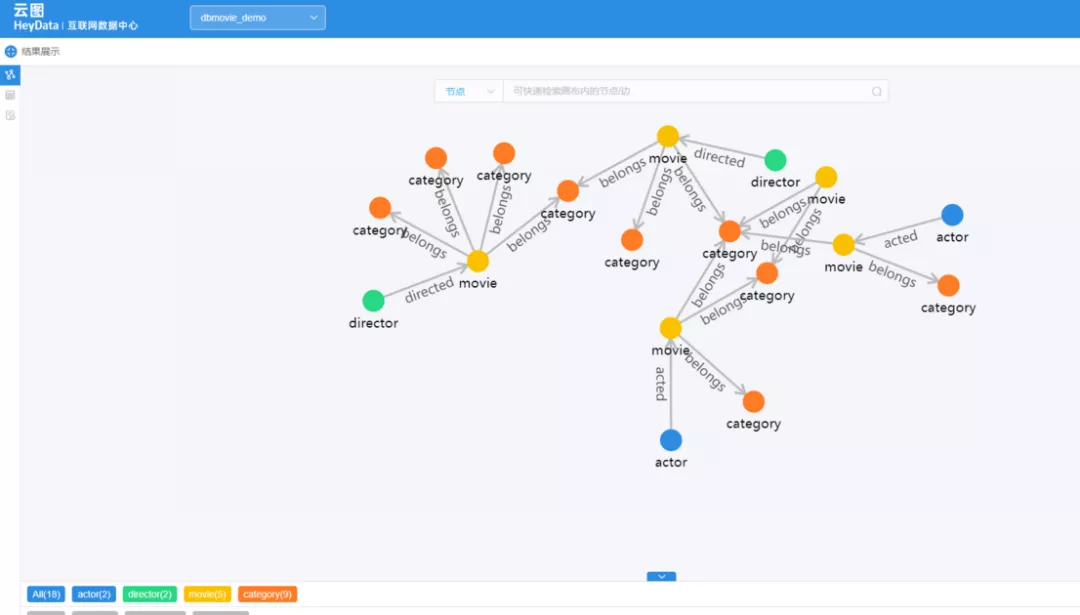
JanusGraph 并没有好用的管理界面,如上图所示,我们开发了一套包含多图管理、Schema 管理、图可视化、图导入、权限管理的管理界面。
而 Nebula Graph Studio 提供多图管理、Schema 管理、图可视化、图导入等功能,省去了很多开发工作,降低了使用门槛。

整个图数据库平台的结构如上图所示,基于 Nebula Graph 和 Nebula Graph 官方工具,着重开发了 全量导入、增量导入、图导出、备份/还原、查询工程(图检索)等功能。
官方导入工具需要提供导入配置文件,为了更便于业务使用,我们设计了一个 schema 配置表格,业务只需填好表格,导入的时候会自动创图,创建图的 schema,自动生成导入配置文件,自动导入数据,自动平衡数据,平衡leader, 创建索引,执行 compact 任务。当前还是批量写入的导入方式,后续会调研 SST 导入,导入性能可进一步提升。
官方提供的导入工具采用的是异步客户端,导入时极难控制导入速率,设置过大,容易导致图数据库请求积压,影响集群的稳定运行。设置过小,速度无法达到最优,导入过慢。我们修改了官方导入工具源码,将异步客户端改成了同步客户端,可以兼顾性能和稳定性。
官方没有提供导出工具,我们基于官方的 nebula-spark 开发了一个导出工具,除了能够导出数据,还能够导出 Schema 配置以及索引配置,便于业务做数据迁移。
为了支持数据回滚,我们开发了指定图谱的数据快速备份和还原的功能,不过该功能无法备份图谱元数据,全量导入会删除并重建图谱,由于元数据发生变化,之前的备份就没有用了。后续会尝试全量导入只清理数据不删图的方式来避免这个问题。
知识图谱业务的边类型非常多,经常一次查询需要查询几十上百种边,每种类型的边其实只需要返回 Top 10(根据rank排序)个结果就好。这种情况通过 nGQL 很不好实现,只能查询这些边的所有数据,或者所有边合在一起的 Top N 个数据,前者有性能问题,后者经常只能返回部分类型边的数据,无法满足需求。针对这种情况,我们对边进行了分类,对于数量较少的那些边类型,一条语句查询所有数据。对于数量多的边类型,使用多线程并行查询每条边的Top 10,这样就能进行一定的规避。
为了保证服务的高可用,我们实现了双机房部署。为了不让上层业务感知机房切换,在图数据库上层做了查询工程(图检索),业务直接调用查询工程的服务,查询工程会根据集群状态选择合适的图数据库集群查询。另外,为了向上层业务屏蔽底层图数据库变更和版本升级,查询工程会管理所有业务的查询语句。遇到图数据库因为版本升级出现查询语句不兼容的时候,只需要在查询工程中将图查询语言进行调整就好,避免波及上层业务。同时,查询工程也对查询结果进行了缓存,可以极大的提高图查询的吞吐量。
当然我们还遇到一些问题,如rank因大小端问题导致排序失效、查询结果只返回边类型id等,因为篇幅原因,在此不一一列举,这些问题通过 Nebula Graph 社区帮助,已经得到了规避或解决。
*注意:以上提到的 Nebula Graph 问题仅针对 V1.2.0 版本,很多问题后续版本已经修复。
5、业务落地
5.1、知识图谱及智能问答
在使用图谱之前,小布助手只支持基于文档的问答 DBQA,DBQA 利用的是非结构化的文本,适合回答 Why、How 等解释性、论述性问题,而对于事实性问题回答准确率和覆盖率不高。
在使用图谱后,小布助手支持基于知识库的问答 KBQA,在 What、When 等事实性问题的准确率和覆盖率大幅度提升。例如:xxx的老婆是?xxx奥特曼的体重是多少?北京的面积是多少?
除了事实性问答,小布助手还可以利用图谱的推理能力实现一些复杂问答:例如:xxx和xxx是什么关系?OPPO发布的第一款手机是什么?xxx和xxx共同参演的电影有哪些?出生在xx的双子座明星有哪些?
由于知识图谱存在规模庞大的半结构化数据,而且数据之间存在很多的关联关系,使用关系型数据库是无法满足存储和查询要求的,而图数据库恰恰能够解决大规模图谱存储和多跳查询的挑战。
5.2、内容标签

在一些推荐场景中,需要理解视频、音频或文本的内容,给其打上和内容相关的标签。例如在短视频推荐中,理解视频的内容有利于对用户进行精准推荐。
对于影视类视频,将演员、影视节目、扮演角色构造成一个影视娱乐图谱,当有新的影视类短视频发布时,可以通过视频中人脸识别出演员、标题或字幕中识别出影视角色,利用图谱快速推理出对应的影视作品,给视频打上内容标签,从而提升推荐效果。
5.3、数据血源
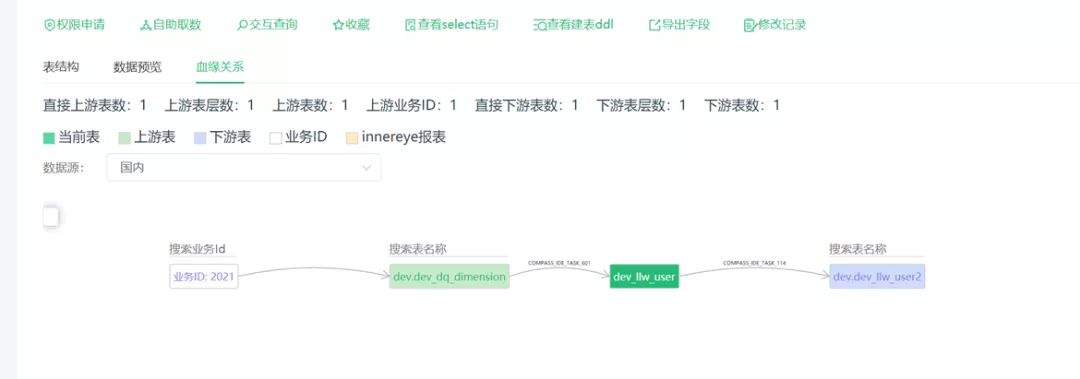
在数仓中,经常需要运行各种 ETL Job,数据表和任务非常多,如何直观的观察数据表上下游与任务之间的关系变成一个亟需解决的问题。
使用关系型数据库处理多层级的关联查询非常麻烦,不仅开发工作量大,而且查询性能极慢。而使用图数据库,不仅大大减少了开发工作量,而且能够快速的查出表的上下游关系,便于直观观察数据的血缘关系。
5.4、服务架构拓扑

在服务资源管理中,业务资源会分为多个层级,每个层级下面有对应的服务器、服务和管理人员,如果使用关系数据库来处理,当需要展示多级资源的时候,查询会很麻烦,性能会很差。这个时候,可以将资源、管理人员、服务器、业务层级之间的关系放到图数据库中,展示的时候,一条查询语句就能搞定,查询速度还很快。
6、总结
通过知识图谱等业务实践落地,完成了从 JanusGraph 向 Nebula Graph 的转变,导入性能提升了一个数量级,查询性能以及并发能力都有 3-6 倍的提升。而且,Nebula Graph 比 JanusGraph 更稳定。在实践的过程中,也遇到过很多问题,得到了 Nebula Graph 社区非常多的帮助,十分感谢社区的支持!
图数据库在最近这几年发展很快,Neo4j 今年上半年融资3.25 亿美金,刷新了数据库的融资记录。Gartner 发布的报告指出:“到 2023 年,图技术将促进全球 30% 企业的快速决策场景化。图技术应用的年增长率超过 100%。”随着 5G 和物联网的普及,图数据库将成为处理关系的基础设施。
7、参考文档
- 1.数据结构:什么是图:https://blog.csdn.net/dudu3332/article/details/104682280
- 2.Nebula Graph 架构总览:https://docs.nebula-graph.com.cn/2.0.1/1.introduction/3.nebula-graph-architecture/1.architecture-overview/
- 3.越来越火的图数据库究竟是什么?https://www.cnblogs.com/mantoudev/p/10414495.html
- 4.图的应用场景:https://help.aliyun.com/document_detail/134191.html
- 5.最全的知识图谱技术综述:https://www.sohu.com/a/196889767_151779
- 6.KBQA 从入门到放弃:https://www.sohu.com/a/163278588_500659
- 7.graphdb-benchmarks:https://github.com/socialsensor/graphdb-benchmarks
- 8.主流开源分布式图数据库 Benchmark:https://discuss.nebula-graph.com.cn/t/topic/1377
- 9.图数据库 LightGraph 测试报告:https://zhuanlan.zhihu.com/p/79426763
- 10.TigerGraph 官方测试:https://www.tigergraph.com.cn/developers/graph-benchmark/comparison/
- 11.GalaxyBase 官方测试:https://blog.csdn.net/qq_41604676/article/details/117331328
作者简介
Qirong, OPPO 高级后端工程师, 主要从事图数据库、图计算及相关领域的工作。
本文中如有任何错误或疏漏,欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.com.cn/ 的 建议反馈 分类下提建议 👏;交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号