浅析图数据库 Nebula Graph 数据导入工具——Spark Writer

从 Hadoop 说起
近年来随着大数据的兴起,分布式计算引擎层出不穷。Hadoop 是 Apache 开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用。Hadoop 的设计核心思想来源于 Google MapReduce 论文,灵感来自于函数式语言中的 map 和 reduce 方法。在函数式语言中,map 表示针对列表中每个元素应用一个方法,reduce 表示针对列表中的元素做迭代计算。通过 MapReduce 算法,可以将数据根据某些特征进行分类规约,处理并得到最终的结果。
再谈 Apache Spark
Apache Spark 是一个围绕速度、易用性构建的通用内存并行计算框架。在 2009 年由加州大学伯克利分校 AMP 实验室开发,并于 2010 年成为 Apache 基金会的开源项目。Spark 借鉴了 Hadoop 的设计思想,继承了其分布式并行计算的优点,提供了丰富的算子。
Spark 提供了一个全面、统一的框架用于管理各种有着不同类型数据源的大数据处理需求,支持批量数据处理与流式数据处理。Spark 支持内存计算,性能相比起 Hadoop 有着巨大提升。Spark 支持 Java,Scala 和 Python 三种语言进行编程,支持以操作本地集合的方式操作分布式数据集,并且支持交互查询。除了经典的 MapReduce 操作之外,Spark 还支持 SQL 查询、流式处理、机器学习和图计算。
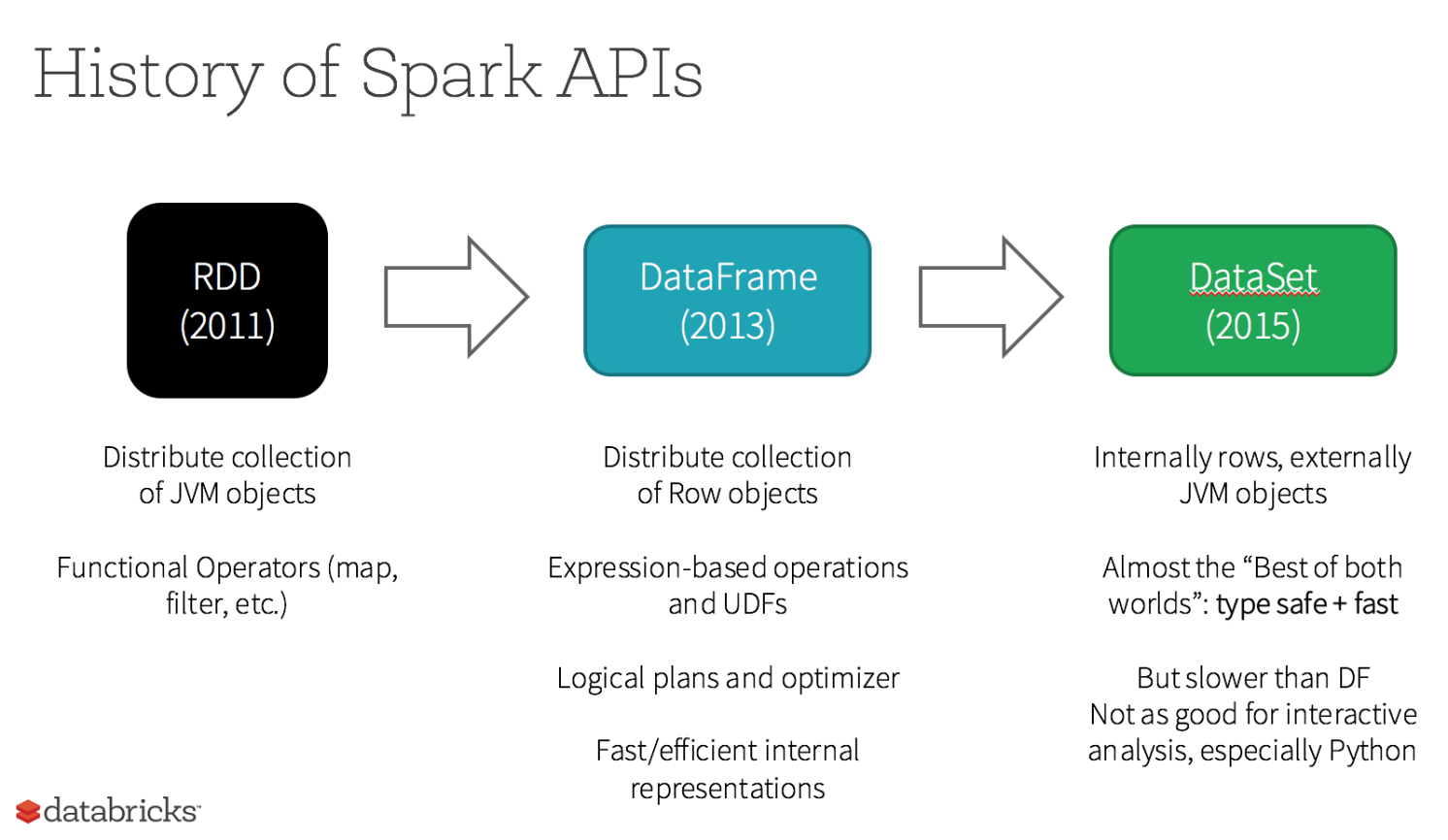
弹性分布式数据集(RDD,Resilient Distributed Dataset)是 Spark 最基本的抽象,代表不可变的分区数据集。RDD 具有可容错和位置感知调度的特点。操作 RDD 就如同操作本地数据集合,而不必关心任务调度与容错等问题。RDD 允许用户在执行多个查询时,显示地将工作集合缓存在内存中,后续查询能够重用该数据集。RDD 通过一系列的转换就就形成了 DAG,根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage。
与 RDD 相似,DataFrame 也是一个不可变分布式数据集合。区别于 RDD,DataFrame 中的数据被组织到有名字的列中,就如同关系型数据库中的表。设计 DataFrame 的目的就是要让对大型数据集的处理变得更简单,允许开发者为分布式数据集指定一个模式,便于进行更高层次的抽象。
DataSet 是一个支持强类型的特定领域对象,这种对象可以函数式或者关系操作并行地转换。DataSet 就是一些有明确类型定义的 JVM 对象的集合,可以通过 Scala 中定义的 Case Class 或者 Java 中的 Class 来指定。DataFrame 是 Row 类型的 Dataset,即 Dataset[Row]。DataSet 的 API 是强类型的;而且可以利用这些模式进行优化。
DataFrame 与 DataSet 只在执行行动操作时触发计算。本质上,数据集表示一个逻辑计划,该计划描述了产生数据所需的计算。当执行行动操作时,Spark 的查询优化程序优化逻辑计划,并生成一个高效的并行和分布式物理计划。
基于 Spark 的数据导入工具
Spark Writer 是 Nebula Graph 基于 Spark 的分布式数据导入工具,基于 DataFrame 实现,能够将多种数据源中的数据转化为图的点和边批量导入到图数据库中。
目前支持的数据源有:Hive 和HDFS。
Spark Writer 支持同时导入多个标签与边类型,不同标签与边类型可以配置不同的数据源。
Spark Writer 通过配置文件,从数据中生成一条插入语句,发送给查询服务,执行插入操作。Spark Writer 中插入操作使用异步执行,通过 Spark 中累加器统计成功与失败数量。
获取 Spark Writer
编译源码
git clone https://github.com/vesoft-inc/nebula.git
cd nebula/src/tools/spark-sstfile-generator
mvn compile package
标签数据文件格式
标签数据文件由一行一行的数据组成,文件中每一行表示一个点和它的属性。一般来说,第一列为点的 ID ——此列的名称将在后文的映射文件中指定,其他列为点的属性。例如Play标签数据文件格式:
{"id":100,"name":"Tim Duncan","age":42}
{"id":101,"name":"Tony Parker","age":36}
{"id":102,"name":"LaMarcus Aldridge","age":33}
边类型数据文件格式
边类型数据文件由一行一行的数据组成,文件中每一行表示一条边和它的属性。一般来说,第一列为起点 ID,第二列为终点 ID,起点 ID 列及终点 ID 列会在映射文件中指定。其他列为边属性。下面以 JSON 格式为例进行说明。
以边类型 follow 数据为例:
{"source":100,"target":101,"likeness":95}
{"source":101,"target":100,"likeness":95}
{"source":101,"target":102,"likeness":90}
{"source":100,"target":101,"likeness":95,"ranking":2}
{"source":101,"target":100,"likeness":95,"ranking":1}
{"source":101,"target":102,"likeness":90,"ranking":3}
配置文件格式
Spark Writer 使用 HOCON 配置文件格式。HOCON(Human-Optimized Config Object Notation)是一个易于使用的配置文件格式,具有面向对象风格。配置文件由 Spark 配置段,Nebula 配置段,以及标签配置段和边配置段四部分组成。
Spark 信息配置了 Spark 运行的相关参数,Nebula 相关信息配置了连接 Nebula 的用户名和密码等信息。 tags 映射和 edges 映射分别对应多个 tag/edge 的输入源映射,描述每个 tag/edge 的数据源等基本信息,不同 tag/edge 可以来自不同数据源。
Nebula 配置段主要用于描述 nebula 查询服务地址、用户名和密码、图空间信息等信息。
nebula: {
# 查询引擎 IP 列表
addresses: ["127.0.0.1:3699"]
# 连接 Nebula Graph 服务的用户名和密码
user: user
pswd: password
# Nebula Graph 图空间名称
space: test
# thrift 超时时长及重试次数,默认值分别为 3000 和 3
connection {
timeout: 3000
retry: 3
}
# nGQL 查询重试次数,默认值为 3
execution {
retry: 3
}
}
Nebula 配置段
标签配置段用于描述导入标签信息,数组中每个元素为一个标签信息。标签导入主要分为两种:基于文件导入与基于 Hive 导入。
- 基于文件导入配置需指定文件类型
- 基于 Hive 导入配置需指定执行的查询语言。
# 处理标签
tags: [
# 从 HDFS 文件加载数据, 此处数据类型为 Parquet tag 名称为 ${TAG_NAME}
# HDFS Parquet 文件的中的 field_0、field_1将写入 ${TAG_NAME}
# 节点列为 ${KEY_FIELD}
{
name: ${TAG_NAME}
type: parquet
path: ${HDFS_PATH}
fields: {
field_0: nebula_field_0,
field_1: nebula_field_1
}
vertex: ${KEY_FIELD}
batch : 16
}
# 与上述类似
# 从 Hive 加载将执行命令 $ {EXEC} 作为数据集
{
name: ${TAG_NAME}
type: hive
exec: ${EXEC}
fields: {
hive_field_0: nebula_field_0,
hive_field_1: nebula_field_1
}
vertex: ${KEY_FIELD}
}
]
说明:
- name 字段用于表示标签名称
- fields 字段用于配置 HDFS 或 Hive 字段与 Nebula 字段的映射关系
- batch 参数意为一次批量导入数据的记录数,需要根据实际情况进行配置。
边类型配置段用于描述导入标签信息,数组中每个元素为一个边类型信息。边类型导入主要分为两种:基于文件导入与基于Hive导入。
- 基于文件导入配置需指定文件类型
- 基于Hive导入配置需指定执行的查询语言
# 处理边
edges: [
# 从 HDFS 加载数据,数据类型为 JSON
# 边名称为 ${EDGE_NAME}
# HDFS JSON 文件中的 field_0、field_1 将被写入${EDGE_NAME}
# 起始字段为 source_field,终止字段为 target_field ,边权重字段为 ranking_field。
{
name: ${EDGE_NAME}
type: json
path: ${HDFS_PATH}
fields: {
field_0: nebula_field_0,
field_1: nebula_field_1
}
source: source_field
target: target_field
ranking: ranking_field
}
# 从 Hive 加载将执行命令 ${EXEC} 作为数据集
# 边权重为可选
{
name: ${EDGE_NAME}
type: hive
exec: ${EXEC}
fields: {
hive_field_0: nebula_field_0,
hive_field_1: nebula_field_1
}
source: source_id_field
target: target_id_field
}
]
说明:
- name 字段用于表示边类型名称
- fields 字段用于配置 HDFS 或 Hive 字段与 Nebula 字段的映射关系
- source 字段用于表示边的起点
- target 字段用于表示边的终点
- ranking 字段用于表示边的权重
- batch 参数意为一次批量导入数据的记录数,需要根据实际情况进行配置。
导入数据命令
bin/spark-submit \
--class com.vesoft.nebula.tools.generator.v2.SparkClientGenerator \
--master ${MASTER-URL} \
${SPARK_WRITER_JAR_PACKAGE} -c conf/test.conf -h -d
说明:
- -c:config 用于指定配置文件路径
- -h:hive 用于指定是否支持 Hive
- -d:dry 用于测试配置文件是否正确,并不处理数据。
作者有话说:Hi ,大家好,我是 darion,Nebula Graph 的软件工程师,对分布式系统方面有些小心得,希望上述文章可以给大家带来些许启发。限于水平,如有不当之处还请斧正,在此感谢^^
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号