认识最大熵模型
摘要:  信息熵 设$X$是取有限个值的随机变量,$X\in{x_1,x_2,\cdots,x_n},\ i=1,2,\cdots,n$,则随机变量$X$的熵定义为: $$H(X)=-\sum_{i=1}^n P(X=x_i)\log_aP(X=x_i)$$ $H(X)$作为$X$对应的随机场的不确定性的度量 阅读全文
信息熵 设$X$是取有限个值的随机变量,$X\in{x_1,x_2,\cdots,x_n},\ i=1,2,\cdots,n$,则随机变量$X$的熵定义为: $$H(X)=-\sum_{i=1}^n P(X=x_i)\log_aP(X=x_i)$$ $H(X)$作为$X$对应的随机场的不确定性的度量 阅读全文
信息熵 设$X$是取有限个值的随机变量,$X\in{x_1,x_2,\cdots,x_n},\ i=1,2,\cdots,n$,则随机变量$X$的熵定义为: $$H(X)=-\sum_{i=1}^n P(X=x_i)\log_aP(X=x_i)$$ $H(X)$作为$X$对应的随机场的不确定性的度量 阅读全文
 PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。  材质球节点图
材质球节点图  例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。  PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。 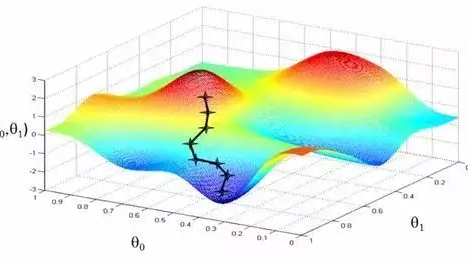 我们知道,梯度表示某一函数在一点处的方向导数,$\nabla_\bm\theta$,沿着其方向取得级大值,那么梯度下降就可以获得我们想要的极小值。但是梯度下降不能一次性到达极小值,而是需要每轮迭代步进到极小值,而步进总有个步长,这个步长可以用学习率$Lr$和上面求出来的损失$J$表示。超平面的参数$\bm\theta$本身也是$N$维空间中一点,每次将它的坐标加上$Lr\nabla_\bm\theta J$,当$\bm\theta$坐标不再移动时,点$\bm\theta$基本上就是极小值点。
我们知道,梯度表示某一函数在一点处的方向导数,$\nabla_\bm\theta$,沿着其方向取得级大值,那么梯度下降就可以获得我们想要的极小值。但是梯度下降不能一次性到达极小值,而是需要每轮迭代步进到极小值,而步进总有个步长,这个步长可以用学习率$Lr$和上面求出来的损失$J$表示。超平面的参数$\bm\theta$本身也是$N$维空间中一点,每次将它的坐标加上$Lr\nabla_\bm\theta J$,当$\bm\theta$坐标不再移动时,点$\bm\theta$基本上就是极小值点。 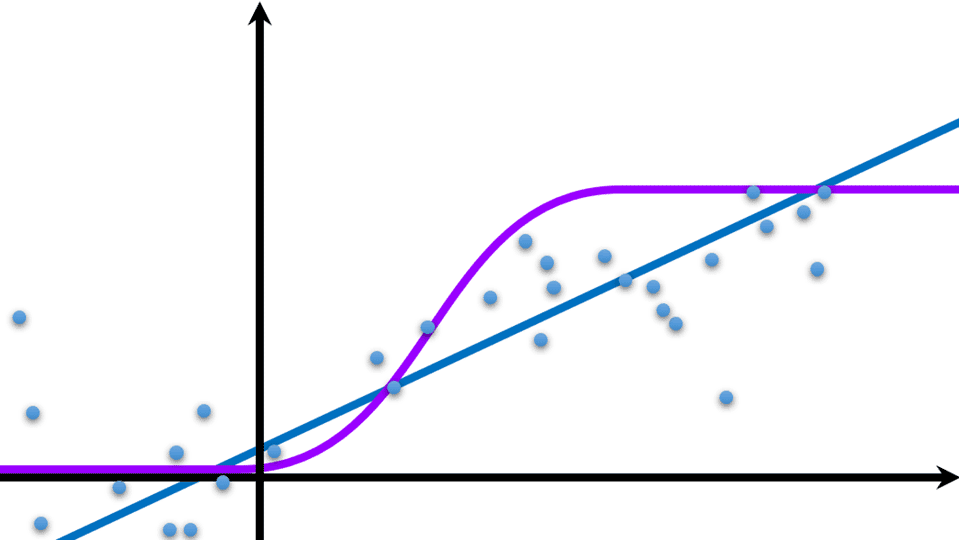 神经元模型是模拟生物神经元工作的数学函数,其对一组输入分别加权并且相加并通过激活函数产生输出,平面的截距则作为一个内部状态被神经元携带。关于我们之前的假设:地面是平的,如果想表示曲面,不妨用很多平面来近似,这时众多神经元以一定的方式彼此连接已经构成神经网络
神经元模型是模拟生物神经元工作的数学函数,其对一组输入分别加权并且相加并通过激活函数产生输出,平面的截距则作为一个内部状态被神经元携带。关于我们之前的假设:地面是平的,如果想表示曲面,不妨用很多平面来近似,这时众多神经元以一定的方式彼此连接已经构成神经网络  𝔸𝕝𝕝 𝒚𝒐𝒖 𝔀𝓪𝓷𝓽 𝐢𝐬 𝖍𝖊𝖗𝖊. 别搜了,你想要的都在这里。特殊字体在线转换可复制为大家提供了非常不错的特殊字体,网络上现在有很多不同风格的网名,大家想要独具一格就必须要在字体上下功夫,可以为大家一键生成各种不同的网名,让大家都可以免费实用,这里提供的字体都可以快速的复制哦!
𝔸𝕝𝕝 𝒚𝒐𝒖 𝔀𝓪𝓷𝓽 𝐢𝐬 𝖍𝖊𝖗𝖊. 别搜了,你想要的都在这里。特殊字体在线转换可复制为大家提供了非常不错的特殊字体,网络上现在有很多不同风格的网名,大家想要独具一格就必须要在字体上下功夫,可以为大家一键生成各种不同的网名,让大家都可以免费实用,这里提供的字体都可以快速的复制哦!  一种与模型无关的、基于值的强化学习算法,直接迭代优化$Q_{\bm\theta}$直至收敛。其中$\bm\theta$是$Q$的参数。和监督学习不同,Q学习的训练数据也需要标注,但这个标注是一个比现在能够计算的动作$\bm a$更好的$\bm a^\prime$,迭代直到$\bm a^\prime\to \bm a^*$。而且这些标注并不能从数据中直接得到,是从环境得到$\bm s^\prime$然后MDP计算出价值间接得到的。
一种与模型无关的、基于值的强化学习算法,直接迭代优化$Q_{\bm\theta}$直至收敛。其中$\bm\theta$是$Q$的参数。和监督学习不同,Q学习的训练数据也需要标注,但这个标注是一个比现在能够计算的动作$\bm a$更好的$\bm a^\prime$,迭代直到$\bm a^\prime\to \bm a^*$。而且这些标注并不能从数据中直接得到,是从环境得到$\bm s^\prime$然后MDP计算出价值间接得到的。  自定义损失函数、自定义训练步骤train_step、早停预防过拟合代码。本文用LeNet进行数字识别,LeNet结构简单易于理解和实现但涉及到的知识一点都不少,是入手深度学习框架的不错的选择。LeNet-5是最早的卷积神经网络之一。论文:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf 提出的卷积层、池化层的概念,也提到本文所使用的数据集:http://yann.lecun.com/exdb/mnist/MNIST 。MNIST数据集已经集成进了Tensorflow框架,可以通过调用一个方法直接使用。
自定义损失函数、自定义训练步骤train_step、早停预防过拟合代码。本文用LeNet进行数字识别,LeNet结构简单易于理解和实现但涉及到的知识一点都不少,是入手深度学习框架的不错的选择。LeNet-5是最早的卷积神经网络之一。论文:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf 提出的卷积层、池化层的概念,也提到本文所使用的数据集:http://yann.lecun.com/exdb/mnist/MNIST 。MNIST数据集已经集成进了Tensorflow框架,可以通过调用一个方法直接使用。