PyTorch实现flappy bird游戏机器玩家
 PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。
运行效果
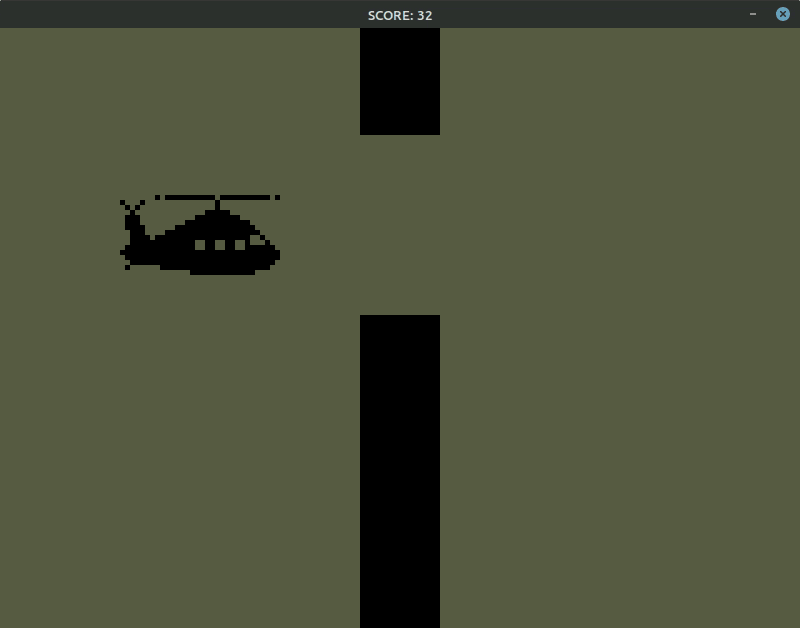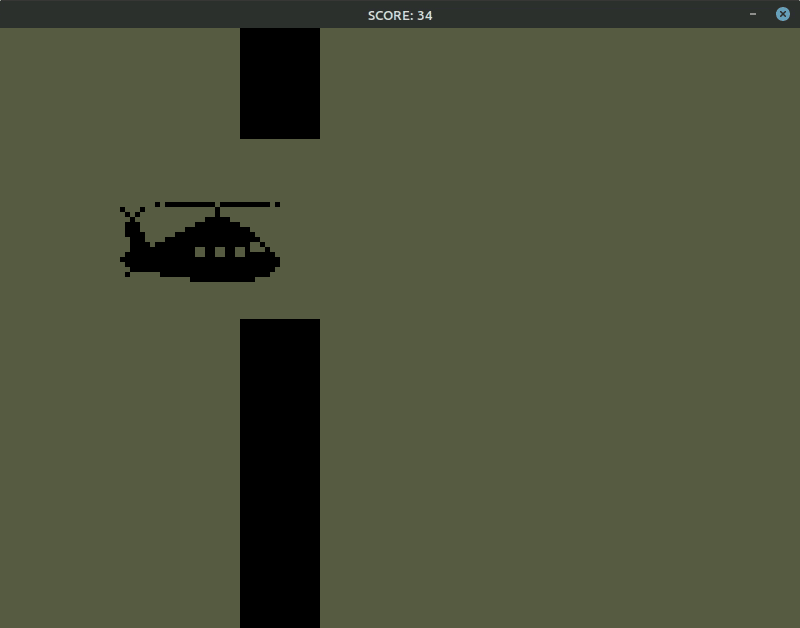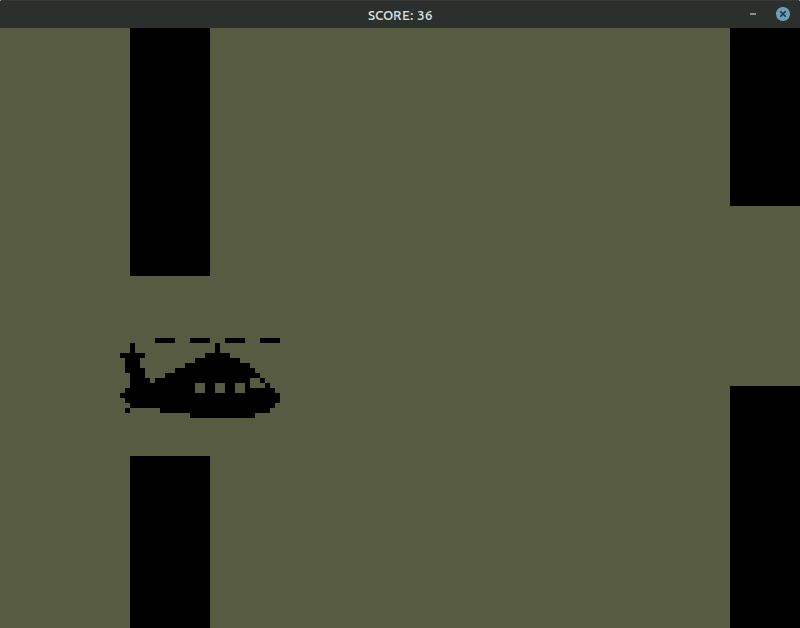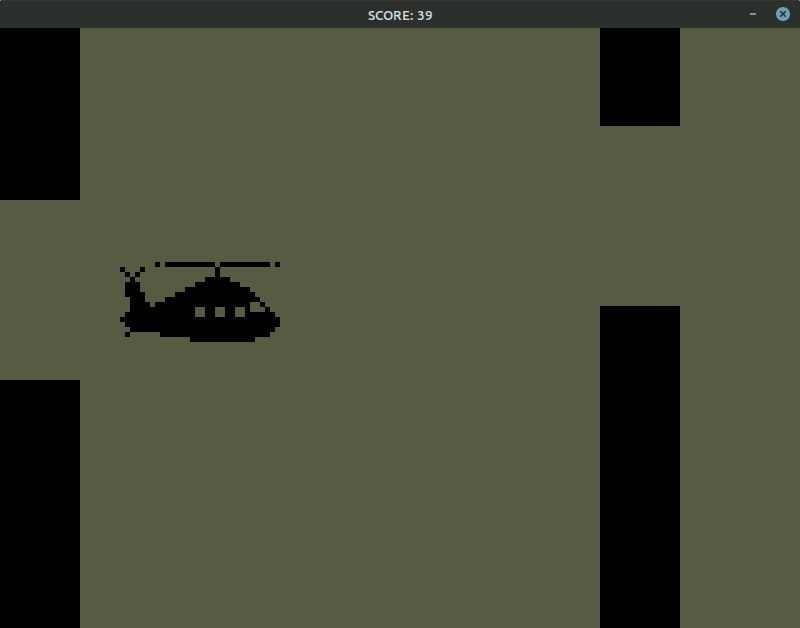
我手动最多打出10分,模型能打30多……
问题分析
- 时间不连续,最小单位为“帧”
- 状态status是连续的浮点数值
- 动作action只有2种,即“升”和“不升”
- 除了刚刚通过门时采取的动作外,动作的结果全是必然没有随机性
与玩家决策相关的量很多比如门(腔缝)的高度和宽度,飞机本身尺寸等等,具体要什么不要什么:
- 玩家左侧与门右侧水平距离占当前两门间距的比例
- 玩家中点与门中点垂直距离占总高度的比例
- 玩家y向速度与“最大速度”的比例
玩家中点与屏幕水平中线的距离占屏幕高度的一半的比例
我们最后用这3个量作为模型入参,所以模型输入3通道但输出只有2通道。只要玩家存活就得到正奖励。
环境搭建
- CUDA版本:
nvcc --versionnvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2021 NVIDIA Corporation Built on Sun_Feb_14_21:12:58_PST_2021 Cuda compilation tools, release 11.2, V11.2.152 Build cuda_11.2.r11.2/compiler.29618528_0 - Python版本:
python --versionPython 3.9.12 - 系统版本:
cat /proc/versionLinux version 5.4.0-109-generic (buildd@ubuntu) (gcc version 9.4.0 (Ubuntu 9.4.0-1ubuntu1~20.04.1)) #123-Ubuntu SMP Fri Apr 8 09:10:54 UTC 2022 - 安装依赖
pip install pygame autopep8 numpy pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
目录结构
- 📁 assets
- 📁 textures
- 🖼 door.gif
- 🖼 player_age0.gif
- 🖼 player_age1.gif
- 📁 textures
- 📄 main.py
- 📄 game.py
- 📄 util.py
代码
main.py
# -*- coding: utf-8 -*-
"""训练和预测。
"""
import random
import sys
from collections import OrderedDict
import numpy as np
import pygame
import torch
from torch import nn, optim
from game import Game
from util import print_bar
class Model(nn.Module):
"""Dueling DQN结构。
"""
def __init__(self):
super(Model, self).__init__()
self.layers = nn.ModuleDict({
'c': nn.Sequential(nn.Linear(3, 12, device=CUDA), nn.Sigmoid()),
'a': nn.Linear(12, 2, device=CUDA),
'v': nn.Linear(12, 1, device=CUDA),
'o': nn.ReLU(),
})
def forward(self, arg: torch.Tensor) -> torch.Tensor:
"""模型前向传播。
Parameters
----------
x : torch.Tensor
样本输入模型
Returns
-------
torch.Tensor
预测值。
"""
output = arg
output = self.layers['c'](output)
adv = self.layers['a'](output)
val = self.layers['v'](output)
output = self.layers['o'](adv+val)
return output
def load_params(self, model: 'Model', rate: float = 1):
"""模型参数软更新。
Parameters
----------
model : Model
将这个模型的参数复制到当前模型
rate : float, optional
`1`表示将模型参数完全复制到当前模型, by default 1
"""
for key, value in self.layers.items():
if rate >= 1.:
forign = model.layers[key].state_dict()
value.load_state_dict(forign)
else:
local = value.state_dict()
forign = model.layers[key].state_dict()
mix = OrderedDict()
for key in local.keys():
mix[key] = local.get(key)*(1-rate) + forign.get(key)*rate
value.load_state_dict(mix)
def simulate(model: Model, batch_size: int, epslion: float = .1, eval_step: int = None, env_args: dict = None) -> 'tuple[list,float,int]':
"""模拟游戏过程并收集数据。
Parameters
----------
model : Model
决策用
batch_size : int
收集数据总条数
epslion : float, optional
尝试比例, by default .1
eval_step : int, optional
模型将控制游戏的最大步数,参与模型评估, by default `batch_size`
env_args : dict, optional
环境初始化参数, by default None
Returns
-------
tuple[list,float,int]
采集的数据, 平均存活时长, 无探索情况下生存时间
"""
cache = []
env = Game(**env_args, without_screen=True)
livetimes = []
livetime = 0
for _ in range(batch_size):
state = env.shot()
if random.random() <= epslion:
action_index = random.randint(0, len(ACTIONS)-1)
else:
values = model(torch.tensor(state, device=CUDA))
action_index = values.argmax(-1)
jump = ACTIONS[action_index]
env.step(jump)
next_state = env.shot()
reward = float(env.playing)
cache.append((state, action_index, next_state, reward))
if not env.playing:
env = Game(**env_args, without_screen=True)
livetimes.append(livetime)
else:
livetime += 1
env = Game(**env_args, without_screen=True)
max_step = eval_step or batch_size
livetime = 0
for _ in range(max_step): # 看模型在不进行随机探索条件下能维持多少帧不摔机,这是评估标准
state = env.shot()
values = model(torch.tensor(state, device=CUDA))
action_index = values.argmax(-1)
jump = ACTIONS[action_index]
env.step(jump)
if not env.playing:
break
livetime += 1
return cache, sum(livetimes)/max(1, len(livetimes))/batch_size, livetime
def train(policy_net: Model, opt: optim.Optimizer, loss_func: 'nn._Loss', epochs: int, batch_size: int, cache_size: int, epslion: float = .1, gamma: float = .5, update_ratio: float = .5, eval_step: int = None, target_accuracy=.99, env_args: dict = None) -> 'tuple[Model,list[float],list[float],list[int]]':
"""训练模型。
Parameters
----------
policy_net : Model
决策网络对象
opt : optim.Optimizer
优化器
loss_func : nn._Loss
损失函数
epochs : int
迭代轮数
batch_size : int
批量
epslion : float, optional
探索动作比例, by default .1
gamma : float, optional
未来奖励权重,`0`表示仅考虑当前奖励, by default .5
update_ratio : float, optional
软更新比例, by default .5
target_accuracy : float, optional
模型决策目标得分, by default .99
env_args : dict, optional
环境初始化参数, by default None
Returns
-------
tuple[Model,list[float],list[float],list[int]]
目标网络, 损失, 存活时间
"""
target_net = Model()
target_net.load_params(policy_net)
policy_net.train(mode=True)
target_net.train(mode=False)
loss_vals, accuracies, livetimes, cache = [], [], [], []
for epoch in range(epochs):
target_net.load_params(policy_net, update_ratio)
# 获取数据
batch, accuracy, livetime = simulate(model=target_net, batch_size=batch_size, epslion=epslion, eval_step=eval_step, env_args=env_args)
accuracies.append(accuracy)
livetimes.append(livetime)
if livetime/(eval_step or batch_size) >= target_accuracy:
# 模型的决策已经达标不需要再训练了
break
# 装入经验池
cache.extend(batch)
cache = cache[-cache_size:]
# 经验池抽样并转换成tensor
states, actions, nexts, rewards = [], [], [], []
for state, action, next_state, reward in random.sample(cache, batch_size):
states.append(state)
actions.append(action)
rewards.append(reward)
nexts.append(next_state)
states = torch.tensor(states, device=CUDA)
actions = torch.tensor(actions, device=CUDA).unsqueeze(-1)
rewards = torch.tensor(rewards, device=CUDA)
nexts = torch.tensor(nexts, device=CUDA)
# 计算输出与损失,批量梯度下降
v_target = target_net.forward(nexts).detach()
y_target = v_target.max(dim=-1).values * gamma
y_target += rewards * (1-gamma)
v_eval = policy_net.forward(states)
y_eval = v_eval.gather(index=actions, dim=-1)
loss = loss_func(y_eval, y_target)
opt.zero_grad()
loss.backward()
opt.step()
loss = loss.item()
loss_vals.append(loss)
print_bar(epoch+1, epochs, ("%.10f" % loss, '%.10f' % accuracy, livetime))
return target_net, loss_vals, accuracies, livetimes
np.set_printoptions(suppress=True)
CUDA = torch.device("cuda")
MODEL = Model()
OPT = optim.Adam(MODEL.parameters(), lr=.01)
LOSS_FUNCTION = nn.MSELoss()
ACTIONS = (True, False)
SCREEN_SIZE = (800, 600)
FPS = 20
GAME_CONFIG = {
'screen_size': SCREEN_SIZE,
'door_size': (80, 180),
'speed': 10,
'jump_force': 3,
'g': 2,
'door_distance': 60,
}
if __name__ == "__main__":
pygame.init() # 初始化
model, loss_vals, accuracies, livetimes = train(
policy_net=MODEL,
opt=OPT,
loss_func=LOSS_FUNCTION,
epochs=20000,
batch_size=192,
cache_size=2000,
epslion=.3,
gamma=.9,
update_ratio=.1,
target_accuracy=.95,
env_args=GAME_CONFIG,
eval_step=1200,
)
# 使用模型决策并观看结果
print('\n\n')
model = model.to('cpu')
model.train(mode=False)
SCREEN = pygame.display.set_mode(SCREEN_SIZE)
fcclock = pygame.time.Clock()
game = Game(**GAME_CONFIG)
while True:
# 循环,直到接收到窗口关闭事件
for event in pygame.event.get():
# 处理事件
if event.type == pygame.QUIT:
# 接收到窗口关闭事件
pygame.quit()
sys.exit()
keys = pygame.key.get_pressed()
if keys[pygame.K_ESCAPE]:
pygame.quit()
sys.exit()
else:
state = torch.tensor(game.shot())
values = model.forward(state)
action_index = values.argmax(-1)
jump = ACTIONS[action_index]
game.step(jump)
pygame.display.set_caption(f'SCORE: {game.score}')
game.draw(SCREEN)
fcclock.tick(FPS)
pygame.display.update()
if not game.playing:
# 自动开局
game = Game(**GAME_CONFIG)
game.py
# -*- coding: utf-8 -*-
"""游戏环境相关。
"""
import random
import sys
import pygame
class Box:
"""包含基础位置、尺寸、速度、加速度的盒子类。
"""
__position = None
__size = None
__speed = None
__acceleration = None
def __init__(self, cx: int, cy: int, w: int, h: int, sx: int = 0, sy: int = 0, ax: int = 0, ay: int = 0):
self.__position = [cx, cy]
self.__size = [w, h]
self.__speed = [sx or 0, sy or 0]
self.__acceleration = [ax or 0, ay or 0]
@property
def width(self):
return self.__size[0]
@property
def height(self):
return self.__size[-1]
@property
def size(self):
return self.__size
@property
def x(self):
return self.__position[0]
@property
def y(self):
return self.__position[-1]
@property
def position(self):
return self.__position
@property
def speed_x(self):
return self.__speed[0]
@speed_x.setter
def speed_x(self, v):
self.__speed[0] = v
@property
def speed_y(self):
return self.__speed[-1]
@speed_y.setter
def speed_y(self, v):
self.__speed[-1] = v
@property
def speed(self):
return self.__speed
@speed.setter
def speed(self, v: 'tuple[int,int]'):
self.__speed[0] = v[0]
self.__speed[-1] = v[-1]
@property
def acceleration_x(self):
return self.__acceleration[0]
@acceleration_x.setter
def acceleration_x(self, v: int):
self.__acceleration[0] = v
@property
def acceleration_y(self):
return self.__acceleration[-1]
@acceleration_y.setter
def acceleration_y(self, v: int):
self.__acceleration[-1] = v
@property
def acceleration(self):
return self.__acceleration
@acceleration.setter
def acceleration(self, v: 'tuple[int,int]'):
self.__acceleration[0] = v[0]
self.__acceleration[-1] = v[-1]
@property
def left(self):
return self.x-self.width/2
@property
def right(self):
return self.x+self.width/2
@property
def top(self):
return self.y-self.height/2
@property
def bottom(self):
return self.y+self.height/2
def move(self, force_x: int = None, force_y: int = None):
"""为盒子施力使其移动。
Parameters
----------
force_x : int, optional
水平分量, by default None
force_y : int, optional
垂直分量, by default None
"""
self.acceleration_x = force_x or 0
self.acceleration_y = force_y or 0
self.speed_x += self.acceleration_x
self.speed_y += self.acceleration_y
self.__position[0] += self.speed_x
self.__position[-1] += self.speed_y
def is_intersect(player: Box, door: Box) -> bool:
return (door.top > player.top or player.bottom > door.bottom) \
and not (player.left >= door.right or door.left >= player.right)
class GameObject(Box):
"""游戏基础对象。
"""
def __init__(self, imgs: list, img_cd: int = 1, *args, **kwargs):
super(GameObject, self).__init__(*args, **kwargs)
self.__imgs = [item for item in imgs]
self.__img_cd = img_cd or -1
self.living = True
self.img_index = -1
def img_grow(self):
self.img_index = (self.img_index+1) % self.__img_cd
@property
def img(self):
return self.__imgs[self.img_index]
class Game:
door_size = None
player = None
jump_force = 0
g = 1
door_distance = 0
doors = None
time = 1
score = 0
def __init__(self, screen_size=(800, 600), player_size=(160, 80), door_size=(80, 160), speed=5, jump_force=1.3, g=0.4, door_distance=100, max_falling_speed: int = 100, without_screen=False, **_):
self.player = GameObject(
cx=screen_size[0]/4,
cy=screen_size[1]/2,
w=player_size[0],
h=player_size[1],
sx=0, sy=0,
ax=0, ay=g,
imgs=[None, ] if without_screen else[
pygame.image.load('./assets/textures/player_age0.gif').convert_alpha(),
pygame.image.load('./assets/textures/player_age1.gif').convert_alpha(),
],
img_cd=2
)
self.without_screen = without_screen
self.screen_size = screen_size
self.door_size = door_size
self.speed = speed
self.jump_force = jump_force
self.g = g
self.door_distance = door_distance
self.max_falling_speed = max_falling_speed
self.doors = [self.create_door()]
@property
def playing(self) -> bool:
"""描述玩家是否存活。
"""
return self.player.living
@property
def door(self) -> 'GameObject|None':
"""距离玩家最近的且玩家未穿过的门。
"""
for door in self.doors:
if door.right >= self.player.left:
return door
return None
def create_door(self) -> GameObject:
"""随机初始化门。
Returns
-------
GameObject
屏幕右侧随机位置的门。
"""
door = GameObject(
cx=self.screen_size[0]+self.door_size[0]/2,
cy=random.randint(self.door_size[1]/2, self.screen_size[1]-self.door_size[1]/2),
w=self.door_size[0],
h=self.door_size[1],
sx=-self.speed,
imgs=[None, ] if self.without_screen else [pygame.image.load('./assets/textures/door.gif').convert_alpha(),],
img_cd=2
)
return door
def draw(self, surface: 'pygame.Surface'):
"""绘制游戏帧。
Parameters
----------
surface : pygame.Surface
pygame屏幕
"""
if not self.player.living:
return
surface.fill([86, 92, 66])
self.player.img_grow()
surface.blit(pygame.transform.scale(self.player.img, (self.player.width, self.player.height)), (self.player.left, self.player.top))
for door in self.doors:
surface.blit(pygame.transform.scale(door.img, (door.width, door.top)), (door.left, 0))
surface.blit(pygame.transform.scale(door.img, (door.width, self.screen_size[1]-door.bottom)), (door.left, door.bottom))
@staticmethod
def __shot(door: Box, player: Box, screen_size: 'tuple[int,int]', speed_scale: int) -> 'list[float]':
return [(door.right-player.left)/screen_size[0], (player.y-door.y)/screen_size[-1], player.speed_y/speed_scale, ]
def shot(self) -> 'list[float]':
"""组装并返回当前游戏环境状态。
Returns
-------
list[float]
模型所需的多元组。
"""
return Game.__shot( self.door, self.player, [self.door_distance*self.speed, self.screen_size[-1]], self.max_falling_speed, )
def step(self, jump: 'bool|int|float' = False):
"""游戏步进。
Parameters
----------
jump : bool, optional
玩家是否跳跃, by default False
"""
# 玩家必须存活才能继续游戏
if not self.player.living:
return
if self.time % self.door_distance == 0 or not (self.doors and len(self.doors)):
# 时间间隔生成门,时间重置
self.doors.append(self.create_door())
self.time = 1
else:
# 时间正常递增直到时间间隔
self.time += 1
# 清除已经移除屏幕的门
while self.doors[0].right < 0:
del self.doors[0]
# 移动玩家和所有门
for door in self.doors:
door.move()
door = self.door
living = 0 < self.player.y < self.screen_size[1] and not is_intersect(self.player, door)
self.player.move(None, -self.jump_force if jump else self.g)
if jump:
self.player.speed_y = min(0, self.player.speed_y)
self.player.living = living
# 判断玩家和门存活
if door.living and self.player.left >= door.right:
door.living = False
self.score += 1
util.py
# -*- coding: utf-8 -*-
"""输出打印工具模块。
"""
def print_bar(epoch, epochs, etc=None, bar_size=50):
"""打印进度条。
Parameters
----------
epoch : int
当前进度
epochs : int
总进度
etc : Any, optional
打印后缀, by default None
bar_size : int, optional
进度条长度, by default 50
"""
process = bar_size*epoch/epochs
process = int(process+(int(process) < process))
strs = [
f"Epoch {epoch}/{epochs}",
f" |\033[1;30;47m{' ' * process}\033[0m{' ' * (bar_size-process)}| ",
]
if etc is not None:
strs.append(str(etc))
if epoch:
strs.insert(0, "\033[A")
print("".join(strs)+" ")
door.gif

player_age0.gif

player_age1.gif

转载源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号