
Generating Videos with Scene Dynamics
论文名称:Generating Videos with Scene Dynamics
作者:Carl Vondrick,Hamed Pirsiavash,Antonio Torralba
来源:NIPS 2016
主要创新点:一种通过无标签数据训练出来的视频生成器,可以输入高斯噪声生成视频。
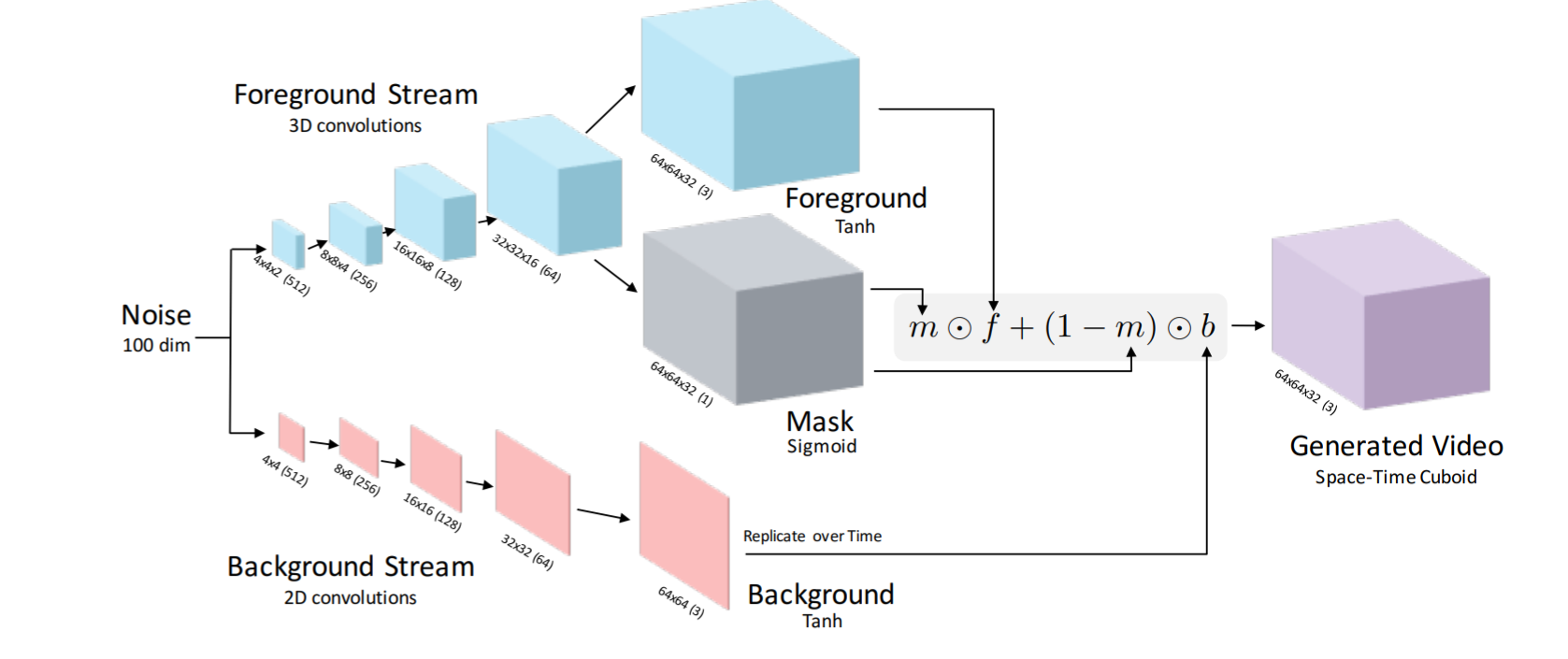
具体内容:这篇文章里有3种不同的生成器。第一种是普通的单线程生成器,架构取自论文Unsupervised representation learning with deep convolutional generative adversarial networks,另结合了spatio-temporal convolution(大概是一种用于视频的有时空属性的卷积)。第二种是文章创新的双线程生成器,将视频中的背景和运动物体分开生成然后再结合到一起,结构如图。蓝色方块表示运动物体的生成,生成完之后会用一个sigmoid mask(区分运动物体和背景的掩模)将运动物体抓取出来。粉色方块表示背景的生成,因为默认视频背景是视频中不动的部分,所以直接生成的2D图片。最后再将视频背景和抓取出来的运动物体结合生成视频。
第三种生成器是在第二种的基础上改进的,本来是用高斯噪声生成,改进后变成输入一张静态图片然后生成以该图片为第一帧的一段视频。但是效果明显没有前面两种好。
我没看懂的地方:在评价该模型的实验中,用作对比的baseline是一组encoder和decoder,训练encoder用来fit Gaussian Mixture Model,用decoder从GMM里采样。没懂这里参数数量和模型结构都跟生成器一样,那么区别在哪里,以及GMM怎么采样。
