

来点树链剖分
树链剖分学习笔记
引入
给你一棵树,先单点加,再路径求和,你觉得很简单,用树上差分解决了这个问题。
再给你一棵树,先路径加,再单点查询,你觉得很简单,用树上差分解决了这个问题。
又给你一棵树,上述操作都有,而且顺序不分先后,你发现树上差分不能解决这个问题。
那么,该如何解决这个问题呢?
从树到序列
考虑序列上的问题。
单点加区间求和、区间加单点查询这两个问题都能使用差分和前缀和解决,然而当出现形似第三个问题的问题时,我们引入了树状数组和线段树。于是我们推测树上的这类问题也能转化为序列上的问题,进而使用这两种数据结构解决。
于是问题变成了:找到一种方式,使我们的树变成一个序列,以便于把树上路径修改与查询变成序列上区间的修改与查询。
笔者决定再给你一棵树,单点加,子树求和,想想该如何解决这个问题。
考虑对树进行 DFS,记录每个点的 DFS 序。
比如我们有这样一棵树:
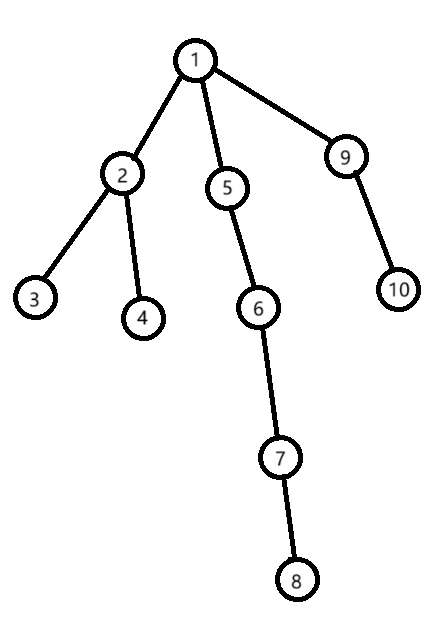
不难发现,每个点的子树的 DFS 序都在一个连续的区间上。于是在这个问题中,我们利用 DFS 序完成了从树上子树问题到序列上区间问题的转换。
我们观察刚才得到的 DFS 序,可以发现,不仅子树的 DFS 序在连续的区间上,从每个节点的 DFS 序开始,会有一个连续区间,对应这个节点向下延伸到底的一条链。
于是我们有一个大胆的想法:利用这一点来把树上路径问题转化为序列上区间问题。
具体地,在搜索时记录每个节点的 DFS 序、深度、所在链的最顶端。每次在 DFS 序列上进行单点操作,当需要对路径操作时,对两个路径端点进行如下操作:
-
找到两端点中链头深度更大的那个点;
-
对从链头到它的这一段 DFS 序在序列上进行操作;
-
跳到它的链头的父节点;
-
重复上述操作直到两端点的链头相同。
当链头相同时,直接对这两个点之间的区间在 DFS 序列上进行操作即可。
有如下代码(以路径加为例):
void modify(int u,int v,int k) { //dfn[]:DFS序 while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]]) swap(u,v); SegTree.add(SegRoot,dfn[top[u]],dfn[u],k,1,n); u=fa[top[u]]; } if(dep[u]>dep[v]) swap(u,v); SegTree.add(SegRoot,dfn[u],dfn[v],k,1,n); }
于是我们成功实现了从树上路径问题到序列上区间问题的转化。这种转化就叫作树链剖分。
然而,这样真的对吗?
改进
按照上面的方式,如果很不幸,这些链的延伸方向是这样:
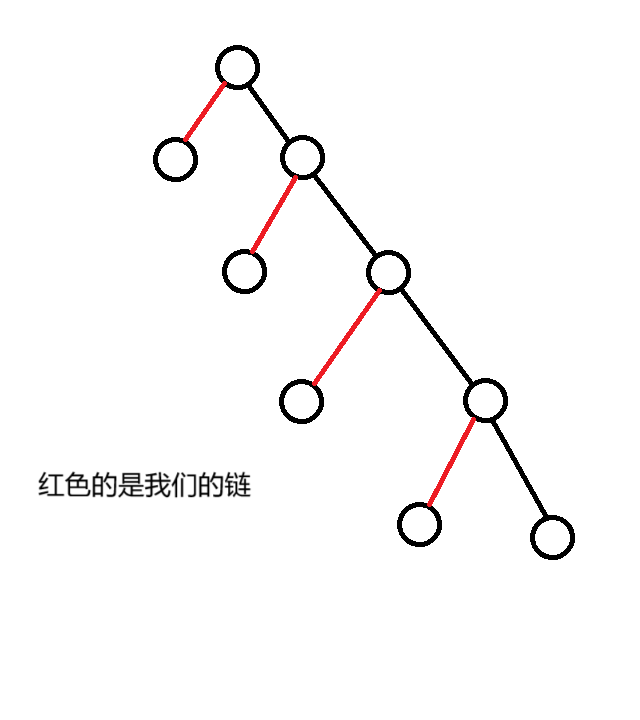
那么每次修改操作的时间复杂度最坏情况下将会来到 \(O(n)\),是无法接受的。
但是如果我们控制链延伸的方向,使得构造出的链能使路径操作中跳链头(u=fa[top[u]])的次数最少,时间复杂度就会变得可以接受。
我们可以让链向子树中节点最多(子树大小最大)的儿子(下文称为重儿子,其他的儿子称为轻儿子)延伸。这种转化叫作重链剖分。
为什么这样做就能使跳链头的次数更少呢?这样做,每次跳链头,都是从链头父亲的轻儿子跳上来。而由于它是轻儿子,它子树的大小一定不超过父亲节点子树大小的一半。因此每次跳链头,都是从一个子树大小为 \(x\) 的点,跳到一个子树大小至少为 \(2x\) 的点。最坏情况下,当从叶子节点一步步跳到根节点,即子树大小从 \(1\) 一步步变为 \(n\) 时,最多变换 \(\log{n}\) 次,时间复杂度为 \(O(\log{n})\),是可以接受的。而实际使用中,往往是卡不满的,因此重链剖分求 LCA 往往比倍增更优,当然也更难写。
通过研究求 DFS 序的过程,可以发现,每个点的链延伸到哪个儿子的方向,取决于哪个儿子最先被访问。因此我们 DFS 预处理出每个节点的重儿子,每访问到一个节点,先访问它的重儿子,再访问轻儿子。
有如下代码:
int dfn[N],dep[N],fa[N],siz[N],son[N],top[N],bot[N],idx; void dfs1(int x) //如果节点编号从0开始,就不能这么写了 { siz[x]=1; for(int i=hed[x];i;i=nxt[i]) if(!siz[tal[i]]) //上一行把siz设为1了,如果siz为0,说明没访问过tal[i] { fa[tal[i]]=x,dep[tal[i]]=dep[x]+1; dfs1(tal[i]); siz[x]+=siz[tal[i]]; if(siz[tal[i]]>siz[son[x]]) son[x]=tal[i]; //son[x]初值为0,而siz[0]=0 } } void dfs2(int x,int tp) //主函数调用:dfs2(1,1);因为根节点的链头是它本身 { if(!x) return; //访问了一个叶子节点的重儿子 bot[x]=dfn[x]=++idx; dfs2(son[x],top[x]=tp); if(bot[son[x]]>bot[x]) bot[x]=bot[son[x]]; //只有一个儿子 for(int i=hed[x];i;i=nxt[i]) if(!top[tal[i]]) //没给链头赋值,说明没访问过 dfs2(tal[i],tal[i]),bot[x]=bot[tal[i]]; //轻儿子的链头是它本身 }
把这个代码和上面的 modify 拼起来,再动用你的智慧补全其他函数,树链剖分板子题就做完了。
实现
笔者这里给出一份 P3384 的代码,毕竟树链剖分对于初学者来说还是挺难调的。
#include <cstdio> #define N 100005 int n,m,r,p,a[N],rt; int hed[N],tal[N<<1],nxt[N<<1],cnte; void adde(int u,int v) {tal[++cnte]=v,nxt[cnte]=hed[u],hed[u]=cnte;} int dfn[N],li[N],dep[N],siz[N],fa[N],son[N],top[N],bot[N],idx; struct sgt { int d[N<<2],tg[N<<2],ls[N<<2],rs[N<<2],id; #define mid (lb+rb>>1) void mt(int x,int lb,int rb,int k) {(d[x]+=(rb-lb+1)*k%p)%=p,(tg[x]+=k)%=p;} void pushdown(int x,int lb,int rb) { if(!tg[x]) return; if(!ls[x]) ls[x]=++id; if(!rs[x]) rs[x]=++id; mt(ls[x],lb,mid,tg[x]); mt(rs[x],mid+1,rb,tg[x]); tg[x]=0; } int build(int lb,int rb) { int x=++id; if(lb==rb) {d[x]=a[li[lb]]%p;return x;} ls[x]=build(lb,mid),rs[x]=build(mid+1,rb); d[x]=(d[ls[x]]+d[rs[x]])%p; return x; } void modify(int x,int l,int r,int k,int lb,int rb) { if(l<=lb&&rb<=r) {mt(x,lb,rb,k);return;} pushdown(x,lb,rb); if(l<=mid) modify(ls[x],l,r,k,lb,mid); if(r>mid) modify(rs[x],l,r,k,mid+1,rb); d[x]=(d[ls[x]]+d[rs[x]])%p; } int query(int x,int l,int r,int lb,int rb) { if(l<=lb&&rb<=r) return d[x]; pushdown(x,lb,rb); int ret=0; if(l<=mid) ret=query(ls[x],l,r,lb,mid); if(r>mid) (ret+=query(rs[x],l,r,mid+1,rb))%=p; return ret; } #undef mid } tr; void dfs1(int x) { siz[x]=1; for(int i=hed[x];i;i=nxt[i]) if(!siz[tal[i]]) { dep[tal[i]]=dep[x]+1,fa[tal[i]]=x; dfs1(tal[i]); siz[x]+=siz[tal[i]]; if(siz[tal[i]]>siz[son[x]]) son[x]=tal[i]; } } void dfs2(int x,int tp) { if(!x) return; li[bot[x]=dfn[x]=++idx]=x; dfs2(son[x],top[x]=tp); if(bot[son[x]]>bot[x]) bot[x]=bot[son[x]]; for(int i=hed[x];i;i=nxt[i]) if(!top[tal[i]]) dfs2(tal[i],tal[i]),bot[x]=bot[tal[i]]; } void pmodify(int x,int y,int z) { while(top[x]!=top[y]) { if(dep[top[x]]<dep[top[y]]) {int tmp=x;x=y,y=tmp;} tr.modify(rt,dfn[top[x]],dfn[x],z,1,n); x=fa[top[x]]; } if(dep[x]>dep[y]) {int tmp=x;x=y,y=tmp;} tr.modify(rt,dfn[x],dfn[y],z,1,n); } int pquery(int x,int y) { int ret=0; while(top[x]!=top[y]) { if(dep[top[x]]<dep[top[y]]) {int tmp=x;x=y,y=tmp;} (ret+=tr.query(rt,dfn[top[x]],dfn[x],1,n))%=p; x=fa[top[x]]; } if(dep[x]>dep[y]) {int tmp=x;x=y,y=tmp;} (ret+=tr.query(rt,dfn[x],dfn[y],1,n))%=p; return ret; } int main() { scanf("%d%d%d%d",&n,&m,&r,&p); for(int i=1;i<=n;i++) scanf("%d",&a[i]); for(int i=1,u,v;i<n;i++) scanf("%d%d",&u,&v),adde(u,v),adde(v,u); dfs1(r),dfs2(r,r); rt=tr.build(1,n); while(m--) { int op,x,y,z; scanf("%d%d",&op,&x); if(op==1) scanf("%d%d",&y,&z),pmodify(x,y,z); if(op==2) scanf("%d",&y),printf("%d\n",pquery(x,y)); if(op==3) scanf("%d",&z),tr.modify(rt,dfn[x],bot[x],z,1,n); if(op==4) printf("%d\n",tr.query(rt,dfn[x],bot[x],1,n)); } }
什么,你要注释?再见吧
边权转点权
顾名思义,有些题需要修改和查询边权,如 P3038。像这类问题就需要把一条边的边权转化为某个点的点权。
由于这是一棵树,一条边一定连接着父亲和儿子,一个父亲可能有多个儿子,而一个儿子只有一个父亲,所以把边权转化为这条边所连的儿子的点权,然后套模板就行了。
注意路径操作需要去掉 LCA 处的点权值,因为两个点的 LCA 连向父亲的边不在这两个点的路径上。
结语
至此,重链剖分便基本讲完了。树链剖分不止有重链剖分,还有长链剖分、LCT 需要的剖分等实现,这里不再展开叙述。
树链剖分由于细节很多,容易写挂,所以需要多加练习。
推荐一个题单:树链剖分练习题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」