
使用Keras开发神经网络
一、使用pip安装好tensorflow
二、使用pip安装好Keras
三、构建过程:
1 导入数据
2 定义模型
3 编译模型
4 训练模型
5 测试模型
6 写出程序
1.导入数据
使用皮马人糖尿病数据集(Pima Indians onset of diabetes)(自行百度,google下载数据集)
数据集的内容是皮马人的医疗记录,以及过去5年内是否有糖尿病。所有的数据都是数字,问题是(是否有糖尿病是1或0),是二分类问题。数据的数量级不同,有8个属性:
- 怀孕次数
- 2小时口服葡萄糖耐量试验中的血浆葡萄糖浓度
- 舒张压(毫米汞柱)
- 2小时血清胰岛素(mu U/ml)
- 体重指数(BMI)
- 糖尿病血系功能
- 年龄(年)
- 类别:过去5年内是否有糖尿病
所有的数据都是数字,可以直接导入Keras。
导入资料
使用随机梯度下降时最好固定随机数种子,这样你的代码每次运行的结果都一致。这种做法在演示结果、比较算法或debug时特别有效。你可以随便选种子:
# fix random seed for reproducibility seed = 7 numpy.random.seed(seed)
现在导入皮马人数据集。NumPy的loadtxt()函数可以直接带入数据,输入变量是8个,输出1个。导入数据后,我们把数据分成输入和输出两组以便交叉检验:
# load pima indians dataset dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",") # split into input (X) and output (Y) variables X = dataset[:,0:8] Y = dataset[:,8]
2 定义模型
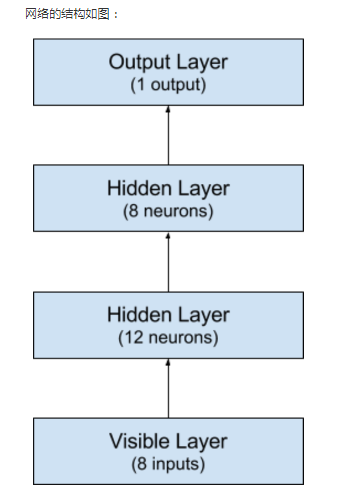
Keras的模型由层构成:我们建立一个Sequential模型,一层层加入神经元。第一步是确定输入层的数目正确:在创建模型时用input_dim参数确定。例如,有8个输入变量,就设成8。
隐层怎么设置?这个问题很难回答,需要慢慢试验。一般来说,如果网络够大,即使存在问题也不会有影响。这个例子里我们用3层全连接网络。
全连接层用Dense类定义:第一个参数是本层神经元个数,然后是初始化方式和激活函数。这里的初始化方法是0到0.05的连续型均匀分布(uniform),Keras的默认方法也是这个。也可以用高斯分布进行初始化(normal)。
前两层的激活函数是线性整流函数(relu),最后一层的激活函数是S型函数(sigmoid)。之前大家喜欢用S型和正切函数,但现在线性整流函数效果更好。为了保证输出是0到1的概率数字,最后一层的激活函数是S型函数,这样映射到0.5的阈值函数也容易。前两个隐层分别有12和8个神经元,最后一层是1个神经元(是否有糖尿病)。
# create model model = Sequential() model.add(Dense(12, input_dim=8, init='uniform', activation='relu')) model.add(Dense(8, init='uniform', activation='relu')) model.add(Dense(1, init='uniform', activation='sigmoid')) # 现在Keras使用API 2.0版本,所以上述的init需要改为kernel_initializer
3 编译模型
定义好的模型可以编译:Keras会调用TensorFlow编译模型。后端会自动选择表示网络的最佳方法,配合你的硬件。这步需要定义几个新的参数。训练神经网络的意义是:找到最好的一组权重,解决问题。
我们需要定义损失函数和优化算法,以及需要收集的数据。我们使用binary_crossentropy,错误的对数作为损失函数;adam作为优化算法,因为这东西好用。
# Compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Fit the model # metrics=['accuracy'] 评价函数,用来度量模型,该训练的评估结果不参与更新权重的运算
4 训练模型
调用模型的fit()方法即可开始训练
网络按轮训练,通过nb_epoch参数控制。每次送入的数据(批尺寸)可以用batch_size参数控制。这里我们只跑150轮,每次10个数据。
# Fit the model model.fit(X, Y, nb_epoch=150, batch_size=10) # 现在Keras API 2.0版本已经将nb_epoch改为了epochs
5 测试模型
我们把测试数据拿出来检验一下模型的效果。注意这样不能测试在新数据的预测能力。应该将数据分成训练和测试集。
调用模型的evaluation()方法,传入训练时的数据。输出是平均值,包括平均误差和其他的数据,例如准确度。
# evaluate the model scores = model.evaluate(X, Y) print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
6 写出程序
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Create first network with Keras from keras.models import Sequential from keras.layers import Dense import numpy # fix random seed for reproducibility seed = 7 numpy.random.seed(seed) # load pima indians dataset dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",") # split into input (X) and output (Y) variables X = dataset[:,0:8] Y = dataset[:,8] # create model model = Sequential() model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu')) model.add(Dense(8, kernel_initializer='uniform', activation='relu')) model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid')) # Compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Fit the model model.fit(X, Y, epochs=150, batch_size=10) # evaluate the model scores = model.evaluate(X, Y) print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100)) # 在开头加上 #import os #os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 是因为我的CPU支持AVX扩展,但是安装的TensorFlow版本无法编译使用。所以使用上面两行代码直接将警告忽略。
# 编译TensorFlow源码
# 如果没有GPU并且希望尽可能多地利用CPU,那么如果CPU支持AVX,AVX2和FMA,则应该从针对CPU优化的源构建tensorflow。
训练时每轮会输出一次损失和正确率,以及最终的效果

总结:
- 如何导入数据
- 如何用Keras定义神经网络
- 如何调用后端编译模型
- 如何训练模型
- 如何测试模型

