
scrapy初探
一 创建scrapy项目
运行命令:
scrapy startproject 项目名称
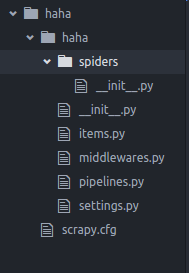
目录结构
二 定义Item容器
Item是保存爬取到数据的容器,其使用方法和python字典类似,并且提供了额外的保护机制来避免拼写错误导致的未定义字段错误
item的内容示例如下:

三 编写爬虫
写在spiders文件夹下: Spider是用户编写用于从网站上爬取数据的类,其包含了一个用于下载的初始URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法.
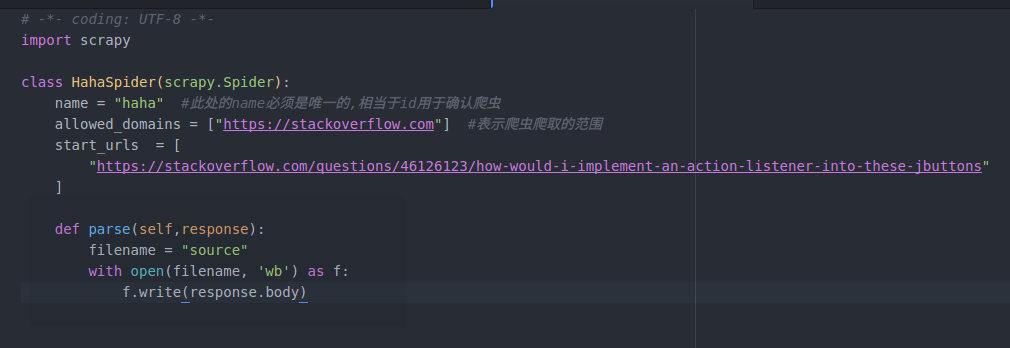
spider文件的具体内容:
在命令行运行:
scrapy crawl 爬虫名称(此处即为spider中name的名称,这也是为什么name不能重复的原因)
对页面进行爬取
注:
一 第一行的 # -*- coding: UTF-8 -*- 是当出现“Non-ASCII character 'xe5' in file”报错问题时加上,
出现问题的原因:
Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文(或者其他非英语系的语言),此时即使你把自己编写的Python源文件以UTF-8格式保存了,但实际上,这依然是不行的。解决的办法只要在上面的开头部分加上上面的那一句话即可
从爬取下来的页面源码中找出我们所需要的信息的方法:
一 使用正则表达式
二 在scrapy中, 我们可以使用一种基于XPath 和 CSS 的表达机制:Scrapy Selectors(选择器)
Selectors(选择器),四个基本的方法:
xpath():传入xpath表达式,返回表达式所对应的所有节点的selector list 列表
css(): 传入css表达式,返回表达式所对应的所有节点的selector list 列表
extract():序列化该节点为unicode字符串并返回list
re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串的列表
在命令行中运行scrapy shell 对爬取的网页进行分析

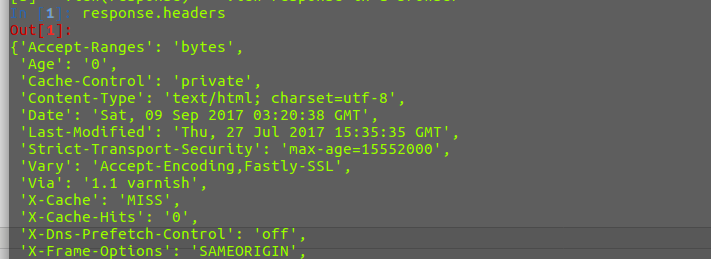
在shell 中输入response.headers,正确返回网页的头部信息即可
接下来可以是使用上述的四个方法对页面进行分析
使用XPath对页面进行分析:
XPath是一门在网页中查找特定信息的语言,所以用XPath来筛选数据,要比正则表达式容易些
XPath 的用法如下:
/html/head/title: 表示选择HTML文档中<head>标签内的<title>元素
/html/head/title/text():表示选择上面提到的<title>元素的文字
//td: 表示选择所有的<td>元素
//div[@class="mine"]: 表示所以具有class="mine"属性的div元素
response.xpath() == response.selector.xpath()
例如:使用response.xpath('//title'), //后面跟着一个标签的名字,表示选出所以标签为title的元素,如下,返回的是一个selector对象的列表

下面对返回的列表进行字符串化,可以使用extract()方法,返回的是一个unicode 的字符串

获取title中的文字,在后面加上/text()即可

取出所有的tag标签
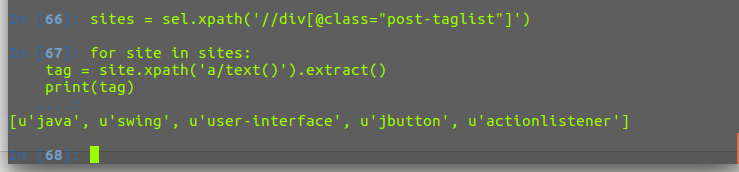
获取所有的标题和链接

四 存储内容
使用item容器,将上述爬取和筛选后的内容存入到item容器之中,在使用之前我们必须将item导入到spider中
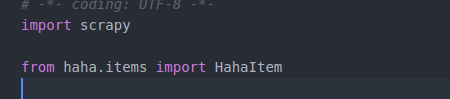
然后修改parse函数
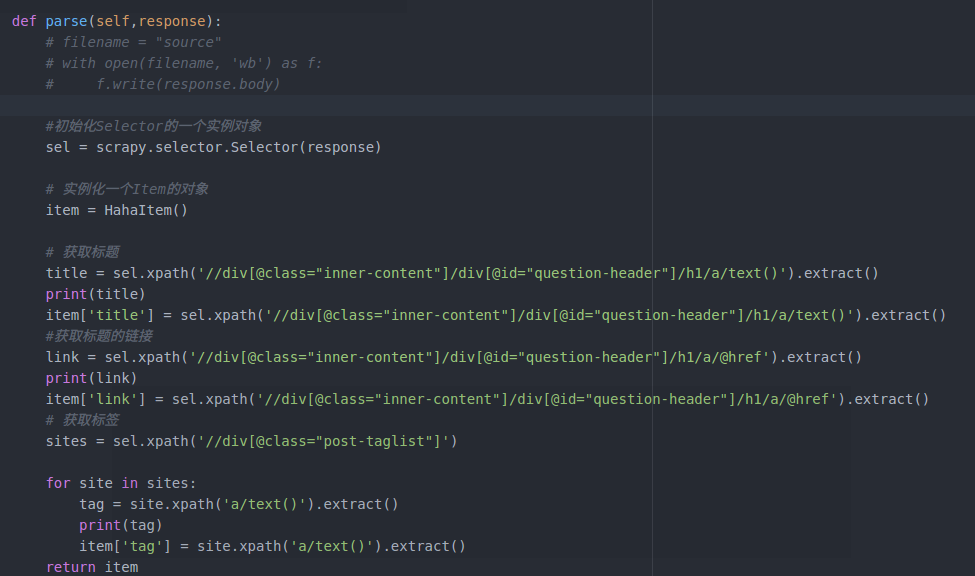
最后将数据导出,导出爬取的数据有四种格式(json,csv,xml等)
运行如下命令:
scrapy crawl haha -o items.json -t json
# 此处 -o 后面跟导出的文件名 -t 后面跟的是导出的形式
成功生成item.json文件

至此,第一个scrapy爬虫就宣告完毕了!!!

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步