python 爬取36K新闻
代码如下:
from urllib import request url = 'http://36kr.com/api/info-flow/newsflash_columns/newsflashes?b_id=65698&per_page=20&_=1498272599297' req = request.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36') resp = request.urlopen(req) print('Status:', resp.status, resp.reason) if 200 == resp.status: data = resp.read().decode('utf-8') else: print('Status Error!\n') exit(0)
#使用with打开文件会自动帮你关闭文件 with open('E:\\data.txt', 'w') as f: f.write(data) import json json_data = json.loads(data) with open('E:\\json_data.txt', 'w', encoding='utf-8') as f: json.dump(json_data, f, indent=4, ensure_ascii=False) for news in json_data['data']['items']: print(news['title']+'\n'+news['updated_at'] + '\n' + news['description'] + '\n\n') print('\nDone!\n')
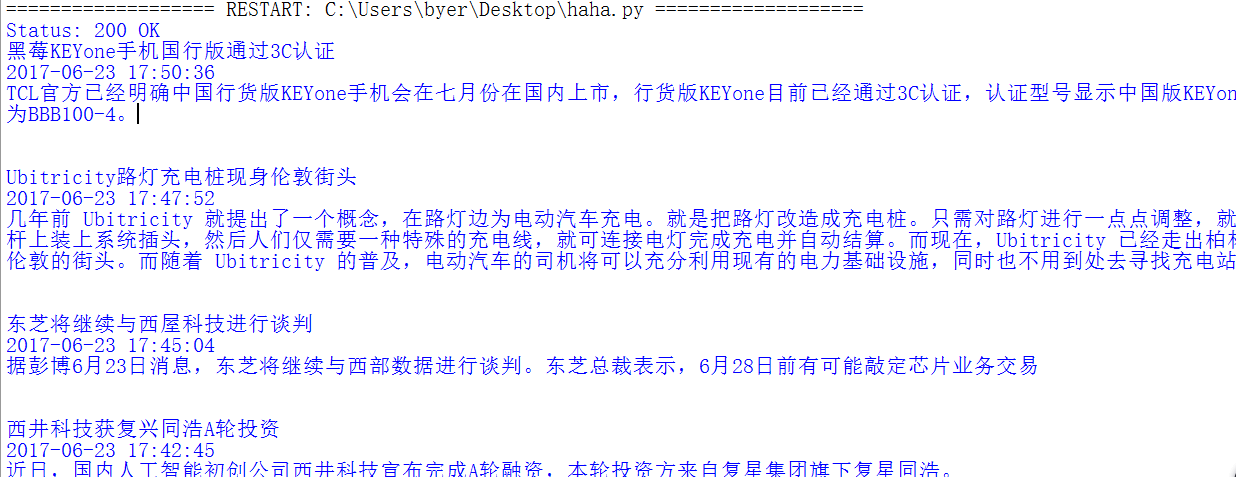
爬取效果图: