

nodeJS爬虫---慕课网
源代码一(爬取html源码)
//引入http模块
var http = require('http');
//引入url地址
var url = 'http://www.imooc.com/learn/271';
http.get(url,function(res){
var html = '';
res.on('data', function(data){
html += data;
})
res.on('end',function(){
console.log(html);
})
}).on('err', function(){
console.log('获取课程数据出错!');
})
源码二(爬取页面的具体信息)
//引入http模块
var http = require('http');
//引入url地址
var url = 'http://www.imooc.com/learn/271';
//引入cheerio对源码进行操作
var cheerio = require('cheerio');
//定义函数对源码进行过滤
function filterChapters(html){
var $ = cheerio.load(html);
//拿到每个大的章节
var chapters = $('.chapter ');
//声明一个数组用来存放所有的大章节的内容
var courseData = [];
//对每个大的章节进行遍历
chapters.each(function(item) {
//拿到单独的某一章
var chapter = $(this);
//获取章节的标题
var chapterTitle = chapter.find('strong').text();
//获取章节下面的内容
var videos = chapter.find('video').children('li');
//声明一个chapterData来存放一个章节的内容、
var chapterData = {
chapterTitle: chapterTitle,
videos: []
};
videos.each(function(item) {
var video = $(this).find('.J-media-item');
var videoTitle = video.text();
var id = video.attr('href').split('video/')[1];
chapterData.videos.push({
title: videoTitle,
id: id
});
});
courseData.push(chapterData);
});
return courseData;
}
//声明一个函数将取到的信息进行打印
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle = item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(item){
console.log(' ['+item.id+'] '+item.title+"\n");
})
})
}
http.get(url,function(res){
var html = '';
res.on('data', function(data){
html += data;
})
res.on('end',function(){
//调用对源码进行过滤的函数
var courseData = filterChapters(html);
//调用将信息进行打印的函数
printCourseInfo(courseData);
})
}).on('err', function(){
console.log('获取课程数据出错!');
})
源码一的内容太长,效果就不截图了,源码二的效果截图如下:
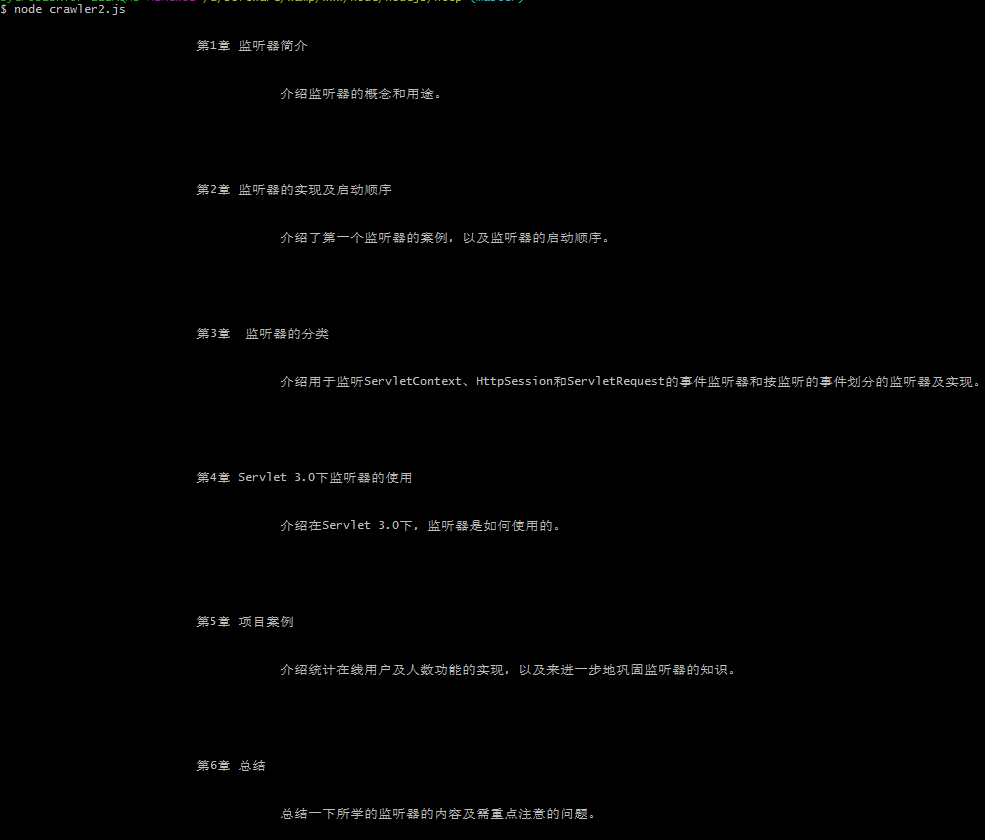
你也可以从https://github.com/byerHu/nodejs上下载源码!
