数据采集与融合技术实践作业三
作业①:Scrapy爬取中国气象网图片
1. 作业代码与实现步骤
Gitee文件夹链接:https://gitee.com/nongchenc/crawl_project/tree/master/作业3/第一题
步骤详解
- 单线程爬取:
- 使用 Scrapy 的Spider类创建一个爬虫,指定起始 URL 为中国气象网首页。
- 通过 Xpath 选择器定位到图片元素,提取图片的 URL。
- 设置限制总页数和总下载图片数量的逻辑,可以通过计数器来实现。
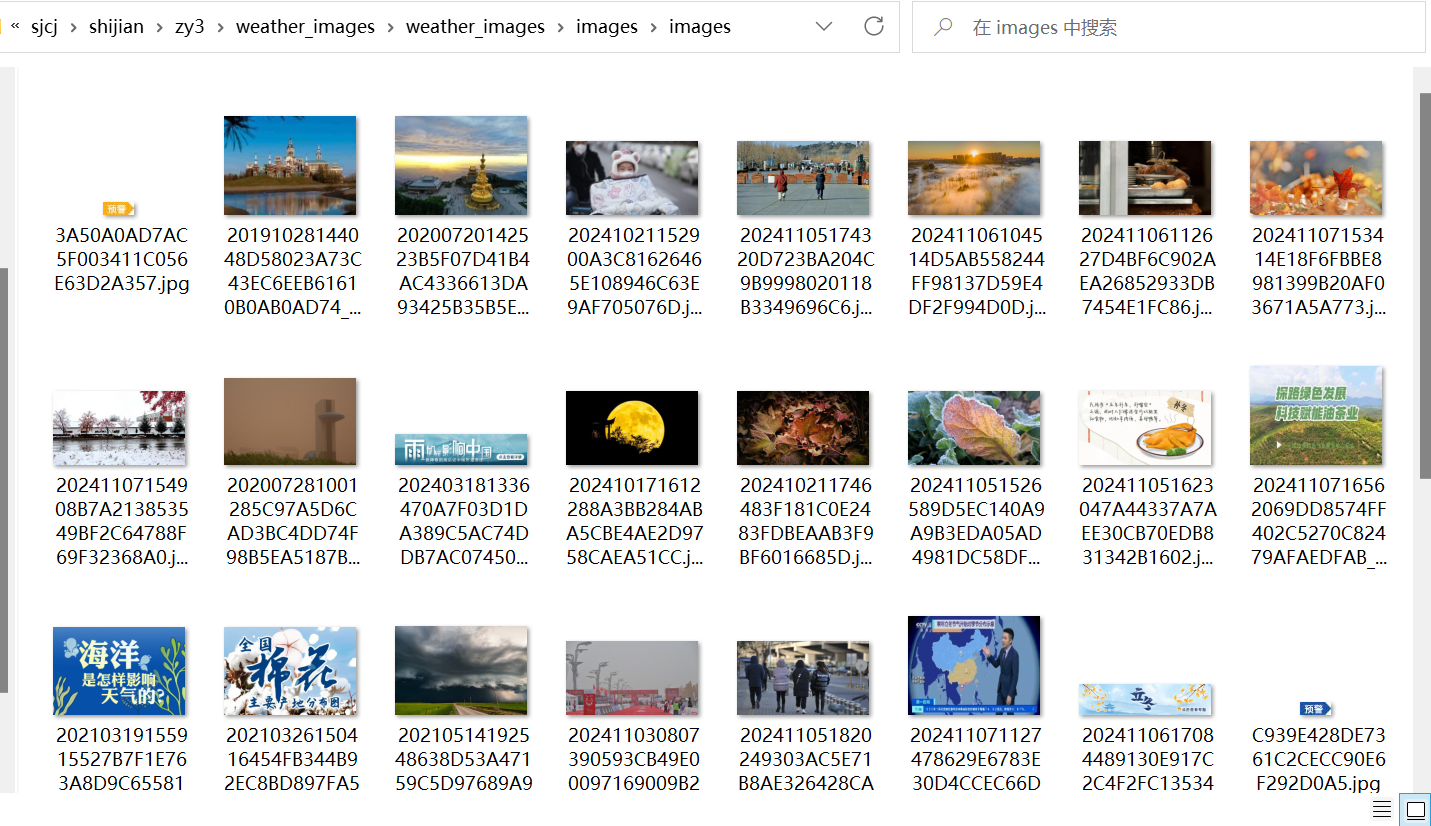
- 将下载的图片存储在images子文件夹中,并在控制台输出下载的 URL 信息。
- 多线程爬取:
- 配置 Scrapy 的设置,启用多线程下载。
- 其他步骤与单线程类似,但由于多线程的特性,需要注意线程安全和资源竞争问题。
代码示例
def parse(self, response):
# 如果超过限定页数,停止爬取
if self.current_page > self.total_pages:
print(f"达到最大页数限制:{self.total_pages}")
return
# 提取图片地址
imgs = response.xpath("//img/@src").extract()
# 下载图片并限制数量
for img in imgs:
if not img.startswith('http'):
img = response.urljoin(img) # 补全图片地址
if self.current_image_count < self.max_images:
item = WeatherImageItem()
item['image_urls'] = [img]
print(f"发现图片 URL: {img}") # 输出图片 URL 到控制台
yield item # 传输到管道
self.current_image_count += 1
else:
print(f"达到最大图片数量限制:{self.max_images}")
break
图片展示
打印结果
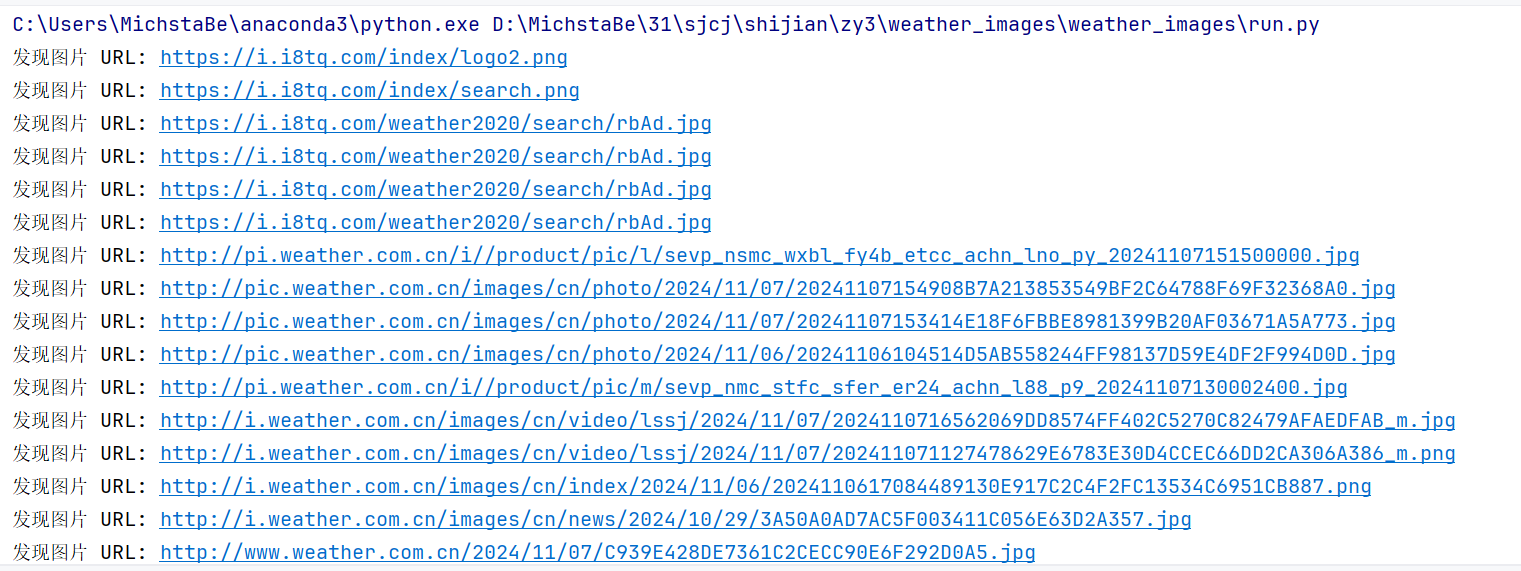
下载图片截图
2. 作业心得
在完成这个作业的过程中,我深刻体会到了 Scrapy 框架的强大之处。通过单线程和多线程的方式爬取图片,让我了解到不同方式的性能差异。设置限制爬取的措施也让我学会了如何更好地控制爬虫的行为,避免对目标网站造成过大的负担。
作业②:爬取东方财富网股票数据
1. 作业代码与实现步骤
Gitee文件夹链接:https://gitee.com/nongchenc/crawl_project/tree/master/作业3/第二题
步骤详解
- 数据爬取:
- 使用 Scrapy 创建一个爬虫,针对东方财富网进行爬取。
- 利用 Xpath 定位到股票信息的各个元素,如股票代码、股票名称、最新报价等。
- 将提取到的数据封装成Item对象。
- 数据存储:
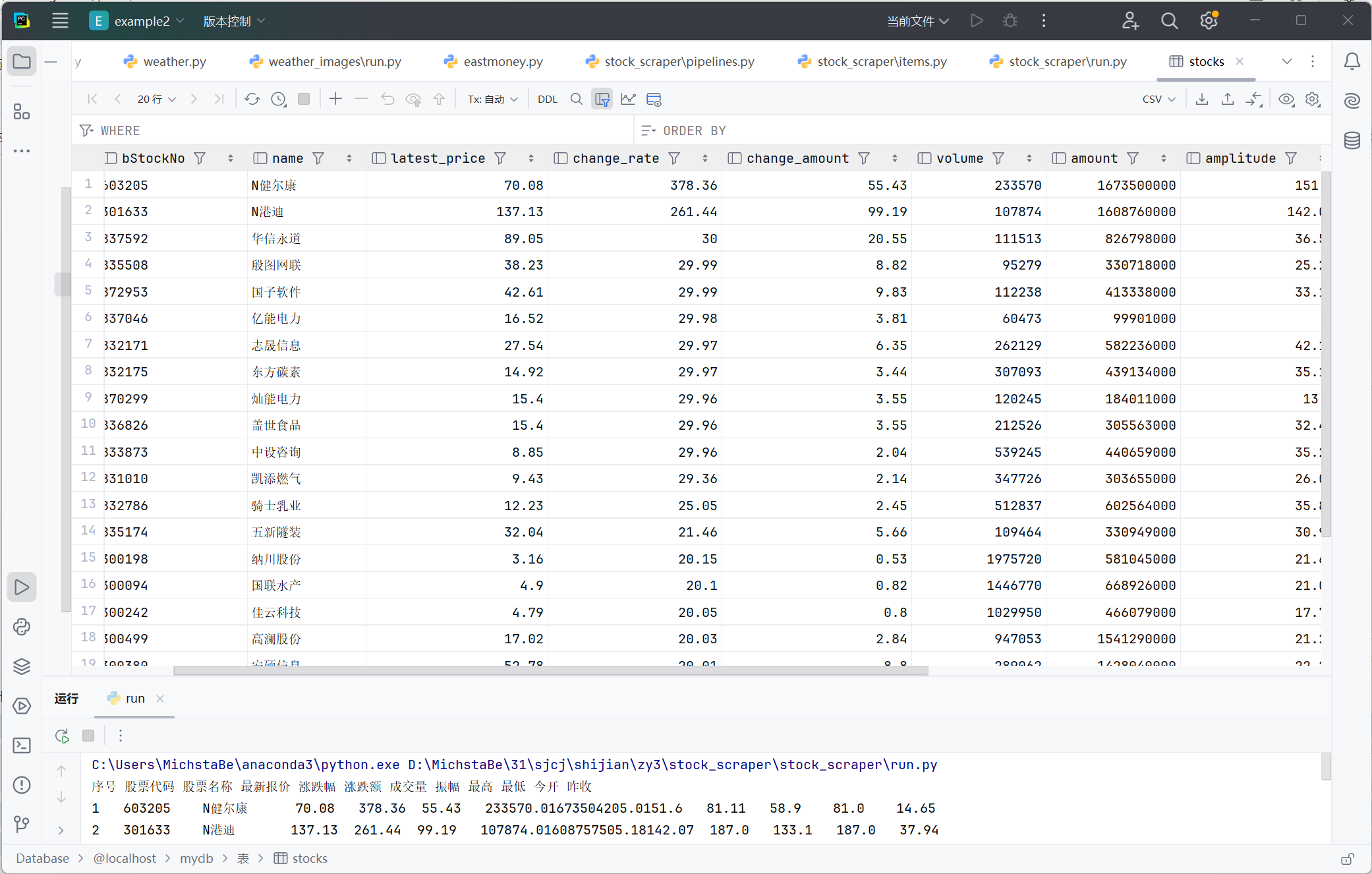
- 创建一个Pipeline,在其中连接 MySQL 数据库。
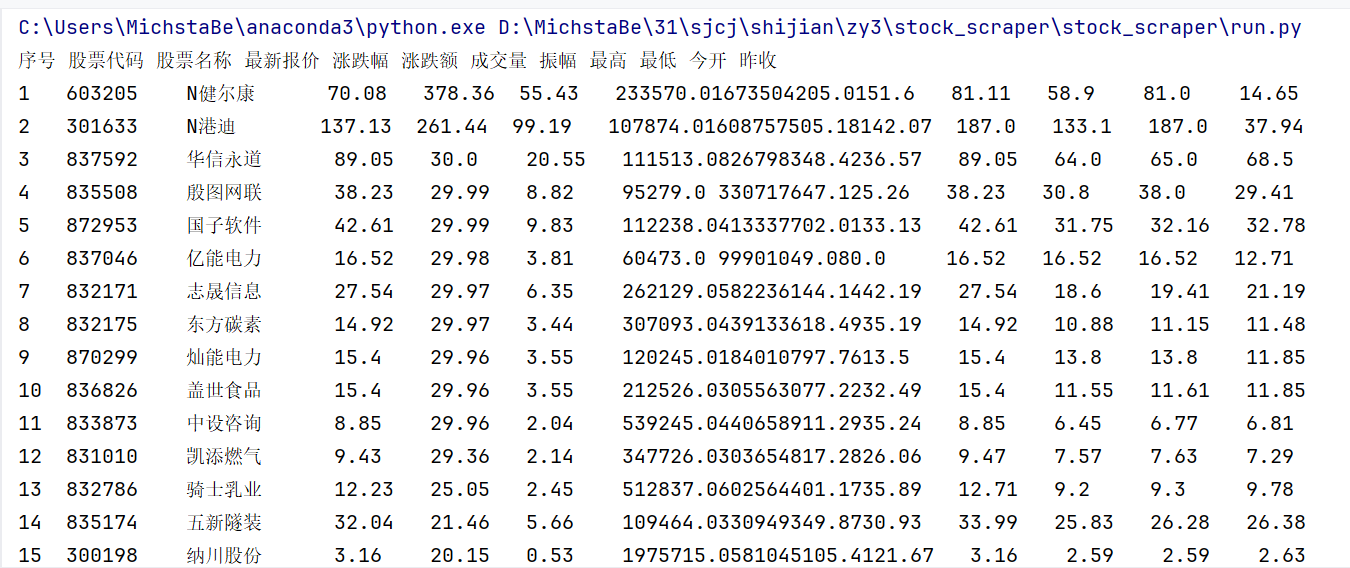
- 将Item中的数据插入到 MySQL 数据库中,并按照规定的输出格式展示。
代码示例
def parse(self, response):
data = json.loads(response.text[response.text.find("(")+1:-2]) # 去掉回调函数
stocks = data.get('data', {}).get('diff', [])
for stock in stocks:
item = StockItem()
item['bStockNo'] = stock['f12']
item['name'] = stock['f14']
item['latest_price'] = float(stock['f2']) if stock['f2'] != '-' else None
item['change_rate'] = float(stock['f3']) if stock['f3'] != '-' else None
item['change_amount'] = float(stock['f4']) if stock['f4'] != '-' else None
item['volume'] = float(stock['f5']) if stock['f5'] != '-' else None
item['amount'] = float(stock['f6']) if stock['f6'] != '-' else None
item['amplitude'] = float(stock['f7']) if stock['f7'] != '-' else None
item['highest'] = float(stock['f15']) if stock['f15'] != '-' else None
item['lowest'] = float(stock['f16']) if stock['f16'] != '-' else None
item['open_price'] = float(stock['f17']) if stock['f17'] != '-' else None
item['close_price'] = float(stock['f18']) if stock['f18'] != '-' else None
yield item
class StockItem(scrapy.Item):
id = scrapy.Field()
bStockNo = scrapy.Field() # 股票代码
name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新报价
change_rate = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amount = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
open_price = scrapy.Field() # 今开
close_price = scrapy.Field() # 昨收
图片展示
打印结果
数据库结果
2. 作业心得
这个作业让我对 Scrapy 的数据处理流程有了更深入的理解。通过Item和Pipeline的配合,能够高效地将爬取到的数据进行序列化输出和存储。在与 MySQL 数据库交互的过程中,我学会了如何正确地配置数据库连接和执行 SQL 语句。
作业③:爬取外汇网站数据
1. 作业代码与实现步骤
Gitee文件夹链接:https://gitee.com/nongchenc/crawl_project/tree/master/作业3/第三题
步骤详解
- 数据爬取:
- 针对中国银行外汇网站创建 Scrapy 爬虫。
- 使用 Xpath 提取外汇数据,包括货币名称、买入价、卖出价等。
- 将数据封装成Item。
- 数据存储与输出:
- 在Pipeline中连接 MySQL 数据库,将外汇数据存入数据库。
- 按照规定的输出格式在控制台输出数据。
代码示例
def parse(self, response):
rows = response.xpath('//table[@align="left"]//tr')
for row in rows[1:]: # 跳过表头
item = ForeignExchangeItem()
currency_text = row.xpath('./td[1]/text()').get()
item['currency'] = currency_text.strip() if currency_text else None
tbp_text = row.xpath('./td[2]/text()').get()
item['tbp'] = tbp_text.strip() if tbp_text else None
cbp_text = row.xpath('./td[3]/text()').get()
item['cbp'] = cbp_text.strip() if cbp_text else None
tsp_text = row.xpath('./td[4]/text()').get()
item['tsp'] = tsp_text.strip() if tsp_text else None
csp_text = row.xpath('./td[5]/text()').get()
item['csp'] = csp_text.strip() if csp_text else None
item['time'] = datetime.now().strftime('%H:%M:%S')
yield item
图片展示
打印结果

数据库结果
2. 作业心得
作业③进一步巩固了我对 Scrapy 和数据库操作的掌握。处理外汇数据的过程中,我学会了如何根据特定的格式要求进行数据输出。同时,也让我意识到在实际项目中,数据的规范化和准确输出对于后续分析和使用的重要性。通过这三个作业,我对 Scrapy 的应用有了更全面的认识和提高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号