
算法竞赛入门经典_5 c++与STL入门
直接跳到第五章了
c语言是一门很有用的语言,但在算法竞赛中却不流行,原因在于它太底层,缺少一些实用的东西。
下面是一个简单的c++框架
#include<cstdio> int main() { int a, b; while(scanf("%d%d", &a, &b) == 2) printf("%d\n", a+b); return 0; }
注:其中c++中的头文件使用sctdio代替stdio.h,cstring代替string.h,cmath代替math.h,cctype代替ctype.h
运行效果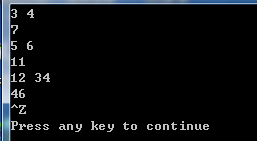
下面是更复杂的:
#include <iostream> #include <algorithm> using namespace std; const int maxn = 100 + 10; int A[maxn]; int main() { // long long a, b; // _int64 a, b; int a, b; while(cin >> a >> b) { //使用_MIN代替min,因为algorithm中没有min函数 cout <<_MIN(a, b) <<endl; } return 0; }
注:在vc6++不支持long long 类型,但是支持_int64的声明,不过在cin>>a>>b中会报错,因为不支持
运行效果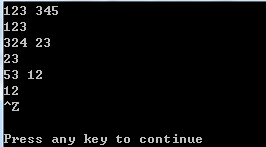
c++还支持引用类型
#include <iostream> using namespace std; void swap2(int &a, int &b) { int t = a; a = b; b = t; } int main() { int a = 3, b = 4; swap2(a, b); cout<< a << " "<< b << endl; return 0; }
运行效果: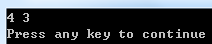
c++中对字符串的处理
#include <iostream> #include <string> #include <sstream> using namespace std; int main() { string line; while(getline(cin, line)) { int sum = 0; int x; stringstream ss(line); while(ss>>x) sum= sum + x; cout << sum << endl; } return 0; }
运行效果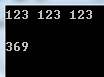
c++中结构体
#include <iostream> using namespace std; struct Point{ int x, y; Point(int x=0, int y=0 ):x(x),y(y){} }; Point operator + (const Point &A, const Point &B){ return Point(A.x + B.x, A.y + B.y); } ostream& operator << (ostream &out, const Point &p){ out<< "("<< p.x << "," <<p.y<< ")"; return out; } int main() { Point a, b(1,2); a.x = 3; cout << a + b<<endl; return 0; }
首先,c++不需要使用typedef来定义一个struct了,而且在struct中,除了可以有变量,还可以有函数
其中,:x(x),y(y)是“Point {int x =0, int y = 0}{this->x = x;this->y = y;}”的简写
此外,上面代码还使用了重载运算符
运行结果: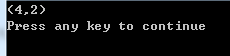
c++模板的使用:
#include<iostream> using namespace std; template<typename T> T sum(T *begin, T *end) { T *p = begin; T ans = 0; for(; p != end; p++) ans = ans + *p; return ans; } int main() { double a[] = {1.1, 2.2, 3.3, 4.4}; cout << sum(a , a+4) << endl; return 0; }
其中:使用template <typename T>声明一个模板T
运行效果:
c++的sort排序
题目:
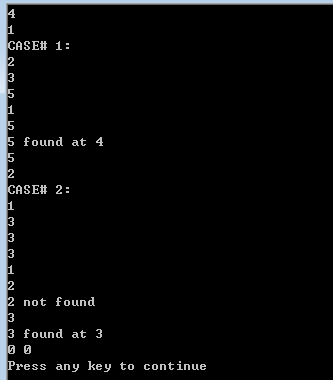
/* 大理石在哪儿问题 现有N个大理石,每个大理石上写了一个非负整数。首先把个数从小到大排序,然后回答 Q个问题,每个问题问是否有一个大理石写着某个整数x,如果是,还要回答哪个石上写 着x.排序后的大理石从左到右编号为1-N。 输入: 4 1 2 3 5 1 5 5 2 1 3 3 3 1 2 3 输出: CASE# 1: 5 found at 4 CASE# 2: 2 not found 3 found at 3 */
代码:
#include<algorithm> #include<iostream> using namespace std; const int maxn = 10000; int main() { int n, q, x, a[maxn], kase = 0; while(scanf("%d%d", &n, &q) == 2 && n){ printf("CASE# %d:\n", ++kase); for(int i = 0; i < n; i++) cin>>a[i]; sort(a, a+n); while(q--){ scanf("%d", &x); int p = lower_bound(a, a+n, x) - a; if(a[p] == x) printf("%d found at %d\n", x, p+1); else printf("%d not found\n", x); } } return 0; }
分析:sort函数可以对任意对象进行排序,参数1是数组起始地址,参数2是数组结尾地址,当然也可以定义自己的比较函数。
lower_bound函数是查找大于或等于x的第一个位置。参数1,2分别是起始和结束地址,参数3是待查数字x.
unique函数可以删除有序数组中的重复元素。
运行效果:
c++中的可变数组vector
问题:
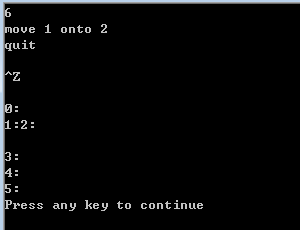
/* 木块问题 从左到右有n个木块,编号为0--n-1,要求模拟以下4种操作(a和b都是编号) move a onto b; 把a和b上方的木块全部归位,然后把a摞在b上面。 move a over b: 把a上方的木块全部归位,然后把a放在b所在木块的的顶部 pile a onto b: 把b上方的木块全部归位,然后把a和a上面的木块整体摞在b上面 pile a over b:把a及上面的木块整体摞在b上方的堆的顶部 */
代码:
#include <iostream> #include <algorithm> #include <string> #include <vector> using namespace std; const int maxn = 30; int n; vector<int> pile[maxn];//每个pile[i]是一个vector //找木块a所在的pile和height,以引用的形式返回调用者 void find_block(int a, int &p, int &h) { for(p = 0; p < n;p++) for(h = 0; h < pile[p].size(); h++) if(pile[p][h] == a)return; } //把第p堆高度为h的木块上方的所有木块移回原位 void clear_above(int p, int h){ for(int i= h+1; i < pile[p].size(); i++) { int b = pile[p][i]; pile[b].push_back(b);//把木块b放回原位 } pile[p].resize(h+1); //pile只应保留下标0-h的元素 } //把第p堆高度为h及上方的木块整体移动到p2堆得顶部 void pile_onto(int p, int h, int p2) { for(int i = h; i < pile[p].size(); i++) pile[p2].push_back(pile[p][i]); pile[p].resize(h); } void print() { for(int i = 0; i < n; i++) { printf("%d:", i); for(int j = 0; j < pile[i].size(); j++) printf("\n"); } } int main() { int a, b; cin >> n; string s1, s2; for(int i = 0; i < n; i++) pile[i].push_back(i); while(cin >> s1 >> a >> s2 >> b) { int pa, pb, ha, hb; find_block(a, pa, ha); find_block(b, pb, hb); if(pa == pb) continue; //非法指令,忽略 if(s2 == "onto") clear_above(pb, hb); if(s1 == "move") clear_above(pa, ha); pile_onto(pa, ha, pb); } print(); return 0; }
分析:上面的代码有一个值得学习的技巧:输入一共4条指令,处理这种问题的更好的方法是 提取出指令键的共同点,编写函数以减少重复代码。
clear()可以清空,resize()可以改变大小,push_back()和pop_back()分别是在尾部进行添加和删除元素。empty()是测试是否为空。
运行效果:
c++中的集合set
问题:
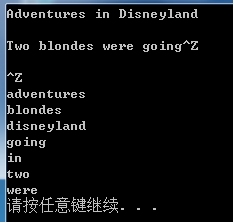
/* 安迪的第一个字典 输入一个文本,找出所有不同的单词(连续的字母序列), 按字典序从小到大输出,单词不区分大小写。 输入: Adventures in Disneyland Two blondes were going to Disneyland when they came to a fork in the road.The sign read :"Disneyland Left."; So they go home. 输出: a adventures blondes came disneyland */
代码:
#include<iostream> #include<algorithm> #include<string> #include<set> #include<sstream> using namespace std; set<string> dict; //string 字典集合 int main() { string s, buf; while(cin >> s) { for(int i = 0; i < s.length(); i++) if(isalpha(s[i])) s[i] = tolower(s[i]);else s[i] = ' '; stringstream ss(s); while(ss >> buf) dict.insert(buf); } for(set<string>::iterator it = dict.begin(); it != dict.end(); ++it) cout<< *it <<endl; return 0; }
分析:isalpha()判断是否是一个字母,tolower函数转化为统一的小写
stringstream是输入输出流,进行类型转化,insert()在集合中添加,
iterator是set对象中的迭代器,begin()和end()是指向开始和结束
*it取得当前对象的值
运行效果:
c++中的映射map:
问题:
/** 反片语 输入一些单词,找出所有满足如下条件的单词:该单词不能通过字母重排,得到输入的 文本中的另外一个单词。在判断是否满足条件时,字母不区分大小写,但在输出是应 保留输入中的大小写,按字典序进行排序(所有大写字母在小写字母的前面) 输入: ladder came tape soon leader acme RIDE lone Disk derail peat ScALE orb eye Rides dealer NotE LaCeS drIed noel dire mace Rob dries # 输出: Disk Note derail drIed eye ladder soon */
代码:
#include<iostream> #include<string> #include<cctype> #include<vector> #include<map> #include<algorithm> using namespace std; map<string, int> cnt; vector<string> words; //将单词s标准化 string repr(const string &s) { string ans = s; for (int i = 0; i < ans.length(); i++) { ans[i] = tolower(ans[i]); } sort(ans.begin(), ans.end()); return ans; } int main(){ int n = 0; string s; while (cin >> s) { if (s[0] == '#') break; words.push_back(s); string r = repr(s); //判断cnt中是否存在键r if (!cnt.count(r)) cnt[r] = 0; cnt[r]++; } vector<string> ans; for (int i = 0; i < words.size(); i++) if (cnt[repr(words[i])] == 1) ans.push_back(words[i]); sort(words.begin(), words.end()); for (int i = 0; i < ans.size(); i++) cout << ans[i] << endl; return 0; }
分析:map有键和值,key value,同样和set集合有类似的insert,find,count和remove操作,此外map还提供了[]运算符
insert是插入键值,find是查找指定位置的值,count是查找值是否存在,remove删除。
运行效果:
c++中的栈
stack<int> s;
push()入栈,pop()出栈,top()取栈顶元素
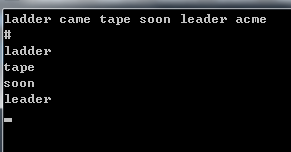
c++中的队列
queue<int> s; push入队,pop出队,front取队首元素。
问题
/* 团体队列 有t个团队正在排一个长队,每次新来一个人时,如果他有队友在排队, 那么这个新人会插到最后一个队友的身后。如果没有任何一个队友排队 ,则他会排到长队的队尾。 输入每个团队中所有队员的编号,要求支持如下3种指令(前两种可以穿插进行) ENQUEUE x: 编号为x的人进入长队 DEQUEUE :长队的队首出队 STOP : 停止模拟 对于每个DEQUEUE 指令,输出出队的人的编号 */
代码:
#include<cstdio> #include<iostream> #include<queue> #include<map> using namespace std; const int maxt = 1000 + 10; int main() { int t, kase = 0; while (scanf("%d", &t) == 1 && t) { printf("Scenario #%d\n", ++kase); //记录所有人的团队编号 map<int, int> team; //team[x]表示编号为x的人所在的团队编号 for (int i = 0; i < t; i++) { int n, x; scanf("%d", &n); while (n--) { scanf("%d", &x); team[x] = i; } } //模拟 queue<int> q, q2[maxt]; //q是团队队列,而q2[i]是团队i成员的队列 for (;;) { int x; char cmd[10]; scanf("%s", cmd); if (cmd[0] == 'S') break; else if (cmd[0] == 'D'){ int t = q.front(); printf("%d\n", q2[t].front()); q2[t].pop(); if (q2[t].empty()) q.pop();//团体t全体出队列 } else if (cmd[0] == 'E') { scanf("%d", &x); int t = team[x]; if (q2[t].empty()) q.push(t);//团队t进入队列 q2[t].push(x); } } printf("\n"); } getchar(); getchar(); return 0; }
分析:
首先进行的是记录所有大团队的编号
用一个team映射键保存每个队的成员编号,值保存每个队的序号。team[编号] = 队序号
然后是模拟阶段,定义了一个q来保存大团队的队列,q2保存个成员所在队列。
分析好了这个,下面就是各种命令就好办了。
运行效果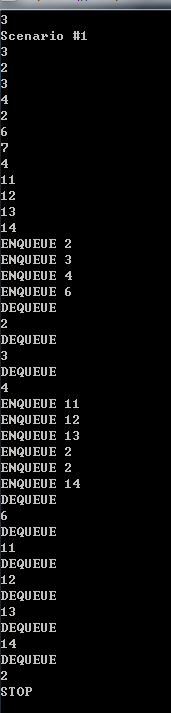
c++中的优先队列
问题
/* 丑数 丑数是指不能被2,3,5以外的其他素数整除的数。把丑数从小到大排列起来,结果如下 1,2,3,4,5,6,7,8,9,10,12,15,... 求第1500个丑数 */
代码
#include<iostream> #include<functional> #include<vector> #include<queue> #include<set> using namespace std; typedef long long LL; const int coeff[3] = {2, 3, 5};//系数 int main() { priority_queue < LL, vector<LL>, greater<LL> > pq; set<LL> s; pq.push(1); s.insert(1); for (int i = 1; ; i++) { LL x = pq.top(); pq.pop(); if (i == 1500) { cout << x << endl; break; } for (int j = 0; j < 3; j++) { LL x2 = x * coeff[j]; if (!s.count(x2)) { s.insert(x2); pq.push(x2); } } } getchar(); return 0; }
分析:
越小的整数优先级越大的优先队列可以用queue头文件中的priority_queue<int, vector<int>, greater<int> > pq;
注意:greater比较模板在functional头文件中,结尾的 > >不能写在一起
先定义一个优先队列pq来保存所有已生成的丑数,集合s来保存所有的丑数
然后取出队首元素,这里是取出一个数然后生成3个丑数,并判断是否已经生成过。
答案:859963392
stl测试
先看代码:
#include<iostream> #include<cstdlib> #include<vector> #include<algorithm> #include<cassert> #include<ctime> using namespace std; void fill_random_int(vector<int>& v, int cnt) { v.clear(); for (int i = 0; i < cnt; i++) v.push_back(rand()); } void test_sort(vector<int>& v) { sort(v.begin(), v.end()); for (int i = 0; i < v.size() - 1; i++) assert(v[i] <= v[i+1]); } int main() { srand(time(NULL)); vector<int> v; fill_random_int(v, 1000000); test_sort(v); getchar(); return 0; }
分析:库不一定没有bug,我们要学会如何测试一个库
首先需要用到随机数,rand()函数实在cstdlib中,使用前需要srand(time(NULL))初始化随机种子
我们定义一个函数fill_random_int来网vector可变数组中存放随机数,void clear(): 函数clear()删除储存在vector中的所有元素.
assert作用是:当表达式为真时无变化,但当表达式为假时强行终止程序
算法题:
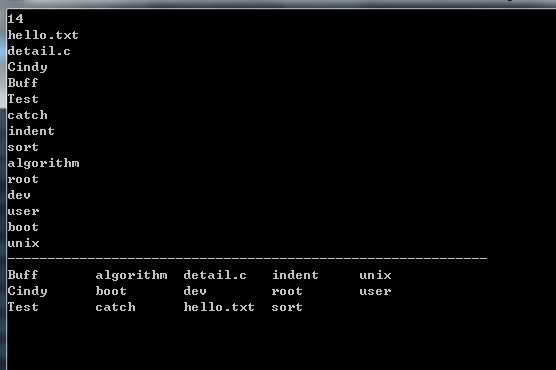
(1)Unix ls命令
问题
/* Unix ls命令问题 输入正整数n以及n个文件名,排序后按列优先方式左对齐输出。 假设最长文件名有M字符,则最右列有M字符,其他列都是M+2字符 */
代码
#include<iostream> #include<string> #include<algorithm> using namespace std; const int maxcol = 60; const int maxn = 100 + 5; string filename[maxn]; //输出字符串s,长度不足len时补字符extra void print(const string& s, int len, char extra) { cout << s; for (int i = 0; i < len - s.length(); i++) cout << extra; } int main() { int n; while (cin >> n) { int M = 0; for (int i = 0; i < n; i++) { cin >> filename[i]; M = max(M, (int)filename[i].length()); } //计算列数cols和行数rows int cols = (maxcol - M) / (M + 2) + 1, rows = (n - 1) / cols + 1; print("", 60, '-'); cout << endl; sort(filename, filename + n); for (int r = 0; r < rows; r++) { for (int c = 0; c < cols; c++) { int idx = c * rows + r; if (idx < n) print(filename[idx], c == cols - 1 ? M : M+2, ' '); } cout << "\n"; } } return 0; }
效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号