Linux常用命令
Linux常用命令
1. read命令
Linux read命令用于从标准输入读取数值,当使用重定向的时候,可以读取文件中的一行数据
read [-ers] [-a aname] [-d delim] [-i text] [-n nchars] [-N nchars] [-p prompt] [-t timeout] [-u fd] [name ...]
参数说明
- -a 后跟一个变量,该变量会被认为是个数组,然后给其赋值,默认是以空格为分割符
- -d 后面跟一个标志符,其实只有其后的第一个字符有用,作为结束的标志(作为什么结束的标志?)
- -p 后面跟提示信息,即在输入前打印提示信息
- -e 在输入的时候可以使用命令补全功能
- -n 后跟一个数字,定义输入文本的长度,当输入计数到定义的长度后,读取自动停止
- -r 屏蔽\,如果没有该选项,则\作为一个转义字符,有的话 \就是个正常的字符了
- -s 安静模式,在输入字符时不再屏幕上显示,例如login时输入密码
- -t 后面跟秒数,定义输入字符的等待时间
- -u 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的
示例代码
#! /bin/bash
# -p参数
read -p "Please input option: " Opt
echo The user input is: $Opt
# -d参数
read -de cm # 将输入读取到变量cm中,碰到字符e则停止读取(读取结果不包含e),无需按回车
echo # 换行
echo The user input is: $cm
# -n参数
read -n5 -p "Please input your name: " name # 限定长度为5,读取计数到5自动结束
echo # 换行 自动结束的需要添加换行
echo The user name is: $name
# -s参数
read -s -p "Please input code: " code
echo The code is: $code
# -t参数
if read -t3 -p "Please input content: " content ; then
echo The content is : $content
else
echo You has expired!
fi

2. echo命令
echo命令用于字符串输出
echo content # 会默认换行
参数:
- -e 开启转义,打印出转义字符
- -n 去掉echo末尾默认的换行符
示例代码
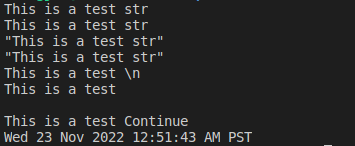
echo This is a test str
echo "This is a test str"
echo \"This is a test str\"
echo "\"This is a test str\""
echo "This is a test \n"
#换行 -e开启转义,实现换行 \n
echo -e "This is a test \n"
# 不换行 -e开启转义,实现不换行 \c
echo -e "This is a test \c"
echo "Continue"
# 显示执行结果
echo `date`
# 显示结果定向至文件
echo "This is a test.\n" > myfile.txt
3. file命令
file命令主要用于辨识文件的类型
file [-bcLvz][-f <名称文件>][-m <魔法数字文件>...][文件或目录...]
参数含义
- -b 列出辨识结果时,不显示文件名
- -c 详细显示指令的执行过程,便于分析程序执行情形
- -f 指定文件名称,当有一个或者多个文件名称的时候,让file依次辨识这些文件
- -L 显示链接符号所指向的文件的类型
- -m 制定魔法数字文件
- -v 显示版本信息
- -z 尝试去解读压缩文件的内容
- [文件或目录列表] 要确定类型的文件列表,多个文件之间使用空格分隔开来,可使用shell通配符来匹配多个文件
示例代码
#! /bin/bash
# 获取当前目录
cur_dir=$(pwd)
script_path=$cur_dir/demonscript4.sh
file $script_path
file -b $script_path
file -i $script_path
file -i -b $script_path
不同文件类型的魔术数字(附加)
文件类型的魔术数字,指定是文件的最开头的几个用于唯一区别其它文件类型的字节,有了这些魔术数字,我们就可以很方便的区别不同的文件,这是除了后缀名区分文件类型的另一种区分文件类型的方法。例如,对于一个JPEG文件,开头的可能是“ffd8 ffe0 0010 4a46 4946 0001 0101 0047 ……JFIF…..G”之类的字符,"ffd8"就表示这个文件是一个JPEG类型的文件,"ffe0"表示这个文件是一个JFIF结构,以下列出几种常见文件类型的魔术数字以及对应的ASCII字符:
| 文件类型 | 后缀名 | 魔术数字 | ASCII字符 |
|---|---|---|---|
| Bitmap Format | .bmp | 42 4d | BM |
| GIF Format | .gif | 47 49 46 38 | GIF8 |
| JPEG File Interchange Format | .jpg | ff d8 ff e0 | .... |
| PNG format | .png | 89 50 4e 47 | .PNG |
| pkzip format | .zip | 50 4b 03 04 | PK.. |
获取当前shell脚本所在的路径
介绍两种shell脚本中获取脚本文件所在路径的方法
#! /bin/bash
# 方法1 获取当前目录
cur_dir=$(pwd)
# 方法2 获取当前目录
cur_dir=`cd $(dirname $0); pwd`
# dirname $0,取得当前执行的脚本文件的父目录 pwd 显示当前工作目录
4. cut 命令
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出,如果没有指定file参数,cut命令将读取标准输入,显示每行从头开始算起num1到num2的文字,语法如下所示:
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
参数含义
- -b 以字节为单位进行分割,这些字节位置将忽略多字节边界符,除非指定了-n参数
- -c 以字符为单位进行分割
- -d 自定义分割符,默认为制表符
- -f 提取指定的字段
- -n 取消分割多字节字符,仅仅和-b一起配合使用
5. unset命令
unset命令用于删除已定义的变量(shell变量或者环境变量),或者shell函数
unset [-fv][变量或函数名称]
参数含义
- -f 仅删除函数
- -v 仅删除变量
export usernametest=ubantu_all # 定义环境变量
echo $usernamett # 查看环境变量
unset usernamett # 删除环境变量

6. 文件压缩与解压命令
zip压缩文件
.zip格式是windows和Linux通用的压缩文件格式,命令的基本格式如下
zip [-AcdDfFghjJKlLmoqrSTuvVwXyz$][-b <工作目录>][-ll][-n <字尾字符串>][-t <日期时间>][-<压缩效率>][压缩文件][文件...][-i <范本样式>][-x <范本样式>]
参数含义(常用几个参数)
- -r 递归压缩目录
- -m 压缩完成后,删除原始的文件
- -v 显示压缩的详细过程
- -q 压缩的时候不显示命令的执行过程
- -n n取(1-9),压缩级别,1代表压缩速度更快,9代表压缩效果更好
- -u 更新压缩文件,即往压缩文件中添加新文件
示例代码
#! /bin/bash
# 获取当前脚本路径
cur_dir=`cd $(dirname $0); pwd`
echo "Current script path is $cur_dir"
filenames=test # 文件名
filecount=4 # 文件个数
fileSuffix=.txt # 文件后缀名
# 数组
files=()
for((i=0;i<$filecount;i++)); do
index=$(($i+1))
#let index=$i+1 # i+1等效写法
#index=`expr $i + 1` # i+1等效写法
filenamepath=${cur_dir}/${filenames}${index}${fileSuffix}
if [ -e $filenamepath -a -f $filenamepath ]; then
rm -f $filenamepath
if [ $? -eq 0 ]; then
echo "Success delete file \"$filenamepath\"" # 删除成功,给出提示
fi
fi
touch $filenamepath
if test $? -eq 0 ; then # 获取touch命令的执行结果,0 成功
echo "Success created file \"$filenamepath\"" >> $filenamepath
fi
# 文件名保存在数组中
files[$i]=$filenamepath
done
# 压缩文件的个数 求取数组长度
filescount=${#files[@]}
echo "Total $filescount file(s) to be compressed."
for((i=0;i<$filescount;i++)); do
filename=${files[i]}
#let fileindex=$i+1
#if [ $fileindex -ge 3 ] ; then
# break
#fi
echo "zipping file \"$filename\""
if test $i -eq 0 ; then
zip -2 test.zip $filename
continue
fi
zip -u -2 test.zip ${filename} # 所有文件压缩
done
echo "------End-----"
unzip命令解压文件
unzip命令用于解压.zip压缩文件
unzip [-cflptuvz][-agCjLMnoqsVX][-P <密码>][.zip文件][文件][-d <目录>][-x <文件>] 或 unzip [-Z]
参数含义
- -d 将压缩文件解压到指定目录下 unzip -d dirname *.zip
- -n 解压时不覆盖已存在的文件
- -o 解压时覆盖已存在的文件,且无需用户确认
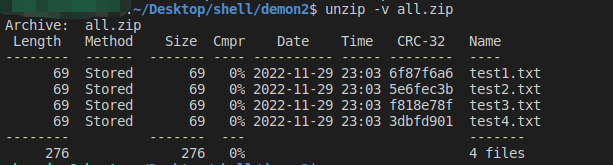
- -v 查看压缩文件的详细信息,包括压缩文件中包含的文件大小、文件名以及压缩比等,但并不做解压操作
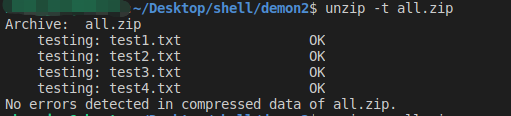
- -t 测试压缩文件是否损坏,但是不解压文件
- -x 解压文件,但是-x指定的文件会跳过,不进行解压
示例代码
#! /bin/bash
unzip -d ./unzipdir ./test.zip # 指定解压目录
unzip ./test.zip -x file1 file2 # 不解压file1 file2

tar命令
tar命令可用于压缩和解压文件
参数含义:
- -tf 用于在不解压包的情况下,查看压缩文件内包含哪些文件和目录(有用)
- -zcvf 将文件打包为*.tar.gz格式的压缩文件
- -zxvf 对压缩包进行解压
- -C 将压缩包解压到指定的目录,通过-C来指定解压目录
tar -zxvf test.tar.gz -C /home/user/test
tar -zcvf命令在压缩文件的时候,如果文件带有目录,则会将文件的目录结构压缩至压缩文件中,如果需要去除文件携带的目录,仅仅将文件进行压缩归档至同一目标目录下,则需要使用-C参数,进行临时目录切换,命令格式如下:
tar -zcvf test.zip -C/home/user/nero mut.txt -C/home/user/hug pik.dat
此时压缩文件中不在有文件携带的目录
xz命令
xz是POSIX平台开发的高效压缩解压工具,它使用LZMA2压缩算法,生成的压缩文件比POSIX平台传统的gzip,bzip2的压缩率更低,且压缩速度更快。
xz [OPTION]... [FILE]...
参数含义:
- -z 压缩文件
- -d 解压文件
- -t 测试压缩文件的完整性
- -l 显示压缩文件的相关信息
- -k 压缩或者解压缩时不删除源文件(保留源文件)
- -e 常使使用更多的时CPU时间来提高压缩率,不会影响解压所需的内存大小(extreme)
- -7 (1...9),压缩预设,默认值6,如果使用更高的值,需要考虑到所占的内存大小
- -T 指定最多使用的线程数,默认线程数为1,如果设置为0,使用与处理器内核一样多的线程
- -q 安静模式,不显示压缩信息
xz命令仅限于压缩文件
7. cp命令
cp命令用于将一个或者多个文件,或者目录复制到指定位置,也可用于文件的备份
参数含义
- -f 若目标文件已经存在,则会直接将目标文件进行覆盖
- -i 若目标文件已经存在,则会询问是否进行覆盖
- -p 保留源文件或者源目录的所有属性
- -r 递归复制,用于文件夹拷贝
- -b 覆盖已存在的目标文件时,将目标文件进行备份
- -v 详细显示cp命令执行的操作过程
- -d 当复制符号链接的时候,把目标文件或者目录也建立为符号链接,并将其指向源文件或者源目录所连接的文件或者目录
- -l 对源文件建立硬连接,而非复制文件
- -s 对源文件建立软连接,而非复制文件
- -a 等价于-pdr
8. find命令
find命令是Linux中强大的搜索命令,可以按照文件名,文件权限,文件大小,时间,inode号等信息搜索文件���因为find命令是直接在硬盘中进行搜索,因此对其指定合适的搜索范围特别重要,如果搜索的范围过大,就会导致消耗较大的系统资源。
命令格式:
find path -option [ -print ] [ -exec -ok command ] {} \;
path : 搜索路径
option : 搜索选项
选项
- -name 按照文件名进行搜索
- -iname 按照文件名进行搜索,不区分大小写
- -inum 按照inode号进行搜索
- -size[+-] 按照文件大小进行搜索, +表示大于size的文件,-表示小于size的文件,(M, k)
- -type 按照特定的类型查找文件, d-目录 f-一般文件 l-符号链接 s-套接字文件 c-字符设备 b-块设备
- -print 将搜索结果输出到标准输出
- -ctime 按照文件创建时间进行搜索 [+-n]
- -mtime 按照文件更改时间进行搜索 [+-n]
- -atime 按照文件访问时间进行搜索 [+-n]
- -perm 按照文件权限进行搜索
按照文件类型搜索,可选的文件类型如下所示
| 符号 | 含义 |
|---|---|
| d | 搜索目录 |
| f | 搜索一般文件 |
| l | 搜索链接文件 |
| s | 搜索套接字文件 |
| c | 搜索字符设备文件 |
| b | 搜索块设备文件 |
按照文件大小搜索,表示文件大小的可选单位如下所示:
| 符号 | 含义 |
|---|---|
| b | 块 512字节 |
| c | 字节 |
| w | 字 |
| k | 千字节 |
| M | 兆字节 |
| G | 吉字节 |
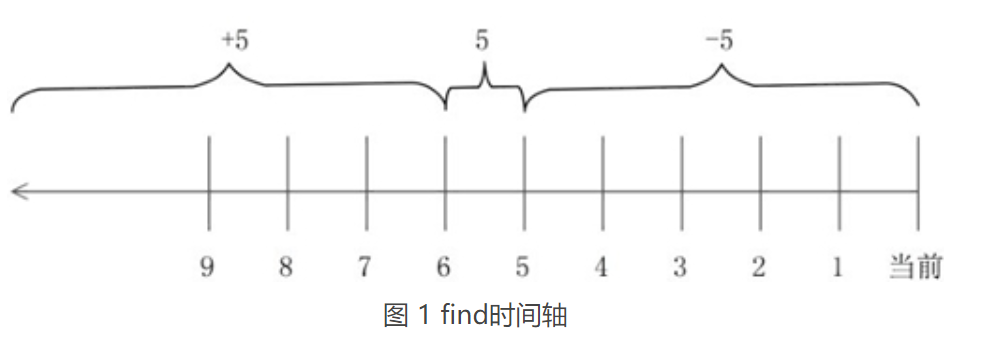
按照修改时间,创建时间,访问时间进行修改,指定时间时可通过+-来指定特定范围的时间,具体使用方式如下所示:
| 符号 | 含义 |
|---|---|
| -n | 表示从当前时间算起,n天以内 |
| n | 表示从当前时间算起,第n年 |
| +n | 表示从当前时间算起,第n天以前 |
示例代码
find ./ -name "*.txt" # 查找后缀名为.txt的文件
find ./ -type f # 查找普通文件
9. wc命令
Linux自带的工具,可以统计文件中文本的行数,字符数,以及字数.
参数含义:
- -c 统计文件中有多少个字符
- -w 统计文件中有多少个字
- -l 统计文件中行数
wc -c ./test.txt
10. top命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况,类似于windows的任务管理器。top是一个动态显示过程,用户可以通过按键来刷新当前状态。如果在前台执行该命令,它将独占前台,直到用户终止程序为止。
top命令提供了对系统处理器状态的实时监视,它会将系统中的CPU任务列表进行展示,可以按照CPU使用,内存使用,以及执行时间对任务进行排序。
参数含义:
- -d 显示信息的更新周期,默认为3s
- -p 仅仅监视指定的pid的进程
- -u 仅监视某个指定用户的进程
- -n 指定循环显示的次数
在top命令的显示窗口中,还可以使用一些命令与其进行交互:
? | H显示交互模式的帮助信息P按照CPU的使用率进行任务列表排序M按照内存的使用率进行排序N按照PID进行排序q退出top命令
11. wget命令
wget命令是Linux下用于从指定网站下载文件的命令,支持http,https,ftp等常见协议
参数含义:
- -V : 显示
wget版本信息 - -h : 显示帮助信息
- -b : 启动后转入后台运行
- -c : 支持断点续传
- -O : 指定输出文件
- --limit-rate=<speed> : 指定最大下载速度speed
- -4 : 仅连接到IPV4
- -6 : 仅连接到IPV6
- -o : 指定日志文件的输出路径
- -v : 显示下载过程中的详细信息
- -q : 安静模式,无信息输出
- -r : 递归下载
示例:
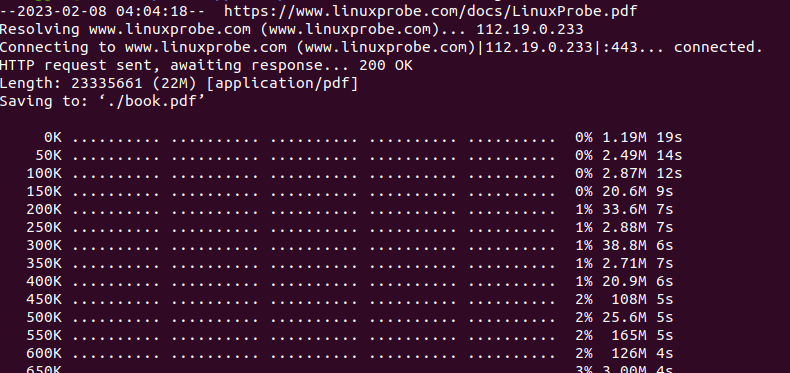
wget -O ./book.pdf -o ./download.log -c https://www.linuxprobe.com/docs/LinuxProbe.pdf
# 打开PDF文件
evince book.pdf
下载成功后,可通过evince命令打开pdf文件进行阅读
查看下载的日志如下所示:
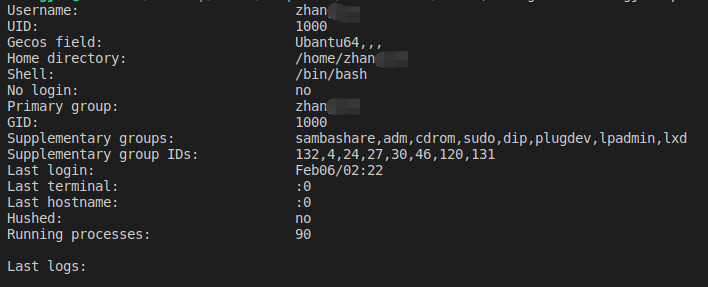
12. lslogins命令
lslgoins命令可以展示出系统中现有用户的相关信息,该命令会检查wtmp和btmp日志,以及/etc/passwd并输出用户相关的数据。
参数含义:
- -u 指定只展示特定用户的相关信息
13. netstat命令
netstat是一个监控TCP/IP网络的常用工具,可以显示路由表,实际的网络连接,以及网络接口设备的状态信息,以及检验本机个端口的连接情况。
参数含义:
- -t 显示TCP传输协议的连接情况
- -u 显示UDP传输协议的连接情况
- -a 显示当前的网络连接情况,TCP合UDP协议都会列出来,包括本地IP端口,远程IP端口,以及连接状态
- -n 直接显示IP地址,不显示别名
- -r 显示路由表的信息
- -p 显示建立连接的相关程序名
- -l 仅列出在Listen的服务状态
常用指令:
netstat -apn | grep "port number"
查看端口被哪个进程占用:
lsof -i:20001
14. ldd命令
15. snap命令
snap是Ubantu公司引入的一种安全的,易于管理的,沙盒化的软件包格式,与传统的dpkg/apt有着很大的区别;彻底解决了Linux的依赖性问题,snap可以同时安装一个软件的多个版本;
apt所采用的包是deb包;deb包最初由Deb Linux推出,由于ubuntu基于debian,ubuntu将其集成到了apt包管理器中。apt可以自动解决软件之间依赖问题,ubuntu创建了一个类似apple store的软件商店。
snap是Canonical公司发布的全新的软件包管理方式,它类似一个容器拥有一个应用程序所有的文件和库,各个应用程序之间完全独立。所以使用snap包的好处就是它解决了应用程序之间的依赖问题,使应用程序之间更容易管理。但是由此带来的问题就是它占用更多的磁盘空间。
常用参数:
- snap version
查看snap的版本信息
- snap find softwarename
查找软件
- snap info softwarename
查看软件相关的信息
- snap list / snap list --all softwarename
列出所有通过snap安装的软件包
- snap install softwarename
安装软件包
- snap refresh sofwarename
更新已安装的软件
- snap enable/disable softwarename
启用/禁止软件
- snap remove softwarename / snap remove softwarename --purge
卸载软件 / 彻底卸载软件
- snap run softwarename
运行对应的软件包
snap对安装的软件具有三种隔离级别:
- strict -- 严格
在默认情况下,使用snap安装的软件包都是该级别,该级别可以认为是安全的,因为它提供了最小的访问权限,在未进行特殊授权的情况下,软件不能访问文件,网络,进程等系统资源; - classic --传统
和传统安装的软件一样,可以访问系统资源,在安装时带上--classic参数 - devmodes
为开发者提供的特殊模式。软件可以完全访问系统资源,并会输出调试信息。安装时需带上--devmode参数.
例如,安装vscode:
sudo snap install -classic code
16. sed命令
sed是一种流编辑器,是进行文本处理的工具,能够配合正则表达式使用。Sed主要用来自动编辑一个或多个文件,可以将数据行进行替换、删除、新增、选取等特定工作,简化对文件的反复操作,编写转换程序等。
sed 命令是一个面向行处理的工具,它以“行”为处理单位,针对每一行进行处理,处理后的结果会输出到标准输出(STDOUT)。你会发现 sed 命令是很懂礼貌的一个命令,它不会对读取的文件做任何贸然的修改,而是将内容都输出到标准输出中。(不修改文件本身的内容)
参数含义:
- -e<script> 以选项中指定的script来处理输入的文本文件
- -f<script> 以选项中指定的script文件来处理输入的文本文件
- -n / -silent / -queit 仅显示script处理后的结果
动作说明:
- a 新增,a后面可接字符串,这些字符串会在指定的行之后
- c 取代,c后面可接字符串,可指定取代的行
- d 删除
- i 插入,a后面可接字符串,这些字符串会在指定的行之前
- p 打印,将某个选择的数据输出
- s 取代,可配合正则表达式使用
新建文件testfile:
This is test para 1
This is test para 2
This is test para 3
This is test para 4
This is test para 5
This is test para 6
注意: 动作必须使用单引号括起来
- 例如在某一行追加新行:(nl表示读取文件并显示行号)
nl testfile | sed -e '4a\thisisnewline testfile'
执行结果:
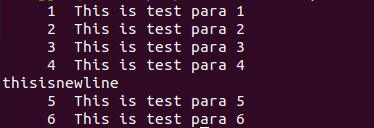
增加两行以上,需要通过\进行分隔开
nl testfile | sed '4a this is new line\this is another line'
- 例如在某一行前面插入行
nl testfile | sed -e '4i\thisisnewline testfile'
执行结果:
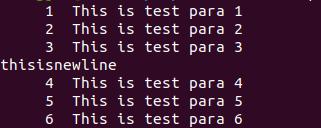
- 例如删除特定的行 (不写-e也可以)
nl testfile | sed '4d' 删除第四行
nl testfile | sed '2,4d' 删除2-4行
nl testfile | sed '3,$d' 删除第3行到最后一行
- 例如取代某行的内容
nl testfile | sed '2,4c\This is replace content'
执行结果:

- 例如仅显示特定范围内的行
nl testfile | sed -n '2,4p' -n 仅显示script处理后的结果
执行结果:

17. awk命令
awk命令是Linux下一个强大的文本处理工具;Linux中有三剑客之称,分别是awk, sed, grep;
- awk 处理文本
- sed 修改文本
- grep 过滤文本
awk的主要功能是用来格式化,它能把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。命令格式为:
awk '{pattern + action}' {filenames}
AWK除过使用命令行进行调用之外,还可以通过shell脚本的方式进行调用,可以将awk的命令写入一个文件,awk会解释执行文件中的命令;
awk [-F separator] 'commands' input-file
- -F 指定分隔符
- commands表示awk的命令
- input-file表示待处理的文件
awk有许多的内置变量:
- ARGC 命令行参数个数
- ARGV 命令行参数排列
- ENVIRON 支持队列中系统环境变量的使用
- FILENAME awk浏览的文件名
- FNR 浏览文件的记录数
- FS 设置输入域分隔符,等价于命令行 -F选项
- NF 浏览记录的域的个数
- NR 已读的记录数
- OFS 输出域分隔符
- ORS 输出记录分隔符
- RS 控制记录分隔符
此外,$0表示整条记录的所有域,$1表示当前行的第一个域,$2表示第二个域,以此类推;
#awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
统计/etc/passwd文件内文件名,行数,列数,记录的内容等信息。
例如创建新的文件,内容如下所示:
name:occupation:age:lover
zhangsan:student:22:football
lisi:doctor:34:fishing
wangwu:driver:45:running
Ggpog:renter:55:balling
执行命令:
# 删除第一行内容 sed '1d'
# 输出文件名 FILENAME
# 输出行号 NR
# 输出列数 NF
# 输出行内容 $0
cat footh.txt | sed '1d' | awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:" $0}'
输出结果:

执行命令:
# 输出第一列的内容
cat footh.txt | sed '1d' | awk -F ':' '{print $1}'
输出结果:

awk中的print和printf:
awk中提供了print和printf两种输出函数,其中print函数的参数可以是变量,数值,或者字符串,字符串必须使用双引号进行引用,参数使用逗号进行分隔,可参考上述awk命令中print的用法;
printf命令的用法与C语言中的用法类似,可进行更复杂的格式化输出;
awk编程:
awk中可自定义变量,也可以编写条件语句,循环语句,定义数组等功能;具体这些高级功能可参考文章《linux awk命令》.
18. grep命令
grep (Global Regular Expression)是Linux系统中的一个命令行小工具,用于从文件中搜索文本或者字符串。当使用指定字符串运行grep命令时,如果匹配,将显示包含该字符串所在的行,而不会对文件内容进行修改;
命令格式:
grep <options> <search string> <file-name>
常用选项:
- -i 表示忽略大小写进行匹配
- -v 表示反向查找,查找不包含search string的内容
- -n 显示匹配的行号
- -r 递归查找子目录中的文件
- -l 打印包含匹配内容的文件名
- -c 只打印匹配的行数(仅显示行数,-n显示行数和匹配内容)
- -e 可匹配多个模式,即多个search string
- -f 从文件中加载匹配模式进行匹配
例如创建新的文件,内容如下所示:
name:occupation:age:lover
zhangsan:student:22:football
lisi:doctor:34:fishing
wangwu:driver:45:running
Ggpog:renter:55:balling
执行命令:
grep -n lisi ./footh.txt
输出结果:

多文件搜索:
grep -l lisi ./footh.txt ./test1.txt ./test2.txt
以特殊符号开头或者结尾的字符(^,$正则表达式)
grep -n ^lisi ./footh.txt
查找文件中所有空行的行号:
grep -n ^$ ./footh.txt
通过参数-e 匹配多个模式:
grep -n -e ^zhang -e ^wan ./footh.txt
# 也可以等价为
grep -n -E "zhang|mail" ./footh.txt
输出结果:

19. pstack命令
在Linux系统中可以通过pstack命令查看一个进程的线程数量和每个线程的调用堆栈情况;
使用方法:
pstack pid
注:使用pstack命令查看的程序必须有调试符号;
pstack命令是一个shell脚本,用于打印正在运行的进程的栈跟踪信息;这个命令在排查进程的问题时非常有用,例如发现一个进程一直处于假死状态(似死循环),则可以在一段时间内,多次执行pstack命令,若发现代码堆栈总是停在同一个位置,则这个位置就需要重点关注;
可利用pstack命令查看线程CPU占用率过高的问题:
- 首先使用top命令查看CPU占用率过高的进程ID
- 可使用top -H 命令(线程模式),能够看到每个进程的各个线程的的CPU占用率,线程运行状态,线程id; (top -H输出的PID列,此时表示线程id)
- 找到进程中CPU占用率比较高的线程id
- 利用
pstack 进程ID,可以列出进程中所有线程的堆栈信息(包含线程ID),结合步骤3中CPU占用率较高的线程ID,以及源代码,即可分析出进程中线程的哪部分代码段导致CPU占用率较高。
20. iconv命令
iconv命令主要用于实现文件编码的转换;将Windows上的文件传输到Linux上打开时,有时会出现乱码,这是由于不同平台的编码问题导致的。而iconv命令可以将指定文件的内容从一种编码转换到另一种编码;
在使用时,可使用file -i data.txt命令先查看文件的编码方式,再进行转换;
常用参数:
- -V 查看版本信息
- -l 查看支持的编码种类
- -f 指定输入文件的编码 (--from-code=CODE_NAME)
- -t 指定输出文件的编码(--to-code=CODE_NAME)
- -o 指定输出文件
- -c 忽略输出的非法字符
- -s silent模式,禁止警告信息,但是不禁止错误信息
- --usage 显示简单使用信息
# 将data.txt文件进行转码,存储到data.txt文件中
iconv -f GBK -t UTF-8 data.txt -o data.txt
# 可在查看文件时候已管道的方式直接进行转码
cat data.txt | iconv -f iso-8859-1 -t UTF-8 | more
21. more命令
more命令用来查看文件,如果文件的内容多余一页,则会将文件按页进行显示,方便预览;
常用参数:
- +n 从第n行开始显示
- Enter每次向下显示一行
- Space 每次向下显示一页
- B 回退一页
- = 显示当前行号
- :f 显示当前文件名以及当前行号
22. sysctl命令
sysctl是一个Linux内核参数调整工具,用于查看,修改系统内核参数。内核参数是操作系统内核的设置,控制着各种系统行为和性能特征。使用sysctl命令,可以列出当前系统上所有可用的内核参数,并且可以查看和修改这些参数的值。
sysctl net.ipv4.tcp_fin_timeout=30
上述命令可以将TCP连接的超时时间设置为30秒。
常用参数:
- -w 临时改变某个参数的值(非永久生效)
sysctl -w net.ipv4.ip_forwar=1 - -a 展示所有的内核参数
- -p/-f 从指定参数读取系统内核参数
内核参数修改方法:
- 临时修改:修改/proc下的内核参数文件,此时不能使用编辑器来修改,因为/proc是一个虚拟文件系统,这些内核参数都是虚拟文件,且在系统运行过程中,内核可能随时会修改这些文件中的某些参数。只能通过echo命令将输出重定向到/proc目录下所选定的文件中。例如,将timeouts_timewait参数设置为30s,
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout。通过这种方式修改后,参数会立即生效,但是系统重启后,参数会恢复默认值。 - 永久修改:修改
/etc/sysctl.conf文件。例如,需要修改timeouts_timewait参数,可直接在文件中添加:net.ipv4.tcp_fin_timeout=30,保存文件即可。重启机器修改参数可生效,如果需要立即生效,则可以执行sysctl -p命令。
23. systemctl
systemctl是一个系统服务管理工具。可用于启动,停止,重启和管理系统服务。
systemctl start service_na # 启动服务
systemctl stop service_na # 停止服务
systemctl status service_na # 查看服务状态
systemctl restart service_na # 重启服务
systemctl enable service_na # 设置开机自启动
systemctl disable service_na # 关闭开机自启动
常用参数:
- -a 显式所有的服务 service --status-all
如果需要在系统配置自定义服务,可在/etc/systemd/system目录下新建服务配置文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号