tensorflow实战学习笔记(1)
tensorflow提供了三种不同的加速神经网路训练的并行计算模式
(一)数据并行:
(二)模型并行:
(三)流水线并行:
主流深度学习框架对比(2017):

第一章
Tensorflow实现Softmax Regression识别手写数字
这是深度学习领域一个非常简单的hello world式的项目:
数据集:28x28像素的手写数字组成。
1.在导入mnist 数据集时,会碰到一系列的问题,在这里做一些简要的说明:
(1)导入数据集时报错如下:(图是别地找的,但报错信息就是这样)

碰到这种情况,直接在官网上下载数据集,不用解压,将存放数据集的路径添加到数据读取函数中,就可以解决,具体见后面的代码:
(2)由于我之前用的是cpu版本的tensorflow,在做mnist实验时没有遇到这种情况,后来更换为gpu版本的时,在读取数据时会报错, 具体信息是:SymbolDatabase has no attribute RegisterServiceDescriptor(图是别地找的,但报错信息就是这样)

百度了一下发现解决的方案很少,也没有提供有价值的信息, 最后在github上这里找到了一些信息。看大家的讨论大致意思是由于protobuf版本的问题,打开pycharm的interpreter:

有一个3.2.0版本的protobuf.
可是当我在anaconda prompt下输入pip list时,发现这样的信息:

怎么会同时从在两个版本的protobuf,我好想知道为什么了
把这两个protobuf 都卸载掉, 重新pip install protobuf. 这次安装的时最新3.6版本

问题解决了。
继续我的mnist手写字体识别。。。。。。。。用一个没有隐含层的神经网络实现mnist手写字体识别。
重点:理解softmax regression
在处理多分类问题时,通常需要使用softmax regression模型,它的工作原理是:将可以判断为某类的特征相加,
然后将这写特征转换为判定是这一类的概率。具体的原理及数学推导可参考这篇博客。
2.理解交叉熵损失函数:
cross-entropy的定义如下:
其中y是预测的概率分布,y'是真实的概率分布(即Label的one-hot编码),通常可以用它来描述模型对真实概率分布估计的准确程度。
现在有了损失函数定义,现在再定义一个优化算法,就可以对模型进行训练:
常见的优化算法有随机梯度下降。
完整代码:
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist_data_path = r'E:\code\112\tensorflow_project\chapter5\data\tensorflow_data' mnist = input_data.read_data_sets(mnist_data_path, one_hot=True) input_nodes = 28 * 28 out_nodes = 10 x = tf.placeholder(dtype=tf.float32, shape=[None, input_nodes], name='x-input') y_ = tf.placeholder(dtype=tf.float32, shape=[None, out_nodes], name='y-input') # 定义权重矩阵 w = tf.Variable(initial_value=tf.random_normal(shape=[input_nodes, out_nodes], mean=0, stddev=0.1), dtype=tf.float32, trainable=True) b = tf.Variable(initial_value=tf.zeros([10]), dtype=tf.float32, trainable=True) output = tf.matmul(x, w) + b y = tf.nn.softmax(output) # 定义一个loss function来描述模型对分类问题的分类精度 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y))) train_step = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(cross_entropy) correction_prediction = tf.equal(tf.argmax(y, axis=1), tf.argmax(y_, axis=1)) accuracy = tf.reduce_mean(tf.cast(correction_prediction, tf.float32)) with tf.Session() as sess: init_op = tf.initialize_all_variables() sess.run(init_op) for i in range(1000): # 每次训练都从数据集中随机抽取一百个数据,构成一个mini-batch,对神经网络进行训练 # 使用一小部分样本进行训练称为随机梯度下降(SGD),如果每次训练都使用全部样本,计算量大,而且也不容易跳出局部最优。 # 使用随机梯度下降可以得到更快的收敛速度 batch_x, batch_y = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_x, y_: batch_y}) # print(i) if i % 10 == 0: accuracy_result = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}) print('After {} iterations the accuracy is {} .'.format(i, accuracy_result))
运行结果:
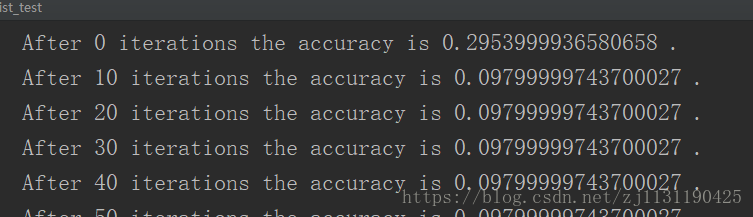
通过上面的例子,实现了一个非常简单的softmax regression算法
下面对之前的程序进行一些改进:对神经网络添加隐藏层, 隐藏层的节点数为500,同时对神经网络参数的更新采用滑动均值模型,采用指数衰减的学习率。
(1)关于滑动均值模型:在网络的训练中采用滑动均值模型,在测试中不使用。滑动均值模型与一阶滞后滤波具有相似性,一阶滞后滤波具体表达式为:
a的取值范围为[0, 1].
本次滤波结果=(1-a)本次采样值+a上次滤波结果,
采用此算法的优点是:
1、降低周期性的干扰;
2、在波动频率较高的场合有很好的效果。
在TensorFlow中提供了tf.train.ExponentialMovingAverage 来实现滑动平均模型,在采用随机梯度下降算法训练神经网络时,使用其可以提高模型在测试数据上的鲁棒性(robustness)。TensorFlow下的 tf.train.ExponentialMovingAverage 需要提供一个衰减率参数decay。该衰减率用于控制模型更新的速度。ExponentialMovingAverage 对每一个待更新的变量(variable)都会维护一个影子变量(shadow variable)。影子变量的初始值就是这个变量的初始值:
上述公式与之前介绍的一阶滞后滤波法的公式相比较,会发现有很多相似的地方,从名字上面也可以很好的理解这个算法的原理:平滑、滤波,即使数据平滑变化,通过调整参数来调整变化的稳定性。
在滑动平滑模型中, decay 决定了模型更新的速度,越大越趋于稳定。实际运用中,decay 一般会设置为十分接近 1 的常数(0.999或0.9999)。为了使得模型在训练的初始阶段更新得更快,ExponentialMovingAverage 还提供了 num_updates 参数来动态设置 decay 的大小:
关于滑动平均模型参考了这篇博客,作者表达的很清楚,引用一下
(2)在模型中添加正则化:通过正则化,能够将表征模型复杂度的指标加入到损失函数中。
regularizer_L2 = tf.contrib.layers.l2_regularizer(regularizer_rate)
loss_function = cross_entropy_mean + regularizer_L2(weight_1) + regularizer_L2(weight_2)
(3)指数衰减学习率:
在训练模型的时候,通常会遇到这种情况:我们平衡模型的训练速度和损失(loss)后选择了相对合适的学习率(learning rate),但是训练集的损失下降到一定的程度后就不在下降了,比如training loss一直在0.8和0.9之间来回震荡,不能进一步下降。如下图所示:

遇到这种情况通常可以通过适当降低学习率(learning rate)来实现。但是,降低学习率又会延长训练所需的时间。
学习率衰减(learning rate decay)就是一种可以平衡这两者之间矛盾的解决方案。学习率衰减的基本思想是:学习率随着训练的进行逐渐衰减。
学习率衰减基本有两种实现方法:
- 线性衰减。例如:每过5个epochs学习率减半
- 指数衰减。例如:每过5个epochs将学习率乘以0.1
我采用的是指数衰减的方法:
采用指数衰减必须初始化一个初始的学习率,以及一个衰减的速率。
learning_rate_raw = 0.8 # 初始的学习率 learning_rate_decay = 0.99 # 学习率的衰减率
计算的公式为:
decayed_learning_rate = learning_rate * decay_rate^(global_step/decay_steps)
其中:
- decayed_learning_rate: 优化后的每一轮的学习效率。
- learning_rate: 最初设置的学习效率。
- decay_rate: 衰减系数。
- decay_steps: 衰减速度。
同时将神经网络的前向传播过程结构化:通过inference函数来表示
# 计算神经网络的前向传播结果, 改用tf.variable_scope() 管理变量 def inference_update(input_tensor, reuse=False): with tf.variable_scope('layer1', reuse=reuse): # 在第一次构建网络时需要创建变量 weight_1 = tf.get_variable(name='weight_1', dtype=tf.float32, initializer=tf.random_normal(shape=[input_nodes, output_nodes], mean=0, stddev=1), trainable=True) bias_1 = tf.get_variable(name='bias_1', dtype=tf.float32, initializer=tf.constant(value=0.01, shape=[layer1_nodes])) layer_1 = tf.nn.relu(tf.matmul(input_tensor, weight_1) + bias_1) # 定义第二层的神经网络变量和参数 with tf.variable_scope('layer2', reuse=reuse): weight_2 = tf.get_variable(name='weight_2', initializer=tf.random_normal(shape=[layer1_nodes, output_nodes], mean=0, stddev=1), dtype=tf.float32, trainable=True) bias_2 = tf.get_variable(name='bias_2', initializer=tf.constant(0.01, shape=[output_nodes]), dtype=tf.float32) layer_2 = tf.matmul(layer_1, weight_2) + bias_2 return layer_2
再通过定义train()函数来训练神经网络:
def train(mnist): # 定义数据输入位置 x = tf.placeholder(dtype=tf.float32, shape=[None, input_nodes], name='x-input') y_ = tf.placeholder(dtype=tf.float32, shape=[None, output_nodes], name='y-input') # 生成隐藏层参数 weight_1 = tf.Variable(tf.random_normal(shape=[input_nodes, layer1_nodes], mean=0, stddev=0.1), dtype=tf.float32, name='weight1', trainable=True) weight_2 = tf.Variable(tf.random_normal(shape=[layer1_nodes, output_nodes], mean=0, stddev=0.1), dtype=tf.float32, name='weight2', trainable=True) bias_1 = tf.Variable(tf.constant(value=0.1, shape=[layer1_nodes])) bias_2 = tf.Variable(tf.constant(value=0.1, shape=[output_nodes])) # 计算在当前条件下神经网络的前向传播结果, 没有对参数使用滑动平均 y = inference(input_tensor=x, avg_class=None, weight_1=weight_1, bias_1=bias_1, weight_2=weight_2, bias_2=bias_2) # 计算在当前条件下神经网络的前向传播结果, 对参数使用了滑动平均 # 定义存储训练轮数的变量 trainable=False global_step = tf.Variable(initial_value=0, trainable=False) # 初始滑动平均类, 给定的参数为滑动平均衰减率和训练轮数 """ 关于滑动平均模型: 实际的原理是对参数的更新进行一阶之后滤波 对每一个参数会维护一个影子变量shadow_variable shadow_variable = shadow_variable * decay + (1 - decay) * variable decay 决定了模型的更心速度 num_updates参数来动态设置参数的大小 decay = min{decay, (1+num_updates)/(10+num_up_dates)} """ variable_average = tf.train.ExponentialMovingAverage(decay=moving_average_decay, num_updates=global_step) # 在所有神经网络参数使用滑动平均模型 variable_averages_op = variable_average.apply(tf.trainable_variables()) # 对所有的train_able=True的参数使用滑动平均模型 average_y = inference(input_tensor=x, avg_class=variable_average, weight_1=weight_1, bias_1=bias_1, weight_2=weight_2, bias_2=bias_2) # 用交叉熵作为损失函数 sparse_softmax_cross_entropy_with_logits()函数加速交叉熵的计算 当分类问题中只有一个正确结果, # 使用该函数可以加速计算 # 参数: logits=y, labels=tf.arg_max(y_, 1) 用预测的结果去表达正确的标签 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.arg_max(y_, 1)) # 找到y_每一行的最大值,即正确的值 cross_entropy_mean = tf.reduce_mean(cross_entropy) # 计算L2正则化损失函数 # 将模型复杂度加入到Loss_function中 regularizer_L2 = tf.contrib.layers.l2_regularizer(regularizer_rate) loss_function = cross_entropy_mean + regularizer_L2(weight_1) + regularizer_L2(weight_2) # 设置指数衰减的学习率 learning_rate_adjust = tf.train.exponential_decay(learning_rate=learning_rate, global_step=global_step, decay_steps=mnist.train.num_examples/batch_size, decay_rate=learning_rate_decay) """ pass """ train_step = tf.train.GradientDescentOptimizer(learning_rate=learning_rate_adjust).minimize(loss_function, global_step=global_step) # 在minize()函数中传入global_step,global_step 将自动更新 train_op = tf.group(train_step, variable_averages_op) # 每过一遍数据, 都要执行这两步, 所以用tf.group()将他们封装到一块 correct_prediction = tf.equal(tf.arg_max(average_y, dimension=1), tf.arg_max(y_, 1)) # 判断两个张量是否相等 accurancy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # cast将Bool型的数据转换为实数 with tf.Session() as sess: sess.run(tf.initialize_all_variables()) validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels} test_feed = {x: mnist.test.images, y_: mnist.test.labels} # 训练模型 # 迭代的训练神经网络 for i_count in range(train_steps): xs, ys = mnist.train.next_batch(batch_size) sess.run(train_op, feed_dict={x: xs, y_: ys}) # 训练 if i_count % 500 == 0: validate_acc = sess.run(accurancy, feed_dict=validate_feed) print("After {} step(s) training the model accurancy is {}".format(i_count, validate_acc)) # 训练结束后测试数据上的精度 test_acc = sess.run(accurancy, feed_dict=test_feed) print("After {} steps the model accuracy is {}".format(train_steps, test_acc
# encoding: utf-8 import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data batch_size = 100 input_nodes = 784 # 输入节点的个数 output_nodes = 10 # 输出节点的个数 layer1_nodes = 500 # 隐藏层的节点数 learning_rate = 0.1 # 学习率 learning_rate_decay = 0.99 # 学习率的衰减 regularizer_rate = 0.0001 # 正则化 train_steps = 30000 # 训练轮数 moving_average_decay = 0.99 # 滑动平均衰减率 # 计算神经网络的前向传播结果 def inference(input_tensor, avg_class, weight_1, bias_1, weight_2, bias_2): if avg_class is None: # 没有滑动平均模型 layer_1 = tf.nn.relu(tf.matmul(input_tensor, weight_1) + bias_1) # 计算输出层的前向传播结果 return tf.matmul(layer_1, weight_2) + bias_2 else: layer_1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weight_1)) + avg_class.average(bias_1)) return tf.matmul(layer_1, avg_class.average(weight_2)) + avg_class.average(bias_2) # 计算神经网络的前向传播结果, 改用tf.variable_scope() 管理变量 def inference_update(input_tensor, reuse=False): with tf.variable_scope('layer1', reuse=reuse): # 在第一次构建网络时需要创建变量 weight_1 = tf.get_variable(name='weight_1', dtype=tf.float32, initializer=tf.random_normal(shape=[input_nodes, output_nodes], mean=0, stddev=1), trainable=True) bias_1 = tf.get_variable(name='bias_1', dtype=tf.float32, initializer=tf.constant(value=0.01, shape=[layer1_nodes])) layer_1 = tf.nn.relu(tf.matmul(input_tensor, weight_1) + bias_1) # 定义第二层的神经网络变量和参数 with tf.variable_scope('layer2', reuse=reuse): weight_2 = tf.get_variable(name='weight_2', initializer=tf.random_normal(shape=[layer1_nodes, output_nodes], mean=0, stddev=1), dtype=tf.float32, trainable=True) bias_2 = tf.get_variable(name='bias_2', initializer=tf.constant(0.01, shape=[output_nodes]), dtype=tf.float32) layer_2 = tf.matmul(layer_1, weight_2) + bias_2 return layer_2 def train(mnist): # 定义数据输入位置 x = tf.placeholder(dtype=tf.float32, shape=[None, input_nodes], name='x-input') y_ = tf.placeholder(dtype=tf.float32, shape=[None, output_nodes], name='y-input') # 生成隐藏层参数 weight_1 = tf.Variable(tf.random_normal(shape=[input_nodes, layer1_nodes], mean=0, stddev=0.1), dtype=tf.float32, name='weight1', trainable=True) weight_2 = tf.Variable(tf.random_normal(shape=[layer1_nodes, output_nodes], mean=0, stddev=0.1), dtype=tf.float32, name='weight2', trainable=True) bias_1 = tf.Variable(tf.constant(value=0.1, shape=[layer1_nodes]), trainable=True) bias_2 = tf.Variable(tf.constant(value=0.1, shape=[output_nodes]), trainable=True) # 计算在当前条件下神经网络的前向传播结果, 没有对参数使用滑动平均 y = inference(input_tensor=x, avg_class=None, weight_1=weight_1, bias_1=bias_1, weight_2=weight_2, bias_2=bias_2) # 计算在当前条件下神经网络的前向传播结果, 对参数使用了滑动平均 # 定义存储训练轮数的变量 trainable=False global_step = tf.Variable(initial_value=0, trainable=False) # 初始滑动平均类, 给定的参数为滑动平均衰减率和训练轮数 """ 关于滑动平均模型: 实际的原理是对参数的更新进行一阶之后滤波 对每一个参数会维护一个影子变量shadow_variable shadow_variable = shadow_variable * decay + (1 - decay) * variable decay 决定了模型的更心速度 num_updates参数来动态设置参数的大小 decay = min{decay, (1+num_updates)/(10+num_up_dates)} """ variable_average = tf.train.ExponentialMovingAverage(decay=moving_average_decay, num_updates=global_step) # 在所有神经网络参数使用滑动平均模型 variable_averages_op = variable_average.apply(tf.trainable_variables()) # 对所有的train_able=True的参数使用滑动平均模型 average_y = inference(input_tensor=x, avg_class=variable_average, weight_1=weight_1, bias_1=bias_1, weight_2=weight_2, bias_2=bias_2) # 用交叉熵作为损失函数 sparse_softmax_cross_entropy_with_logits()函数加速交叉熵的计算 当分类问题中只有一个正确结果, # 使用该函数可以加速计算 # 参数: logits=y, labels=tf.arg_max(y_, 1) 用预测的结果去表达正确的标签 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.arg_max(y_, 1)) # 找到y_每一行的最大值,即正确的值 cross_entropy_mean = tf.reduce_mean(cross_entropy) # 计算L2正则化损失函数 # 将模型复杂度加入到Loss_function中 regularizer_L2 = tf.contrib.layers.l2_regularizer(regularizer_rate) loss_function = cross_entropy_mean + regularizer_L2(weight_1) + regularizer_L2(weight_2) # 设置指数衰减的学习率 learning_rate_adjust = tf.train.exponential_decay(learning_rate=learning_rate, global_step=global_step, decay_steps=mnist.train.num_examples/batch_size, decay_rate=learning_rate_decay) """ pass """ train_step = tf.train.GradientDescentOptimizer(learning_rate=learning_rate_adjust).minimize(loss_function, global_step=global_step) # 在minize()函数中传入global_step,global_step 将自动更新 train_op = tf.group(train_step, variable_averages_op) # 每过一遍数据, 都要执行这两步, 所以用tf.group()将他们封装到一块 correct_prediction = tf.equal(tf.arg_max(average_y, dimension=1), tf.arg_max(y_, 1)) # 判断两个张量是否相等 accurancy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # cast将Bool型的数据转换为实数 with tf.Session() as sess: sess.run(tf.initialize_all_variables()) validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels} test_feed = {x: mnist.test.images, y_: mnist.test.labels} # 训练模型 # 迭代的训练神经网络 for i_count in range(train_steps): xs, ys = mnist.train.next_batch(batch_size) sess.run(train_op, feed_dict={x: xs, y_: ys}) # 训练 if i_count % 500 == 0: validate_acc = sess.run(accurancy, feed_dict=validate_feed) print("After {} step(s) training the model accurancy is {}".format(i_count, validate_acc)) # 训练结束后测试数据上的精度 test_acc = sess.run(accurancy, feed_dict=test_feed) print("After {} steps the model accuracy is {}".format(train_steps, test_acc)) # 定义主程序入口 def main(argv=None): data_path = r'E:\code\112\tensorflow_project\chapter5\data\tensorflow_data' mnist = input_data.read_data_sets(data_path, one_hot=True) train(mnist) if __name__ == "__main__": tf.app.run()
程序的运行结果如下所示:

后面持续更行,会添加模型保存以及调用tensorboard的部分程序。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号