

python爬虫基础(1)
需要了解http基本原理,网页基础知识,爬虫原理, Cookies的原理
1. URI和URL
URI: Uniform Resource Indentifier 统一资源标识符
URL: Uniform Resource Locatior
URI包括:URL和URN(统一资源名称,只负责命名)
2. 超文本
网页的源代码html就可以称为超文本,其包含很多的标签,如图片img, 段落p,这些标签经过浏览器解析后,就呈现为我们所看到的网页。
URL中http/htps就是访问资源需要的协议类型,能够保证超文本高效准确的传输到本地浏览器。
HTTP,HyperText Transfer Protocol
HTTPS HyperText Transfer Protocol over Secure Socket Layer, 相当于http的安全版
3. HTTP请求
Get: get请求的参数会包含在url里面,数据可以在url中看到,而post请求中的url不会包含这些数据和信息。get请求提交的数据最多只有1024字节
Post: 表单提交时发起的请求, 如登录过程中, 数据都是通过表单的形式传输,会包含在请求体中,上传文件时,由于内容比较大,也采用post请求
4 .请求头
用来说明服务器需要使用的附加信息,比如Cookie, Referer, User-Agent
Cookies: 这是网站为了辨别用户会话进行跟踪而存储在用户本地的数据,它的主要共功能是维持当前访问会话,我们输入用户名和密码成功登陆某个网站后,服务器会用会话保存登录状态,后面每次刷新或者请求该站点的其他页面时,会发现都是登陆状态,这就是Cookies的作用。cookies里面的信息表示了我们所对应的服务器的会话,每次浏览器在请求该站点时,都会请求头中加上cookies并将其发送给服务器,服务器通过cookies识别出是我们自己,并查出当前是登录状态,所以返回结果就是登录之后才能看到的网页内容。
user-agent: 是一个特殊的字符串头,里面包含客户使用的操作系统的版本,浏览器的版本等信息,做爬虫时加上此信息,可以模拟浏览器。如果不加,可能会被识别出为爬虫。
5.请求体
请求体一般承载post请求中的数据表单,而对于get请求,请求体为空。
| Content-type | 提交数据的方式 |
| application/x-www-form-urlencoded | 表单数据 |
| multipart/form-data | 表单文件上传 |
| application/json | 序列化json |
| text/xml | xml数据 |
在爬虫中,如果需要构造post请求,需要使用正确的content-type,否则可能导致post提交后无法正常响应。
6.响应
服务器返回给客户端的信息。由三部分组成:
1. 响应状态吗(Response status code)。
200服务器响应正常
500服务器内部错误
404
2. 响应头(Response Header)
包含服务器对请求的应答信息,如
date: 响应产生的时间
content-type, 文档类型,指定返回的数据类型
Server, 服务器信息
Set-Cookies 设置cookie,响应头中的set-cookies告诉浏览器需要将此内容放在cookies中,下次请求携带cookies
3. 响应体(Response body)
响应的正文数据
6. 网页基础
组成部分:
(1)HTML 超文本标记语言, 定义网页的内容和结构
(2)CSS cascading style sheet 层叠样式表, 描述网页的布局
(3)JavaScript 定义网页行为,使用户和网页交互
7. 爬虫的基本原理
1.获取网页
首先构造请求,向网站服务器发送请求,返回的响应体就是网页源代码, python 中urllib,request等库
2.提取信息
分析第一步得到的网页源代码,提取需要的数据。 Beautiful soup, pyquery, lxml
3.保存数据
数据可以保存在:txt, json, excel文件
数据库:sql, mongodb数据库
8.Javascript渲染页面
有时候用urllib和request抓取页面,得到的HTML和在浏览器上看到的不一样,越来越多的网页采用Ajax,模块化前端工具来构建,整个页面由javascript渲染出来,我们抓取到的HTML代码只是一个空壳。可以采用分析Ajax接口,也可以使用selenium,splash这样的库来实现模拟JavaScript渲染
9.会话,cookies
需要登陆才能访问的网页,涉及到会话(session)和cookie
静态网页:
动态网页:动态解析URL中参数的变化,关联数据库并呈现不同的内容
会话, cookie是为了保持http状态而采用的技术,会话在服务器端,用来保存用户的会话信息,cookie在客户端(浏览器端),当浏览器向服务器发送请求时,会附带上浏览器的cookie信息,作为登陆的凭证。
会话维持:当客户端第一次请求服务器时,服务器返回一个请求头中带有set-cookie字段的响应给客户端,用来标记是哪一个客户,浏览器会把cookie保存起来,在下一次请求时,浏览器把cookie信息添加到请求头中提交给服务器,cookie携带了会话ID信息。服务器检查cookie即可找到对应的会话,再判断会话来以此辨认用户状态
打开cookies:具体内容如下
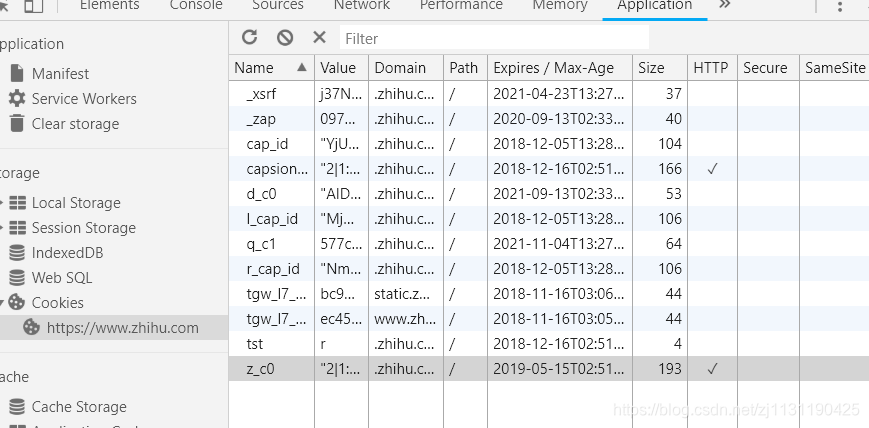
10. 代理的基本原理
代理指的是代理服务器,代理服务器相当于在客户端和用户之间搭建一个桥梁,客户端和服务器之间的信息传递都要经过代理。
通常爬虫在单位时间内重复访问一个网站的次数太多的话,可能会被网站识别到是爬虫,会将我们的ip封了。
采用代理可以隐藏我们的真实IP
