skip-gram模型介绍及代码
在自然语言处理中,首先要把文本转化为数据的形式,更确切地说,是把词转化为向量的形式,才可以用计算机通过各种算法处理自然语言问题。在词向量的表示方法中,One-hot编码是一个非常经典的表示方法,但是在这种编码方法中,词向量的维度等于词的总个数,且词向量中只有一个位置数为1,其他位置全为0,这就导致了词表构成的矩阵是一个稀疏矩阵,它会消耗相当大的计算资源。
word2vector模型是自然语言处理技术中的新方法,它通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。embedding其实就是一个映射,将单词从原先所属的空间映射到新的低维空间中,这样就解决了向量稀疏问题。
word2vector主要有Skip-Gram和CBOW两种模型。
Skip-Gram模型分为两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。首先基于训练数据构建一个神经网络,当这个模型训练好以后,并不会用这个训练好的模型处理新的任务,真正需要的是这个模型通过训练数据所学得的参数,即隐层的权重矩阵,这些权重在word2vector中实际上就是需要的“word vectors”。
Skip-Gram模型的基础形式如下图所示:(下面的部分均翻译自原文献,水平有限)
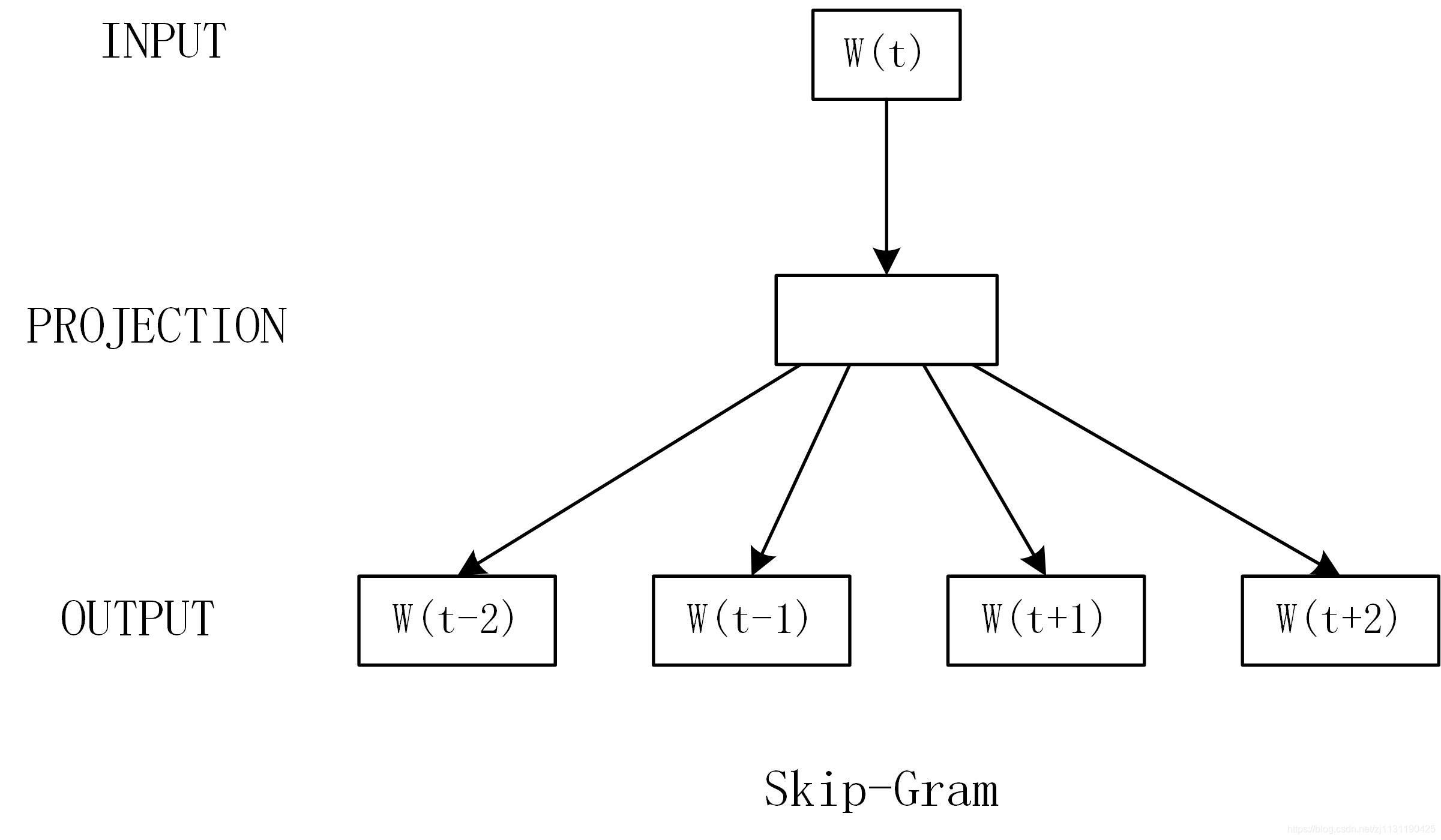
从上图可知,Skip-Gram是根据当前的词来预测上下文的词。

对softmax的改进:
上述的softmax函数并不实用,因为![]() 的计算成本与词汇表的大小成正比。
的计算成本与词汇表的大小成正比。
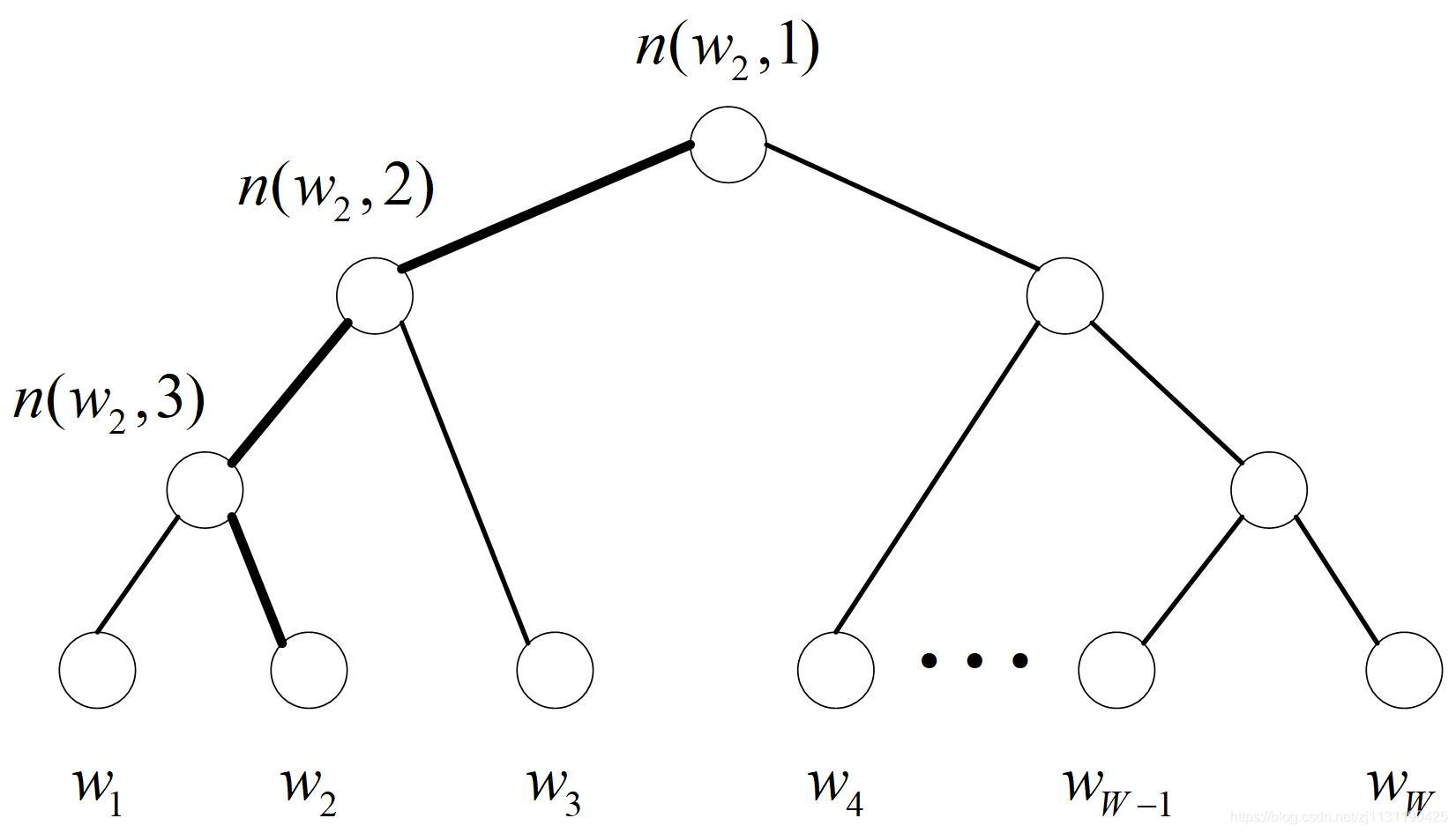
为了避免要计算所有词的softmax概率,word2vec采用了霍夫曼树来代替从隐藏层到输出softmax层的映射。和之前的神经网络语言模型相比,霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的。(ps: 这段是翻译自原论文,本人英文水平实在有限)


skip-gram训练词向量代码:
# coding=utf-8
import jieba
import numpy as np
import tensorflow as tf
from tqdm import tqdm
from pprint import pprint
obj_path = r'E:\back_up\NLP\process_train.txt'
stop_word_file = r"E:\back_up\NLP\pro1\data\stop_word.txt"
def get_stop_word(stop_word_file):
"""
加载停用词
:param stop_word_file:
:return:
"""
stopwords = [x.strip() for x in open(stop_word_file, 'r', encoding='utf-8').readlines()]
return stopwords + list("0123456789") + [r'\n', '\n']
def get_data(file_path, windows_len, lines_number):
"""
:param file_path: 数据的路径
:param windows_len: 窗口长度
:return:
"""
words = set() # 保存词
sentences = [] # 保存句子
stopwords = get_stop_word(stop_word_file)
stopwords = set(stopwords)
count = 0
with open(file_path, 'r', encoding='utf-8') as fp:
while True:
line = fp.readline()
count = count + 1
if not line or count > lines_number:
break
# print(line)
out_str = []
result = jieba.cut(line, cut_all=False) # 精确模式
for c in result:
if c not in stopwords and len(c) > 1:
out_str.append(c)
words.add(c) # 保存所有的词
else:
continue
out_str.append("EOS")
sentences.append(out_str)
word2id = {}
words = list(words)
for i in range(len(words)):
word2id[words[i]] = i + 1
word2id["EOS"] = len(words) + 1
# 构造输入input和输出labels
input = []
labels = []
# 构造训练数据和标签
for sentence in sentences:
for word_index in range(len(sentence)):
start = max(0, word_index - windows_len)
end = min(word_index + windows_len + 1, len(sentence))
for index in range(start, end):
if index == word_index:
continue
else:
input_word_id = word2id.get(sentence[word_index], None)
label_word_id = word2id.get(sentence[index], None)
if input_word_id is None or label_word_id is None:
continue
input.append(int(input_word_id))
labels.append(int(label_word_id))
return words, word2id, sentences, input, labels, len(words)
class TrainData:
def __init__(self, inputs, labels, words, vocab_size, batch_size):
"""
:param inputs: 输入
:param labels: 输出
:param words: 所有单词
:param vocab_size:
"""
self.inputs = inputs
self.labels = labels
self.words = words
self.vocab_size = vocab_size
self.batch_size = batch_size
self.input_length = len(inputs)
def get_batch_data(self, batch_count):
"""
:param batch_count: batch计数
:return:
"""
# 确定选取的batch大小
start_position = batch_count * self.batch_size
end_position = min((batch_count + 1) * self.batch_size, self.input_length)
batch_input = self.inputs[start_position: end_position]
batch_labels = self.labels[start_position: end_position]
batch_input = np.array(batch_input, dtype=np.int32)
batch_labels = np.array(batch_labels, dtype=np.int32)
batch_labels = np.reshape(batch_labels, [len(batch_labels), 1]) # 转置
return batch_input, batch_labels
def get_batch_nums(self):
"""
获取数据的batch数
:return:
"""
return self.input_length // self.batch_size + 1
class Model:
def __init__(self, vocab_size, embedding_size, batch_nums, num_sampled, learning_rate):
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.batch_nums = batch_nums
self.num_sampled = num_sampled
self.lr = learning_rate
self.batch_size = None
# self.graph = tf.Graph()
# 创建placeholder
with tf.name_scope("placeholders"):
self.inputs = tf.placeholder(dtype=tf.int32, shape=[self.batch_size], name="train_inputs") # 输入
self.labels = tf.placeholder(dtype=tf.int32, shape=[self.batch_size, 1], name="train_labels")
self.test_word_id = tf.placeholder(dtype=tf.int32, shape=[None], name="test_word_id")
# 创建词向量
with tf.name_scope("word_embedding"):
self.embedding_dict = tf.get_variable(name="embedding_dict", shape=[self.vocab_size, self.embedding_size],
initializer=tf.random_uniform_initializer(-1, 1, seed=1)
)
self.nce_weight = tf.get_variable(name="nce_weight", shape=[self.vocab_size, self.embedding_size],
initializer=tf.random_uniform_initializer(-1, 1, seed=1)
)
self.nce_bias = tf.get_variable(name="nce_bias", initializer=tf.zeros([self.vocab_size]))
# 定义误差
with tf.name_scope("creating_embedding"):
embeded = tf.nn.embedding_lookup(self.embedding_dict, self.inputs)
self.embeded = tf.layers.dense(inputs=embeded, units=self.embedding_size, activation=tf.nn.relu) # 激活函数
# 定义误差
with tf.name_scope("creating_loss"):
self.loss = tf.reduce_mean(
tf.nn.nce_loss(weights=self.nce_weight,
biases=self.nce_bias,
labels=self.labels,
inputs=self.embeded,
num_sampled=self.num_sampled,
num_classes=self.vocab_size,
# remove_accidental_hits=True
)
)
# 定义测试函数
with tf.name_scope("evaluation"):
norm = tf.sqrt(tf.reduce_sum(tf.square(self.embedding_dict), 1, keepdims=True))
self.normed_embedding_dict = self.embedding_dict / norm
test_embed = tf.nn.embedding_lookup(self.normed_embedding_dict, self.test_word_id)
self.similarity = tf.matmul(test_embed, tf.transpose(self.normed_embedding_dict), name='similarity')
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(self.loss)
# tensorboard 显示数据
with tf.name_scope("summaries"):
tf.summary.scalar('loss', self.loss) # 在 tensorboard中显示信息
self.summary_op = tf.summary.merge_all()
def train(self, train_data, train_steps=1000):
with tf.Session() as sess:
# 初始化变量
sess.run(tf.group(tf.local_variables_initializer(), tf.global_variables_initializer()))
writer = tf.summary.FileWriter(r'E:\back_up\NLP\graph', sess.graph)
initial_step = 0 # self.global_step.eval(session=sess)
step = 0 # 记录总的训练次数
saver = tf.train.Saver(tf.global_variables(), max_to_keep=2) # 保存模型
for index in range(initial_step, train_steps):
total_loss = 0.0 # 总的loss
for batch_count in tqdm(range(self.batch_nums)):
batch_inputs, batch_labels = train_data.get_batch_data(batch_count)
feed_dict = {self.inputs: batch_inputs,
self.labels: batch_labels}
sess.run(self.optimizer, feed_dict=feed_dict)
batch_loss = sess.run(self.loss, feed_dict=feed_dict)
summary = sess.run(self.summary_op, feed_dict=feed_dict)
# batch_loss, summary = sess.run([self.loss, self.summary_op])
total_loss += batch_loss
step += 1
if step % 200 == 0:
saver.save(sess=sess, save_path=r'E:\back_up\NLP\global_variables\global_variables', global_step=step)
writer.add_summary(summary, global_step=step)
print('Train Loss at step {}: {:5.6f}'.format(index, total_loss/self.batch_nums))
word_embedding = sess.run(self.embedding_dict)
np.save(r"E:\back_up\NLP\word_embedding\word_embedding", word_embedding) # 保存词向量
def predict(test_word, word2id, top_k=4): # 测试训练的词向量
"""
:param test_word:
:param word2id:
:param top_k: 与testword最相近的k个词
:return:
"""
sess = tf.Session()
check_point_file = tf.train.latest_checkpoint(r'E:\back_up\NLP\global_variables') # 加载模型
saver = tf.train.import_meta_graph("{}.meta".format(check_point_file), clear_devices=True)
saver.restore(sess, check_point_file)
graph = sess.graph
graph_test_word_id = graph.get_operation_by_name("placeholders/test_word_id").outputs[0]
graph_similarity = graph.get_operation_by_name("evaluation/similarity").outputs[0]
test_word_id = [word2id.get(x) for x in test_word]
feed_dict = {graph_test_word_id: test_word_id}
similarity = sess.run(graph_similarity, feed_dict)
for index in range(len(test_word)):
nearest = (-similarity[index, :]).argsort()[0:top_k] # argsort()默认按照从小大的顺序 最接近的词
log_info = "Nearest to %s: " % test_word[index]
for k in range(top_k):
closest_word = [x for x, v in word2id.items() if v == nearest[k]]
log_info = '%s %s,' % (log_info, closest_word)
print(log_info)
if __name__ == "__main__":
batch_size = 40
window_len = 4
words, word2id, sentences, inputs, labels, vocab_size = get_data(obj_path, windows_len=window_len, lines_number=2000)
train_data = TrainData(inputs, labels, words, vocab_size, batch_size)
batch_nums = train_data.get_batch_nums()
# print(words)
print("vocab_size: ", vocab_size)
print("batch_nums", batch_nums)
model = Model(vocab_size=vocab_size, embedding_size=128, batch_nums=batch_nums, num_sampled=5, learning_rate=0.0001)
model.train(train_data=train_data, train_steps=150)
if __name__ == "__main__":
batch_size = 200
window_len = 4
words, word2id, sentences, inputs, labels, vocab_size = get_data(obj_path, windows_len=window_len,
lines_number=2000)
test_word = []
for count in range(50):
test_word.append(np.random.choice(words))
print(test_word)
predict(test_word, word2id)
这篇翻译的水,论文中很多东西还是没有理解,代码可用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号