

卷积神经网络CNN(Convolutional Neural Network)原理与代码实现 Le-Net5
图像识别经典数据集:
图像识别是人工智能的一个重要的领域。其他常用的图像识别数据集:
CIFAR: http://www.cs.toronto.edu/~kriz/cifar.html
CIFAR数据集分为CIFAR-10和CIFAR-100两个问题。
CIFAR-10数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。

数据集下载: http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
ImageNet数据集:
为了解决CIFAR数据集存在的问题:真实环境中的图像的分辨率远大于32X32, 且一张图像中不是只包含一种类别,所以便出现了ImageNet, ImageNet是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库。是美国斯坦福的计算机科学家李飞飞模拟人类的识别系统建立的。能够从图片识别物体。目前已经包含14197122张图像,是已知的最大的图像数据库。每年的ImageNet大赛更是魂萦梦牵着国内外各个名校和大型IT公司以及网络巨头的心。
卷积神经网络CNN:
Top-N正确率: 图像识别算法给出的前N个答案中有一个是正确答案的概率。
CNN的基本结构:
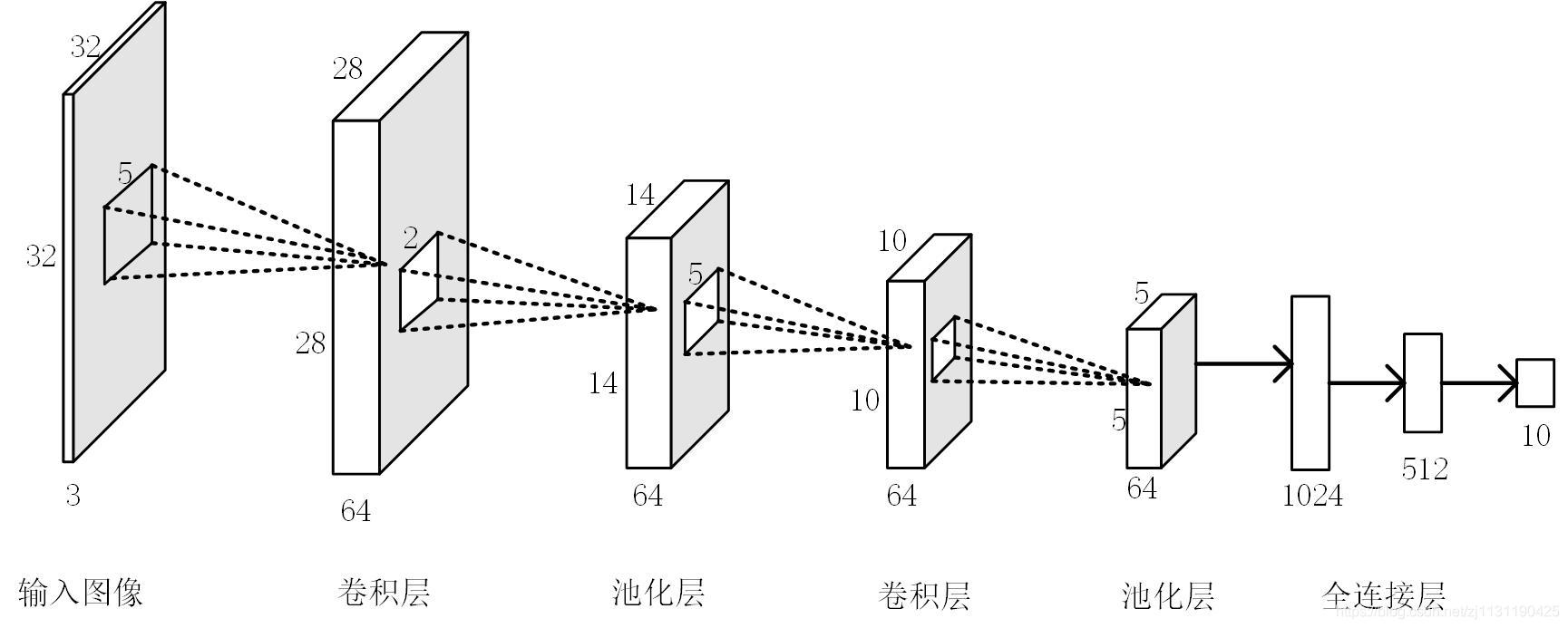
卷积神经网络构成部分:
1.输入层:
神经网络的输入,在处理图像时,一般代表图像的像素矩阵。大小通常为 w x h x 3或者w x h x 1的矩阵。
2.卷积层:
卷积层中每一个节点的输入只是上一层神经网络的的一小块。大小通常为3x3或者5x5.卷积层的作用是将图像中的每一小块进行更加深入地分析从而得到抽象程度更高的特征。经过卷积层处理的节点矩阵会变深。
卷积层中过滤器(filter)的结构:

过滤器的作用是将当前层神经网络上的子节点矩阵转化为下一层神经网络上的一个单位节点矩阵(长宽为1,深度不计)。
过滤器的参数: 长度,宽度,深度(处理得到的下一层节点矩阵的深度)。
在卷积层的前向传播过程中,下一层单矩阵中第i个节点的取值为:

卷积层的操作过程就是将上面的filter从当前层的左上角移动到右下角。在移动过程中计算每一个对应的单位矩阵。如下图所示:
(图片来源: https://www.jianshu.com/p/cbe93f5152cb)
可以采用zero-padding来填充当前层的矩阵,以保证卷积操作后矩阵的尺寸不变。同时,还可以设定filter的移动步长来调整结果矩阵的大小。
结果矩阵的大小:
a. 当使用zero-padding的时候:

b 当不使用zero-padding的时候:

卷积层filter的参数是共享的(包括偏置项),这样使得图像上的内容不受位置的影响(mnist中1出现在哪里都是属于同一类别);同时可以减少网络的参数。
tensorflow实现:
import tensorflow as tf # 定义一个过滤器 # [5,5,3,16] 尺寸为5x5, 当前层的深度3,filter的深度16 filter_1 = tf.get_variable(name='filter_1', shape=[5, 5, 3, 16], dtype=tf.float32, initializer=tf.random_normal(mean=0, stddev=1)) # 定义偏置项 biases_1 = tf.get_variable(name='biases_1', shape=[16], dtype=tf.float32, initializer=tf.random_normal(mean=0, stddev=1)) # 卷积层前向传播算法 # 参数 输入input 四维矩阵,第一个维度表示batch的大小,后面的维度表示输入层的维度 filter, # strides=[1,1,1,1] 第一和最后一个数字必须是1,其他两个是步长参数 # padding: SAME(zero-padding) VALID(no-padding) conv = tf.nn.conv2d(input=input, filter=filter_1, strides=[1, 1, 1, 1], padding='SAME') layer_1 = tf.nn.bias_add(conv, biases_1) activated_layer_1 = tf.nn.relu(layer_1)
3.池化层:
池化层不改变三维矩阵的升深度,但是会改变矩阵的大小。池化层操作可以看作是将一张图像处理成分辩率更低的图像,从而减少最后全连接层中的节点数,进一步减少神经网络参数的数目。
池化层的操作于卷积层的filter类似,但是池化层不是加权,而实采用最大值或者平均值, max-pool和average-pool,与卷积层的filter不同的是,池化层在长度,宽度和深度上移动。
# 最大池化层 参数 # value: 输入数据,四维矩阵 # ksize: 过滤器尺寸[1,3,3,1]第一个和最后一个参数必须为1 # strides参数与卷积层相同 # padding参数与卷积层相同 pool = tf.nn.max_pool(value=activated_layer_1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
4.全连接层:
在经过多层的卷积层和池化层操作后,一般会有1-2个全连接层,给出最后的分类结果。可以将卷积层和池化层看作自动提取图像特征的操作,经过操作会将图像信息含量更高的特侦提取出来。最后任然需要使用全连接层来完成分类任务。
5. softmax层:
将神经网络的输入转化为概率分布。
dropout:
一般只用在全连接层,将全连接层随机的部分节点的输出改为0,dropout可以避免过拟合,使得模型在测试数据上更加健壮
经典的卷积神经网络模型:
Le-Net5模型:于98年提出,第一个应用于图像识别问题的卷积神经网络
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import numpy as np from tqdm import tqdm class TrainData: def __init__(self, data_path, batch_size=100): """ :param data_path: 训练数据路径 """ self.batch_size = batch_size self.mnist = input_data.read_data_sets(train_dir=data_path, one_hot=True) def display_data_info(self): """ 输出数据集的信息 :return: """ print("-"*40) print("training data size: {}".format(self.mnist.train.num_examples)) print("test data size: {}".format(self.mnist.test.num_examples)) print("validation data size: {}".format(self.mnist.validation.num_examples)) print("-"*40) def next_batch(self): """ 获取下一个batch的数据 经过处理后的图片为(28x28=784)的一维数组 :return: """ xs, ys = self.mnist.train.next_batch(self.batch_size) # 返回训练数据和标签 xs: [batch_size, 784] return xs, ys def validation_data(self): """ 返回验证集 :return: """ images, labels = self.mnist.validation.images, self.mnist.validation.labels return images, labels def test_data(self): """ 返回测试集 :return: """ images, labels = self.mnist.test.images, self.mnist.test.labels return images, labels def get_batch_num(self): return self.mnist.train.num_examples // self.batch_size class Model: def __init__(self, input_image_size, output_node, learning_rate, train_data, board_data, model_save, train_step, regularize=False): self.input_image_size = input_image_size self.input_node = self.input_image_size[0] * self.input_image_size[1] * self.input_image_size[2] # 输入节点数量 self.output_node = output_node self.learning_rate = learning_rate self.train_data = train_data self.board_data = board_data self.model_save = model_save self.train_step = train_step self.regularize = regularize if self.regularize: self.regularize_rate = 0.01 # 卷积层1 self.conv1_deep = 32 self.conv1_size = 5 self.conv1_stride = 1 # 卷积层2 self.conv2_deep = 64 self.conv2_size = 3 self.conv2_stride = 1 # 池化层 self.pool1_size = 2 self.pool1_stride = 2 # 池化层 self.pool2_size = 2 self.pool2_stride = 2 # 全连接层 self.fc_size = 500 with tf.name_scope("placeholder"): self.x = tf.placeholder(dtype=tf.float32, shape=[None, self.input_image_size[0], self.input_image_size[1], self.input_image_size[2]], name='x-input') # 输入是一个四维矩阵 self.y_ = tf.placeholder(dtype=tf.float32, shape=[None, 10], name='y-input') # 标签 with tf.name_scope("layer1_conv1"): # 定义卷积层1权重 # 定义一个过滤器 # [5,5,3,16] 尺寸为5x5, 当前层的深度3,filter的深度32 # stride=1 # padding: SAME # 输出 28x28x32 self.conv1_weight = tf.get_variable(name='conv1_weight', shape=[self.conv1_size, self.conv1_size, self.input_image_size[2], self.conv1_deep], dtype=tf.float32, initializer=tf.truncated_normal_initializer(mean=0, stddev=0.5)) self.conv1_biases = tf.get_variable(name='conv1_biases', shape=[self.conv1_deep], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) self.conv1 = tf.nn.conv2d(input=self.x, filter=self.conv1_weight, strides=[1, self.conv1_stride, self.conv1_stride, 1], padding='SAME') # 这里的输出为28x28x32 self.layer1 = tf.nn.relu(tf.nn.bias_add(value=self.conv1, bias=self.conv1_biases)) with tf.name_scope("layer2_pool1"): # 定义池化层 # 定义一个过滤器 # [1, 2, 2, 1] 尺寸为2x2, 当前层的深度32 # stride = 2 # padding SAME # 输出 ceil(28/stride)=14 14x14x32 self.layer2 = tf.nn.max_pool(value=self.layer1, ksize=[1, self.pool1_size, self.pool1_size, 1], strides=[1, self.pool1_stride, self.pool1_stride, 1], padding='SAME') # 输出为14*14*32 celi(28/2)=14 with tf.name_scope("layer3_conv2"): # 定义一个过滤器 # [3, 3, 32, 64] 尺寸为5x5, 当前层的深度32 # stride = 1 # padding SAME # 输出 ceil(14/stride)=14 14x14x64 self.conv2_weight = tf.get_variable(name='conv2_weight', shape=[self.conv2_size, self.conv2_size, self.conv1_deep, self.conv2_deep], dtype=tf.float32, initializer=tf.truncated_normal_initializer(mean=0, stddev=0.4)) self.conv2_biases = tf.get_variable(name='conv2_biases', shape=[self.conv2_deep], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) self.conv2 = tf.nn.conv2d(input=self.layer2, filter=self.conv2_weight, strides=[1, self.conv2_stride, self.conv2_stride, 1], padding='SAME') self.layer3 = tf.nn.relu(tf.nn.bias_add(value=self.conv2, bias=self.conv2_biases)) with tf.name_scope("layer4_pool2"): # 定义一个过滤器 # [1, 2, 2, 1] 尺寸为2x2, 当前层的深度64 # stride = 2 # padding SAME # 输出 ceil(14/stride)=7 7x7x32 self.layer4 = tf.nn.max_pool(value=self.layer3, ksize=[1, self.pool2_size, self.pool2_size, 1], strides=[1, self.pool2_stride, self.pool2_stride, 1], padding='SAME') # 将第四层池化层的输出转化为全连接层的形式 with tf.name_scope("layer5_fc1"): # 全连接层 self.pool_shape = self.layer4.get_shape().as_list() # self.pool_shape [batch_size, w, h, d] 四维数组 nodes = self.pool_shape[1] * self.pool_shape[2] * self.pool_shape[3] self.fc = tf.reshape(tensor=self.layer4, shape=[-1, nodes]) self.fc1_weight = tf.get_variable(name="fc1_weight", shape=[nodes, self.fc_size], dtype=tf.float32, initializer=tf.random_normal_initializer(mean=0, stddev=1)) self.fc1_biases = tf.get_variable(name='fc1_biases', shape=[self.fc_size], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) self.layer5 = tf.nn.relu(tf.matmul(self.fc, self.fc1_weight) + self.fc1_biases) self.layer5 = tf.nn.dropout(x=self.layer5, keep_prob=0.5) if self.regularize: tf.add_to_collection(name='loss', value=tf.contrib.layers.l2_regularizer(self.regularize_rate)(self.fc1_weight)) with tf.name_scope("layer6_fc2"): # 全连接层 self.fc2_weight = tf.get_variable(name='fc2_weight', shape=[self.fc_size, self.output_node], dtype=tf.float32, initializer=tf.truncated_normal_initializer(mean=0, stddev=1)) self.fc2_biases = tf.get_variable(name='fc2_biases', shape=[self.output_node], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) self.layer6 = tf.matmul(self.layer5, self.fc2_weight) + self.fc2_biases if self.regularize: tf.add_to_collection(name='loss', value=tf.contrib.layers.l2_regularizer(self.regularize_rate)(self.fc2_weight)) with tf.name_scope("layer7_output"): # soft max层 self.cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.layer6, labels=tf.argmax(self.y_, 1)) self.cross_entropy_mean = tf.reduce_mean(self.cross_entropy) tf.add_to_collection(name='loss', value=self.cross_entropy_mean) with tf.name_scope('loss'): self.loss = tf.add_n(tf.get_collection('loss')) with tf.name_scope('optimizer'): self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(loss=self.loss) with tf.name_scope('evaluate'): # 计算验证数据集的准确率 self.predict_correction = tf.equal(tf.argmax(self.layer6, 1), tf.argmax(self.y_, 1)) self.accuracy = tf.reduce_mean(tf.cast(self.predict_correction, dtype=tf.float32), name="accuracy") # tensor board显示数据 with tf.name_scope("summary"): tf.summary.scalar("loss", self.loss) tf.summary.scalar("accuracy", self.accuracy) self.summary_op = tf.summary.merge_all() def train(self, train_data): # 输入图像的大小 with tf.Session() as sess: init_op = tf.group(tf.local_variables_initializer(), tf.global_variables_initializer()) sess.run(init_op) writer = tf.summary.FileWriter(logdir=self.board_data, graph=sess.graph) # 保存tensorboard中的数据 saver = tf.train.Saver(tf.global_variables(), max_to_keep=2) # 保存模型 count = 0 for step in range(self.train_step): for _ in range(train_data.get_batch_num()): xs, ys = train_data.next_batch() xs = np.reshape(xs, newshape=(-1, self.input_image_size[0], self.input_image_size[1], self.input_image_size[2]) ) feed_dict = {self.x: xs, self.y_: ys} _, loss, summary = sess.run([self.optimizer, self.loss, self.summary_op], feed_dict=feed_dict) # print("The loss at step {} is {}".format(count, loss)) count += 1 if count % 100 == 0: x_valid, y_valid = train_data.validation_data() x_valid = np.reshape(x_valid, newshape=(-1, self.input_image_size[0], self.input_image_size[1], self.input_image_size[2]) ) feed_dict_validation = {self.x: x_valid, self.y_: y_valid} accuracy = sess.run(self.accuracy, feed_dict=feed_dict_validation) print("The accuracy After {} steps is {}".format(count, accuracy)) # 保存模型 saver.save(sess=sess, save_path=self.model_save) # 保存tensor board数据 writer.add_summary(summary=summary, global_step=step) def predict(train_data, load_model, image_size): sess = tf.Session() check_point_file = tf.train.latest_checkpoint(load_model) saver = tf.train.import_meta_graph("{}.meta".format(check_point_file), clear_devices=True) saver.restore(sess=sess, save_path=check_point_file) graph = sess.graph test_data = graph.get_operation_by_name("placeholder/x-input").outputs[0] test_label = graph.get_operation_by_name("placeholder/y-input").outputs[0] test_accuracy = graph.get_operation_by_name("evaluate/accuracy").outputs[0] x_t, y_t = train_data.test_data() x_t = np.reshape(x_t, newshape=(-1, image_size[0], image_size[1], image_size[2])) feed_dict = {test_data: x_t, test_label: y_t} accuracy = sess.run(test_accuracy, feed_dict=feed_dict) print("The test accuracy is {}".format(accuracy)) if __name__ == '__main__': data_path = r'E:\code\112\tensorflow_project\chapter5\data\tensorflow_data' board_data = r"E:\back_up\code\112\tensorflow_project\newbook\chapter4\model\tensorboard" # tensorboard数据保存路径 model_save = r'E:\back_up\code\112\tensorflow_project\newbook\chapter4\model\garph\graph' # 保存模型的数据 load_model = r"E:\back_up\code\112\tensorflow_project\newbook\chapter4\model\garph" train_data = TrainData(data_path=data_path, batch_size=100) train_data.display_data_info() model = Model(input_image_size=[28, 28, 1], output_node=10, learning_rate=0.001,train_data=train_data, board_data=board_data, model_save=model_save, train_step=40) model.train(train_data=train_data) print("---------test-----------") predict(train_data=train_data, load_model=load_model, image_size=[28, 28, 1])
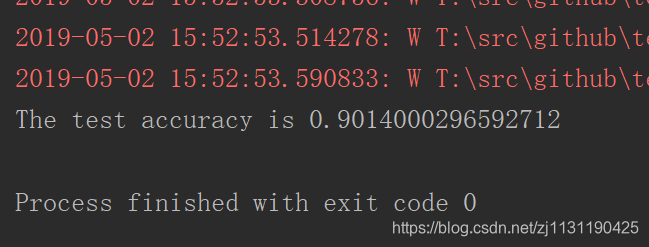
训练的结果:
在卷积神经网络中,卷积层过滤器的深度一般都设置为逐层递增的方式,卷积层的步长一般为1.,2或者3。池化层过滤器的边长一般为2或者3,步长一般也为2或者3.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)