

深度学习 循环神经网络RNN
循环神经网络简介:
循环神经网络(Recurrent Neural Networks)是一种特殊的神经网络结构, 它是根据"人的认知是基于过往的经验和记忆"这一观点提出的. 它与DNN,CNN不同的是: 它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能。RNN的主要用途是处理和预测序列数据。
RNN之所以称为循环神经网路,是因为一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
神经网络的结构如下所示:
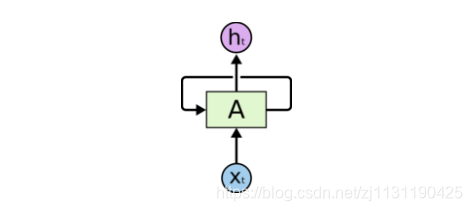
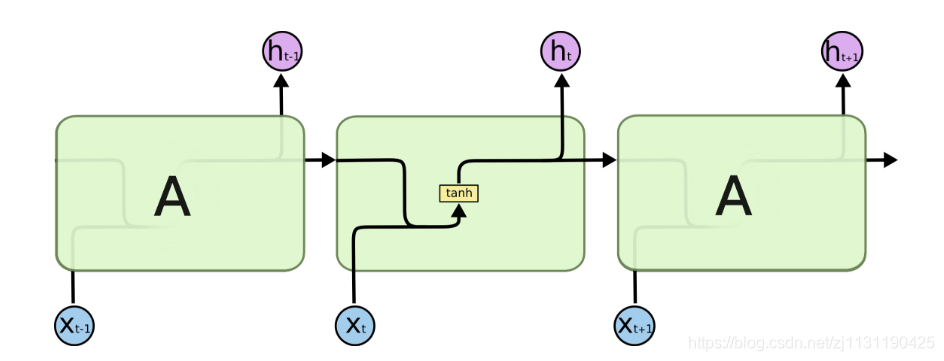
在每一时刻t,RNN结合该时刻的输入x和当前模型的状态h给出一个输出y,同时更新模型的状态。模块A中的运算和变量在不同时刻是相同的。如果说卷积神经网络是在不同的空间位置共享参数的,那么RNN就是在不同的时间位置共享参数。可以将上图所示的结构展开,则循环神经网络的结构就变成如下图所示:

如上图所示,循环神经网络在每一时刻有输入, 然后根据前一时刻的状态
计算新的状态(输出)
,并计算输出。在t时刻,状态
包含了前面
的信息,用于作为输出
的参考。由于序列x可以无限延长,但是状态h的维度有限,不可能将序列的全部信息都保存下来,因此模型学习只保留与后面输出
相关的最重要的信息。
RNN的训练:
如上图所示, 长度为N的循环神经网络展开之后,可以视为一个有N个中间层的前馈神经网络,这个网络没有循环链接,可以直接用反向传播算法进行训练。
循环神经网络可以看作是同一神经网络结构在时间序列上被复制多次的结果,这个被复制多次的结构成为循环体。循环体的结构如下图所示:
循环神经网络前向传播的计算过程:

循环神经网络的状态通过一个向量表示,这个向量的维度也称之为循环神经网络隐藏层的大小。
沿时间反向传播算法(Back-Propagation Through Time, BPTT)是训练RNN的常见方法
长短时记忆网络(LSTM):
循环神经网络的长期依赖问题:
循环神经网络通过保存历史信息来帮助当前的决策,这样可以很好的利用传统神经网络所不能建模的信息。在有些问题中,模型仅仅需要短期内的信息来执行当前的任务。举个例子,(来自书本《实战tensorflow框架》,个人觉得是很经典的例子):
场景一:
预测“大海的颜色是_____”,模型并不需要记忆这个短语之前更长的上下文信息,因为这句话已经包含足够的信息来预测最后一个词。这种场景中,待预测的词和相关的信息之间的间隔很小,RNN可以比较容易地利用先前的信息。
场景二:
预测”某地设了大量的工厂,污染严重,大海的颜色是_____,“,这种场景下短期以来就无法很好的解决问题了。如果模型需要准确预测缺失的词,就要考虑距离当前位置较远的上下文信息。此时待预测的词和相关的信息之间的间隔较大。RNN可能会丧失学习到距离如此远的信息的能力。
在更加复杂的场景中,有用信息的距离有近又远,长短不一,RNN就不能表现出较好的性能。
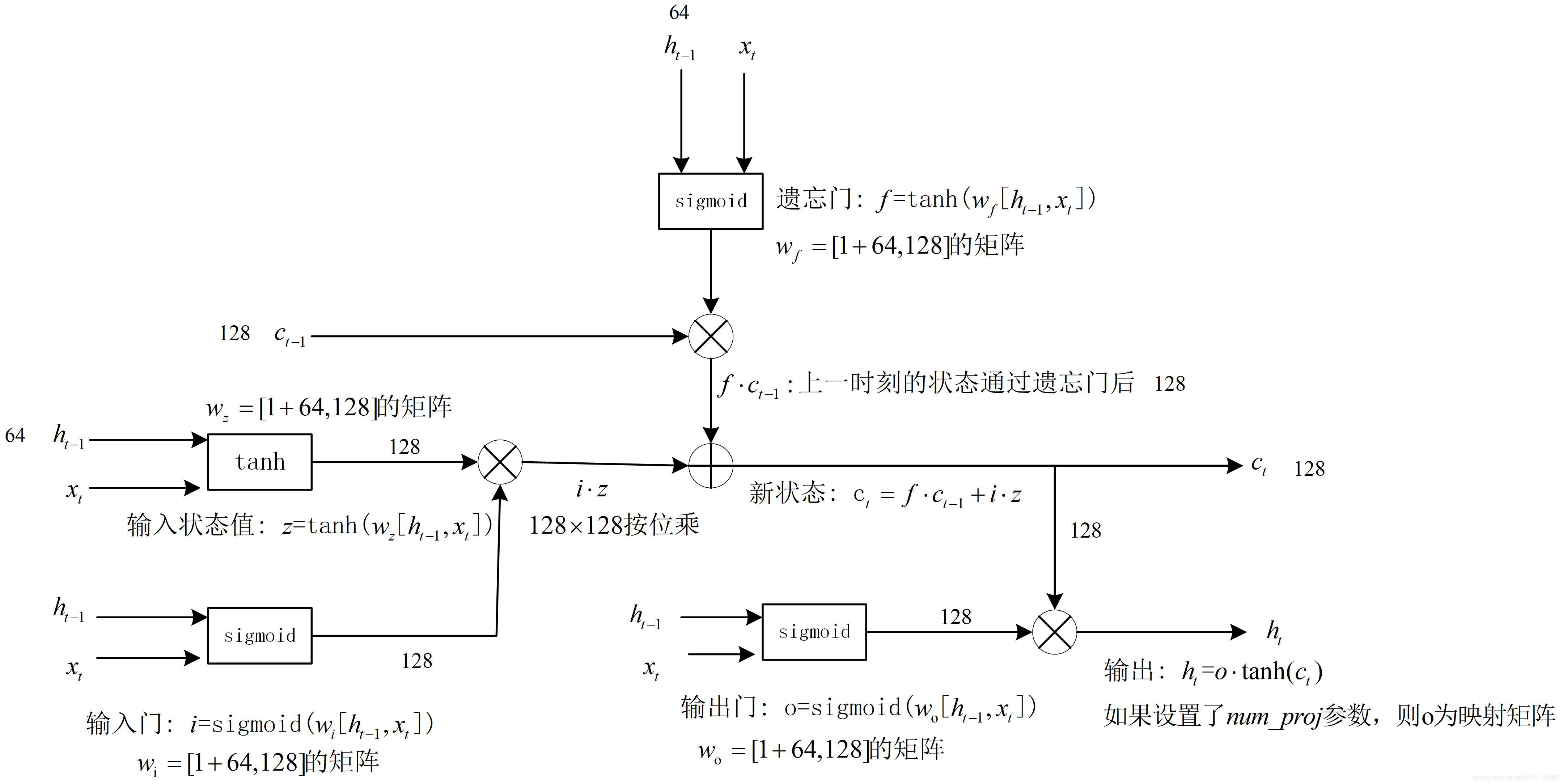
长短时记忆网络(Long short-term memory)的设计就是解决这个问题。LSTM是一种具有特殊循环体结构的循环神经网络。LSTM的循环体结构如下:
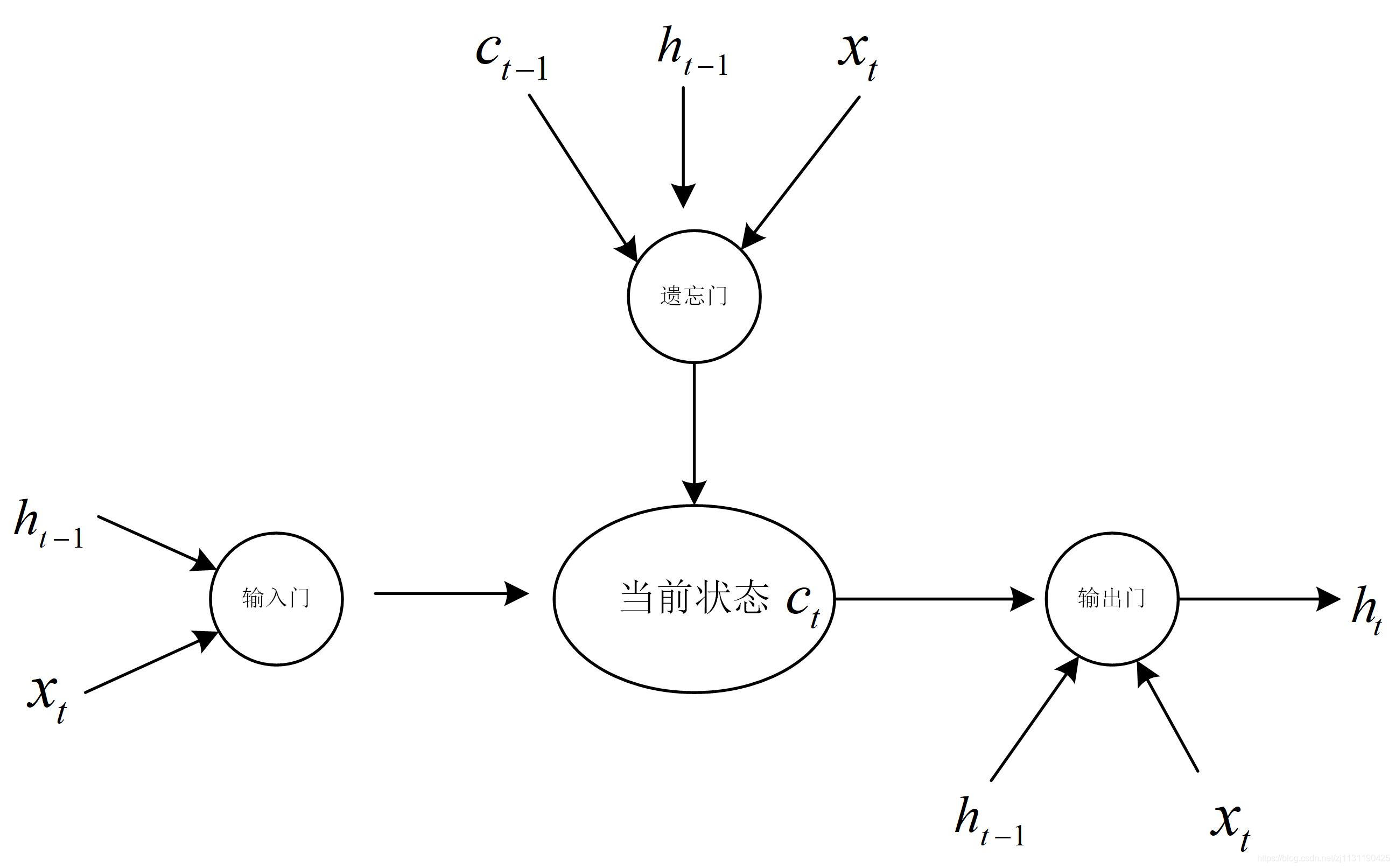
LSTM单元结构的特点是具有三个门结构,这些门结构能够让信息有选择性地影响循环神经网络中每个时刻的状态。”门“结构就是用一个sigmoid神经网络和一个按位做乘法的操作,这两个操作合在一起就是”门“结构。sigmoid作为激活函数的全连接层神经网络输出0~1之间的值,表示有多少信息量可以通过”门结构“。
遗忘门:
遗忘门的作用是让循环神经网络忘记之前没有用的信息,遗忘门通过输入和上一次的输出
决定那一部分记忆需要被遗忘,
假设状态c的维度为n,遗忘门会更具输入 和上衣时刻的输出
计算计算出一个n维的向量 f :
向量f的每一位的取值是[0, 1], 再将上一时刻的状态按位乘以f, 即,那么f中取值接近0的维度上的信息会被忘记。接近1的维度上的信息会被保留。
输入门:
当LSTM通过遗忘门忘记了部分之前的状态的时候,它还需要通过输入门从当前的输入补充一些新的记忆到。输入门根据输入和上一次的输出
决定哪些信息需要加入到状态
中形成新的状态
。
输出门:
输出门会根据状态,上一时刻的输出
和输入
来决定当前时刻的输出
循环体的计算细节如下图所示:(书中的这个有助于理解)

tensorflow实现LSTM结构:
import tensorflow as tf lstm_hidden_size = 100 lstm = tf.nn.rnn_cell.BasicLSTMCell(num_units=lstm_hidden_size) # lstm结构 # lstm的状态初始化为全0的数组 # BasicLSTMCell的zero_state函数生成全0的初始状态 state = lstm.zero_state(batch_size=50, dtype=tf.float32) # state是一个包含两个张量的lstm_state_tuple类 # state.c代表状态c, state.h代表输出 loss = 0.0 for _ in range(1000): lstm_out, state = lstm(current_input, state) loss = calculate(loss)
双向循环神经网络:
在上面介绍的循环神经网络中,状态的传输是从前向后单向进行的,再在有些问题当中,这一时刻的输出与之前的状态和之后的状态都有关系,这时就需要使用双向循环神经网络来解决这类问题。例如:预测句子中缺失的单词。不仅需要前文也需要后文才能做出准确的判断。双向神经网络是两个独立的神经网络叠加到一起,它的输出是两个神经网络上出拼接在一起的。如下图所示的双向RNN:

在同一时刻t,输入同时提供给两个方向相反的RNN, 两个网络独立进行计算,各自产生输出和新的状态。
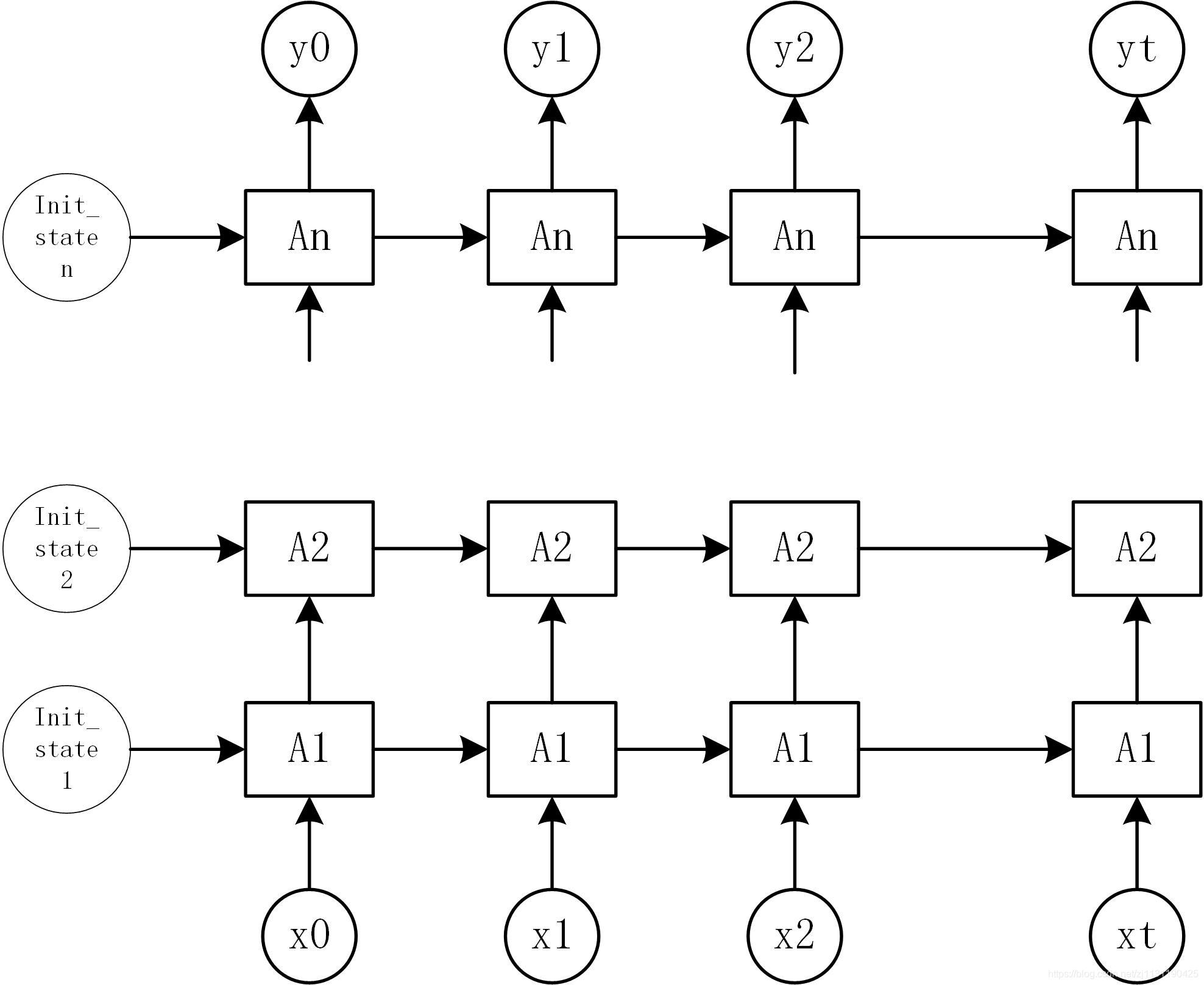
深层循环神经网络:
DeepRNN是RNN的另一个变种,为了增强模型的表达能力,在网络中设置多个循环层,将每层循环网络的输出传递给下一层进行处理。DeepRNN的结构如下图所示:
tensorflow实现DeepRNN:
import tensorflow as tf lstm_hidden_size = 100 lstm = tf.nn.rnn_cell.BasicLSTMCell(num_units=lstm_hidden_size) # lstm结构 # lstm的状态初始化为全0的数组 # BasicLSTMCell的zero_state函数生成全0的初始状态 # 通过MultiRNNCell类实现深层循环神经网络每一时刻的前向传播过程 number_of_layers = 5 # Deep RNN的层数 stacked_lstm = tf.nn.rnn_cell.MultiRNNCell([lstm for _ in range(number_of_layers)]) # 注意,tensorflow自1.1版本起,不能使用[lstm]*N 来形成MultiRNNCell,否则Deep RNN每一层之间会共享参数 state = stacked_lstm.zero_state(batch_size=50, dtype=tf.float32) # state是一个包含两个张量的lstm_state_tuple类 # state.c代表状态c, state.h代表输出 loss = 0.0 for _ in range(1000): lstm_out, state = lstm(current_input, state) loss = calculate(loss)
循环神经网络的dropout
与CNN类似,在RNN上也可以使用dropout,使得神经网络更加的健壮。CNN只在最后的全连接层中使用dropout,而RNN一般只在不同循环体之间使用使用dropout,而不在同一层的循环体之间使用。

如上图所示,假设需要将输入到网络的时候,虚线部分会使用dropout, 而实线部分不会使用。
tensorflow中RNN实现dropout:
import tensorflow as tf lstm_hidden_size = 100 lstm = tf.nn.rnn_cell.BasicLSTMCell(num_units=lstm_hidden_size) # lstm结构 # lstm的状态初始化为全0的数组 # BasicLSTMCell的zero_state函数生成全0的初始状态 # 通过MultiRNNCell类实现深层循环神经网络每一时刻的前向传播过程 number_of_layers = 5 # Deep RNN的层数 # 使用类DropoutWrapper来实现dropout功能,有两个参数需要设置 # input_keep_prob 输入的dropout概率 # output_keep_prob 输入的dropout概率 stacked_lstm = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.DropoutWrapper(lstm, input_keep_prob=0.3, output_keep_prob=0.4) for _ in range(number_of_layers)]) # 注意,tensorflow自1.1版本起,不能使用[lstm]*N 来形成MultiRNNCell,否则Deep RNN每一层之间会共享参数 state = stacked_lstm.zero_state(batch_size=50, dtype=tf.float32) # state是一个包含两个张量的lstm_state_tuple类 # state.c代表状态c, state.h代表输出 loss = 0.0 for _ in range(1000): lstm_out, state = lstm(current_input, state) loss = calculate(loss)
lstm的输入数据的形式有点不好理解,通过查阅资料,理解如下(如有错误请指正,万分感激)
介绍几个函数:
1. tf.nn.rnn_cell.LSTMCell: 这是一个基本的创建LSTM cell的类,使用的时候创建一个lstm对象。
构造函数为:
__init__( num_units, use_peepholes=False, cell_clip=None, initializer=None, num_proj=None, proj_clip=None, num_unit_shards=None, num_proj_shards=None, forget_bias=1.0, state_is_tuple=True, activation=None, reuse=None, name=None, dtype=None, **kwargs )
只介绍几个常用的参数:
- num_units: LSTM cell中的units数量,也就是说的隐藏层的节点数。
- num_proj: 可选,实际是一个全连接层,表示投射(projection)操作之后输出的维度,要是为None的话,表示不进行投射操作。
- state_is_tuple: state状态作为一个元组,今后都默认为
True - activation: 内部状态的激活函数,默认是
tanh
通过一段代码展示一下:
import numpy as np import tensorflow as tf from tensorflow.contrib.layers.python.layers import initializers lstm_cell=tf.nn.rnn_cell.LSTMCell( num_units=128, use_peepholes=True, initializer=initializers.xavier_initializer(), num_proj=64, name="LSTM_CELL" ) print("output_size:", lstm_cell.output_size) print("state_size:", lstm_cell.state_size) print("state_size_h", lstm_cell.state_size.h) print("state_size_c", lstm_cell.state_size.c)
代码的运行结果:
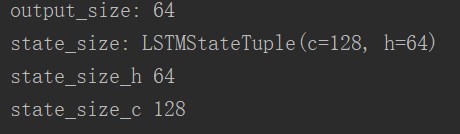
这个过程可以借助下图理解:
隐藏层维度128是指c的维度,参数num_proj如果None的话,则Lstm的输出h的维度也是128,这里将num_proj的维度设置为64,相当于在128维i输出h的后面再加一个全连接层,将输出映射成64维。
2. tf.nn.dynamic_rnn()
这个函数的作用就是通过指定的RNN Cell来展开计算神经网络,它的参数列表如下:
def dynamic_rnn(cell, inputs, sequence_length=None, initial_state=None, dtype=None, parallel_iterations=None, swap_memory=False, time_major=False, scope=None):
默认条件下,当time_major == False (default) 的时候,必须是形状为 [batch_size, max_time, input_size] 的tensor。要是 time_major == True 的话, 必须是形状为 [max_time, batch_size, input_size] 的tensor。
sequence_length: 可选,一个int32/int64类型的vector,他的尺寸是[batch_size]. 对于最后结果的正确性,这个还是非常有用的.因为给他具体每一个序列的长度,能够精确的得到结果,排除了之前为了把所有的序列弄成一样的长度padding造成的不准确.
initial_state: 可选,RNN的初始状态. 要是cell.state_size 是一个整形,那么这个参数必须是一个形状为 [batch_size, cell.state_size] 的tensor. 要是cell.state_size 是一个tuple, 那么这个参数必须是一个tuple,其中元素为形状为[batch_size, s] 的tensor,s为cell.state_size 中的各个相应size.
dtype: 可选,表示输入的数据类型和期望输出的数据类型.当初始状态没有被提供或者RNN的状态由多种形式构成的时候需要显示指定.
parallel_iterations: 默认是32,表示的是并行运行的迭代数量(Default: 32). 有一些没有任何时间依赖的操作能够并行计算,实际上就是空间换时间和时间换空间的折中,当value远大于1的时候,会使用的更多的内存但是能够减少时间,当这个value值很小的时候,会使用小一点的内存,但是会花更多的时间.
swap_memory: Transparently swap the tensors produced in forward inference but needed for back prop from GPU to CPU. This allows training RNNs which would typically not fit on a single GPU, with very minimal (or no) performance penalty.
time_major: 规定了输入和输出tensor的数据组织格式,如果 true, tensor的形状需要是[max_time, batch_size, depth]. 若是false, 那么tensor的形状为[batch_size, max_time, depth]. 要是使用time_major = True 的话,会更加高效率一点,因为避免了在RNN计算的开始和结束的时候对于矩阵的转置 ,然而,大多数的tensorflow数据格式都是采用的以batch为主的格式,所以这里也默认采用以batch为主的格式.
scope: 子图的scope名称,默认是"rnn"
(来源:https://blog.csdn.net/xierhacker/article/details/78772560)
关于LSTM的输入和输出维度问题:
输入的数据如下图所示:

输出的数据的维度如下图所示:
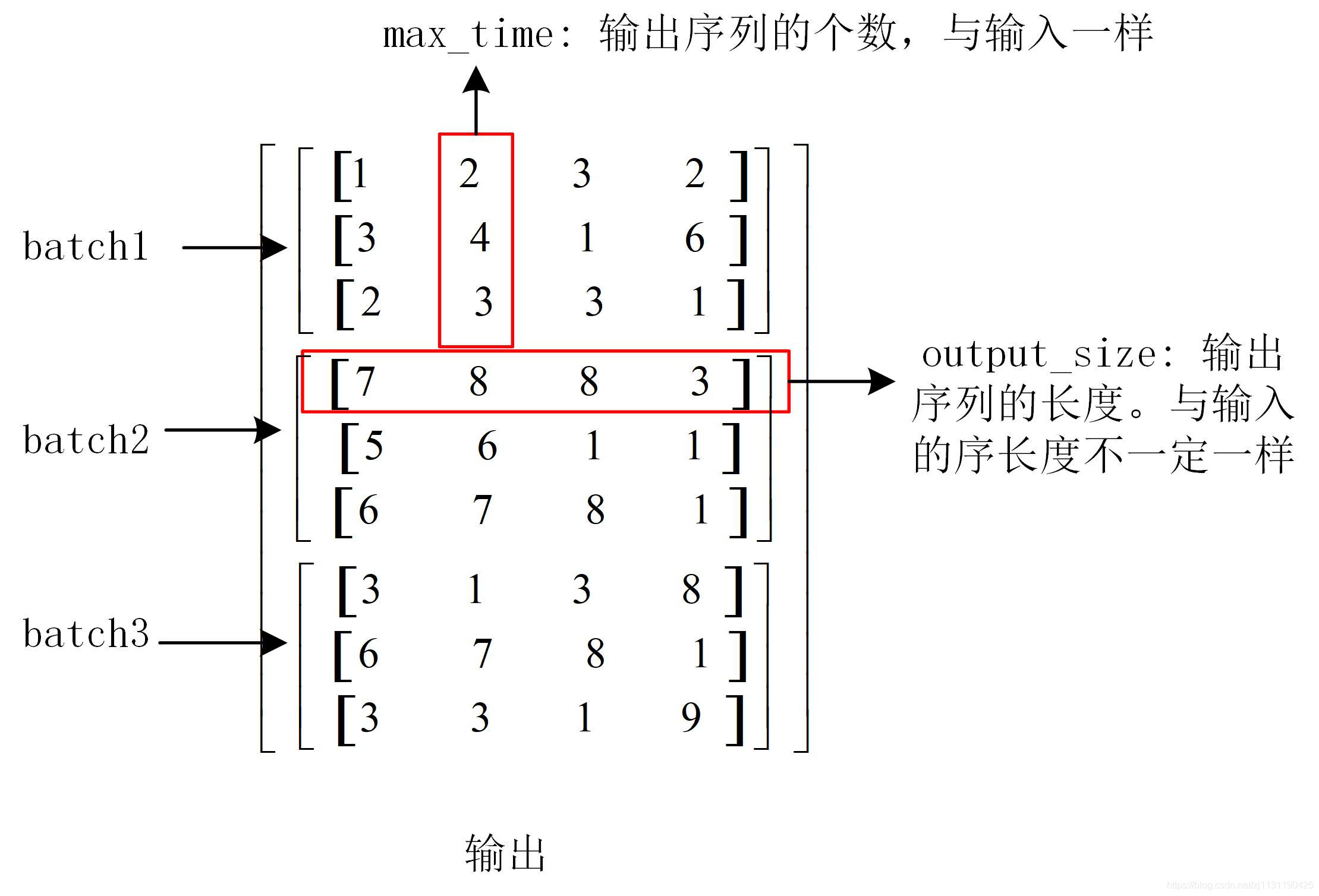
input_size相当于输入的一个序列,max_time代表输入序列的数目。
可以通过如下方式查看输入输出的维度:
import tensorflow as tf import numpy as np inputs = tf.placeholder(np.float32, shape=(32, 40, 5)) # [batch_size, max_time, input_size] lstm_cell_1 = tf.nn.rnn_cell.LSTMCell(num_units=128, num_proj=64) print("output_size:", lstm_cell_1.output_size) print("state_size:", lstm_cell_1.state_size) output, state = tf.nn.dynamic_rnn( cell=lstm_cell_1, inputs=inputs, dtype=tf.float32 ) print("output.shape:", output.shape) print("len of state tuple", len(state)) print("state.h.shape:", state.h.shape) print("state.c.shape:", state.c.shape)
输出维度:

RNN的简单应用:
预测正弦函数:
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt from tqdm import tqdm class Data: def __init__(self, time_step, batch_size, sample_gap, train_examples, test_examples): """ :param time_step: :param batch_size: :param sample_gap: :param train_examples: 训练集数量 :param test_examples: 测试集数量 """ # self.seq = seq self.time_step = time_step self.batch_size = batch_size self.sample_gap = sample_gap self.train_examples = train_examples self.test_examples = test_examples self.test_start = (self.train_examples + self.time_step) * self.sample_gap self.test_end = self.test_start + (self.test_examples + self.time_step) * self.sample_gap def generate_data(self, seq): x = [] y = [] for i in range(len(seq) - self.time_step): x.append([seq[i:i + self.time_step]]) y.append([seq[i + self.time_step]]) # x, y = np.array(x, dtype=np.float32), np.array(y, dtype=np.float32) return x, y def get_train_data(self): sequence_train = np.sin(np.linspace(start=0, stop=self.test_start, num=self.train_examples, dtype=np.float32)) train_x, train_y = self.generate_data(sequence_train) # [batch_size, input_size, max_time] return train_x, train_y def get_batch_data(self, batch_count): """ 获取一个batch的数据 :param batch_count: :return: """ xx, yy = self.get_train_data() start_pos = batch_count * self.batch_size end_pos = min((batch_count + 1) * self.batch_size, self.train_examples) batch_x, batch_y = xx[start_pos: end_pos], yy[start_pos: end_pos] batch_x = np.array(batch_x) batch_y = np.array(batch_y) return batch_x, batch_y def get_test_data(self): """ 获取所有的测试数据 :return: """ sequence_test = np.sin(np.linspace(start=self.test_start, stop=self.test_end, num=self.test_examples, dtype=np.float32)) test_x, test_y = self.generate_data(sequence_test) return test_x, test_y def get_batch_num(self): return self.train_examples // self.batch_size class Model: def __init__(self, hidden_size, num_layers, max_time, input_size, learning_rate, train_step, model_save, board_data): self.hidden_size = hidden_size self.num_layers = num_layers self.max_time = max_time # 输入序列的长度 self.input_size = input_size # 序列的个数 self.learning_rate = learning_rate self.train_step = train_step self.model_save = model_save self.board_data = board_data with tf.name_scope("placeholder"): self.x = tf.placeholder(dtype=tf.float32, shape=[None, self.max_time, self.input_size], name='x_input') self.y_ = tf.placeholder(dtype=tf.float32, shape=[None, 1], name='y_input') with tf.name_scope("lstm"): cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.LSTMCell(num_units=self.hidden_size, num_proj=64) for _ in range(self.num_layers)]) # tf.nn.dynamic_rnn函数的参数: # cell, # inputs, # 维度是[batch_size, max_time, input_size] batch_size, 序列长度, 序列的个数 # sequence_length = None, # initial_state = None, 如果不提供init_state,则必须指定dtype # dtype = None, init_state的数据类型 # parallel_iterations = None, # swap_memory = False, # time_major = False, # scope = None self.output, self.state = tf.nn.dynamic_rnn(cell, self.x, dtype=tf.float32) # dynamic_rnn这个函数的作用就是通过指定的RNN Cell来展开计算神经网络 # RNN的输出 # outputs:[batch_size, max_time, cell.output_size] # state: [batch_size, cell.state_size] self.outputs = self.output[:, -1, :] # 只取最后一个时刻的输出 with tf.name_scope("loss"): predictions = tf.contrib.layers.fully_connected(inputs=self.outputs, num_outputs=1, activation_fn=None) self.loss = tf.losses.mean_squared_error(labels=self.y_, predictions=predictions) with tf.name_scope("summary"): tf.summary.scalar("loss", self.loss) self.summary_op = tf.summary.merge_all() with tf.name_scope("train_op"): # self.train_op = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(self.loss) self.train_op = tf.contrib.layers.optimize_loss(self.loss, tf.train.get_global_step(), optimizer="Adagrad", learning_rate=self.learning_rate) def train(self, data): with tf.Session() as sess: init_op = tf.group(tf.local_variables_initializer(), tf.global_variables_initializer()) sess.run(init_op) writer = tf.summary.FileWriter(logdir=self.board_data, graph=sess.graph) # 保存tensorboard中的数据 saver = tf.train.Saver(tf.global_variables(), max_to_keep=2) # 保存模型 loop_count = 0 # 加载测试数据 test_x, test_y = data.get_test_data() test_x, test_y = test_x[:100], test_y[:100] y_label = [tmp[0] for tmp in test_y] plt.plot(y_label, color='r') for count in range(self.train_step): total_loss = 0 print("Train step is {}".format(count)) for batch_count in tqdm(range(data.get_batch_num())): train_x, train_y = data.get_batch_data(batch_count) feed_dict = {self.x: np.reshape(train_x, [-1, self.max_time, self.input_size]), self.y_: np.reshape(train_y, [-1, 1])} _, loss, summary = sess.run([self.train_op, self.loss, self.summary_op], feed_dict=feed_dict) total_loss += loss loop_count += 1 if loop_count % 500 == 0: # 执行测试程序 feed_dict = {self.x: np.reshape(test_x, [-1, self.max_time, self.input_size]), self.y_: np.reshape(test_y, [-1, 1])} test_loss, test_out = sess.run([self.loss, self.outputs], feed_dict=feed_dict) y_test = [xx[0] for xx in test_out] # 将嵌套的列表转化为列表 plt.plot(y_test) # 作图 print("After {} loops the test loss is {}".format(loop_count, test_loss)) # 保存模型 saver.save(sess=sess, save_path=self.model_save) # 保存tensor board数据 writer.add_summary(summary=summary, global_step=count) plt.show() if __name__ == '__main__': model_save = r"E:\back_up\code\112\tensorflow_project\newbook\chapter5\model\graph\graph" board_data = r"E:\back_up\code\112\tensorflow_project\newbook\chapter5\model\board" data = Data(time_step=10, batch_size=10, sample_gap=0.1, train_examples=10000, test_examples=1000) model = Model(hidden_size=128, num_layers=2, max_time=10, input_size=1, learning_rate=0.001, train_step=30, model_save=model_save, board_data=board_data) model.train(data)
Loss变化如图所示:
通过tensorbaord查看loss数据



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)