AlexNet原理及tensorflow实现
AlexNet的介绍
在前一篇博客卷积神经网络CNN介绍了Le-Net5网络的结构以及tensorflow实现,下面介绍一下另一种经典的卷积神经网络AlexNet的结构以及实现。AlexNet可以看作Le-Net5网络的一个更深更宽的版本。其首次在CNN中成功应用了dropout,ReLu,和LRN等trick.
1. dropout防止模型过拟合,增强模型的健壮性。
2. ReLu函数的应用,解决了sigmoid函数在网络较深时出现的梯度弥散问题。
3. AlexNet中提出池化核的步长的比池化核的尺度小,使得池化层输出的之间有重叠,这样可以提升特征的丰富性
4. 加入LRU层,LRN全称为Local Response Normalization,即局部响应归一化层。LRN函数类似DROPOUT和数据增强,作为relu激活函数之后防止数据过拟合而提出的一种处理方法。这个函数很少使用,基本上被类似DROPOUT这样的方法取代。LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的之变得相对更大,而对响应小的神经元进行抑制。从而增强模型的泛化能力。
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),然后根据论文有公式如下 :

公式中参数的含义如下:
i:代表下标,要计算像素值的下标,从0计算起
j:平方累加索引,代表从j~i的像素值平方求和
x,y:像素的位置,公式中用不到
a:代表feature map里面的 i 对应像素的具体值
N:每个feature map里面最内层向量的列数
k:超参数,由原型中的blas指定
α:超参数,由原型中的alpha指定
n/2:超参数,由原型中的deepth_radius指定
β:超参数,由原型中的belta指定
其实这个公式的含义就是对与第i个像素值,经过LRN后,它的值等于原来的值除以其周围窗口长度为n的范围内的像素值的平方和,最后再加上两个超参数α和k.
5. 数据增强: AlexNet采取从随机的从256x256的图像中随即截取254x254的图像,以及水平反转的镜像。这样能够防止参数众多的CNN陷入过拟合,提升模型的泛化能力。
在进行预测的时候 ,从测试图像的四个角以及中间位置,共取得五张图片,并进行左右反转,这样总共可以得到十张图片,对得到的图片进行预测,最后的结果取均值。
AlexNet的网络结构:

AlexNet网络有6千万个参数,650000个神经元。包含了五个卷积层(卷积操作层和下采样层统称之为卷积层), 和三个全连接层。 LRN层出现在第一个以及第二个卷积层之后,最大池化层出现在两个LRN层以及最后一个卷积层,ReLu函数则应用在每一层的后面,为了使得训练更快,原作者采用两个GPU训练,所以需要将模型拆分为两部分,所以模型图会出现上面的那种结构,现在一块GPU就可以存储网络的所有参数,所以不需要再将模型拆分为上下两部分。
从模型的结构图可以看出,网络的具体结构如下:
第一层:卷积层,卷积核的尺度为11x11,深度96,步长为4.
第二层: LRN层
第三层: 最大池化层,尺寸为3x3, 步长为2
第四层:接着是一个5x5的卷积核,深度256,步长1
第五层:LRN层
第六层:最大池化层,尺寸为3x3,步长为2
第七层:卷积层,卷积核的尺度为3x3,深度384,步长为1.
第八层:卷积层,卷积核的尺度为3x3,深度384,步长为1.
第九层:卷积层,卷积核的尺度为3x3,深度256,步长为1.
第十层:最大池化层,尺寸为3x3, 步长为2
第十一层:全连接层,尺寸4096
第十二层:全连接层,尺寸4096
第十三层:输出层,1000(分类个数)
AlexNet的实现:
首先介绍数据集:车辆类别分类数据集
这里使用的数据集来自这篇博客:https://blog.csdn.net/qq_40421671/article/details/85319887(用笔记本进行模型训练,太大的数据集不现实,所以就选择一个小的数据集,重在学习)
数据集的下载地址:
链接:https://pan.baidu.com/s/1yoC4EYhK9zpTMZDIZDAQoA
提取码:pfic
下载后数据的形式如图所示:

训练集数据如图所示:
每一个文件夹下对应140张该类别的图片,大致是这样的:

考虑到数据集有点小,打算后面做一下数据增强,再对网络进行训练。
首先对数据进行预处理,将图片处理成固定大小,并且给图片按类别命名和保存,图片处理的大小为250x250.处理图片的代码如下:
from PIL import Image
import os
from tqdm import tqdm
def image_process(data_path, data_save, width, height):
"""
:param data_path: 原图片的路径
:param data_save: 处理后的图片的路径
:param width: 图像宽度
:param height: 图像高度
:return:
"""
if not os.path.exists(data_save):
os.makedirs(data_save)
category = os.listdir(data_path)
for cat in category:
image_path = os.path.join(data_path, cat)
count = 0
print("category is %s" % cat)
for img_name in tqdm(os.listdir(image_path)):
complete_path = os.path.join(image_path, img_name)
image = Image.open(complete_path)
image = image.convert("RGB")
reshaped_image = image.resize((width, height), Image.BILINEAR)
reshape_path = os.path.join(data_save, str(count) + "_" + cat + ".jpg")
count += 1
reshaped_image.save(reshape_path)
if __name__ == "__main__":
raw_data_path = r"E:\back_up\NLP\course\train-1\train"
new_data_save = r"E:\back_up\NLP\course\rename_train"
image_process(data_path=raw_data_path, data_save=new_data_save, width=250, height=250)
处理后的图片如下所示:
图片的命名格式为 “编号_类别名”

这里将AlexNet网络输入的图片大小改为为200x200,与AlexNet论文中一样,这里也采用随机裁剪的方法,从每张裁剪出一个200x200的图片,并通过左右反转再得到一张图像,就有140*10*3=5200张图片了
数据增强:
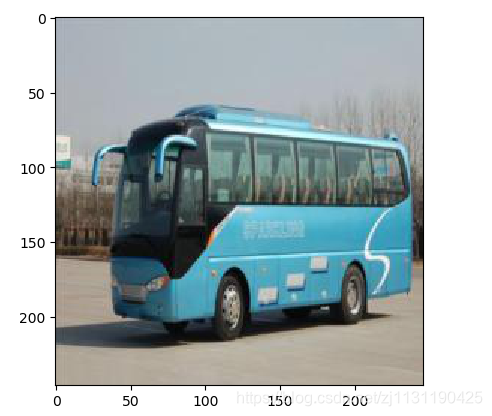
1. 首先进行随机的裁剪:
原图:
裁剪后:
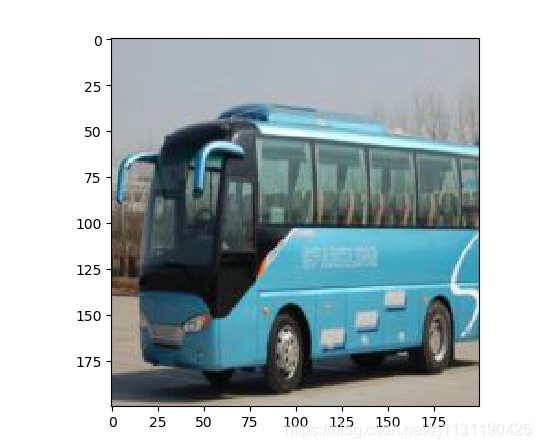

在SSD论文中,对裁剪的描述:
The data augmentation strategy described in Sec. 2.2 helps to improve the performance dramatically, especially on small datasets such as PASCAL VOC. The random crops generated by the strategy can be thought of as a ”zoom in” operation and can generate many larger training examples.
作者提到裁剪相当于zoom in放大效果,可以使网络对尺度更加不敏感,因此可以识别小的物体。
2. 旋转:
对训练数据进行处理的代码:
from PIL import Image
import os
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
def image_process(data_path, data_save, width, height):
"""
将文件夹中的图片处理成固定大小的图片
:param data_path: 原图片的路径
:param data_save: 处理后的图片的路径
:param width: 图像宽度
:param height: 图像高度
:return:
"""
if not os.path.exists(data_save):
os.makedirs(data_save)
category = os.listdir(data_path)
for cat in category:
image_path = os.path.join(data_path, cat)
count = 0
print("category is %s" % cat)
for img_name in tqdm(os.listdir(image_path)):
complete_path = os.path.join(image_path, img_name)
image = Image.open(complete_path)
image = image.convert("RGB")
reshaped_image = image.resize((width, height), Image.BILINEAR)
reshape_path = os.path.join(data_save, str(count) + "_" + cat + ".jpg")
count += 1
reshaped_image.save(reshape_path)
def test_image_process(test_path, save_path, size):
if not os.path.exists(save_path):
os.makedirs(save_path)
test_image_names = os.listdir(test_path)
count = 0
for name in test_image_names:
img_path = os.path.join(test_path, name)
image = Image.open(img_path)
image = image.convert("RGB")
image_reshaped = image.resize(size, Image.BILINEAR)
image_reshaped.save(os.path.join(save_path, str(count)+'.jpg'))
count += 1
class DataAugmentation:
"""
常用的数据增强的方法: 参考https://www.cnblogs.com/zhonghuasong/p/7256498.html
https://blog.csdn.net/guduruyu/article/details/70842142
1. 翻转变换 flip 左右/垂直
2. 随机修剪 random crop
3. 色彩抖动 color jittering
4. 平移变换 shift
5. 尺度变换 scale
6. 对比度变换 contrast
7. 噪声扰动 noise
8. 旋转变换/反射变换 Rotation/reflection
"""
def __init__(self, raw_data_path, new_data_path, crop_window_size=(100, 100)):
"""
数据增强
原图片的大小为250x250, 通过随机在原图片的五个位置(上下左右中)裁剪得到246x246的图片
:param raw_data_path: 原图片的路径
:param new_data_path: 处理后新图片的路径
:param crop_window: 裁剪窗口的大小
:return:
"""
self.raw_data_path = raw_data_path
self.new_data_path = new_data_path
self.crop_window_size = crop_window_size
if not os.path.exists(self.new_data_path):
os.makedirs(self.new_data_path)
def augmentation(self):
image_names = os.listdir(self.raw_data_path)
for name in tqdm(image_names):
full_path = os.path.join(self.raw_data_path, name)
image = Image.open(full_path) # 读取图片
print("image size is ", image.size)
# 随机裁剪图片
img_width = image.size[0]
img_height = image.size[1]
if img_width < self.crop_window_size[0] or img_height < self.crop_window_size[1]:
print("The crop window size is invalid")
return
width_duration = img_width - self.crop_window_size[0] # 宽度的范围
height_duration = img_height - self.crop_window_size[1] # 高度的范围
width_start = np.random.randint(low=0, high=width_duration, size=1)[0]
height_start = np.random.randint(low=0, high=height_duration, size=1)[0]
crop_regin = (width_start, height_start, width_start + self.crop_window_size[0],
height_start + self.crop_window_size[1])
img_crop = image.crop(crop_regin) # 随机裁剪后的图像
# 对图片进行反转
img_rotate = img_crop.transpose(Image.FLIP_LEFT_RIGHT)
# 对图片进行缩放
img_resize = image.resize(self.crop_window_size)
# 对图片进行保存,原来图片的名称为 形如 n_bus, 进行数据增强后图片的名称为 crop_n_bus
img_crop_path = os.path.join(self.new_data_path, 'crop_'+name)
img_crop.save(img_crop_path)
img_rotate_path = os.path.join(self.new_data_path, 'rotate_'+name)
img_rotate.save(img_rotate_path)
img_resize_path = os.path.join(self.new_data_path, 'resize_'+name)
img_resize.save(img_resize_path)
if __name__ == "__main__":
# 训练数据的处理
# raw_data_path = r"E:\back_up\NLP\course\train-1\train" # 原始数据路径
# new_data_save = r"E:\back_up\NLP\course\rename_train" # 处理成250x250的存放路径
# image_process(data_path=raw_data_path, data_save=new_data_save, width=250, height=250)
# raw_data = r"E:\back_up\NLP\course\rename_train" # 处理成250x250的存放路径
# new_data = r"E:\back_up\NLP\course\rename_train_dr" # 数据增强后的路径
# dr = DataAugmentation(raw_data_path=raw_data, new_data_path=new_data, crop_window_size=[200, 200])
# dr.augmentation()
# 验证集的处理
# raw_data_path = r"E:\back_up\NLP\course\val-1\val" # 原始数据路径
# new_data_save = r"E:\back_up\NLP\course\rename_val" # 处理成250x250的存放路径
# image_process(data_path=raw_data_path, data_save=new_data_save, width=250, height=250)
# raw_data = r"E:\back_up\NLP\course\rename_val" # 处理成250x250的存放路径
# new_data = r"E:\back_up\NLP\course\rename_val_dr" # 数据增强后的路径
# dr = DataAugmentation(raw_data_path=raw_data, new_data_path=new_data, crop_window_size=[200, 200])
# dr.augmentation()
# 测试集处理
test = r"E:\back_up\NLP\course\test-1\test"
save = r"E:\back_up\NLP\course\rename_test"
test_image_process(test_path=test, save_path=save, size=(200, 200))
处理后的训练数据如图所示:

编写读取图像的代码:
class Data:
"""
读取训练集,验证集,测试集数据
"""
def __init__(self, batch_size, data_path, val_data, test_data):
"""
:param batch_size:
:param data_path: 训练数据路径
:param val_data: 验证集路径
:param test_data: 测试集路径
"""
self.batch_size = batch_size
self.data_path = data_path
self.labels_name = []
self.val_data = val_data
self.test_data = test_data
# self.images = []
self.image_names = os.listdir(self.data_path) # 所有的图片集合
for name in tqdm(self.image_names):
# image_path = os.path.join(self.data_path, name)
# image = Image.open(image_path)
# image = np.array(image) / 255.0 # 图像像素值归一化到0-1
"""
归一化的原因
1. 转换成标准模式,防止仿射变换的影响。
2、减小几何变换的影响。
3、加快梯度下降求最优解的速度。
"""
# self.images.append(image)
class_name = name.split('.')[0].split('_')[-1]
self.labels_name.append(class_name)
class_set = set(self.labels_name)
self.labels_dict = {}
for v, k in enumerate(class_set):
self.labels_dict[k] = v
print("Data Loading finished!")
print("Label dict: ", self.labels_dict)
self.labels = [self.labels_dict.get(k) for k in self.labels_name] # 将标签名转化为标签的编号
print("Label names: ", self.labels_name)
print("Labels is: ", self.labels)
def get_batch(self, count):
"""
get_batch函数按照batch将图片读入,因为一次读入全部图片会导致内存暴增
:param count:
:return:
"""
start = count * self.batch_size
end = (count + 1) * self.batch_size
start_pos = max(0, start)
end_pos = min(end, len(self.labels))
images_name_batch = self.image_names[start_pos: end_pos]
images = [] # 存放图片
for images_name in images_name_batch:
image_path = os.path.join(self.data_path, images_name)
image = Image.open(image_path)
image = np.array(image) / 255.0 # 图像像素值归一化到0-1
images.append(image)
labels = self.labels[start_pos: end_pos]
datas = np.array(images)
labels = np.array(labels)
return datas, labels
def get_batch_num(self):
return len(self.labels) // self.batch_size
def get_batch_size(self):
return self.batch_size
def get_val_data(self):
val_names = os.listdir(self.val_data) # 验证集图片
val_images = []
val_labels = []
for name in val_names:
image_path = os.path.join(self.val_data, name)
image = Image.open(image_path)
image = np.array(image) / 255.0 # 图像像素值归一化到0-1
"""
归一化的原因
1. 转换成标准模式,防止仿射变换的影响。
2、减小几何变换的影响。
3、加快梯度下降求最优解的速度。
"""
val_images.append(image)
class_name_val = name.split('.')[0].split('_')[-1]
val_labels.append(class_name_val)
val_images = np.array(val_images)
val_labels = [self.labels_dict.get(k) for k in val_labels] # 将标签名转化为标签的编号
val_labels = np.array(val_labels)
return val_images, val_labels
def get_label_dict(self):
return self.labels_dict
def get_test_info(self):
"""
测试数据没有标签
:return:
"""
test_names = os.listdir(self.test_data)
return self.test_data, test_names在读取数据后,对图像的像素值做了归一化处理:
归一化的原因
1. 转换成标准模式,防止仿射变换的影响。
2、减小几何变换的影响。
3、加快梯度下降求最优解的速度。
完整代码:
import tensorflow as tf
import math
import time
from datetime import datetime
import os
from PIL import Image, ImageDraw, ImageFont
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
class Data:
"""
读取训练集,验证集,测试集数据
"""
def __init__(self, batch_size, data_path, val_data, test_data):
"""
:param batch_size:
:param data_path: 训练数据路径
:param val_data: 验证集路径
:param test_data: 测试集路径
"""
self.batch_size = batch_size
self.data_path = data_path
self.labels_name = []
self.val_data = val_data
self.test_data = test_data
# self.images = []
self.image_names = os.listdir(self.data_path) # 所有的图片集合
for name in tqdm(self.image_names):
# image_path = os.path.join(self.data_path, name)
# image = Image.open(image_path)
# image = np.array(image) / 255.0 # 图像像素值归一化到0-1
"""
归一化的原因
1. 转换成标准模式,防止仿射变换的影响。
2、减小几何变换的影响。
3、加快梯度下降求最优解的速度。
"""
# self.images.append(image)
class_name = name.split('.')[0].split('_')[-1]
self.labels_name.append(class_name)
class_set = set(self.labels_name)
self.labels_dict = {}
for v, k in enumerate(class_set):
self.labels_dict[k] = v
print("Data Loading finished!")
print("Label dict: ", self.labels_dict)
self.labels = [self.labels_dict.get(k) for k in self.labels_name] # 将标签名转化为标签的编号
print("Label names: ", self.labels_name)
print("Labels is: ", self.labels)
def get_batch(self, count):
"""
get_batch函数按照batch将图片读入,因为一次读入全部图片会导致内存暴增
:param count:
:return:
"""
start = count * self.batch_size
end = (count + 1) * self.batch_size
start_pos = max(0, start)
end_pos = min(end, len(self.labels))
images_name_batch = self.image_names[start_pos: end_pos]
images = [] # 存放图片
for images_name in images_name_batch:
image_path = os.path.join(self.data_path, images_name)
image = Image.open(image_path)
image = np.array(image) / 255.0 # 图像像素值归一化到0-1
images.append(image)
labels = self.labels[start_pos: end_pos]
datas = np.array(images)
labels = np.array(labels)
return datas, labels
def get_batch_num(self):
return len(self.labels) // self.batch_size
def get_batch_size(self):
return self.batch_size
def get_val_data(self):
val_names = os.listdir(self.val_data) # 验证集图片
val_images = []
val_labels = []
for name in val_names:
image_path = os.path.join(self.val_data, name)
image = Image.open(image_path)
image = np.array(image) / 255.0 # 图像像素值归一化到0-1
"""
归一化的原因
1. 转换成标准模式,防止仿射变换的影响。
2、减小几何变换的影响。
3、加快梯度下降求最优解的速度。
"""
val_images.append(image)
class_name_val = name.split('.')[0].split('_')[-1]
val_labels.append(class_name_val)
val_images = np.array(val_images)
val_labels = [self.labels_dict.get(k) for k in val_labels] # 将标签名转化为标签的编号
val_labels = np.array(val_labels)
return val_images, val_labels
def get_label_dict(self):
return self.labels_dict
def get_test_info(self):
"""
测试数据没有标签
:return:
"""
test_names = os.listdir(self.test_data)
return self.test_data, test_names
class Model:
def __init__(self, input_size, learning_rate, class_num, board_data, model_save, lrn_option=False):
self.lrn_option = lrn_option
self.input_size = input_size
self.class_num = class_num
self.learning_rate = learning_rate
self.board_data = board_data
self.model_save = model_save
with tf.name_scope("placeholder"):
self.x = tf.placeholder(dtype=tf.float32, shape=[None, self.input_size[0],
self.input_size[1], self.input_size[2]],
name='x_input')
self.y_ = tf.placeholder(dtype=tf.int32, shape=[None], name='y_input')
with tf.name_scope("conv1"):
self.filter1 = tf.get_variable(name='filter1', shape=[11, 11, self.input_size[2], 64],
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.conv1 = tf.nn.conv2d(input=self.x, filter=self.filter1, strides=[1, 4, 4, 1], padding="SAME")
self.biases1 = tf.get_variable(name='biases1', shape=[64], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
self.layer1 = tf.nn.relu(tf.nn.bias_add(value=self.conv1, bias=self.biases1))
if self.lrn_option: # 是否使用LRN
self.layer1 = tf.nn.lrn(self.layer1, depth_radius=4, bias=1, alpha=0.001, beta=0.75, name='lrn1')
with tf.name_scope("pool1"):
self.pool1 = tf.nn.max_pool(value=self.layer1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='VALID', name='pool1')
with tf.name_scope("conv2"):
self.filter2 = tf.get_variable(name='filter2', shape=[5, 5, 64, 192],
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.conv2 = tf.nn.conv2d(input=self.pool1, filter=self.filter2, strides=[1, 1, 1, 1], padding='SAME')
self.biases2 = tf.get_variable(name='biases2', shape=[192], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
self.layer2 = tf.nn.relu(tf.nn.bias_add(value=self.conv2, bias=self.biases2))
if self.lrn_option:
self.layer2 = tf.nn.lrn(self.layer2, depth_radius=4, bias=1, alpha=0.001, beta=0.75, name='lrn2')
with tf.name_scope("pool2"):
self.pool2 = tf.nn.max_pool(value=self.layer2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.name_scope("conv3"):
self.filter3 = tf.get_variable(name='conv3', shape=[3, 3, 192, 384], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.conv3 = tf.nn.conv2d(input=self.pool2, filter=self.filter3, strides=[1, 1, 1, 1], padding='SAME')
self.biases3 = tf.get_variable(name='biases3', shape=[384], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.layer3 = tf.nn.relu(tf.nn.bias_add(value=self.conv3, bias=self.biases3))
with tf.name_scope("conv4"):
self.filter4 = tf.get_variable(name='conv4', shape=[3, 3, 384, 256], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.conv4 = tf.nn.conv2d(input=self.layer3, filter=self.filter4, strides=[1, 1, 1, 1], padding='SAME')
self.biases4 = tf.get_variable(name='biases4', shape=[256], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
self.layer4 = tf.nn.relu(tf.nn.bias_add(value=self.conv4, bias=self.biases4))
with tf.name_scope("conv5"):
self.filter5 = tf.get_variable(name='conv5', shape=[3, 3, 256, 256], dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.conv5 = tf.nn.conv2d(input=self.layer4, filter=self.filter5, strides=[1, 1, 1, 1], padding='SAME')
self.biases5 = tf.get_variable(name='biases5', shape=[256], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
self.layer5 = tf.nn.relu(tf.nn.bias_add(value=self.conv5, bias=self.biases5))
with tf.name_scope("pool3"):
self.layer6 = tf.nn.max_pool(value=self.layer5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="VALID")
# 连接全连接层
with tf.name_scope("fc1"):
self.pool_shape = self.layer6.get_shape().as_list()
self.nodes = self.pool_shape[1] * self.pool_shape[2] * self.pool_shape[3]
self.fc1 = tf.reshape(self.layer6, shape=[-1, self.nodes])
self.fc1_weight = tf.get_variable(name='fc1_weight', shape=[self.nodes, 1024],
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.fc1_biases = tf.get_variable(name='fc1_biases', shape=[1024],
initializer=tf.constant_initializer(0.0))
self.layer6 = tf.nn.relu(tf.matmul(self.fc1, self.fc1_weight) + self.fc1_biases)
self.layer6 = tf.nn.dropout(self.layer6, keep_prob=0.5)
with tf.name_scope("fc2"):
self.fc2_weight = tf.get_variable(name='fc2_weight', dtype=tf.float32, shape=[1024, 512],
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.fc2_biases = tf.get_variable(name='fc2_biases', dtype=tf.float32, shape=[512],
initializer=tf.constant_initializer(0.0))
self.layer7 = tf.nn.relu(tf.matmul(self.layer6, self.fc2_weight) + self.fc2_biases)
self.layer7 = tf.nn.dropout(self.layer7, keep_prob=0.6)
with tf.name_scope("output"):
self.fc3_weight = tf.get_variable(name='fc3_weight', dtype=tf.float32, shape=[512, self.class_num],
initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1))
self.fc3_biases = tf.get_variable(name='fc3_biases', dtype=tf.float32, shape=[self.class_num],
initializer=tf.constant_initializer(0.0))
# self.layer8 = tf.matmul(self.layer7, self.fc3_weight) + self.fc3_biases
self.layer8 = tf.nn.bias_add(value=tf.matmul(self.layer7, self.fc3_weight), bias=self.fc3_biases,
name='outputs')
with tf.name_scope("loss"):
self.loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.layer8,
labels=self.y_), name='loss')
with tf.name_scope("train"):
self.train_op = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(loss=self.loss)
with tf.name_scope("evaluate"):
self.prediction_correction = tf.equal(tf.cast(tf.argmax(self.layer8, 1), dtype=tf.int32), self.y_,
name='prediction')
self.accuracy = tf.reduce_mean(tf.cast(self.prediction_correction, dtype=tf.float32), name='accuracy')
with tf.name_scope("summary"):
tf.summary.scalar('loss', self.loss)
tf.summary.scalar('accuracy', self.accuracy)
self.summary_op = tf.summary.merge_all()
def train(self, data, train_step):
with tf.Session() as sess:
init_op = tf.group(tf.local_variables_initializer(), tf.global_variables_initializer())
sess.run(init_op)
writer = tf.summary.FileWriter(logdir=self.board_data, graph=sess.graph)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=2)
count = 0
for step in range(train_step):
batch_num = data.get_batch_num()
total_loss = 0
for batch_count in tqdm(range(batch_num)):
train_images, train_labels = data.get_batch(batch_count)
feed_dict = {self.x: train_images, self.y_: train_labels}
_, loss, summary = sess.run([self.train_op, self.loss, self.summary_op], feed_dict=feed_dict)
total_loss += loss
count += 1
if count % 200 == 0:
val_images, val_labels = data.get_val_data()
val_feed = {self.x: val_images, self.y_: val_labels}
accuracy = sess.run(self.accuracy, feed_dict=val_feed)
print("The accuracy is {}".format(accuracy))
# 保存模型
saver.save(sess=sess, save_path=self.model_save)
writer.add_summary(summary=summary, global_step=count)
print("After {} steps the loss is {}".format(step, total_loss / batch_num))
def predict(data, model_path, labels_dict, test_result, top_k=3, sample_num=None):
"""
加载模型,对测试数据进行分类
:param data: 数据data类
:param model_path: 模型的存储路径
:param labels_dict: 分类的类别编号
:param test_result: 测试集分类结果的保存路径
:param top_k: top-k准确率
:param sample_num: 样本数量,缺省参数值为None, 默认对测试集中所有的样本进行分类
:return:
"""
sess = tf.Session()
check_point_file = tf.train.latest_checkpoint(model_path)
saver = tf.train.import_meta_graph("{}.meta".format(check_point_file), clear_devices=True)
saver.restore(sess=sess, save_path=check_point_file)
graph = sess.graph
test_img = graph.get_operation_by_name("placeholder/x_input").outputs[0]
# test_label = graph.get_operation_by_name("placeholder/y_input").outputs[0]
prediction = graph.get_operation_by_name("output/outputs").outputs[0]
test_path, img_names = data.get_test_info()
if sample_num is not None:
img_names = img_names[: sample_num]
if not os.path.exists(test_result):
os.mkdir(test_result)
font = ImageFont.truetype(font=r"C:\Windows\Fonts\Times New Roman\times.ttf", size=30)
for name in img_names:
img_path = os.path.join(test_path, name)
image = Image.open(img_path)
image_array = np.array(image) / 255.0
image_array = [image_array]
result = sess.run(prediction, feed_dict={test_img: image_array})
print(result)
index_sorted = (-result[0]).argsort()
print(index_sorted)
index = index_sorted[:top_k]
print(index)
prediction_names = []
for x in index:
predict_name = [k for k, v in labels_dict.items() if int(v) == x]
prediction_names.append(predict_name[0])
print(prediction_names)
draw = ImageDraw.Draw(image)
# draw.text(xy=(20, 20), text="分类结果: %s, %s" % (str(prediction_names[0]), str(prediction_names[1])))
draw.text(xy=(20, 20), text=prediction_names[0], fill=(255, 0, 0), font=font)
test_result_save = os.path.join(test_result, name) # 保存测试的结果
image.save(test_result_save)
if __name__ == '__main__':
data_path = r"E:\back_up\NLP\course\rename_train_dr"
val_data = r"E:\back_up\NLP\course\rename_val_dr"
test_data = r"E:\back_up\NLP\course\rename_test"
model = r"E:\back_up\code\112\tensorflow_project\newbook\chapter6\model\model"
board = r"E:\back_up\code\112\tensorflow_project\newbook\chapter6\board_data"
test_result = r"E:\back_up\NLP\course\test_result"
data = Data(batch_size=20, data_path=data_path, val_data=val_data, test_data=test_data)
model = Model(input_size=[200, 200, 3], learning_rate=0.001, class_num=10, model_save=model, board_data=board)
model.train(data=data, train_step=100)
label_dictionary = data.get_label_dict() # label_dict要使用从data中获取的值
# label_dictionary = {'jeep': 0, 'SUV': 1, 'racing car': 2, 'taxi': 3, 'fire engine': 4, 'bus': 5,
# 'family sedan': 6, 'truck': 7, 'minibus': 8, 'heavy truck': 9}
model_load = r"E:\back_up\code\112\tensorflow_project\newbook\chapter6\model"
predict(data=data, model_path=model_load, sample_num=None, labels_dict=label_dictionary, test_result=test_result)
训练过程:
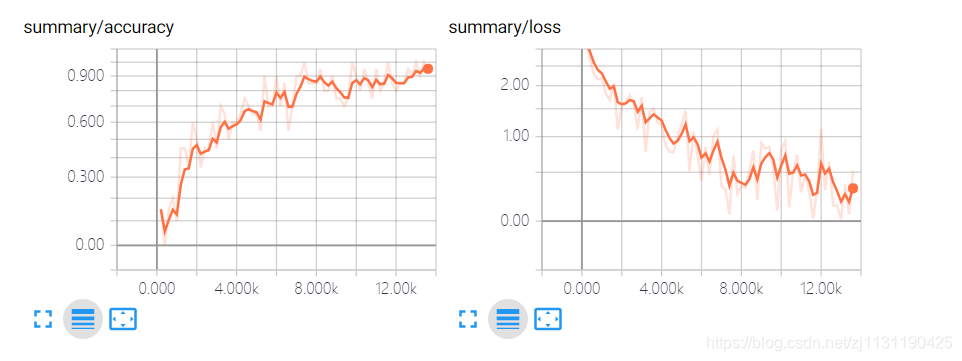
最后模型训练的准确率大概在63%左右
测试过程:
通过定义prediction()函数进行测试,在prediction()函数中加载保存的模型,对策是图片进行分类,分类的结果如下图所示:
正确分类的:














分类错误的:




 浙公网安备 33010602011771号
浙公网安备 33010602011771号