

Python PIL库处理图片常用操作,图像识别数据增强的方法
在博客AlexNet原理及tensorflow实现训练神经网络的时候,做了数据增强,对图片的处理采用的是PIL(Python Image Library), PIL是Python常用的图像处理库.
下面对PIL中常用到的操作进行整理:
1. 改变图片的大小
from PIL import Image, ImageFont, ImageDraw def image_resize(image, save, size=(100, 100)): """ :param image: 原图片 :param save: 保存地址 :param size: 大小 :return: """ image = Image.open(image) # 读取图片 image.convert("RGB") re_sized = image.resize(size, Image.BILINEAR) # 双线性法 re_sized.save(save) # 保存图片 return re_sized
2. 对图片进行旋转:
from PIL import Image, ImageFont, ImageDraw import matplotlib.pyplot as plt def image_rotate(image_path, save_path, angle): """ 对图像进行一定角度的旋转 :param image_path: 图像路径 :param save_path: 保存路径 :param angle: 旋转角度 :return: """ image = Image.open(image_path) image_rotated = image.rotate(angle, Image.BICUBIC) image_rotated.save(save_path) return image_rotated

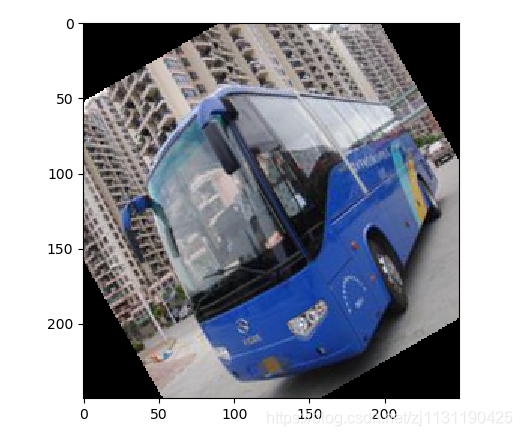
3. 对图片进行左右反转:
from PIL import Image, ImageFont, ImageDraw import matplotlib.pyplot as plt def image_flip(image_path, save_path): """ 图图象进行左右反转 :param image_path: :param save_path: :return: """ image = Image.open(image_path) image_transpose = image.transpose(Image.FLIP_LEFT_RIGHT) # Image.FLIP_TOP_BOTTOM 上下反转 image_transpose.save(save_path) return image_transpose

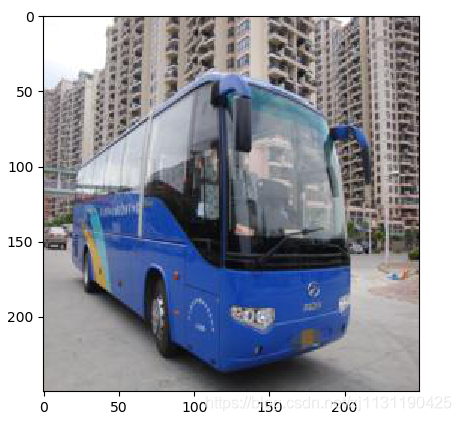
4. 对图像进行裁剪:
from PIL import Image, ImageFont, ImageDraw import matplotlib.pyplot as plt def image_crop(image_path, save_path, crop_region): """ 对图像进行裁剪 :param image_path: :param save_path: :param crop_region: 裁剪的区域 crop_window=(x_min, y_min, x_max, y_max) :return: """ image = Image.open(image_path) image_crop = image.crop(crop_region) # (width_min, height_min, width_max, height_max) 图像的原点是在左上角 image_crop.save(save_path) return image_crop

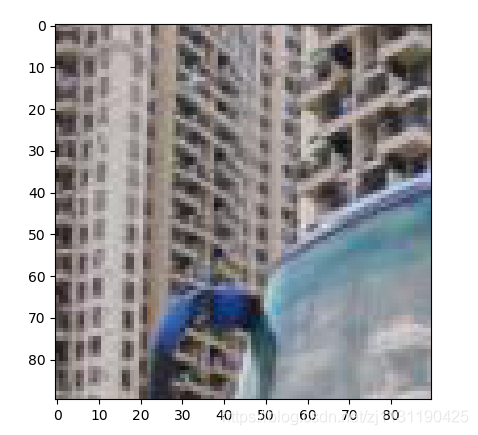
5. 在图片上添加文字
from PIL import Image, ImageFont, ImageDraw import matplotlib.pyplot as plt def image_title(image_path, save_path, font_pos, font_size, text): """ 对图像添加文字 :param image_path: :param save_path: :param font_pos: 文字位置(x, y) :param font_size: 文字大小 :param text: 文字内容 :return: """ image = Image.open(image_path) font = ImageFont.truetype(font=r"C:\Windows\Fonts\Times New Roman\times.ttf", size=font_size) draw = ImageDraw.Draw(image) draw.text(xy=font_pos, text=text, fill=(255, 0, 0), font=font) image.save(save_path) return image

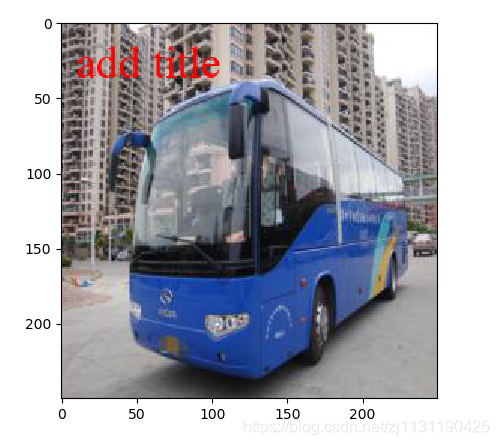
除以上之外,数据增强的方法还有对图像颜色进行抖动,和对图像进行高斯噪声处理
1. 颜色抖动:
from PIL import Image, ImageFont, ImageDraw, ImageEnhance import matplotlib.pyplot as plt import numpy as np def image_color(image_path, save_path): """ 对图像进行颜色抖动 :param image_path: :param save_path: :return: """ image = Image.open(image_path) print(type(image)) random_factor = np.random.randint(low=0, high=31) / 10.0 # 随机的扰动因子 color_image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度 random_factor = np.random.randint(low=10, high=21) / 10.0 bright_image = ImageEnhance.Brightness(color_image).enhance(random_factor) # 调整图像的亮度 random_factor = np.random.randint(low=10, high=21) / 10.0 contrast_image = ImageEnhance.Contrast(bright_image).enhance(random_factor) # 调整图像的对比度 random_factor = np.random.randint(low=0, high=31) / 10.0 sharp_image = ImageEnhance.Sharpness(contrast_image).enhance(random_factor) # 调整图像的锐度 sharp_image.save(save_path) return sharp_image

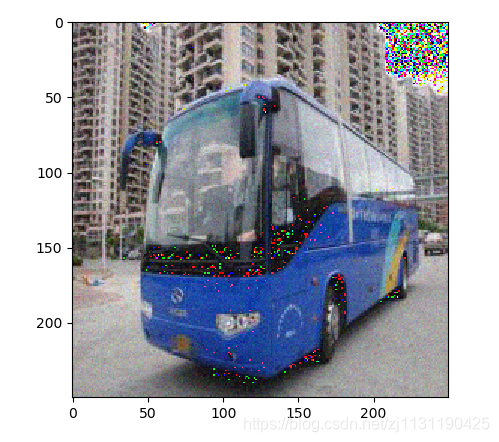
2.高斯噪声处理:
from PIL import Image, ImageFont, ImageDraw, ImageEnhance import matplotlib.pyplot as plt import numpy as np import random def image_gauss(image_path, save_path, mean, stddev): """ 对图像进行颜色抖动 :param image_path: :param save_path: :return: """ def gaussNoisy(pixel_array, mean, stddev): """ 对图像的单个通道进行高斯噪声处理 :param pixel_array: :param mean: 均值 :param stddev: 方差 :return: """ for x in pixel_array: x += random.gauss(mean, stddev) return pixel_array # 对图像进行数据转换 image = Image.open(image_path) image.convert("RGB") img = np.asarray(image) # 将PIL中的数据格式转化为array img.flags.writeable = True # 将数组改为读写模式 width, height = img.shape[: 2] img_r = img[:, :, 0].flatten() img_g = img[:, :, 1].flatten() img_b = img[:, :, 2].flatten() img_r_new = gaussNoisy(pixel_array=img_r, mean=mean, stddev=stddev) img_g_new = gaussNoisy(pixel_array=img_g, mean=mean, stddev=stddev) img_b_new = gaussNoisy(pixel_array=img_b, mean=mean, stddev=stddev) img[:, :, 0] = img_r_new.reshape([width, height]) img[:, :, 1] = img_g_new.reshape([width, height]) img[:, :, 2] = img_b_new.reshape([width, height]) image_new = Image.fromarray(np.uint8(img)) # 将array中的数据格式转化为PIL中的数据格式 image_new.save(save_path) return image_new



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)