

VGGNet原理及tensorflow实现
VGGNet介绍:
VGGNet是牛津大学计算机视觉组和Google DeepMind一起研发的卷积神经网络,VGGNet探索了卷积神经网络的深度与其性能之间的关系。VGG的结构特点是通过反复堆叠3x3的卷积核和2x2的max-pool, 与在其之前的卷积神经网络相比,错误率大大降低。同时,VGGNet扩展性强,迁移其他数据上的泛化能力好,因此VGGNe常被用来提取图像特征。
VGG各级别网络结构:
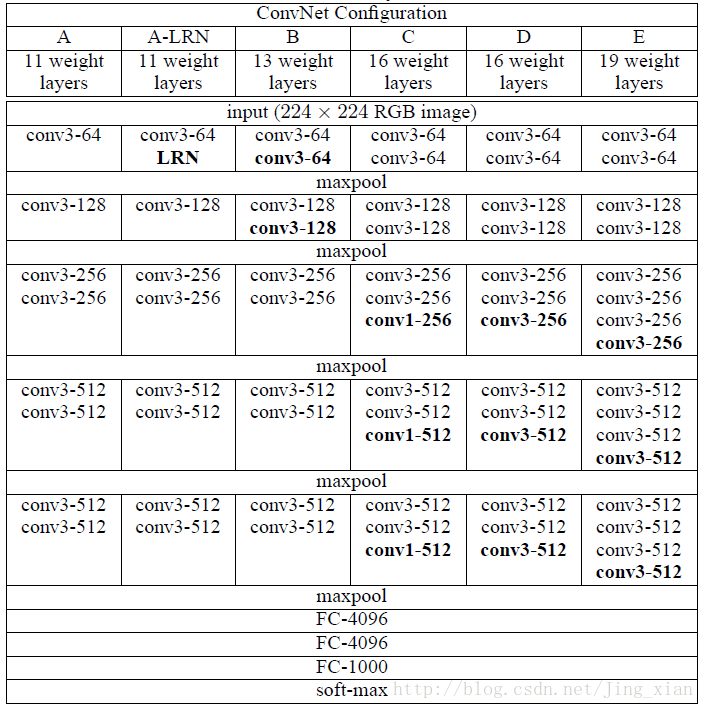
从上面的结构图可以看到。VGG拥有5段卷积,每一段内又2-3个卷积层,同时每一段的尾部会连接一个最大池化层,用于缩小图片的尺寸。可以看到VGG中经常出现多个完全一样的3x3的卷积核堆叠到一起,这种卷积层串联是一种非常有用的设计。两个3x3的卷积层串联相当于一个5x5的卷积层,也就是说一个像素会和周围5个像素产生关联,即感受野的大小是5x5,:
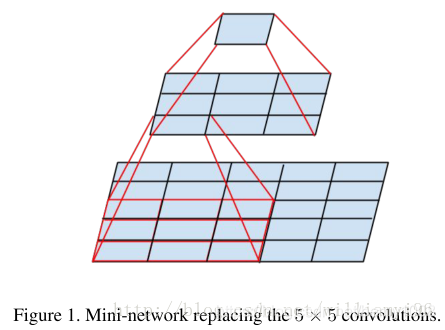
个人理解的两个3x3的卷积层串联相当于一个5x5的卷积层:
以手写字体图片为例,假设输入图像的尺寸为28x28, 则经过两个3x3的卷积层后:(假设padding="VALID", strides=1)
1. (28-3+1)/1 = 26
2. (26-3+1) / 1 = 24
同样大小的图像,经过一个5x5的卷积层之后:
1. (28-5+1)/1 = 24
而且多个小的卷积层串联有如下优势:
1.参数更少, 假设3个3x3x3的卷积层串联,参数的数量3x3xN+3x3xN+3x3xN=3x3x3xN,而一个7x7的卷积层的参数为7x7xN;
前者只有后者参数的(3x3x3xN)/(7x7xN)=55%.
2. 多个卷积层串联比一个卷积层拥有更多的非线性变换(三次使用激活函数),使得网络能够更好地学习特征。
VGG-16:
VGG-16 feature-map的维度如下所示:

VGG在训练时做数据增强的方法:
将原始图像缩放到不同的尺寸,然后再随机裁剪成224x224大小的图像,增加数据量,防止模型过拟合。(这一点和AlexNet中的数据增强方法类似, AlexNet中对裁剪得到的图象还进行了左右反转)。
对于VGG,同时有如下结论:
(1) LRN层的作用不大
(2) 越深的网络效果越好。
(3) 大一些的卷积核可以学习到更多的空间特征
关于1x1的卷积核的作用:
(参考博客:https://blog.csdn.net/wonengguwozai/article/details/72980828
https://www.jianshu.com/p/04c2a9ccaa75)
1. 实现跨通道的交互和信息整合
2. 进行卷积核通道数的降维和升维
3. 增加网络的非线性
3.对于单通道feature map 用单核卷积即为乘以一个参数,而一般情况都是多核卷积多通道,实现多个feature map的线性组合
VGG16的tensorflow代码:
数据用的是博客车型分类中的数据集:
(在车型分类中,已经对数据的处理和读取做了详细的介绍,代码正确,但是本人无法运行模型,只有笔记本囧)
import tensorflow as tf import math import time import os from tqdm import tqdm from PIL import Image, ImageDraw, ImageFont import numpy as np class Data: """ 读取训练集,验证集,测试集数据 """ def __init__(self, batch_size, data_path, val_data, test_data): """ :param batch_size: :param data_path: 训练数据路径 :param val_data: 验证集路径 :param test_data: 测试集路径 """ self.batch_size = batch_size self.data_path = data_path self.labels_name = [] self.val_data = val_data self.test_data = test_data # self.images = [] self.image_names = os.listdir(self.data_path) # 所有的图片集合 for name in tqdm(self.image_names): # image_path = os.path.join(self.data_path, name) # image = Image.open(image_path) # image = np.array(image) / 255.0 # 图像像素值归一化到0-1 """ 归一化的原因 1. 转换成标准模式,防止仿射变换的影响。 2、减小几何变换的影响。 3、加快梯度下降求最优解的速度。 """ # self.images.append(image) class_name = name.split('.')[0].split('_')[-1] self.labels_name.append(class_name) class_set = set(self.labels_name) self.labels_dict = {} for v, k in enumerate(class_set): self.labels_dict[k] = v print("Data Loading finished!") print("Label dict: ", self.labels_dict) self.labels = [self.labels_dict.get(k) for k in self.labels_name] # 将标签名转化为标签的编号 print("Label names: ", self.labels_name) print("Labels is: ", self.labels) def get_batch(self, count): """ get_batch函数按照batch将图片读入,因为一次读入全部图片会导致内存暴增 :param count: :return: """ start = count * self.batch_size end = (count + 1) * self.batch_size start_pos = max(0, start) end_pos = min(end, len(self.labels)) images_name_batch = self.image_names[start_pos: end_pos] images = [] # 存放图片 for images_name in images_name_batch: image_path = os.path.join(self.data_path, images_name) image = Image.open(image_path) image = np.array(image) / 255.0 # 图像像素值归一化到0-1 images.append(image) labels = self.labels[start_pos: end_pos] datas = np.array(images) labels = np.array(labels) return datas, labels def get_batch_num(self): return len(self.labels) // self.batch_size def get_batch_size(self): return self.batch_size def get_val_data(self): val_names = os.listdir(self.val_data) # 验证集图片 val_images = [] val_labels = [] for name in val_names: image_path = os.path.join(self.val_data, name) image = Image.open(image_path) image = np.array(image) / 255.0 # 图像像素值归一化到0-1 """ 归一化的原因 1. 转换成标准模式,防止仿射变换的影响。 2、减小几何变换的影响。 3、加快梯度下降求最优解的速度。 """ val_images.append(image) class_name_val = name.split('.')[0].split('_')[-1] val_labels.append(class_name_val) val_images = np.array(val_images) val_labels = [self.labels_dict.get(k) for k in val_labels] # 将标签名转化为标签的编号 val_labels = np.array(val_labels) return val_images, val_labels def get_label_dict(self): return self.labels_dict def get_test_info(self): """ 测试数据没有标签 :return: """ test_names = os.listdir(self.test_data) return self.test_data, test_names class Model: def __init__(self, input_size, learning_rate, keep_prob, class_num, lamb=0.01): self.input_size = input_size self.learning_rate = learning_rate self.keep_prob = keep_prob self.loss = 0 self.train_op = 0 self.losses = 0 self.lamb = lamb self.class_num = class_num def conv_op(self, input_tensor, name, kernel, stride, padding, train_flag): """ # 定义创建卷积层的函数 :param input_tensor: 输入的张量 [w, h, d] :param name: 卷积层名称 :param kernel: 卷积核的尺度 [宽度, 高度, 深度] :param stride: 卷积核移动的步长[w, h] :param padding: "SAME", "VALID" :return: """ depth = input_tensor.get_shape()[-1].value # 获取输入张量的深度 with tf.name_scope(name): filter = tf.get_variable(name=name + '_weight', shape=[kernel[0], kernel[1], depth, kernel[2]], dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer_conv2d()) # xavier_initializer会根据某一层网络的输入输出的节点数,自动调整最合适的分布 # xavier指出, 如果深度学习模型的权重初始化的太小,那么信号将在每层间传递时逐渐缩小而难以产生作用, # 权重太大将导致信号在每层之间传递时逐渐放大并导致发散和失效 # xavier_initializer让权重满足均值为0, 方差为2/(n_in, n_out),分布可以用均匀分布或者高斯分布 if train_flag: tf.add_to_collection('loss', tf.contrib.layers.l2_regularizer(self.lamb)(filter)) # 正则化 conv = tf.nn.conv2d(input=input_tensor, filter=filter, strides=[1, stride[0], stride[1], 1], padding=padding) biases = tf.get_variable(name=name + 'bias', shape=[kernel[2]], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) layer = tf.nn.relu(tf.nn.bias_add(value=conv, bias=biases), name=name + 'layer') return layer def fc_op(self, input_tensor, name, output_nodes, train_flag): """ 全连接层 :param input_tensor: 输入的张量 :param name: 名称 :param output_nodes: 输出节点的个数 :return: """ length = input_tensor.get_shape()[-1].value with tf.name_scope(name): weight = tf.get_variable(name=name + '_weight', shape=[length, output_nodes], dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer()) biases = tf.get_variable(name=name + '_bias', shape=[output_nodes], dtype=tf.float32, initializer=tf.constant_initializer(0.1)) out_put = tf.nn.bias_add(value=tf.matmul(input_tensor, weight), bias=biases) layer = tf.nn.relu(out_put) if train_flag: tf.add_to_collection("loss", tf.contrib.layers.l2_regularizer(self.lamb)(weight)) # L2正则化 layer = tf.nn.dropout(layer, keep_prob=self.keep_prob) return layer def maxpool_op(self, input_tensor, name, kernel, stride, padding): """ :param input_tensor: 输入张量 :param name: 名称 :param kernel: 核 [w, h] :param stride: 步长 [w, h] :param padding: “SAME" VALID :return: """ with tf.name_scope(name): layer = tf.nn.max_pool(value=input_tensor, ksize=[1, kernel[0], kernel[1], 1], strides=[1, stride[0], stride[1], 1], padding=padding, name=name + '_layer') return layer def inference(self, x, train_flag): """ :param x: 输入张量 :param train_flag: :return: """ # VGG的第一段是两个3x3的卷积层串联,再接一个池化层,卷积层的深度为64 conv1_1 = self.conv_op(input_tensor=x, name="conv1_1", kernel=[3, 3, 64], stride=[1, 1], padding="SAME", train_flag=train_flag) conv1_2 = self.conv_op(input_tensor=conv1_1, name="conv1_2", kernel=[3, 3, 64], stride=[1, 1], padding='SAME', train_flag=train_flag) pool1 = self.maxpool_op(input_tensor=conv1_2, name="pool_1", kernel=[2, 2], stride=[2, 2], padding='SAME') # 100 # VGG的第2段是两个3x3的卷积层串联,再接一个池化层,但是卷层的深度变成128 conv2_1 = self.conv_op(input_tensor=pool1, name="conv2_1", kernel=[3, 3, 128], stride=[1, 1], padding='SAME', train_flag=train_flag) conv2_2 = self.conv_op(input_tensor=conv2_1, name="conv2_2", kernel=[3, 3, 128], stride=[1, 1], padding='SAME', train_flag=train_flag) pool2 = self.maxpool_op(input_tensor=conv2_2, name="pool_2", kernel=[2, 2], stride=[2, 2], padding="SAME") # 50 # VGG的第3段是三个3x3的卷积层串联,再接一个池化层,但是卷层的深度变成256 conv3_1 = self.conv_op(input_tensor=pool2, name="conv3_1", kernel=[3, 3, 256], stride=[1, 1], padding="SAME", train_flag=train_flag) conv3_2 = self.conv_op(input_tensor=conv3_1, name="conv3_2", kernel=[3, 3, 256], stride=[1, 1], padding="SAME", train_flag=train_flag) conv3_3 = self.conv_op(input_tensor=conv3_2, name="conv3_3", kernel=[3, 3, 256], stride=[1, 1], padding='SAME', train_flag=train_flag) pool3 = self.maxpool_op(input_tensor=conv3_3, name="pool_3", kernel=[2, 2], stride=[2, 2], padding='SAME') # 25 # VGG的第四段,三个3x3的卷积层串联,再加一个最大池化层,卷积层通道数512 进一步加深网络的深度,减小图像的尺寸 conv4_1 = self.conv_op(input_tensor=pool3, name="conv4_1", kernel=[3, 3, 512], stride=[1, 1], padding='SAME', train_flag=train_flag) conv4_2 = self.conv_op(input_tensor=conv4_1, name="conv4_2", kernel=[3, 3, 512], stride=[1, 1], padding='SAME', train_flag=train_flag) conv4_3 = self.conv_op(input_tensor=conv4_2, name="conv4_3", kernel=[3, 3, 512], stride=[1, 1], padding='SAME', train_flag=train_flag) pool4 = self.maxpool_op(input_tensor=conv4_3, name="pool_4", kernel=[2,2], stride=[2, 2], padding='SAME') # 13 # VGG的第五段,三个3x3的卷积层串联,再加一个最大池化层,卷积层通道数512,步长1,池化层进一步缩小图像的尺寸 conv5_1 = self.conv_op(input_tensor=pool4, name="conv5_1", kernel=[3, 3, 512], stride=[1, 1], padding='SAME', train_flag=train_flag) conv5_2 = self.conv_op(input_tensor=conv5_1, name="conv5_2", kernel=[3, 3, 512], stride=[1, 1], padding='SAME', train_flag=train_flag) conv5_3 = self.conv_op(input_tensor=conv5_2, name="conv5_3", kernel=[3, 3, 512], stride=[1, 1], padding='SAME', train_flag=train_flag) pool5 = self.maxpool_op(input_tensor=conv5_3, name="pool_5", kernel=[2, 2], stride=[2, 2], padding='SAME') # 7 # 全连接层 pool5_shape = pool5.get_shape() nodes = pool5_shape[1].value * pool5_shape[2].value * pool5_shape[3].value # 计算节点数 pool5_flatten = tf.reshape(pool5, shape=[-1, nodes], name="pool5_flatten") fc1 = self.fc_op(input_tensor=pool5_flatten, name="fc1", output_nodes=4096, train_flag=train_flag) fc2 = self.fc_op(input_tensor=fc1, name='fc2', output_nodes=2048, train_flag=train_flag) # 输出 fc3 = self.fc_op(input_tensor=fc2, name='fc3', output_nodes=self.class_num, train_flag=train_flag) return fc3 # 网络输出 def train(self, data, train_step): with tf.name_scope("placeholder"): x = tf.placeholder(dtype=tf.float32, shape=[None, self.input_size[0], self.input_size[1], self.input_size[2]], name='x_input') y_ = tf.placeholder(dtype=tf.int32, shape=[None], name='y_input') inference_output = self.inference(x, train_flag=True) self.loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=inference_output, labels=y_, name='loss')) tf.add_to_collection('loss', self.loss) self.losses = tf.add_n(tf.get_collection('loss')) self.train_op = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(self.losses) with tf.Session() as sess: init_op = tf.group(tf.local_variables_initializer(), tf.global_variables_initializer()) sess.run(init_op) for step in range(train_step): batch_num = data.get_batch_num() total_loss = 0.0 for batch_count in tqdm(range(batch_num)): train_x, train_y = data.get_batch(batch_count) feed_dict = {x: train_x, y_: train_y} _, loss = sess.run([self.train_op, self.losses], feed_dict=feed_dict) total_loss += loss print("After {} step training the loss is {}".format(step, total_loss/batch_num)) if __name__ == "__main__": data_path = r"E:\back_up\NLP\course\rename_train_dr" # 训练集 val_data = r"E:\back_up\NLP\course\rename_val_dr" # 验证集 test_data = r"E:\back_up\NLP\course\rename_test" # 测试集 # model = r"E:\back_up\code\112\tensorflow_project\newbook\chapter6\model\model" # board = r"E:\back_up\code\112\tensorflow_project\newbook\chapter6\board_data" # test_result = r"E:\back_up\NLP\course\test_result" data = Data(batch_size=2, data_path=data_path, val_data=val_data, test_data=test_data) model = Model(input_size=[200, 200, 3], learning_rate=0.001, keep_prob=0.6, class_num=10) model.train(data=data, train_step=5)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)