算法设计 分治, 归并排序, 快速排序
算法思想:
分治方法与软件设计的模块化方法非常的相似。要解决一个大实例问题,可以(1)将它分解成多个更小的实例,(2)分别解决每个小实例,(3)将小实例的解组合成大实例的解。
例子:
寻找假硬币。一个袋子有16枚硬币,其中可能有一个假币,并且假币比真币要轻,现在要找出这个假币。
现在要找出假硬币,我们把两个或者三个硬币视为不可再分的小实例,只有一个硬币时,不能确定它的真假。
2. 金块问题:
从袋子中寻找出最重的和最轻的金块:希望用最少的比较次数找出最重和最轻的金块;
方法1: 使用max()函数经过n-1次比较,得到重量最大的,再通过n-2次比较得到重量最小的。共需要2n-3次比较
方法2:采用分治的方法:当金块的个数n较大的时候
第一步: 把金块先分成两部分A,B
第二步: 分别找出A,B中的最轻的和最重的金块, L_A,H_A, L_B,H_B
第三步: 比较L_A,L_B, 比较H_A,H_B
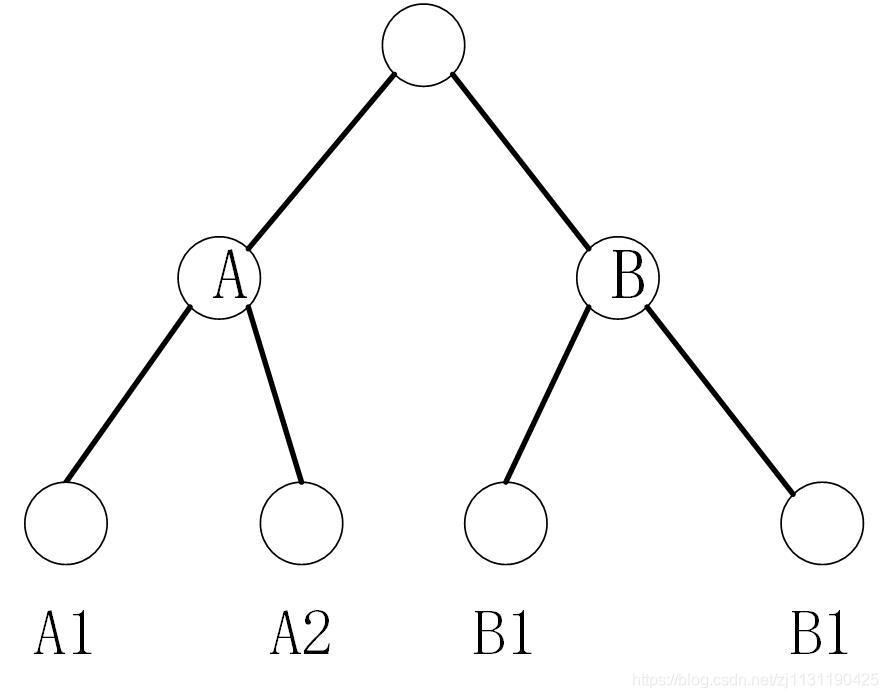
现在假设金块的数量n=8,整个比较的过程可以用下面的二叉树来描述:
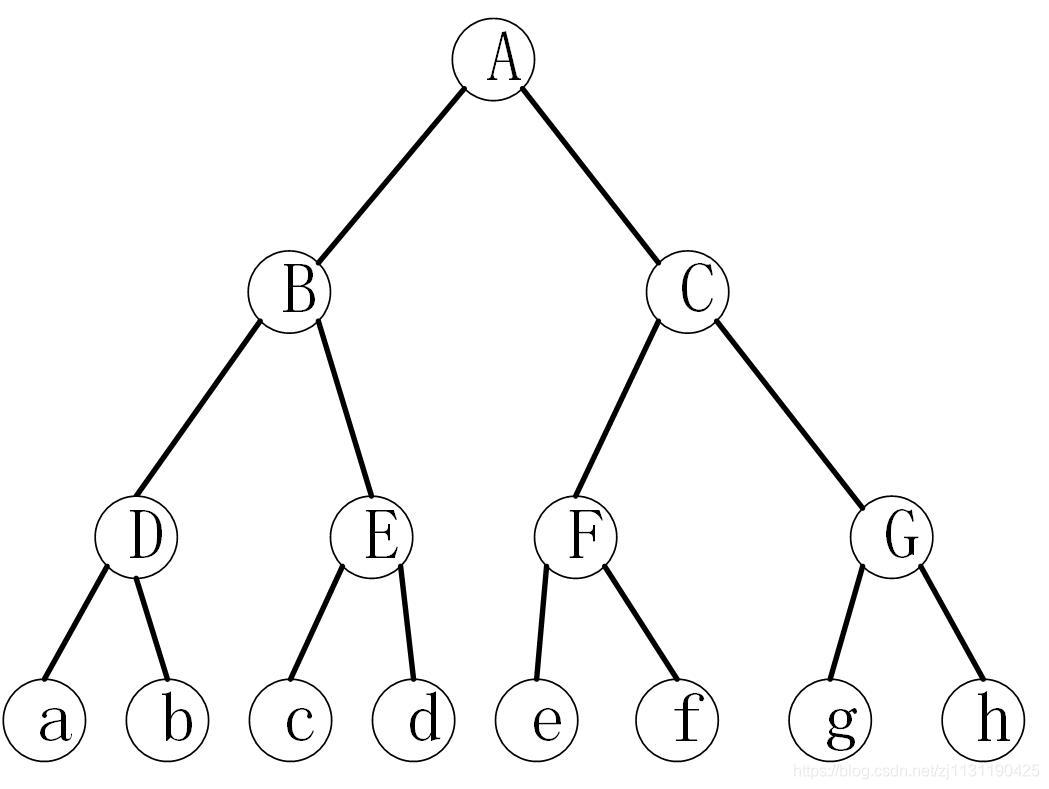
图中的每个大写字母代表的节点表示一个实例,实例中的金块的个数等于以该节点为根的子树的所有叶子。
1. 沿着根至叶子的路径,把一个大实例划分成若干个大小为1或者2的实例
2. 在每一个大小为2的实例中,比较确定哪一个较轻,哪一个较重(节点DEFG中),大小为1的实例既是最轻的,也是最重的
3. 对较轻的金块比较哪一块是最轻的,对较重的金块比较哪一块是最重的(节点ABC)
找出最大值和最小值的分治非递归算法:
template<typename T>
bool minmax(T a[], int n, int& minIndex, int& maxIndex)
{
// 元素个数
if(n<1)
{
return false;
}
if(n==1)
{
minIndex = 1;
maxIndex = 1;
return true;
}
// n>1的情况
int s = 1; // 比较的起点
if(n%2==1) // n奇数
{
minIndex = 0; // 这样是为了使得剩余的节点个数为偶数个
maxIndex = 0;
}
else
{
if(a[0]>a[1])
{
maxIndex = 0;
minIndex = 1;
}
else
{
maxIndex = 1;
minIndex = 0;
}
s = 2; // 比较的起点
}
// 比较剩余的元素 偶数和元素,每两个元素作为一个实例
for(int i=s; i<n; i+=2)
{
if(a[i]>a[i+1])
{
if(a[i]>a[maxIndex])
{
maxIndex = i;
}
if(a[i+1]<minIndex)
{
minIndex = i+1;
}
}
else
{
if(a[i]<a[minIndex])
{
minIndex = i;
}
if(a[i+1]>a[maxIndex])
{
maxIndex = i+1;
}
}
}
return true;
}在算法开始的时候首先处理n=1和n<1的情况:
1. 当n为偶数的时候,先比较数组的前两个元素,作为最大最小元素的候选者,剩余的元素个数为偶数,再进行比较。
2. 当n为奇数的时候,将数组的第0个元素作为候选的元素,剩余的元素个数也为偶数
3. 接下来比较剩余的偶数个元素
复杂度分析:
当n为偶数的时候,在for循环的外部,有一次比较,内部有(n/2-1)*3此比较
当n为奇数的时候,在for循环的外部没有比较,内部有(n-1)/2*3次比较
所以总的比较次数为: 【3n/2】-2次比较,这是在寻找最大最小值的算法中比较次数最小的算法
归并排序:
可以使用分治的方法设计排序算法,这种方法的思路是将序列划分为k个子序列(k>=2), 先对每一个子序列排序,然后将有序子序列归并为一个序列。
假设A组包含n/k个元素,B组包含其余的元素,递归的应用分治对A,B两个序列进行排序,然后采用归并的过程,将有序子序列归并为一个序列。
在k=2时的排序称为归并排序,更准确的说,是二路归并排序。
例如: 对于序列:【10, 4,6, 3, 8,2,5,7】,选定k=2, 则子序列[10,4,6,3]和[8.2.5.7]需要分别独立排序,得到两个有序的子序列,在将这两个有序的子序列进行合并。
伪代码如下所示:
void sort(E, n) // 对E中k个元素进行排序
{
if(n>=k)
{
i=n/k; // A的元素个数
j = n-i; // B的元素个数
sort(A, i);
sort(B, j);
merge(A,B,E,i,j); // 把AB合并到E中
}
else
{
对E进行插入排序
}
}归并n个元素所需的时间为O(n),假设t(n)为分治排序算法在最坏情况下的用时,则其递推公式为:
当两个小的实例所包含的元素个数近似相等时,分治算法通常具有最佳的性能。
在上面的递推公式中,取k=2, 且假设n为2的幂:
则递推公式可以简化为:
在n位其他数的时候,这个结论也适用:可以得到
这也是归并排序在最好和最坏情况下的时间复杂度;
归并排序的C++实现:
1. 一种方法可以将排序的元素存储到一个链表中,在n/2处将链表断开,分成两个大致相等的子链表。然后再将两个排序后的子链表归并到一起。
2. 使用数组存储元素
归并排序的非递归写法:
#include <iostream>
using namespace std;
// 归并排序:
/*
原理:
初始段: [8] [4] [5] [6] [2] [1] [7] [3]
归并到b [4, 8] [5, 6] [1, 2] [3, 7]
复制到a [4, 8] [5, 6] [1, 2] [3, 7]
归并到b [4 5 5 8] [1 2 3 7]
复制带a [4 5 5 8] [1 2 3 7]
归并到b [1 2 4 5 6 7 7 8]
复制到a [1 2 4 5 6 7 7 8]
*/
template<typename T>
void merge(T c[], T d[], int startOfFirst, int endOfFirst, int endOfSecond)
{
// 数据段a,b
int first = startOfFirst;
int second = endOfFirst+1;
int res = startOfFirst;
// 开始归并数据段
// 反复将c归并到d中,再将d归并到a中
while(first<=endOfFirst && second<=endOfSecond)
{
if(c[first]<=c[second])
{
d[res++] = c[first++];
}
else
{
d[res++] = c[second++];
}
}
// 归并剩余的字段
if(first>endOfFirst) // 此时first段已经完全归并了,则考虑归并second,如果second有剩余的话
{
for(int i=second; i<=endOfSecond; i++)
{
d[res++] = c[i];
}
}
else // 相反
{
for(int i=first; i<=endOfFirst; i++)
{
d[res++] = c[i];
}
}
}
template<typename T>
void mergePass(T x[], T y[], int n, int segment)
{
// 从x到y归并相邻的数据段
int i=0; // 数据段起始位置
while(i<=n-2*segment)
{
merge(x, y, i, i+segment-1, i+2*segment-1); // x, y 数据段1 :i起始位置, i+segment截至位置; 数据段2;结束位置: i+2*segment-1
i = i+2*segment;
}
// 少于两个满数据段
if(i+segment<n) // 少于两个数据段没有合并
{
merge(x, y, i, i+segment-1, n-1); // n-1是最后一个元素的位置
}
else // 只剩一个数据段
{
for(int j=i; j<n; j++)
{
y[j] = x[j];
}
}
}
template<typename T>
void mergeSort(T a[], int n)
{
T* b = new T[n];
int segmentSize = 1;
while(segmentSize<n)
{
mergePass(a, b, n, segmentSize);
segmentSize += segmentSize;
mergePass(b, a, n, segmentSize);
segmentSize += segmentSize;
}
delete []b;
}
int main(int argc, char *argv[])
{
int array[] = {8,4,5,6,2,1,7,3};
mergeSort(array, 8);
for(int i=0; i<8; i++)
{
cout << array[i] << " ";
}
cout << endl;
return 0;
}
快速排序:
用分治可以实现另一种排序方法,快速排序。把n个元素分为三段,left, middle, right,其中middle段仅有一个元素,left段中的元素都不大于中间段的元素,right段的元素都不小于middle段的元素。middle的元素称为支点。
算法思路:
1,从a[0:n-1]之间选择一个元素作为middle段
2. 把生于元素分成left和right两部分,是左段的元素都不大于middle,右段的元素都不小于middle。
3. 对left段递归快速排序
4. 对right段递归快速排序
C++实现:
#include <iostream>
using namespace std;
template<typename T>
void quickSort(T a[], int n)
{
// a[]排序数组 n 元素个数
if(n<=1)
{
return;
}
// 找到最大的元素, 将其放到数组最右端
int index = 0;
for(int i=1; i<n; i++)
{
if(a[i]>a[index])
{
index = i;
}
}
T temp = a[index];
a[index] = a[n-1];
a[n-1] = temp;
quickSort(a, 0, n-2); // 调用递归函数quickSort
}
template<typename T>
void quickSort(T a[], int leftend, int rightend)
{
// a[leftend:rightend]排序
if(leftend>=rightend)
{
return;
}
int leftCursor = leftend; // 从左到右移动搜索
int rightCursor = rightend+1; // 从右到左移动搜索
T pivot = a[leftend]; // 选择支点
while(1)
{
do // 寻找左侧不小于支点的元素
{
leftCursor++;
} while(a[leftCursor]<pivot);
do // 寻找优策不大于支点的元素
{
rightCursor--;
} while(a[rightCursor]>pivot);
if(leftCursor>=rightCursor)
{
break;
}
T temp = a[leftCursor];
a[leftCursor] = a[rightCursor];
a[rightCursor] = temp;
}
// 放置支点
a[leftend] = a[rightCursor];
a[rightCursor] = pivot;
// 递归调用quickSort()
quickSort(a, leftend, rightCursor-1);
quickSort(a, rightCursor+1, rightend);
}
int main(int argc, char *argv[])
{
int array[] = {8,4,5,6,2,1,7,3};
quickSort(array, 8);
for(int i=0; i<8; i++)
{
cout << array[i] << " ";
}
cout << endl;
return 0;
}
复杂度分析:
快速排序的平均复杂度是,其中n为元素的个数
各种排序算法的时间复杂度对比:
| 排序算法 | 最坏情况下性能 | 最好情况下性能 |
| 冒泡排序 | ||
| 计数排序 | ||
| 插入排序 | ||
| 选择排序 | ||
| 堆排序 | ||
| 归并排序 | ||
| 快速排序 |
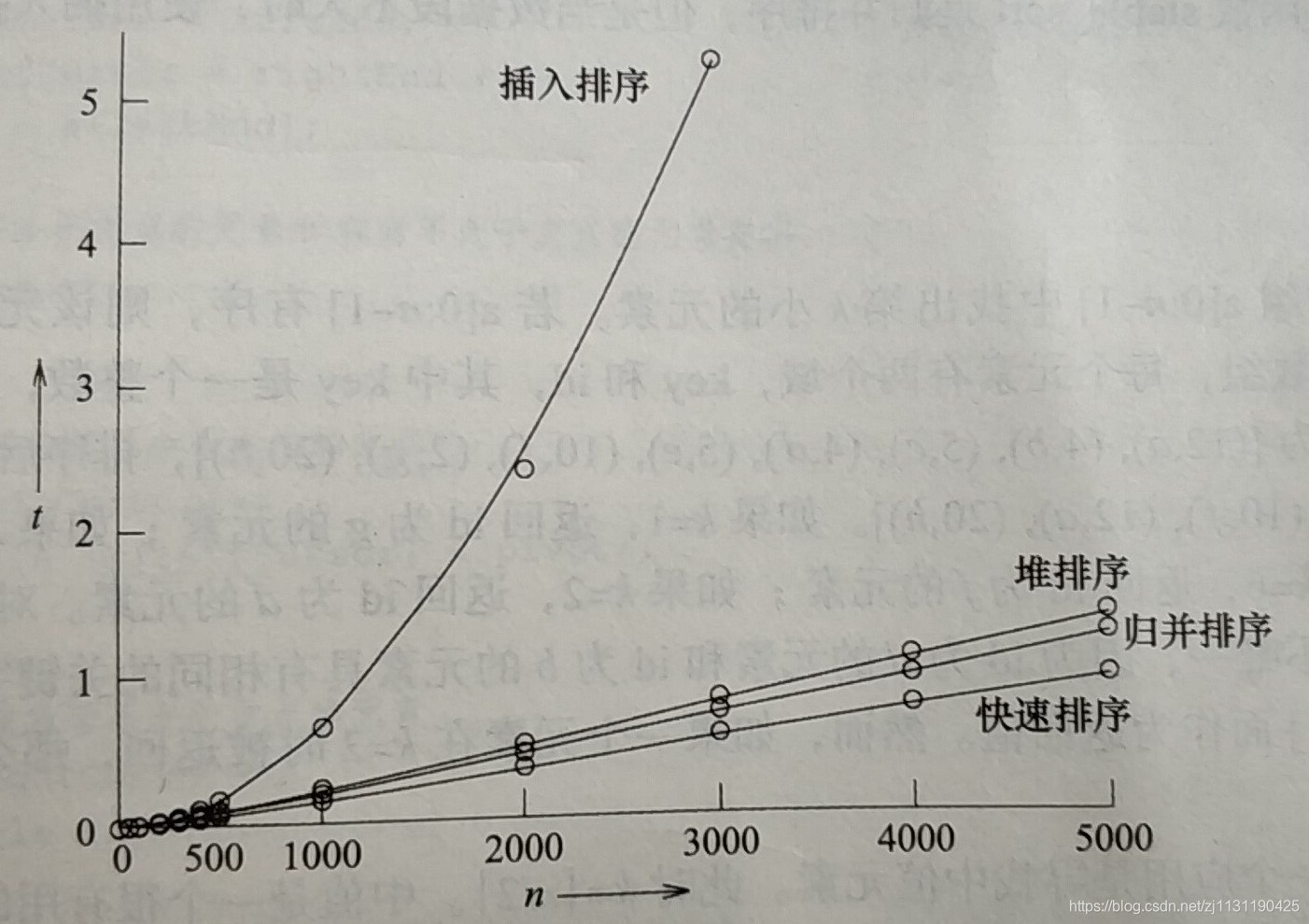
性能测量:

上图生成的曲线:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号