

c++知识整理 编程模块
最近开始看c++primer,做一点记录!
函数的基础知识:
要使用函数,必须完成:
1. 提供函数的定义
2.提供函数原型
3.调用函数
了解一下,函数是如何返回它的返回值:
函数会通过将返回值复制到指定的cpu寄存器或者内存单元中来将其返回,随后,调用程序将查看该内存单元,在这一过程中,返回函数和调用函数必须就该内存中存储的数据的类型达成一致,函数原型将返回值类型告知调用程序,而函数的定义决定被调函数应该返回什么类型的数据。在原型中提供与定义中相同的信息似乎有些多余,但是这样做确实有道理。例如要让信差从办公室的桌上取走一些物品,则向信差和办公室的同事都交代自己的意图,将提高信差完成这项工作的概率(C++ primer)
函数原型与函数定义:
函数原型: 即函数声明
函数定义: 函数的定义
1. c++中为什么需要提供函数原型
原型描述了函数到编译器的接口,也就是说,它将函数的返回值类型和参数的类型,数量告诉编译器。
例如函数原型:
double cube(double x);
首先,原型会告诉编译器cube()函数有一个double类型的参数,如果程序没有提供这样的参数,原型将让编译器能够捕获到这种错误。在cube()函数完成计算之后,将把返回值放到指定的位置(CPU寄存器或者内存中),然后调用函数(main()函数)将从这个指定的位置取得返回值,由于原型中指出了函数cube的返回值类型为double,因此编译器知道应该检索多少个字节以及如何解释它们。
这样做可以解决编译时的效率问题,如果没有函数原型,编译器在编译过程中在文件中查找函数的定义的话,会比较耗时,同时在查找的过程中会停止对main()函数的编译,而且函数很可能不在文件中,这样,编译器将无权访问函数代码。
所以,综上所述,原型可以确保以下几点:
1. 编译器正确处理函数的返回值
2. 编译器检查使用的参数数目是否正确
3. 编译器检查使用的参数类型是否正确
上述在编译阶段进行的原型化称为静态类型检查(static type checking)
函数和数组
数组做为函数的指针,将数组的首地址作为参数传递给函数,,节省可复制整个数组所需的内存空间和时间。尤其是在遇到大的数组的时候。
int sum(int array[], int size) { int M = sizeof array; // sizeof array返回的是指向数组元素的指针 的字节数(大小) // 指针本身并没有指出数组的长度 } int main(int argc, char *argv[]) { const int arraySize = 8; int cookies[arraySize] = {1,2,3,4,5,6,7,8}; int L = sizeof cookies; // 这里返回的是整个数组的长度(字节数) int total = sum(cookies, arraySize); return 0; }
由于上面的原因,所以数组作为函数参数的时候必须显式的传递数组的大小
// 可以选择数组的起始和结束的位置 int total = sum(cookies+3, 4); // 起始位置, 数组的长度
在数组作为函数的参数时,使用const保护数组:
函数使用普通参数时,这种保护机制将自动实现,因为参数按值传递,使用的是实参的副本,但是当参数为数组时,应该考虑如何避免参数被修改。
// 使用const保护数组参数 void show_array(const double arr[], int n);
使用const限制数组参数,这意味着原始数组不一定得是常量,而是意味着不能再show_array()函数中修改数组中元素的值。
将数组的区间作为参数传入函数,在STL中,使用 “超尾” 的概念来指定区间,如数组名是指向数组第一个元素的指针,数组大小i为n,则数组名+n是执行数组中最后一个元素的后一个位置,所以会有“超尾”这个概念。
例如对之前的sum()函数做修改:
#include <iostream> #include <algorithm> using namespace std; int sum(const int* begin, const int* end) { int total = 0; const int* pt; // pt指向常量的指针 for(pt=begin; pt<end; pt++) { total += *pt; } return total; } int main(int argc, char *argv[]) { const int arraySize = 8; int cookies[arraySize] = {1,2,3,4,5,6,7,8}; cout << sum(cookies, cookies+arraySize) << endl;; return 0; }
关于const对指针的限制:
1. 可以用const来修饰指针,让指针指向一个常量对象,防止使用指针来修改指向元素的值
但是要注意:const *pt这样的声明,并不意味着pt指向的值实际就是一个常量,而实意味着对pt而言,这个值是一个常量,不能y用pt来修改他:
int age = 20; // age不是一个常量 const int* pt = &age; // pt指向的age值是一个常量。不能修改: age += 10; // 可以修改age的值 *pt += 10; // 不能修改age的值
2.第二种使用const的方式使得无法修改指针的值:
int age = 20; // age不是一个常量 int* const pt = &age; // 指针不能被修改,只能指向age int sage = 80; pt = &sage; // 禁止这样修做!
3. 第三种,可以声明指向const对象的const指针:
int age = 20; // age不是一个常量 const int* const pt = &age; // 指针不能被修改,只能指向age,且不能通过指针修改age的值
函数,二维数组
// 理解二维数组作为函数参数的原理
int data[3][4] = {{1,2,3,4},{2,3,4,5},{5,6,7,8}}; int sum(int arr[][4], int size) { // 二维矩阵作为函数的参数 // 参数arr相当于一个指针 ,指向数组的第一个元素, //这个数组的每一个元素都有四个元素组成,所以需要传入二维数组的列数 //因此 arr[i]是一个由四个元素组成的数组的数组名 int total = 0; for(int i=0; i<size; i++) { for(j=0; j<4; j++) { total += arr[i][j]; } } return total; }
函数与c-风格字符串
包含字符,但是不以空值字符结尾的char类型的数组只是数组,而不是字符串。意味着不必将字符串的长度传递给函数。
#include <iostream> #include <algorithm> using namespace std; unsigned int c_in_str(const char* str, char target) // 寻找字符串中特定字符的个数 { unsigned int count = 0; while(*str) // != '\0' { if(*str == target) { count++; } str++; } return count; } int main(int argc, char *argv[]) { char ghost[15] = "helloworld"; char* str = "helloworld"; cout << c_in_str(ghost, 'o') << endl; cout << c_in_str(str, 'l') << endl; return 0; }
返回c-风格的字符串
#include <iostream> #include <algorithm> using namespace std; char* build_str(char ch, int n) { char* pstr = new char[n+1]; // new动态分配内存 pstr[n] = '\0'; // 字符串结尾 while(n> 0) { n--; pstr[n] = ch; } return pstr; } int main(int argc, char *argv[]) { char* p = build_str('M', 8); cout << p << endl; delete []p; // 释放内存 return 0; }
函数和结构体:
可以将一个结构赋值给另一个结构,也可以按值传递结构,就像普通变量一样。结构作为函数的参数,可以按值传递,但是按值传递的操作实际上函数中使用的是结构的副本(会将结构进行复制), 所以如果结构包含的数据量比较大的话,则复制结构需要增加内存需求,降低系统的运行速度。所以一般采用 pass by address 或者 pass by reference
#include <iostream> #include <algorithm> using namespace std; // 定义结构 struct travel_time { int hour; int minute; travel_time(int hour, int minute) { this->hour = hour; this->minute = minute; } travel_time() { this->hour = 0; this->minute = 0; } }; const int minutes_perH = 60; travel_time sum(travel_time, travel_time); // 计算时间之和 void show_time(travel_time); // 显示时间 int main(int argc, char *argv[]) { // travel_time time1 = {12, 45}; // 如果没有定义构造函数,则用这种方法初始化结构体 travel_time time1(12, 45); travel_time time2(1, 35); // 定义了构造函数的初始化方法 show_time(sum(time1, time2)); return 0; } travel_time sum(travel_time t1, travel_time t2) { travel_time total; total.minute = (t1.minute + t2.minute) % minutes_perH; total.hour = t1.hour + t2.hour + (t1.minute + t2.minute) / minutes_perH; return total; } void show_time(travel_time t) { cout << "The total time is: " << t.hour << ":" << t.minute << endl; }
坐标的转化:
#include <iostream> #include <algorithm> #include <cmath> using namespace std; struct rect { double x; double y; rect(double x, double y) { this->x = x; this->y = y; } rect() { this->x = 0; this->y = 0; } }; // 定义结构 struct polar { double dist; double angle; polar(double dist, double angle) { this->dist = dist; this->angle = angle; } polar() { this->dist = 0; this->angle = 0; } }; // prototype polar rect2polar(rect r) { polar p; p.dist = sqrt(r.x*r.x + r.y*r.y); p.angle = atan2(r.y, r.x); return p; } void show_polar(polar p) { const double rad2degree = 180.0/3.1415; cout << "The distance is " << p.dist << endl; cout << "The degree is " << p.angle*rad2degree << endl; } int main(int argc, char *argv[]) { rect r; polar p; cout << "Enter the rect.x and rect.y: "; while(cin >> r.x >> r.y) { p = rect2polar(r); show_polar(p); cout << "Next two numbers:(q to quit)"; } return 0; }
运行结果:

while(cin >> x >> y), cin是一个istream对象, cin >> x也是一个istream对象,因此cin >> x >> y最终返回的也是一个istream对象(cin), 而cin在被用于测试表达式中时,将根据输入是否成功,被转换为bool型的true和false.所以如果输入q, cin将知道输入不正确,从而q将被留在队列中,并返回一个被转换为false的值。
递归与分治:
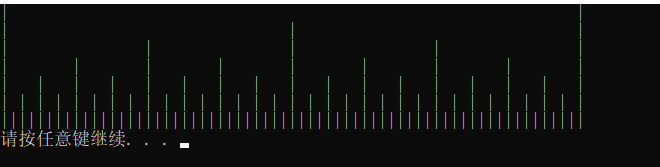
例:绘制标尺
#include <iostream> #include <algorithm> #include <cmath> using namespace std; // 绘制标尺 void subdivide(char ar[], int low, int high, int level) { // 递归函数, 采用分治的方法 if(level == 0) { return; } int mid = (low + high) / 2; ar[mid] = '|'; subdivide(ar, low, mid, level-1); subdivide(ar, mid, high, level-1); } int main(int argc, char *argv[]) { const int LEN = 66; const int divs = 6; char ruler[LEN]; // 初始化ruler ruler[LEN-1] = '\0'; for(int i=1; i<LEN-2; i++) { ruler[i] = ' '; } int min_index = 0; int max_index = LEN-2; ruler[min_index] = ruler[max_index] = '|'; cout << ruler << endl; for(int i=1; i<=divs; i++) { subdivide(ruler, min_index, max_index, i); cout << ruler << endl; // 将数组设置为空,以便进行下一次的分割 for(int j=1; j<LEN-2; j++) { ruler[j] = ' '; } } return 0; }
运行结果:
------------------------------------------------------------------分割线------------------------------------------------------------------


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)