开源ETL工具kettle系列之常见问题
开源ETL工具kettle系列之常见问题
摘要:本文主要介绍使用kettle设计一些ETL任务时一些常见问题,这些问题大部分都不在官方FAQ上,你可以在kettle的论坛上找到一些问题的答案
1. Join
我得到A 数据流(不管是基于文件或数据库),A包含field1 , field2 , field3 字段,然后我还有一个B数据流,B包含field4 , field5 , field6 , 我现在想把它们 ‘加’ 起来, 应该怎么样做.
这是新手最容易犯错的一个地方,A数据流跟B数据流能够Join,肯定是它们包含join key ,join key 可以是一个字段也可以是多个字段。如果两个数据流没有join key ,那么它们就是在做笛卡尔积,一般很少会这样。比如你现在需要列出一个员工的姓名和他所在部门的姓名,如果这是在同一个数据库,大家都知道会在一个sql 里面加上where 限定条件,但是如果员工表和部门表在两个不同的数据流里面,尤其是数据源的来源是多个数据库的情况,我们一般是要使用Database Join 操作,然后用两个database table input 来表示输入流,一个输入是部门表的姓名,另一个是员工表的姓名,然后我们认为这两个表就可以 ”Join” 了,我们需要的输出的确是这两个字段,但是这两个字段的输出并不代表只需要这两个字段的输入,它们之间肯定是需要一个约束关系存在的。另外,无论是在做 Join , Merge , Update , Delete 这些常规操作的时候,都是先需要做一个compare 操作的,这个compare 操作都是针对compare key 的,无论两个表结构是不是一样的,比如employee 表和department 表,它们比较的依据就是employee 的外键department_id , 没有这个compare key 这两个表是不可能连接的起来的.. 对于两个表可能还有人知道是直接sql 来做连接,如果是多个输入数据源,然后是三个表,有人就开始迷茫了,A表一个字段,B表一个字段,C表一个字段,然后就连Join操作都没有,直接 database table output , 然后开始报错,报完错就到处找高手问,他们的数据库原理老师已经在吐血了。如果是三个表连接,一个sql 不能搞定,就需要先两个表两个表的连接,通过两次compare key 连接之后得到你的输出,记住,你的输出并不能代表你的输入. 下面总结一下:
1. 单数据源输入,直接用sql 做连接
2. 多数据源输入,(可能是文本或是两个以上源数据库),用database join 操作.
3. 三个表以上的多字段输出.
2. Kettle的数据库连接模式
Kettle的数据库连接是一个步骤里面控制一个单数据库连接,所以kettle的连接有数据库连接池,你可以在指定的数据库连接里面指定一开始连接池里面放多少个数据库连接,在创建数据库连接的时候就有Pooling 选项卡,里面可以指定最大连接数和初始连接数,这可以一定程度上提高速度.
3. transaction
我想在步骤A执行一个操作(更新或者插入),然后在经过若干个步骤之后,如果我发现某一个条件成立,我就提交所有的操作,如果失败,我就回滚,kettle提供这种事务性的操作吗?
Kettle 里面是没有所谓事务的概念的,每个步骤都是自己管理自己的连接的,在这个步骤开始的时候打开数据库连接,在结束的时候关闭数据库连接,一个步骤是肯定不会跨session的(数据库里面的session), 另外,由于kettle是并行执行的,所以不可能把一个数据库连接打开很长时间不放,这样可能会造成锁出现,虽然不一定是死锁,但是对性能还是影响太大了。ETL中的事务对性能影响也很大,所以不应该设计一种依赖与事务方式的ETL执行顺序,毕竟这不是OLTP,因为你可能一次需要提交的数据量是几百 GB都有可能,任何一种数据库维持一个几百GB的回滚段性能都是会不大幅下降的.
4. 我真的需要transaction 但又不想要一个很复杂的设计,能不能提供一个简单一点的方式
Kettle 在3.0.2GA版中将推出一种新功能,在一个table output 步骤中有一个Miscellaneous 选项卡,其中有一个Use unique connections 的选项,如果你选中的话就可以得到一个transaction 的简单版,
由于是使用的单数据库连接,所以可以有错误的时候回滚事务,不过要提醒一点是这种方式是以牺牲非常大的性能为前提条件的,对于太大的数据量是不适合的(个人仍然不建议使用这种方式)
5. temporary 表如何使用
我要在ETL过程中创建一个中间表,当某个条件成立的时候,我要把中间表的数据进行转换,当另一条件成立的时候我要对中间表进行另一个操作,我想使用数据库的临时表来操作,应该用什么步骤。
首先从temp 表的生命周期来分,temp分为事务临时表和会话临时表,前面已经解释过了,kettle是没有所谓事务的概念的,所以自然也没有所谓的事务临时表。Kettle的每个步骤管理自己的数据库连接,连接一结束,kettle也就自然丢掉了这个连接的session 的handler , 没有办法可以在其他步骤拿回这个session 的handler , 所以也就不能使用所谓的会话临时表,当你尝试再开一个连接的时候,你可以连上这个临时表,但是你想要的临时表里面的数据都已经是空的(数据不一定被清除了,但是你连不上了),所以不要设计一个需要使用临时表的转换
之所以会使用临时表,其实跟需要 ”事务” 特性有一点类似,都是希望在ETL过程中提供一种缓冲。临时表很多时候都不是某一个源表的全部数据的镜像,很多时候临时表都是很小一部分结果集,可能经过了某种计算过程,你需要临时表无非是基于下面三个特性:
1. 表结构固定,用一个固定的表来接受一部分数据。
2. 每次连接的时候里面没有数据。你希望它接受数据,但是不保存,每次都好像执行了truncate table 操作一样
3. 不同的时候连接临时表用同一个名字,你不想使用多个连接的时候用类似与temp1 , temp2 , temp3 , temp4 这种名字,应为它们表结构一样。
既然临时表不能用,应该如何设计ETL过程呢?(可以用某种诡异的操作搞出临时表,不过不建议这样做罢了)
如果你的ETL过程比较的单线程性,也就是你清楚的知道同一时间只有一个这样的表需要,你可以创建一个普通的表,每次连接的时候都执行truncate 操作,不论是通过table output 的truncate table 选项,还是通过手工执行truncate table sql 语句(在execute sql script 步骤)都可以达到目的(基于上面的1,2 特性)
如果你的ETL操作比较的多线程性,同一时间可能需要多个表结构一样并且里面都是为空的表(基于上面1,2,3特性),你可以创建一个 “字符串+序列” 的模式,每次需要的时候,就创建这样的表,用完之后就删除,因为你自己不一定知道你需要多少个这种类型的表,所以删除会比truncate 好一些。
下面举个例子怎么创建这种表:
你可以使用某种约定的表名比如department_temp 作为department 的临时表。或者
把argument 传到表名,使用 department_${argument} 的语法,
如果你需要多个这种表,使用一个sequence 操作+execute sql script 操作,execute sql script 就下面这种模式
Create table_? (…………..)
在表的名字上加参数,前面接受一个sequence 或类似的输入操作.
需要注意的是这种参数表名包括database table input 或者execute sql script ,只要是参数作为表名的情况前面的输入不能是从数据库来的,应为没有办法执行这种preparedStatement 语句,从数据库来的值后面的操作是 “值操作” ,而不是字符串替换,只有argument 或者sequence 操作当作参数才是字符串替换. (这一点官方FAQ也有提到)
6. update table 和execute sql script 里面执行update 的区别
执行update table 操作是比较慢的,它会一条一条基于compare key 对比数据,然后决定是不是要执行update sql , 如果你知道你要怎么更新数据尽可能的使用execute sql script 操作,在里面手写update sql (注意源数据库和目标数据库在哪),这种多行执行方式(update sql)肯定比单行执行方式(update table 操作)快的多。
另一个区别是execute sql script 操作是可以接受参数的输入的。它前面可以是一个跟它完全不关的表一个sql :
select field1, field2 field3 from tableA
后面执行另一个表的更新操作:
update tableB set field4 = ? where field5=? And field6=?
然后选中execute sql script 的execute for each row .注意参数是一一对应的.(field4 对应field1 的值,
field5 对应field2 的值, field6 对应field3 的值)
7. kettle的性能
kettle本身的性能绝对是能够应对大型应用的,一般的基于平均行长150的一条记录,假设源数据库,目标数据库以及kettle都分别在几台机器上(最常见的桌面工作模式,双核,1G内存),速度大概都可以到5000 行每秒左右,如果把硬件提高一些,性能还可以提升 , 但是ETL 过程中难免遇到性能问题,下面一些通用的步骤也许能给你一些帮助.
尽量使用数据库连接池
尽量提高批处理的commit size
尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流)
Kettle 是Java 做的,尽量用大一点的内存参数启动Kettle.
可以使用sql 来做的一些操作尽量用sql
Group , merge , stream lookup ,split field 这些操作都是比较慢的,想办法避免他们.,能用sql 就用sql
插入大量数据的时候尽量把索引删掉
尽量避免使用update , delete 操作,尤其是update , 如果可以把update 变成先delete , 后insert .
能使用truncate table 的时候,就不要使用delete all row 这种类似sql
合理的分区
如果删除操作是基于某一个分区的,就不要使用delete row 这种方式(不管是delete sql 还是delete 步骤),直接把分区drop 掉,再重新创建
尽量缩小输入的数据集的大小(增量更新也是为了这个目的)
尽量使用数据库原生的方式装载文本文件(Oracle 的sqlloader , mysql 的bulk loader 步骤)
尽量不要用kettle 的calculate 计算步骤,能用数据库本身的sql 就用sql ,不能用sql 就尽量想办法用procedure , 实在不行才是calculate 步骤.
要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log 生成的方式来了解你的ETL操作最慢的地方。
远程数据库用文件+FTP 的方式来传数据 ,文件要压缩。(只要不是局域网都可以认为是远程连接)
8. 描述物理环境
源数据库的操作系统,硬件环境,是单数据源还是多数据源,数据库怎么分布的,做ETL的那台机器放在哪,操作系统和硬件环境是什么,目标数据仓库的数据库是什么,操作系统,硬件环境,数据库的字符集怎么选,数据传输方式是什么,开发环境,测试环境和实际的生产环境有什么区别,是不是需要一个中间数据库(staging 数据库) ,源数据库的数据库版本号是多少,测试数据库的版本号是多少,真正的目标数据库的版本号是多少……. 这些信息也许很零散,但是都需要一份专门的文档来描述这些信息,无论是你遇到问题需要别人帮助的时候描述问题本身,还是发现测试环境跟目标数据库的版本号不一致,这份专门的文档都能提供一些基本的信息
9. procedure
为什么我不能触发procedure?
这个问题在官方FAQ里面也有提到,触发procedure 和 http client 都需要一个类似与触发器的条件,你可以使用generate row 步骤产生一个空的row ,然后把这条记录连上procedure 步骤,这样就会使这条没有记录的空行触发这个procedure (如果你打算使用无条件的单次触发) ,当然procedure 也可以象table input 里面的步骤那样传参数并且多次执行.
另外一个建议是不要使用复杂的procedure 来完成本该ETL任务完成的任务,比如创建表,填充数据,创建物化视图等等.
10. 字符集
Kettle使用Java 通常使用的UTF8 来传输字符集,所以无论你使用何种数据库,任何数据库种类的字符集,kettle 都是支持的,如果你遇到了字符集问题,也许下面这些提示可以帮助你:
1. 单数据库到单数据库是绝对不会出现乱码问题的,不管原数据库和目标数据库是何种种类,何种字符集
2. 多种不同字符集的原数据库到一个目标数据库,你首先需要确定多种源数据库的字符集的最大兼容字符集是什么,如果你不清楚,最好的办法就是使用UTF8来创建数据库.
3. 不要以你工作的环境来判断字符集:现在某一个测试人员手上有一个oracle 的基于xxx 字符集的已经存在的数据库,并且非常不幸的是xxx 字符集不是utf8 类型的,于是他把另一个基于yyy字符集的oracle 数据库要经过某一个ETL过程转换到oracle , 后来他发现无论怎么样设置都会出现乱码,这是因为你的数据库本身的字符集不支持,无论你怎么设置都是没用的. 测试的数据库不代表最后产品运行的数据库,尤其是有时候为了省事把多个不同的项目的不相关的数据库装在同一台机器上,测试的时候又没有分析清楚这种环境,所以也再次强调描述物理环境的重要性.
4. 你所看到的不一定代表实际储存的:mysql 处理字符集的时候是要在jdbc 连接的参数里面加上字符集参数的,而oracle 则是需要服务器端和客户端使用同一种字符集才能正确显示,所以你要明确你所看到的字符集乱码不一定代表真的就是字符集乱码,这需要你检查在转换之前的字符集是否会出现乱码和转换之后是否出现乱码,你的桌面环境可能需要变动一些参数来适应这种变动
5. 不要在一个转换中使用多个字符集做为数据源.
11. 预定义时间维
Kettle提供了一个小工具帮助我们预填充时间维,这个工具在kettle_home / samples / transformations / General – populate date dimension. 这个示例产生的数据不一定能满足各种需要,不过你可以通过修改这个示例来满足自己的需求.
12. SQL tab 和 Options tab
在你创建一个数据库连接的时候除了可以指定你一次需要初始化的连接池参数之外(在 Pooling 选项卡下面),还包括一个Options 选项卡和一个 SQL 选项卡, Options 选项卡里面主要设置一些连接时的参数,比如autocommit 是on 还是off , defaultFetchSize , useCursorFetch (mysql 默认支持的),oracle 还支持比如defaultExecuteBatch , oracle.jdbc.StreamBufferSize, oracle.jdbc.FreeMemoryOnEnterImplicitCache ,你可以查阅对应数据库所支持的连接参数,另外一个小提示:在创建数据库连接的时候,选择你的数据库类型,然后选到Options 选项卡,下面有一个Show help text on options usage , 点击这个按钮会把你带到对应各个数据库的连接参数的官方的一个参数列表页面,通过查询这个列表页面你就可以知道那种数据库可以使用何种参数了.
对于SQL 选项卡就是在你一连接这个Connection 之后,Kettle 会立刻执行的sql 语句,个人比较推荐的一个sql 是执行把所有日期格式统一成同一格式的sql ,比如在oracle 里面就是:
alter session set nls_date_format = xxxxxxxxxxxxx
alter session set nls_xxxxxxxxx = xxxxxxxxxxxx
这样可以避免你在转换的时候大量使用to_date() , to_char 函数而仅仅只是为了统一日期格式,对于增量更新的时候尤其适用.
13. 数据复制
有的时候可能我们需要的是类似数据复制或者一个备份数据库,这个时候你需要的是一种数据库私有的解决方案,Kettle 也许并不是你的第一选择,比如对于Oracle 来说,可能rman , oracle stream , oracle replication 等等, mysql 也有mysql rmaster / slave 模式的replication 等私有的解决方法,如果你确定你的需求不是数据集成这方面的,那么也许kettle 并不是一个很好的首选方案,你应该咨询一下专业的DBA人士也会会更好.
14. 如何控制版本变更
Kettle 的每一个transformation 和job 都有一个version 字段(在你保存的时候), 不过这个功能还不实用,如果你需要版本控制的话,还是建议你将transformation 和job 转换成文本文件保存,然后用svn 或cvs 或任意你熟悉的版本控制系统将其保存,kettle 将在下一个版本加入版本控制的功能(做的更易用).
15. 支持的数据源
Kettle 支持相当广的数据源,比如在数据库里面的一些不太常见的Access , MaxDB (SAP DB) , Hypersonic , SAP R/3 system , Borland Interbase , Oracle RDB , Teradata和3.0新加入的Sybase IQ .
另外还包括Excel , CSV , LDAP ,以及OLAP Server Mondrian , 目前支持Web Service 不过暂时还不支持SOAP.
16. 调试和测试
当ETL转换出现不可预知的问题时,或是你不清楚某个步骤的功能是什么的情况下,你可能需要创建一个模拟环境来调适程序,下面一些建议可能会有所帮助:
尽量使用generate row 步骤或者固定的一个文本文件来创建一个模拟的数据源
模拟的数据源一定要有代表性,数据集一定尽量小(为了性能考虑)但是数据本身要足够分散.
创建了模拟的数据集后你应该清楚的知道你所要转换之后的数据时什么样的.
17. 错误处理
在ETL任务中由于数据问题出现转换错误是一件非常正常的事情,你不应该设计一个依赖于临时表或者拥有事务特点的ETL过程,面对数据源质量问题的巨大挑战,错误处理是并不可少的,kettle同样提供非常方便的错误处理方式,在你可能会出错的步骤点击右键选择Define Error handing , 它会要求你指定一个处理error 的步骤,你可以使用文本文件或者数据库的表来储存这些错误信息,这些错误信息会包含一个id 和一个出错的字段,当你得到这些错误信息之后就需要你自己分析出错的原因了,比如违反主键约束可能是你生成主键的方式有错误或者本身的数据有重复,而违反外键约束则可能是你依赖的一些表里面的数据还没有转换或者外键表本身过滤掉了这些数据. 当你调整了这些错误之后,确定所有依赖的数据都被正确的处理了.kettle user guide 里面有更详细的解释,里面还附带了一个使用javascript 来处理错误的示例,这种方式可以作为处理简单数据质量的方式.
18. 文档,文档,文档
Kettle 提供了丰富的文档和使用手册,小到一个数据库连接怎么连,大到一个功能怎么实现,所有的参数列表,对话框的每一个输入输出代表什么意思都有解释,所以当你遇到问题你应该第一时间翻阅这些文档,也许上面已经告诉你怎么做了. 另外kettle 还有一个非常活跃的社区,你可以到上面提问,但是记住在你提问之前先搜索一下论坛看有没有类似的问题已经问过了,如果没有记得描述清楚你的问题
总结
本系列文章主要讨论了如何使用kettle 来处理数据仓库中的缓慢增长维,动态ETL如何设计,增量更新的一些设计技巧,在应用程序中如何集成kettle 以及在使用kettle 时的一些常见问题. 如果你正在寻找一个工具来帮助你解决数据库的集成问题或是你打算建立一个商业智能项目的数据仓库,那么kettle是一个不错的选择,你不用支付任何费用就可以得到很多很多数据集成的特性,大量文档和社区支持. 难道这些不就是你希望从一个商业工具上的到的吗?还在等什么 ,开始你的数据集成之旅吧
开源ETL工具kettle系列之在应用程序中集成
摘要:本文主要讨论如何在你自己的Java应用程序中集成Kettle
如果你需要在自己的Java应用程序中集成Kettle , 一般来说有两种应用需求,一种是通过纯设计器来设计ETL转换任务,然后保存成某种格式,比如xml或者在数据库中都可以,然后自己调用程序解析这个格式,执行这种转换,是比较抽象的一种执行方式,ETL里面转换了什么东西我们并不关心,只关心它有没有正常执行。另一种是通过完全编程的方式来实现,详细的控制每一个步骤,需要知道转换执行的成功与否,这种方式可能需要更多的理解kettle的API 以便更好的跟你的应用程序紧密结合,不过难度也比较大,可以很好的定制你的应用程序,代价自然是入门门槛比较高。本文主要向你解释第一种Kettle的集成方式,文中所列出的代码节选自pentaho ,不过应用程序本身跟pentaho 没有什么关系。
Pentaho 集成kettle的代码主要是两个类,KettleSystemListener和 KettleComponent,看名字就猜出KettleSystemListener 主要是起监听器的作用,它主要负责初始化kettle的一些环境变量,这个类主要包含四个方法: startup() , readProperties(),environmentInit(),shutdown(),程序入口自然是startup()方法,然后它会调用 environmentInit() 方法,这个方法就调用readProperties()方法读一个配置文件kettle.properties,这个文件主要记录者kettle运行时可以调用的一些环境变量,关于kettle.properties文件怎么用,第二篇文章“使用Kettle设计动态转换”有提到,readProperties()方法读完这个文件之后就把里面的键值对转换成变量传给kettle运行环境.当kettle运行完了之后就调用 shutdown()方法结束转换. KettleSystemListener相对逻辑比较简单,就不多介绍,下面主要介绍重点类:
KettleComponent
KettleComponent的方法主要有三种类型,一类是用来初始化工作,做一些验证工作,第二类是执行转换的方法,也是主要需要讨论的方法,第三类是取得数据结果的,有时候你需要得到转换的结果交给下一个步骤处理.下面分别讨论这三类方法。
初始化
KettleComponent的初始化工作主要是验证这个转换,包括有 validateSystemSettings(),init(),validateAction(),全部都是public 方法,validateSystemSettings()会检查kettle 使用何种方式来连接资源库。
kettle有两种方式连接资源库,一种是纯数据库式,也就是你所有的转换全部都保存在一个数据库中,一般你在开始使用kettle的时候,它都会要求你建立一个资源仓库,这个资源仓库的连接方式就是你的数据库连接,你需要能够有相应的数据库驱动和对应的连接用户名和密码。另外一种连接方式是使用文本文件,也就是xml文件,在做完任何转换之后,我们都可以把转换或者Job变成xml文件输出,这个输出文件包含你所有转换的全部信息。
在示例应用中使用的是文件的连接方式,下面看一下初始化的一段代码:
Boolean useRepository = PentahoSystem.getSystemSetting("kettle/settings.xml",
"repository.type","files").equals("rdbms");
PentahoSystem.getSystemSetting()方法只是返回一个字符串,使用的xpath读一个xml的对应字段,下面列出settings.xml文件:
<kettle-repository>
<!-- The values within <properties> are passed directly to the Kettle Pentaho components. -->
<!-- This is the location of the Kettle repositories.xml file, leave empty if the default is used: $HOME/.kettle/repositories.xml -->
<repositories.xml.file></repositories.xml.file>
<repository.type>files</repository.type>
<!-- The name of the repository to use -->
<repository.name></repository.name>
<repository.userid>admin</repository.userid>
<repository.password>admin</repository.password>
</kettle-repository>
可以看到其中的repositories.xml.file 上面的一段注释,如果这个值为空会默认使用$HOME/.kettle/repository.xml文件当作资源库的连接文件,由于示例中使用的是文本文件所以没有用数据库连接,下面的repository.userid和repository.password是指的kettle的资源库连接的用户名和密码,一般默认安装就两个,admin/admin 和guest/guest , 这里的用户名和密码不是连接数据库的用户名和密码,连接数据库的用户名和密码是在另外一个文件repositories.xml.file指定的值所定义的
一般默认的kettle安装并且运行了一段时间之后,会在$HOME/.kettle 目录下创建一些文件,如果你要在自己的系统中集成kettle的话,也需要保留这些文件,当然不一定位置是在原来的位置,关键是要让kettle知道这些文件放在哪。
执行转换
当读完了这些配置文件并且验证了之后,KettleComponent就开始把前面读到的转换文件或者资源库类型变成Kettle的API,这主要是在executeAction()方法里面进行,它当然根据连接方式也分两种执行类型:
1. 文本执行方式
2. 资源库连接方式
文本执行方式需要接受一个你指定的运行转换的文件或者Job的文件,然后把这个xml文件解析成Kettle能够执行的模式,
根据执行的类型又可以分成两种:
1. Trans任务
2. Job任务
两个执行的逻辑差不多,下面先介绍Trans的执行方式:
执行Trans任务
transMeta = new TransMeta(fileAddress, repository, true);
transMeta.setFilename(fileAddress);
然后它会调用:
executeTransformation(TransMeta transMeta, LogWriter logWriter)
这个方法是真正的把前面的来的transMeta转换成trans对象,等待下一步的执行:
Trans trans = new Trans(logWriter, transMeta);
List stepList = trans.getSteps();
for (int stepNo = 0; stepNo < stepList.size(); stepNo++) {
StepMetaDataCombi step = (StepMetaDataCombi) stepList.get(stepNo);
if (step.stepname.equals(stepName)) {
① Row row = transMeta.getStepFields(stepName);
// create the metadata that the Pentaho result set needs
String fieldNames[] = row.getFieldNames();
String columns[][] = new String[1][fieldNames.length];
for (int column = 0; column < fieldNames.length; column++) {
columns[0][column] = fieldNames[column];
}
② MemoryMetaData metaData = new MemoryMetaData(columns, null);
results = new MemoryResultSet(metaData);
// add ourself as a row listener
③ step.step.addRowListener(this);
foundStep = true;
break;
}
}
1. Row对象是kettle用来表示一行数据的标准对象,跟jdbc取出来的一条数据转化后成为的一个POJO是一样的。里面可以包含多个字段。
2 . MemoryMetaData对象是pentaho特有的,是专门用来返回ETL任务执行后的结果的,与标准的JDBC里面的resultSet 对应的resultSetMetaData 是一样的。
3. 对于如何处理数据的一个Listener,实现的是一个RowListener,数据是每一行每一行处理的,后面会介绍如果需要输出数据怎么取得这些输出数据。如果不需要放回任何对象,则从1处开始都可以不要,只要初始化step对象即可。
所有的step对象都已经初始化之后就可以开始执行了,
trans.startThreads();
trans.waitUntilFinished();
结束之后还有一些清理工作就不列出了。
执行Job任务
执行Job任务之前还是会读取Job任务的描述文件,然后把这个描述文件(kettle的 .ktr文件)变成一个xml文档的dom :
org.w3c.dom.Document doc = XmlW3CHelper.getDomFromString(jobXmlStr);
之后也是初始化对应的元数据对象JobMeta
jobMeta = new JobMeta(logWriter, doc.getFirstChild(), repository);
得到了jobMeta 之后就可以执行这个Job了,这里跟trans是一样的。
job = new Job(logWriter, StepLoader.getInstance(), repository, jobMeta);
由于Job一般都没有什么返回值,所以Job不需要初始化它下面的对象,直接开始运行就可以了
job.start();
job.waitUntilFinished(5000000);
连接资源库
连接资源库使用的是connectToRepository()方法,先取得RepositoriesMeta对象,然后根据你在setting.xml文件里面定义的repository的名字来连接对应的repository.理论上来说我们一般都只使用一个 repository ,但如果在产品中需要使用多个repository的话,你需要自己配置多个repository的名字和对应的用户名和密码。只列出几行关键代码,
repositoriesMeta = new RepositoriesMeta(logWriter);
repositoriesMeta.readData(); // 从$HOME/.kettle/repositories.xml 读数据.
repositoryMeta = repositoriesMeta.findRepository(repositoryName);
repository = new Repository(logWriter, repositoryMeta, userInfo);
userInfo = new UserInfo(repository, username, password);
从资源库读取Trans
连接到资源库之后自然是想办法读取数据库的表,把里面的记录转换成为Trans 对象,使用的是loadTransformFromRepository,这个方法的函数原型需要解释一下:
TransMetaloadTransformFromRepository(String directoryName, String transformationName, Repository repository,LogWriter logWriter)
第一个参数String directoryName 代表是你储存转换的目录,当你使用kettle 图形界面的时候,点击repository菜单的explorer repository , 你会发现你所有的东西都是存储在一个虚拟的类似与目录结构的地方,其中包括database connections , transformations , job , users 等,所以你需要的是指定你连接的目录位置,你也可以在目录里面再创建目录。
String transformationName 自然指的就是你转换的名字.
Repository repository 指的是你连接的资源库。
LogWriter logWriter 指定你的日志输出,这个log 指的是你kettle 转换的日志输出,不是应用程序本身的输出。
读取TransMeta的步骤也相对比较简单
repositoryDirectory=repository.getDirectoryTree().findDirectory(directoryName);
transMeta = new TransMeta(repository, transformationName, repositoryDirectory);
从资源库读取Job
从资源库读取Job跟Trans 的步骤基本是一样的,同样需要指定你存储Job的目录位置.
JobMeta loadJobFromRepository(String directoryName, String jobName,
Repository repository, LogWriter logWriter)
读取结果集
一般Job都是不会返回任何结果集的,大部分Trans也不会返回结果集,应为结果集一般都会直接从一个数据库到另一个数据库了,但是如果你需要返回转换的结果集,那么这一小结将会向你解释如何从一个Trans里面读取这些结果集
首先,你需要一个容纳Result的容器,就是类似与JDBC里面的resultSet, resultSet当然会有一个resultSetMetadata跟它相关联,在本文所举的实例中,使用的是pentaho私有的memoryResultSet,
你可以不用关心它的细节,并且它的类型正如它的名字一样是存在与Memory的,所以它不能被持久化,这个里面储存的是一个二维的Object数组,里面的数据就是从kettle转化之后来的。
要从kettle的转换中读取结果集,要实现RowListener 接口,Row 是kettle里面表示一行数据的一个类,RowListener 自然是指在转换数据转换的时候发生的事件,它有三个方法需要实现,
void rowReadEvent(Row)
void rowWrittenEvent(Row)
void errorRowWrittenEvent(Row)
分别对应读数据时的事件,写数据事的时间,出错时的时间,我们需要取得结果集,所以只需要实现rowWrittenEvent(Row)就可以了,Row对象是通过TransMeta取得的,
Row row = transMeta.getStepFields(stepName);
下面给出具体实现取Row转换成resultSet的代码:
Object pentahoRow[] = new Object[results.getColumnCount()];
for (int columnNo = 0; columnNo < results.getColumnCount(); columnNo++) {
Value value = row.getValue(columnNo);
switch (value.getType()) {
case Value.VALUE_TYPE_BIGNUMBER:
pentahoRow[columnNo] = value.getBigNumber();
break;
........
results.addRow(pentahoRow);
默认的数据类型是String 类型(在省略部分).
整个代码最重要的一行是Value value = row.getValue(columnNo);
这是真正取得实际数据的一行。有时候你会觉得实现一个resultSet比较麻烦,尤其是你还要实现相关的resultSetMetaData,怎么把数据转换成你自己的类型,你大可以就用一个List of List 来实现,里面的List 就代表Row 的对应数据,外面一层List 就是result , 整个代码会简单一些,当然,你要自己知道最后这个List怎么用.
本文有意隐藏了一些跟pentaho有关的细节,比如 validateSystemSettings(),init(),validateAction()方法,这些都是pentaho私有的,有些方法比如 rowWrittenEvent(Row) 是用来取结果集的,但是很多时候我们不需要取转换的结果集,文中很多代码都只列出主要的部分,省略一些判断,调试,log部分的代码,大家可以自己下载这些代码来研究,
本文并没有给出一个可以独立运行的示例,因为这个示例一定会太过于简单(不超过15行代码),但是却并不能考虑到各种情况,连接资源库还是文件,运行转换还是Job ,metadata怎么得来的,需不需要转换之后的结果。
关于在本文一开始提到的使用kettle的两种方式,对于第二种使用方式:使用完全编程的方式来运行转换,其实它的与第一种方式的区别就好像一个用设计器来写xml文件,一个用纯手工方式写xml文件(用代码的xml),大家可以参考官方网站上的一段示例代码,地址如下:
http://kettle.pentaho.org/downloads/api.php
开源ETL工具kettle系列之增量更新设计
ETL中增量更新是一个比较依赖与工具和设计方法的过程,Kettle中主要提供Insert / Update 步骤,Delete 步骤和Database Lookup 步骤来支持增量更新,增量更新的设计方法也是根据应用场景来选取的,虽然本文讨论的是Kettle的实现方式,但也许对其他工具也有一些帮助。本文不可能涵盖所有的情况,欢迎大家讨论。
应用场景
增量更新按照数据种类的不同大概可以分成:
1. 只增加,不更新,
2. 只更新,不增加
3. 即增加也更新
4. 有删除,有增加,有更新
其中1 ,2, 3种大概都是相同的思路,使用的步骤可能略有不同,通用的方法是在原数据库增加一个时间戳,然后在转换之后的对应表保留这个时间戳,然后每次抽取数据的时候,先读取这个目标数据库表的时间戳的最大值,把这个值当作参数传给原数据库的相应表,根据这个时间戳来做限定条件来抽取数据,抽取之后同样要保留这个时间戳,并且原数据库的时间戳一定是指定默认值为sysdate当前时间(以原数据库的时间为标准),抽取之后的目标数据库的时间戳要保留原来的时间戳,而不是抽取时候的时间。
对于第一种情况,可以使用Kettle的Insert / Update 步骤,只是可以勾选Don’t perform any update选项,这个选项可以告诉Kettle你只会执行Insert 步骤。
对于第二种情况可能比较用在数据出现错误然后原数据库有一些更新,相应的目标数据库也要更新,这时可能不是更新所有的数据,而是有一些限定条件的数据,你可以使用Kettle的Update 步骤来只执行更新。关于如何动态的执行限定条件,可以参考前一篇文章。
第三种情况是最为常见的一种情况,使用的同样是 Kettle的Insert / Update 步骤,只是不要勾选Don’t perform any update 选项。
第四种情况有些复杂,后面专门讨论。
对于第1,2,3种情况,可以参考下面的例子。
这个例子假设原数据库表为customers , 含有一个id , firstname , lastname , age 字段,主键为id , 然后还加上一个默认值为sysdate的时间戳字段。转换之后的结果类似:id , firstname , lastname , age , updatedate . 整个设计流程大概如下:
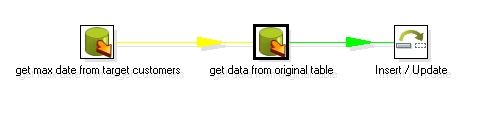
图1
其中第一个步骤的sql 大概如下模式:
Select max(updatedate) from target_customer ;
你会注意到第二个步骤和第一个步骤的连接是黄色的线,这是因为第二个table input 步骤把前面一个步骤的输出当作一个参数来用,所有Kettle用黄色的线来表示,第二个table input 的sql 模式大概如下:
Select field1 , field2 , field3 from customers where updatedate > ?
后面的一个问号就是表示它需要接受一个参数,你在这个table input 下面需要指定replace variable in script 选项和execute for each row 为选中状态,这样,Kettle就会循环执行这个sql , 执行的次数为前面参数步骤传入的数据集的大小。
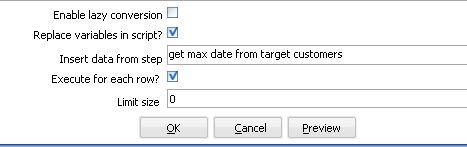
图2
关于第三个步骤执行insert / update 步骤需要特别解释一下,
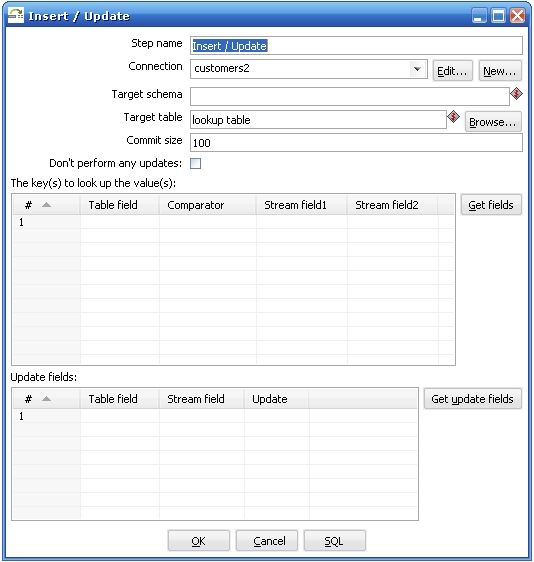
图3
Kettle执行这个步骤是需要两个数据流对比,其中一个是目标数据库,你在Target table 里面指定的,它放在The keys to look up the values(s) 左边的Table field 里面的,另外一个数据流就是你在前一个步骤传进来的,它放在The keys to look up the value(s) 的右边,Kettle首先用你传进来的key 在数据库中查询这些记录,如果没有找到,它就插入一条记录,所有的值都跟你原来的值相同,如果根据这个key找到了这条记录,kettle会比较这两条记录,根据你指定update field 来比较,如果数据完全一样,kettle就什么都不做,如果记录不完全一样,kettle就执行一个update 步骤。所以首先你要确保你指定的key字段能够唯一确定一条记录,这个时候会有两种情况:
1.维表
2.事实表
维表大都是通过一个主键字段来判断两条记录是否匹配,可能我们的原数据库的主键记录不一定对应目标数据库中相应的表的主键,这个时候原数据库的主键就变成了业务主键,你需要根据某种条件判断这个业务主键是否相等,想象一下如果是多个数据源的话,业务主键可能会有重复,这个时候你需要比较的是根据你自定义生成的新的实际的主键,这种主键可能是根据某种类似与sequence 的生成方式生成的,
事实表在经过转换之后,进目标数据库之前往往都是通过多个外键约束来确定唯一一条记录的,这个时候比较两条记录是否相等都是通过所有的维表的外键决定的,你在比较了记录相等或不等之后,还要自己判断是否需要添加一个新的主键给这个新记录。
上面两种情况都是针对特定的应用的,如果你的转换过程比较简单,只是一个原数据库对应一个目标数据库,业务主键跟代理主键完全相同的时候完全可以不用考虑这么多。
有删除,有增加,有更新
首先你需要判断你是否在处理一个维表,如果是一个维表的话,那么这可能是一个SCD情况,可以使用Kettle的Dimension Lookup 步骤来解决这个问题,如果你要处理的是事实表,方法就可能有所不同,它们之间的主要区别是主键的判断方式不一样。
事实表一般都数据量很大,需要先确定是否有变动的数据处在某一个明确的限定条件之下,比如时间上处在某个特定区间,或者某些字段有某种限定条件,尽量最大程度的先限定要处理的结果集,然后需要注意的是要先根据id 来判断记录的状态,是不存在要插入新纪录,还是已存在要更新,还是记录不存在要删除,分别对于id 的状态来进行不同的操作。
处理删除的情况使用 Delete步骤,它的原理跟Insert / Update 步骤一样,只不过在找到了匹配的id之后执行的是删除操作而不是更新操作,然后处理Insert / Update 操作,你可能需要重新创建一个转换过程,然后在一个Job 里面定义这两个转换之间的执行顺序。
如果你的数据变动量比较大的话,比如超过了一定的百分比,如果执行效率比较低下,可以适当考虑重新建表。
另外需要考虑的是维表的数据删除了,对应的事实表或其他依赖于此维表的表的数据如何处理,外键约束可能不太容易去掉,或者说一旦去掉了就可能再加上去了,这可能需要先处理好事实表的依赖数据,主要是看你如何应用,如果只是简单的删除事实表数据的话还比较简单,但是如果需要保留事实表相应记录,可以在维表中增加一条记录,这条记录只有一个主键,其他字段为空,当我们删除了维表数据后,事实表的数据就更新指向这条空的维表记录。
定时执行增量更新
可能有时候我们就是定时执行更新操作,比如每天或者一个星期一次,这个时候可以不需要在目标表中增加一个时间戳字段来判断ETL进行的最大时间,直接在取得原数据库的时间加上限定条件比如:
Startdate > ? and enddate < ?
或者只有一个startdate
Startdate > ? (昨天的时间或者上个星期的时间)
这个时候需要传一个参数,用get System Info 步骤来取得,而且你还可以控制时间的精度,比如到天而不是到秒的时间。
当然,你也需要考虑一下如果更新失败了怎么处理,比如某一天因为某种原因没有更新,这样可能这一天的记录需要手工处理回来,如果失败的情况经常可能发生,那还是使用在目标数据库中增加一个时间字段取最大时间戳的方式比较通用,虽然它多了一个很少用的字段。
执行效率和复杂度
删除和更新都是一项比较耗费时间的操作,它们都需要不断的在数据库中查询记录,执行删除操作或更新操作,而且都是一条一条的执行,执行效率低下也是可以预见的,尽量可能的缩小原数据集大小。减少传输的数据集大小,降低ETL的复杂程度
时间戳方法的一些优点和缺点
优点: 实现方式简单,很容易就跨数据库实现了,运行起来也容易设计
缺点: 浪费大量的储存空间,时间戳字段除ETL过程之外都不被使用,如果是定时运行的,某一次运行失败了,就有可能造成数据有部分丢失.
其他的增量更新办法:
增量更新的核心问题在与如何找出自上次更新以后的数据,其实大多数数据库都能够有办法捕捉这种数据的变化,比较常见的方式是数据库的增量备份和数据复制,利用数据库的管理方式来处理增量更新就是需要有比较好的数据库管理能力,大多数成熟的数据库都提供了增量备份和数据复制的方法,虽然实现上各不一样,不过由于ETL的增量更新对数据库的要求是只要数据,其他的数据库对象不关心,也不需要完全的备份和完全的stand by 数据库,所以实现方式还是比较简单的.,只要你创建一个与原表结构类似的表结构,然后创建一个三种类型的触发器,分别对应insert , update , delete 操作,然后维护这个新表,在你进行ETL的过程的时候,将增量备份或者数据复制停止,然后开始读这个新表,在读完之后将这个表里面的数据删除掉就可以了,不过这种方式不太容易定时执行,需要一定的数据库特定的知识。如果你对数据的实时性要求比较高可以实现一个数据库的数据复制方案,如果对实时性的要求比较低,用增量备份会比较简单一点。
几点需要注意的地方:
1.触发器
无论是增量备份还是数据复制,如果原表中有触发器,在备份的数据库上都不要保留触发器,因为我们需要的不是一个备份库,只是需要里面的数据,最好所有不需要的数据库对象和一些比较小的表都不用处理。
2.逻辑一致和物理一致
数据库在数据库备份和同步上有所谓逻辑一致和物理一致的区别,简单来说就是同一个查询在备份数据库上和主数据库上得到的总的数据是一样的,但是里面每一条的数据排列方式可能不一样,只要没有明显的排序查询都可能有这种情况(包括group by , distinct , union等),而这可能会影响到生成主键的方式,需要注意在设计主键生成方式的时候最好考虑这一点,比如显式的增加order 排序. 避免在数据出错的时候,如果需要重新读一遍数据的时候主键有问题.
总结
增量更新是ETL中一个常见任务,对于不同的应用环境可能采用不同的策略,本文不可能覆盖所有的应用场景,像是多个数据源汇到一个目标数据库,id生成策略,业务主键和代理主键不统一等等,只是希望能给出一些思路处理比较常见的情况,希望能对大家有所帮助。
开源ETL工具kettle系列之动态转换
摘要:本文主要讨论使用Kettle来设计一些较为复杂和动态的转换可能使用到的一些技巧,这些技巧可能会让你在使用Kettle的时候更加容易的设计更强大的ETL任务。
动态参数的传递
Kettle 在处理运行时输入参数可以使用JavaScript 来实现,大部分工作只是按照一个模板来处理的
动态参数传递主要使用在像数据清理,调式,测试,完成复杂的条件过滤等等,这种方式一般不会在产品已经运行稳定了一段时间之后使用,因为我们一般仍然是做定时任务来自动转换数据,所以在开始介绍如何使用动态参数之前,希望大家能明白不要在产品数据库上做实验,即使你已经知道你的转换有什么影响并且做了备份,因为这种方法是不可能自动执行的。
Kettle有两种动态参数传递的方法,一种是非常轻量级的传argument , 另一种是对付较复杂一点情况使用JavaScript . 下面分别介绍这两种方法。
1. argument
当你在运行一个转换的时候,不管这个转换是一个Job的一部分还是只有这个转换,你都可以传递参数给它,当你运行一个转换的时候,会弹出一个 Execution a Transformation 的对话框,让你选择执行转换的方式,本地执行,远程执行,分布式执行,下面就是日志记录的级别和回放时间,然后是argument 和 variables 的设定。Argument 和 variables 的区别在官方FAQ里面也有解释。你也可以参考一下官方的解释和下面解释的异同。
Q : Argument 和 variables 的区别 /
A : variables 也可以认为叫做environment variables , 就像它的名字一样,主要是用来设定环境变量的,比如最常见的:文件的存放地址,smtp的配置等等,你也可以把它认为是编程语言里面的全局变量,即使是不同的转换它们也拥有同样的值,而argument 自然就类似与局部变量,只针对一个特定的转换,比如像是限定结果集的大小和过滤条件。
取得argument的值
我们在转换之前设置了argument的值,需要用到的时候就使用get system info 步骤,这个步骤取得在运行时参数,需要注意的是我们是先设置get system info ,然后在里面决定要使用多少个参数,最多10个,每个参数名叫什么,然后我们才能在运行时看到你设置了的参数名后面跟一个要你输入的值,并且参数类型是不能够指定,全部都当作字符串处理,如果你需要对参数类型有要求,你需要自己转换,使用一个Mapping步骤或者Select values步骤。
取得variable的值
Variable 的值个数不受限制,你可以在kettle菜单的set environment里面设置,也可以使用文件储存这些值,在第一次运行kettle之后,kettle会在%HOME_USER_FOLDER%菜单里面创建一个 .kettle文件夹,如果是windows 用户可能就是C:/Documents and Settings/${your user name}/.kettle这个文件夹,如果是linux用户可能就是/home/${your user name }/.kettle文件夹,这个文件夹下面有kettle.properties文件,如果你打开这个文件,你会发现里面有一些以#开头的注释,其中设置了一些像是:PRODUCTION_SERVER = Hercules 这样的键值对,你可以自己定义一些环境变量比如像是smtp的地址,ftp服务器的地址,你放log文件的目录名等等,当然不能直接编辑这个文件就设置环境变量,要先设置KETTLE_HOME环境变量,windows就是点我的电脑,然后在设置path的那个地方添加一个KETTLE_HOME变量,linux就是export KETTLE_HOME=’一个目录’,这个目录可以任意地方,不过一般还是指向kettle的安装目录或是你自己的文档目录,然后启动kettle它会创建一个新的.kettle目录,编辑里面的kettle.properties文件就可以设置环境变量了.
2. 使用脚本
Kettle使用的是JavaScript来作为它的脚本实现,使用的是mozilla 的rhino 1.5r5版本实现,如果你打算实现一些复杂的计算过程,比如字符串分割,数据类型转换,条件计算等等,你都应该使用脚本语言来搞定。
我们在某种应用环境下使用脚本语言来实现一些动态的功能大部分原因都是为了避免编程,一个复杂一点的应用程序,比如像是Kettle这种工具,或是报表工具,它们不可能提供全部功能,把什么都做成图形化,应用条件永远都是复杂的,如果你不想研究代码和程序的结构,甚至你都不知道怎样编程,脚本语言绝对是一种简单的解决方案,而JavaScript语言又是其中入门门槛非常低的一种,你完全可以多看一些例子,尝试模仿一些脚本来解决问题,也许会有一点难以调试和测试,但总比自己编程要好的多。
下面的这个例子将会使用JavaScript弹出一个对话框来接受两个参数,都是时间类型,其中的UI组件是使用的swt 的一些类,Kettle使用的是swt 作为其UI组件,如果你对swt 有了解的话会更容易理解这些UI组件,当然这并不需要你有swt 编程的经验或者其他GUI设计的经验。
打开Kettle 下载目录下的samples / transformation / JavaScript dialog.ktr 文件(使用Kettle File 菜单里面的import from an xml file 。你会看到一个包含3个步骤的转换。
第一个步骤使用generate rows 产生一条测试数据,测试数据包含一个DateFromProposal 时间字段和一个DateToProposal时间字段。
第二个步骤使用JavaScript 来实现动态的参数转变,它会连续弹出两次对话框,要求输入一个起始值和结束值,然后它会调用一些JavaScript 函数来对日期格式做一些处理,
第三个步骤使用Dummy 来接受输入,你完全可以使用File output 步骤来查看输出。
我们先看一下第二部中的JavaScript代码:(删掉了开头的注释)
var display;
var displayHasToBeDisposed=false;
var shell=null;
try {
display=Packages.org.eclipse.swt.widgets.Display.getCurrent();
shell=display.getActiveShell();
} catch(e) {
// if it runs in batch mode (Pan or preview mode) no Display is available, so we have to create one
display=new Packages.org.eclipse.swt.widgets.Display();
displayHasToBeDisposed=true;
shell=new Packages.org.eclipse.swt.widgets.Shell(display);
}
// if we run in Pan we need to load the properties:
if(!Packages.org.pentaho.di.ui.core.PropsUI.isInitialized()) {
Packages.org.pentaho.di.ui.core.PropsUI.init(display,2); //2=TYPE_PROPERTIES_PAN
}
var dateDefaultFrom=DateFromProposal.getString().substr(0,10); //only the date and not the time
var dialogDateFrom=new Packages.org.pentaho.di.ui.core.dialog.EnterTextDialog(shell, "Date from", "Please enter the beginning date", dateDefaultFrom);
var dateFromAsString=dialogDateFrom.open();
if(dateFromAsString!=null && dateFromAsString.length()>0) {
var dateDefaultTo=DateToProposal.getString().substr(0,10); //only the date and not the time;
var dialogDateTo=new Packages.org.pentaho.di.ui.core.dialog.EnterTextDialog(shell, "Date to", "Please enter the ending date", dateDefaultTo);
var dateToAsString=dialogDateTo.open();
if(dateToAsString!=null && dateToAsString.length()>0) {
// here you could check or change formats a.s.o
} else {
// stop transformation when user cancels
throw new Packages.java.lang.RuntimeException("Input canceled by the user.");
}
} else {
// stop transformation when user cancels
throw new Packages.java.lang.RuntimeException("Input canceled by the user.");
}
if(displayHasToBeDisposed) {
display.dispose();
}
Display 和 shell 都是swt 里面的对象,你只用知道他们是表示UI的就可以了.
DateFromProposal和DateToProposal都是前面传过来的字段,dateFromAsString和dateToAsString都是需要输出的内容,整个脚本只是简单的取了两个日期变量的时间部分,使用了字符串操作的substr()函数。
其中有三点需要注意:
1. dialog对象的初始化方式:使用的构造函数类型为
EnterTextDialog(Shell parent, String title, String message, String text) , 另一种构造函数类型是加一个参数fixed :
EnterTextDialog(Shell parent, String title, String message, String text, boolean fixed)
fixed代表字体是否用固定宽度,text参数代表的是输入在对话框里面的值,一般可以默认为空或输入一段用户提示信息,例子中是设置成原先转换之前的值,相当于默认值。
2. 使用open()函数取得输入值
我们调用dialog 的open()函数取得输入的值。
3. 异常的处理方式
基本上是一个标准的java 语法的try catch throw .
最后运行一下并查看输出,运行的时候什么都不输入接受默认值就可以了,最后查看输出,以下是文本方式的输出,以分号分割
DateFromProposal;DateToProposal;dateFromAsString;dateToAsString
2006/01/01 00:00:00.000;2006/12/31 00:00:00.000;2006/01/01;2006/12/31
最后需要注意的是这种方式的实现可能将来会直接用一个新的step来实现,不用这样写脚本。
调试
调试可不是程序的专利,ETL过程同样需要调试过程,Kettle同样支持比较简单的调试过程,你可能已经发现了在菜单下面的工具栏下面有一个debug 和preview 按钮来支持调试过程,这种调试的技巧同样可以用来帮助你完成一些复杂的ETL工程,下面以一个例子来解释调试过程.
首先,打开samples / add sequence specify a common counter.ktr 文件,你会发现一个定义了两个sequence 的转换,点击debug按钮,它会弹出一个Transformation debug dialog 窗口。
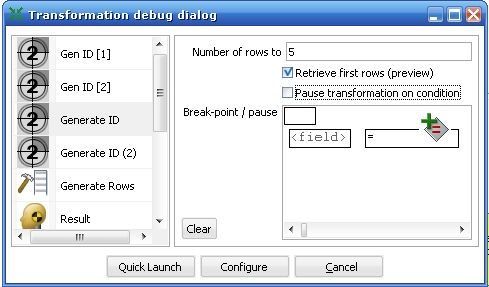
图1
这个窗口左边列出了在这个转换中所有的步骤,我们选取Generate ID 步骤,然后设置断点的条件:
Kettle支持两种断点的方法,一种基于限定结果集的数量大小,另一种是基于条件的判断过程。
我们选择基于结果集大小的方式,只查看前面5条数据。
你会看到Kettle列出了Generate ID 步骤产生的前面5条数据,
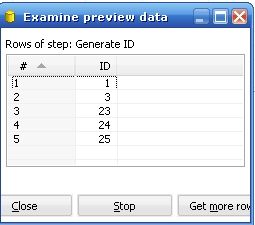
图2
从上图中可以看到这个generate id 步骤产生了5个值并不是连续的,下面的按钮Close ,Stop 可以控制当前线程是继续还是停止.
利用调试的方法可以帮住我们设计一些需要基于条件判断的复杂ETL过程,我们使用调试的方法来查看数据中是否可能存在某些特定数据,以此来设计一些ETL过程针对这些数据进行处理。
开源ETL工具kettle系列之建立缓慢增长维
1. Kettle 简介
Kettle 是一个强大的,元数据驱动的ETL工具被设计用来填补商业和IT之前的差距,将你公司的数据变成可增长的利润.
我们先来看看Kettle能做什么:
1. Data warehouse population with built-in support for slowly changing dimensions, junk dimensions and much, much more.
2. Export of database(s) to text-file(s) or other databases
3. Import of data into databases, ranging from text-files to excel sheets
4. Data migration between database applications
5. Exploration of data in existing databases. (tables, views, synonyms, )
6. Information enrichment by looking up data in various information stores (databases, text-files, excel sheets, )
7. Data cleaning by applying complex conditions in data transformations
8. Application integration
本系列文章主要介绍如下几点:
1. 数据仓库内建支持缓慢增长维SCD ,
2. 在数据转换中使用复杂条件判断来清理数据
3. 如何使用kettle 来处理增量更形
4. 将Kettle 集成到你的应用程序里
5. 使用kettle中应该注意的一些地方
2. Kettle 文档
最好的kettle教程就在你身边,我们下载的kettle-version. zip 文件里其实已经包括了非常多的示例和文档,在你的kettle文件夹下,docs 文件夹下包含了所有的文档,samples文件夹下包含了一些示例,后面的介绍中一部分示例都来自kettle自带的这个示例文件夹下。docs里面最主要的是Spoon-version-User-Guide. zip ,里面记录了kettle 的技术性文档,包括支持的操作系统,数据库平台,文本格式,图形化的界面,其中最重要的是所有的转换对象(Transformation Core Objects) 和Job对象(Job Core Objects) 的解释,包括截图和每一个参数的解释。
3. Kettle与Slowly Changing Dimension
我们使用kettle自带的samples文件下的示例,来看kettle如何支持SCD的。
打开samples / jobs / Slowly Changing Dimension 文件夹,发现里面有三个文件,
create - populate - update slowly changing dimension.kjb
DimensionLookup - update dimension table 2.ktr
DimensionLookup - update dimension table.ktr
其中后缀以 .kjb 结尾的是kettle 的job 文件导出的格式,而以ktr 结尾的是kettle 的transformation 导出的格式,打开其中的DimensionLookup - update dimension table.ktr , 出现如下所示 :
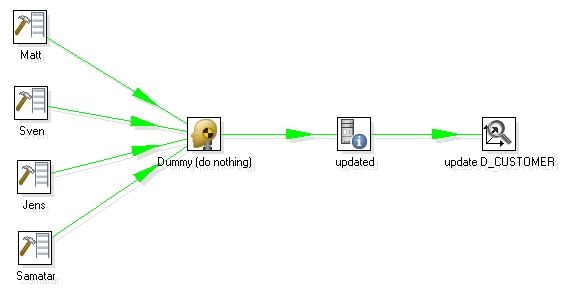
图1
1. 最左边的是产生测试数据,如果是实际环境的话应该是连接真实的数据库,产生的真实数据格式打开如下:
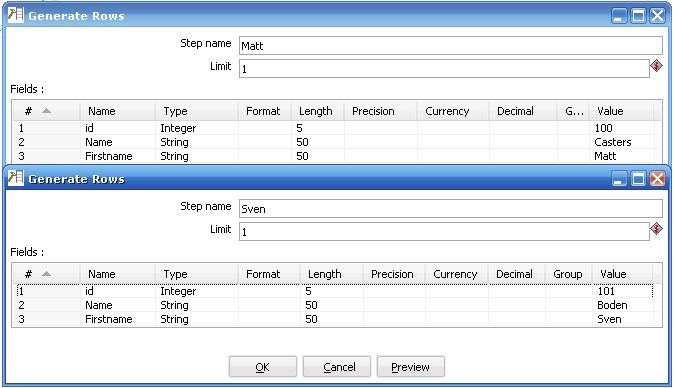
图2
2 第二个步骤Dummy 就是把前面的数据合并起来,Dummy 步骤本身不做任何事情,不过由于前面有四个输入指向它,所以它在第二步的作用等同于数据合并。
3 第三个步骤是取得系统参数(get system date) , 它取得当前系统时间的日期,并且格式是当天的 00:00:00 , 如图所示
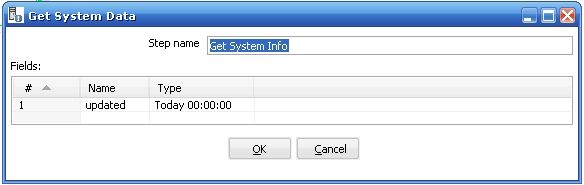
4. 最后一步是真正的重点,执行Dimension Lookup / Update 步骤来更新和插入数据,以此来实现Type 1 ,2 ,3 的不同Slowly Changing Dimension
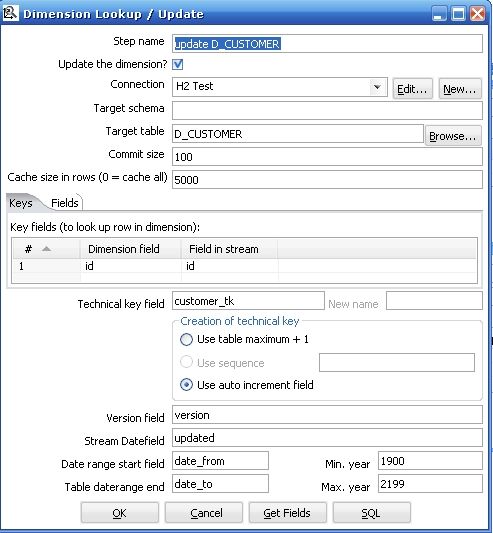
图4
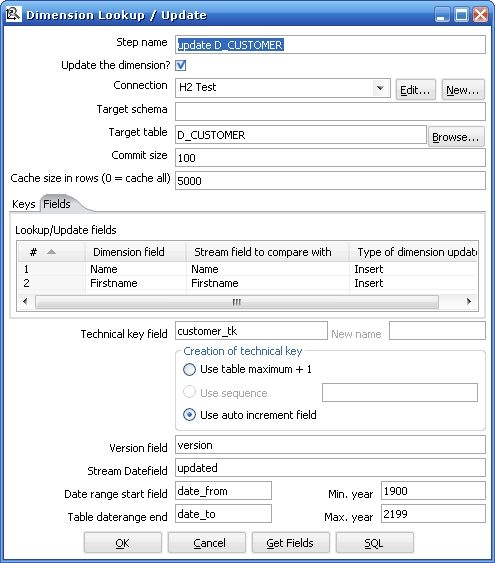
图5
在开始介绍Dimension Lookup / Update 之前,先看看在执行这个步骤之前的输入和输入:
输入:
|
字段名
|
数据类型
|
说明
|
|
id
|
int
|
前面步骤的输入
|
|
name
|
Varchar(50)
|
前面步骤的输入
|
|
firstname
|
Varchar(50)
|
前面步骤的输入
|
|
updated
|
time
|
从第三步来的时间参数
|
| 字段名 | 数据类型 | 说明 |
| id | INT | 来自输入 |
| name | varchar(50) | 来自输入 |
| firstname | varchar(50) | 来自输入 |
| customer_tk | BIGINT | 代理主键 |
| version | INT | 版本变更号 |
| Date_from | datetime | 有效期起始日期 |
| Date_to | Datetime | 有效期失效日期 |

图6
Date_from 都是 1900/01/01 00:00:00.000
Date_to 都是 2199/12/31 23:59:59.000 这两列都是根据图4下面部分定义的
Id , name , firstname 都是测试数据,从前面步骤来的.

图7
注意到其中customer_tk 并没有什么变化,仍然在产生类似序列的输出
Version 的值中出现了 2 , 并且只有在我们改变的数据中
在出现了改变的行中的date_from 变成了2007/11/28/ 00:00:00.000
在出现了改变的行中原来数据的date_to 变成了 2007-11-28 00:00:00.000
Id 列没有变化,(变化了也没用,图5中的中间部分 Field 选项卡没有选id)
Name , firstname 有两个值变了(我们手工改变的)
| Step name | 步骤的名称,在一个转换中必须是唯一的 |
| Update the dimension? | 当找到符合条件记录的时候更新这条记录,如果这个复选框没有选择,找到了符合条件记录的时候就是插入新纪录而不是更新 |
| Connection | 数据库连接的名字 |
| Target schema | |
| Target table | 要更新的维表的名称 |
| Commit size | 批处理更新的记录数 |
| Cache size in rows |
这是把维表的数据放在缓存中用来提高数据查找速度从而减少数据库查询的次数
注意只有最近一次的记录会被放在缓存中,如果记录数超过缓存大小,最有最有关的最近的最高版本号记录会被放在缓存中
如果把cache size 设置成0 ,kettle会一直把记录放在缓存中直到JVM没有内存了,如果你这样设置要确保维的记录数不要太大
设置成 1 表示不使用缓存
|
| Keys tab | 设置在流中的主键和目标维表的业务主键,当两个键相等时认为这条记录匹配 |
| Fields tab | 设定要更新的字段,当主键记录匹配的时候,只有设定更新的字段不一样才认为是这条记录是不一样的,需要更新或者插入(注意图5的中间部分,Fields tab 右边设定的是Insert ,所以实现的是Type2 的SCD) |
| Technical key field | 维的主键,也可以叫做代理主键(Surrogate Key) |
| Creation of technical key |
指定技术主键的生成方式,对于你数据库连接不适合的方式会自动被去掉,一共有三种:
1 .Use table maximum + 1 : 使用当前表最大记录数加一的方式产生新主键,注意新的最大值会被缓存,所以不用每次需要产生新记录的时候就计算
2 . Use sequence : 使用一个数据库支持的序列来产生技术主键(比如Oracle ,你也可以看到图4中这一条是灰色的因为使用的是mysql 数据库)
3. Use auto increment field : 使用一个数据库支持的自动增长来产生技术主键(比如DB2)
|
| Version field | 使用这个字段来储存版本号 |
| Stream Datafield | 你可以指定维记录最后一次被更改的时间,它能指定你要更新的维的精度,如果不指定,就会默认是系统时间 |
| Date range start field | 维记录其实有效时间 |
| Table daterange end | 维记录失效时间 |
| Get Fields button | 指定所有你想要更新的字段,除了你指定的主键 |
| SQL button | 产生sql 来创建维表 |
官方文档中提到的注意事项:
1. Stream date field : 如果你不想每次都改变时间的范围,你需要添加一个额外的这个字段,比如你打算每天的午夜来进行ETL过程,可以考虑加一个Join 步骤”Yesterday 23:59:59” 作为输入的时间字段.
2. 这必须是一个Date 字段(不能是转换后的字符串,即使他们有相同的格式也不行),我们(Kettle 的开发小组)把功能实现隔离出来,如果你需要的话自己要先转换.
3. 对于Date range start and end fields : 你只能指定一个表示年的数据,而不是时间戳,如果你输入YYYY(比如2100) ,这将会被当成一个时间戳来用: YYYY-01-01 00:00:00.000 ,(注意图6中的格式)
另外需要注意的地方:
1. Technical key field : 其他一些ETL工具(比如OWB)也许叫做代理主键,只是名字上不同而已.
2. SQL Button : 当你在目标数据库中还没有建立维表的时候,你点击SQL Button ,Kettle 会弹出如下对话框帮你建立维表,你会发现它默认帮你在代理主键和业务主键上建立索引。
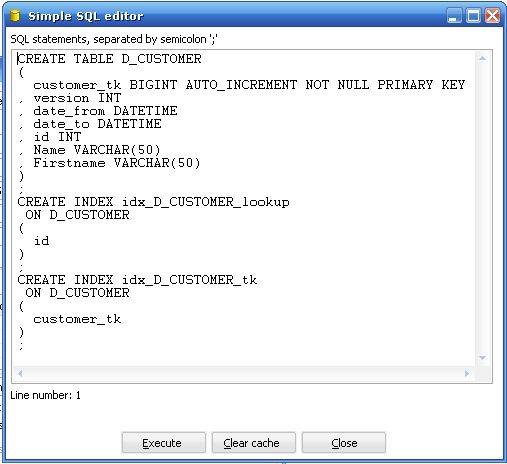
图8
3 Creation of technical key : 在这个选项的第二种实现方式上,Use sequence ,这个要视你数据库支持而定,mysql 就不支持,Oracle 支持sequence , 但是你要自己创建和管理这个sequence , 如果这个sequence 的值因某种外部因素改变了,你要自己确定sequence 产生的值处于何种状态,如果可以的话尽量不要用,尽量用第一种:table maximum + 1 ,这种方式永远不要担心数据库的不同和实现方式的不同,而且简单易懂。
4 Stream Datefield
4.1 这个选项是用来控制时间的精度的,有的时候我们可能只是一个月进行一次ETL,这个时候Datefield 显然没有必要到秒的精度,而且这个选项严重影响你后面如果使用缓慢增长维的sql 的复杂度,因为你需要先把时间的精度调到你需要的精度,比如你使用的数据是到秒的精度,但是你实际需要的只是天的精度,你在sql 里面有大量的时间都浪费在toString( stream date field) ,然后把这个字符串substring() ,执行效率会低一些.
4.2 不要轻易改这个精度,一旦你确定了精度问题,不要尝试改变它,尤其是当精度变细的时候,你可能会损失掉已经存在与数据库中的数据的精度,如果你只是从 “Today 00:00:00.000” 改成 “Today 23.59.59.000” 的情况,需要手动处理好已经存在的数据格式问题.
4.3 执行ETL的时间可能决定这个值,如果你一天可能存在5次执行ETL过程(包括自动执行或者手工执行)那么你显然不希望时间的精度是按天来计算的(比如Today 00.00.00这种格式)
4.4 精度的损失并不可怕:考虑一下你的应用场景,比如我们要做表,列出2006年11月份和2006年12月份的所有销售总和,结合上图中的customer 的例子,假设是按客户聚合的, 我们对于customer 的精度要求只要求到月,没有要求到天,如果我们执行ETL的过程是一个星期执行一次,可能一个客户在一个星期内改变了三次他的名字(虽然不是个好例子,完全是为了配合上面的图),而只有最后一次的改变被记录了下来,这完全跟你执行ETL的频度有关,但是考虑到用户需求,只要精度到月就够了,即使这种精度有数据损失也完全没关系,所以你如何指定你的Stream date field 的精度主要是看用户需求的精度。
4.5 如果以上四点你觉得只是一堆让你头疼的字符串,那你完全可以把stream date field 设置成空(默认的到时间戳的精度)
执行Type 2 SCD
1. “Update the dimension?” 选中
2. 在Field tabs 里面,对于每一个你想要保持全部记录的字段都要选择Insert 方式.
错误处理和依赖问题
如果你运行了这个转换,你会发现你的输出中有一条customer_tk为1,version为1的数据,你在图6和图7中没有看到这条数据是因为我不想一开始把这条数据跟SCD的实现混在一起,SCD的实现本身并不会告诉你要添加这条数据,这完全是跟数据建模有关系,为了理解这个问题,我们看一下如下情况该如何处理:
一个产品销售的记录是作为一个立方体的主要事实表,它包括一个客户维,现在因为某种原因客户维需要删除掉一部分数据,但是对映的产品销售记录却要保存起来,该如何处理外键约束的问题?
SCD实现本身并不会考虑这个问题,因为它跟维表没有什么关系,你要处理的是事实表里面那些引用了维表的记录,如果你没有这个空行(它唯一的一个值就是 id ,而且是为了满足主键约束,version那个字段有没有值不重要),事实表中的记录就不好处理这种情况,因为你把它赋予任何一个值都是不合适的。这种方法是为了处理像数据依赖(外键的关系)和错误处理比较常见的方法。
http://tech.cms.it168.com/db/2008-03-21/200803211716994.shtml
开源ETL工具kettle系列之动态转换
http://tech.cms.it168.com/o/2008-03-17/200803171550713.shtml
开源ETL工具kettle系列之增量更新设计技巧
http://tech.cms.it168.com/db/2008-03-21/200803211924754.shtml
开源ETL工具kettle系列之在应用程序中集成
http://tech.it168.com/db/2008-03-19/200803191510476.shtml
开源ETL工具kettle系列之常见问题
http://tech.it168.com/db/2008-03-19/200803191501671.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号