2020春-面向對象設計與構造-第一單元總結
2020春-面向對象設計與構造-第一單元總結
一、程序結構分析
作業1
作業1代碼量不多,主要難點在於將輸入的字符串形式的表達式轉換爲特定數據結構的存儲形式。在作業1中我分了三個類:Main、RegExp、Term。其中RegExp類使用靜態變量存儲了構造的正則表達式字符串;Term類對指數和係數進行了封裝,並給出其構造方法和toString方法;主類對匹配輸入字符串、處理輸入字符串、輸出結果的三個過程進行了封裝,三個部分均使用了static修飾的方法。
下圖爲代碼行數統計信息

可以看出作業1代碼量不多,但注釋所占代碼的比例比較低。在較爲簡單的程序中這可能不會有很大影響,但在更複雜的程序中,注釋行所占比例應當再大一些,程序的可讀性才會有所保障。
下圖爲UML類圖
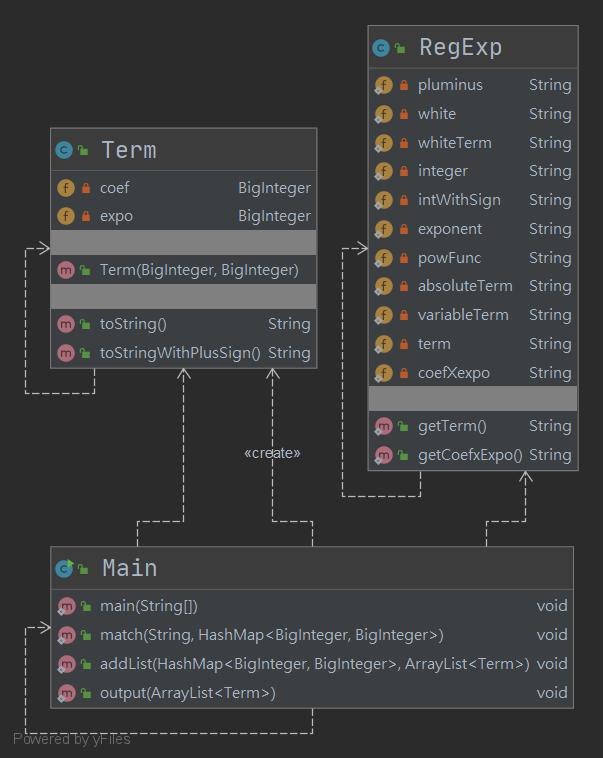
此次作業的類之間沒有繼承關係,只有互相調用的關係。可以説本次作業仍舊沒有脫離面向過程的“魔爪”,主要處理方法仍舊在主類中以static修飾的方法形式出現。
下圖爲方法複雜度分析
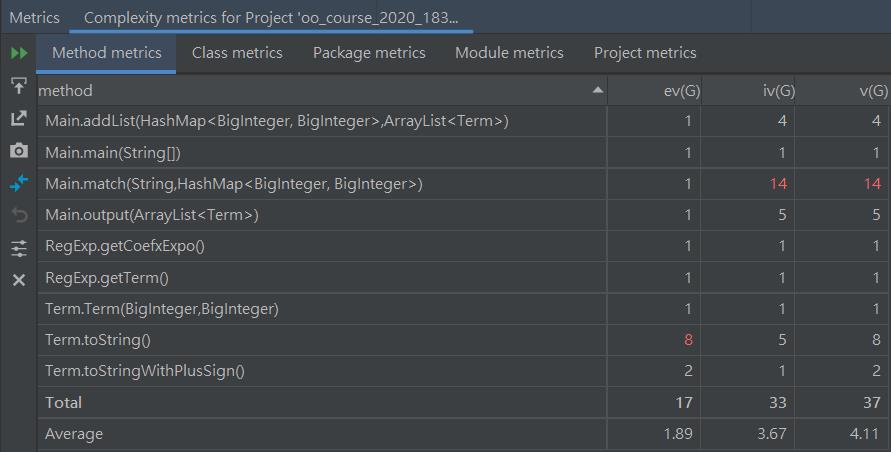
可以看出主類中的match方法與Term類中的toString方法的複雜度較高。其中Term.toString方法主要是對指數和係數的可縮減表達的情況進行了枚舉式的判斷,而Main.match方法主要是條件語句、循環語句的層數過多,將匹配正則表達式與構造表達式數據結構的過程全都寫到了一個方法中。
下圖爲類複雜度分析
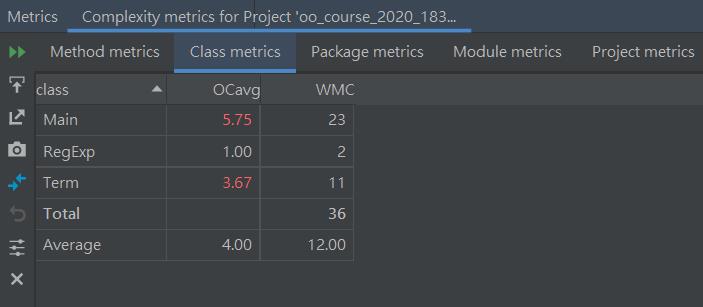
其中主類與Term類的平均複雜度較高,這與前面的方法複雜度有所對應。
作業2
作業2在作業1的基礎上增加了對正餘弦函數求導的要求。由於作業1我是采取了完全的面向過程思想,可以説是沒有架構,所以作業2不能叫重構,而是從頭開始首構(首次建構)起了一個面向對象的架構。與作業1相比,本次作業有了面向對象的影子;但是缺點在於沒有考慮之後作業3可能的拓展要求,所以作業3仍舊不能使用作業2已有的架構,即作業1無構,作業2始構,作業3重構。
作業2中我分了4個類:主類、RegExp類、Term類、Expression類。其中主類僅涉及對輸入的讀取與處理後的輸出;RegExp類以static變量的形式存儲了所有的正則表達式;Term類以係數、冪指數、正弦指數、餘弦指數四個BigInteger對單個的項進行了抽象;Expression類以Arraylist<Term>的形式對表達式是由多個項組成這一實際情況進行了抽象。
值得一提的是,我的作業2在第一次提交中測的時候就通過了所有的測試點,這還是令我很高興的。
下圖爲代碼行數統計信息

沒有注釋確實不是一件好事,不過可能也是因爲我每個方法的名字都盡量不用縮寫、能較好地表達每個方法的功能,因此在可讀性上我認爲還算可以。
下圖爲UML類圖
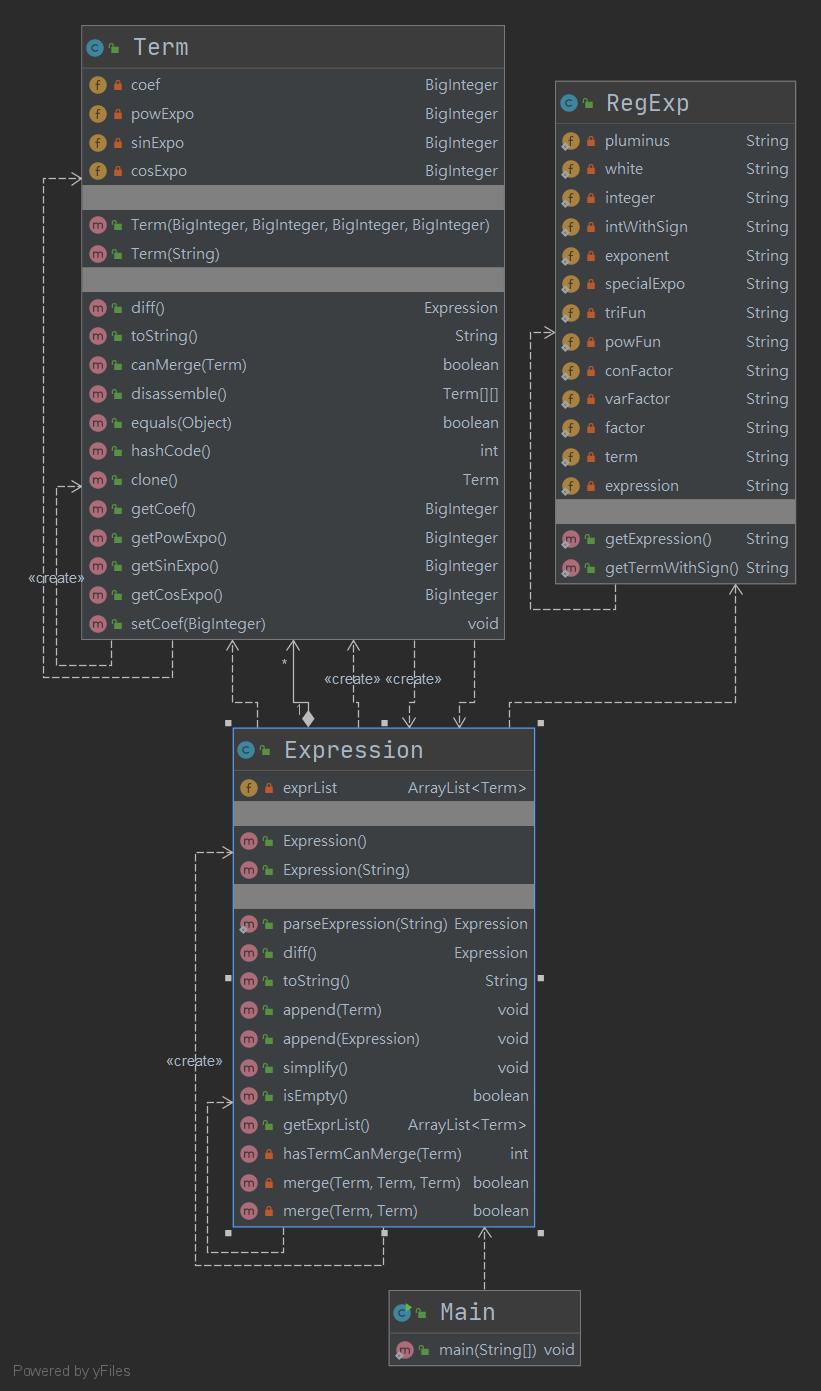
此次作業我認爲最符合面向對象思想的地方就在於Term類與Expression類内部的方法了。Term對象求導會生成一個Expression對象,Expression對象求導也會生成一個Expression對象。Expression類的求導方法會調用Arraylist中每一個Term的求導方法,并將Term對象求導得到的Expression對象通過append方法添加到將返回爲Expression類求導結果所生成的的Expression對象中。
下圖爲方法複雜度分析
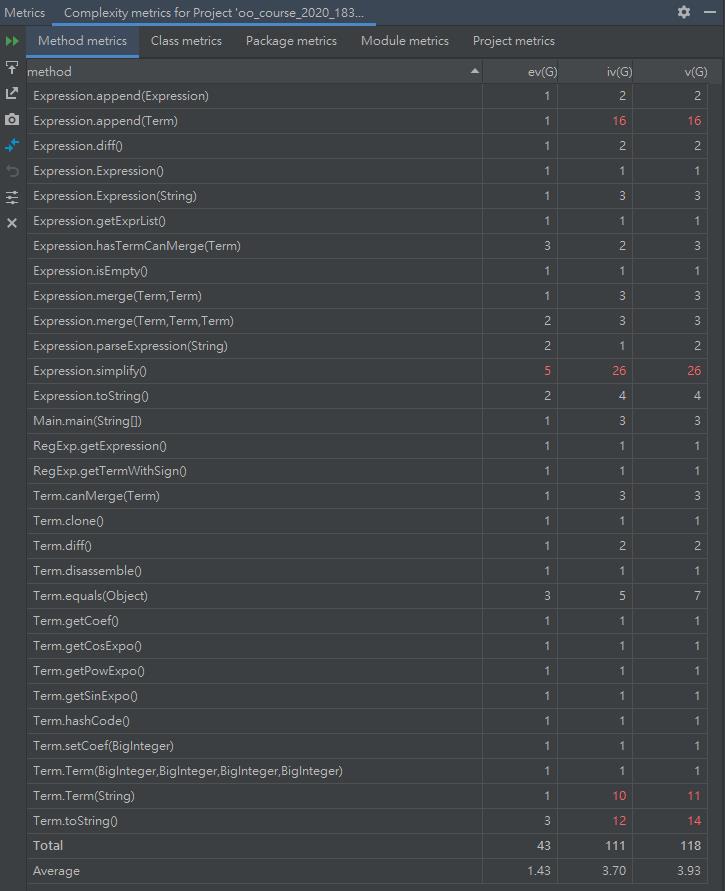
Expression.append方法與Expression.symplify方法複雜度較高。我在向表達式中添加每一項的過程中都遍歷了表達式的每一個Term項判斷能否對其進行合並簡化,又在輸出之前又對表達式進行了多輪簡化,而在簡化過程中出現了許多判斷Term不同的拆項方式能否與已有項進行合并的過程,因此我想是這一部分導致了複雜度較高的情況出現。此外Term.Term(String)方法與Term.toString方法複雜度較高,原因是我將分割得到的每一項對應的字符串轉化爲存儲結構的過程全部寫到了Term的構造方法中,而toString方法仍舊是枚舉式的輸出。
下圖爲類複雜度分析
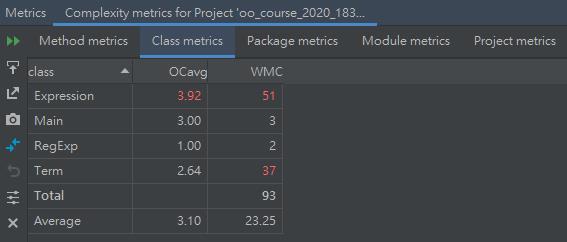
其中Expression類的複雜度較高,Term類次之,而主類已經不再像作業1一樣將所有處理過程都包含進去了,而是僅僅提供一個程序入口。可以看出作業2比作業1更加面向對象。
作業3
作業3在作業2的基礎上增加了表達式因子的概念,使得原先作業2“一個項僅有係數、冪函數、sin(x)冪次函數、cos(x)冪次函數構成”的緊密封裝的Term類無法繼續使用,因此是一次重構。
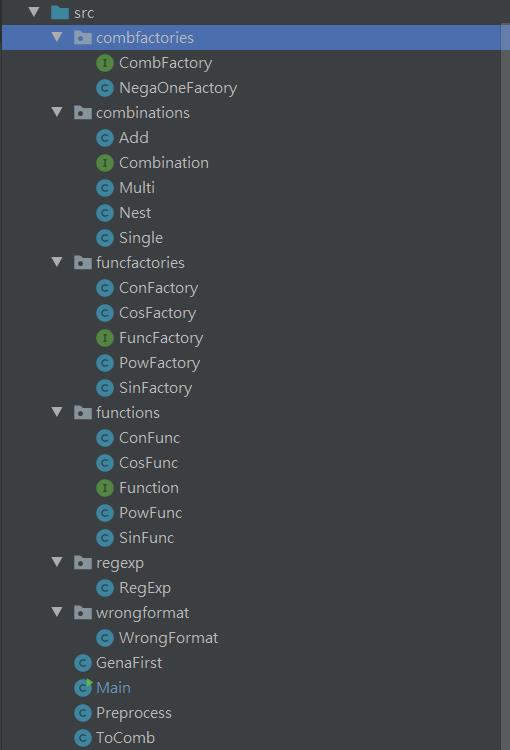
作業3要管理的類較多,所以我第一次使用了package來對各個類進行了管理。此外我還在作業3中使用了工廠模式,將構造方法交給工廠統一管理,簡化了構造新的因子的複雜程度。
下圖爲目錄結構樹
下圖爲代碼行數統計信息
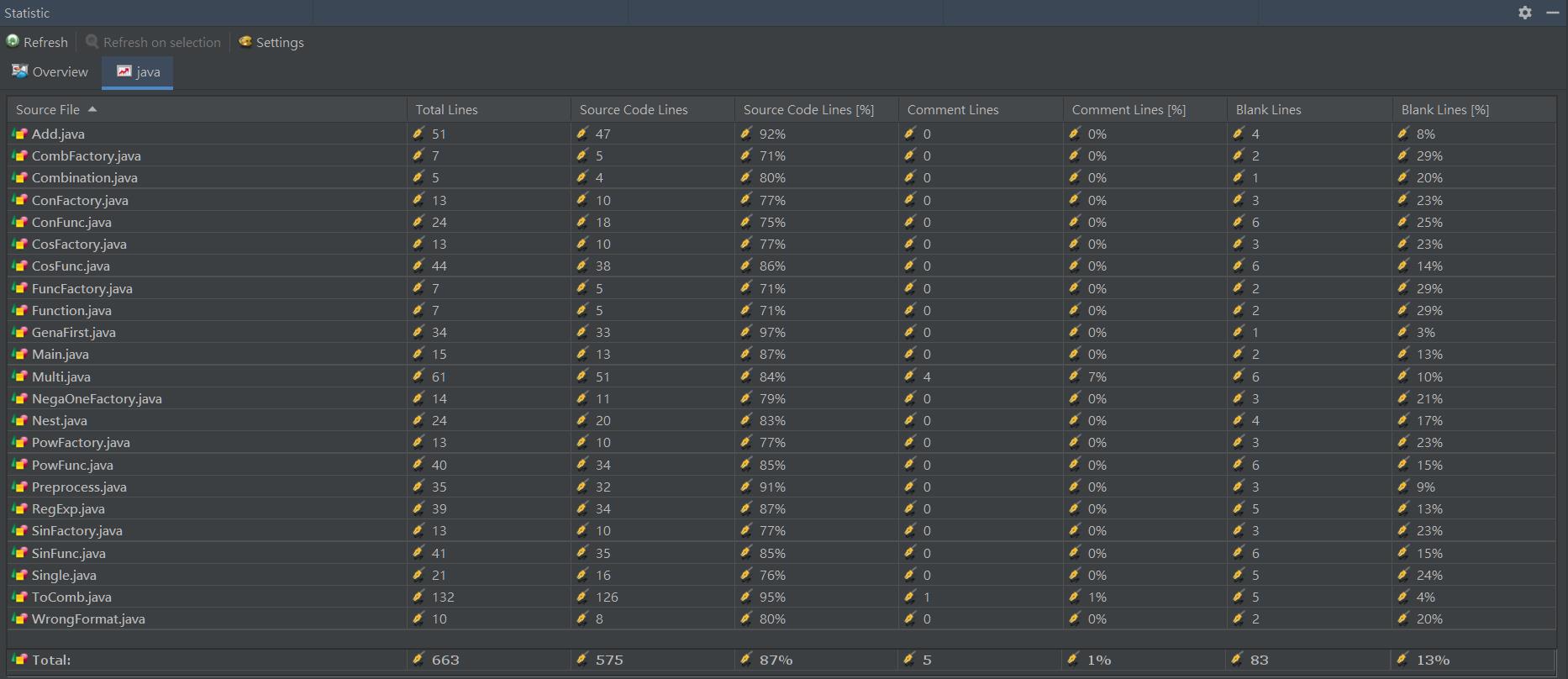
注釋還是很少,希望之後我能多寫點注釋吧。。。
下圖爲UML類圖
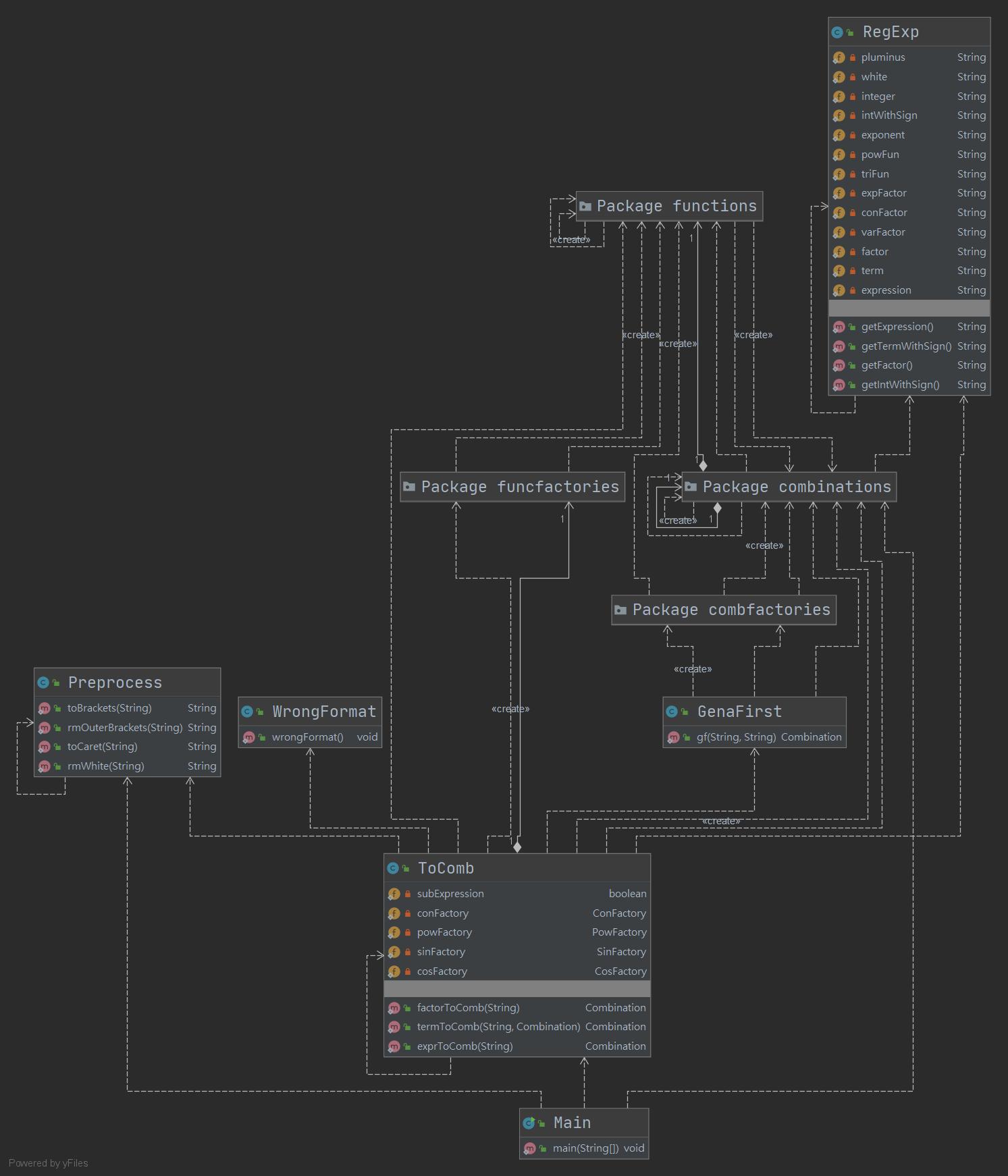

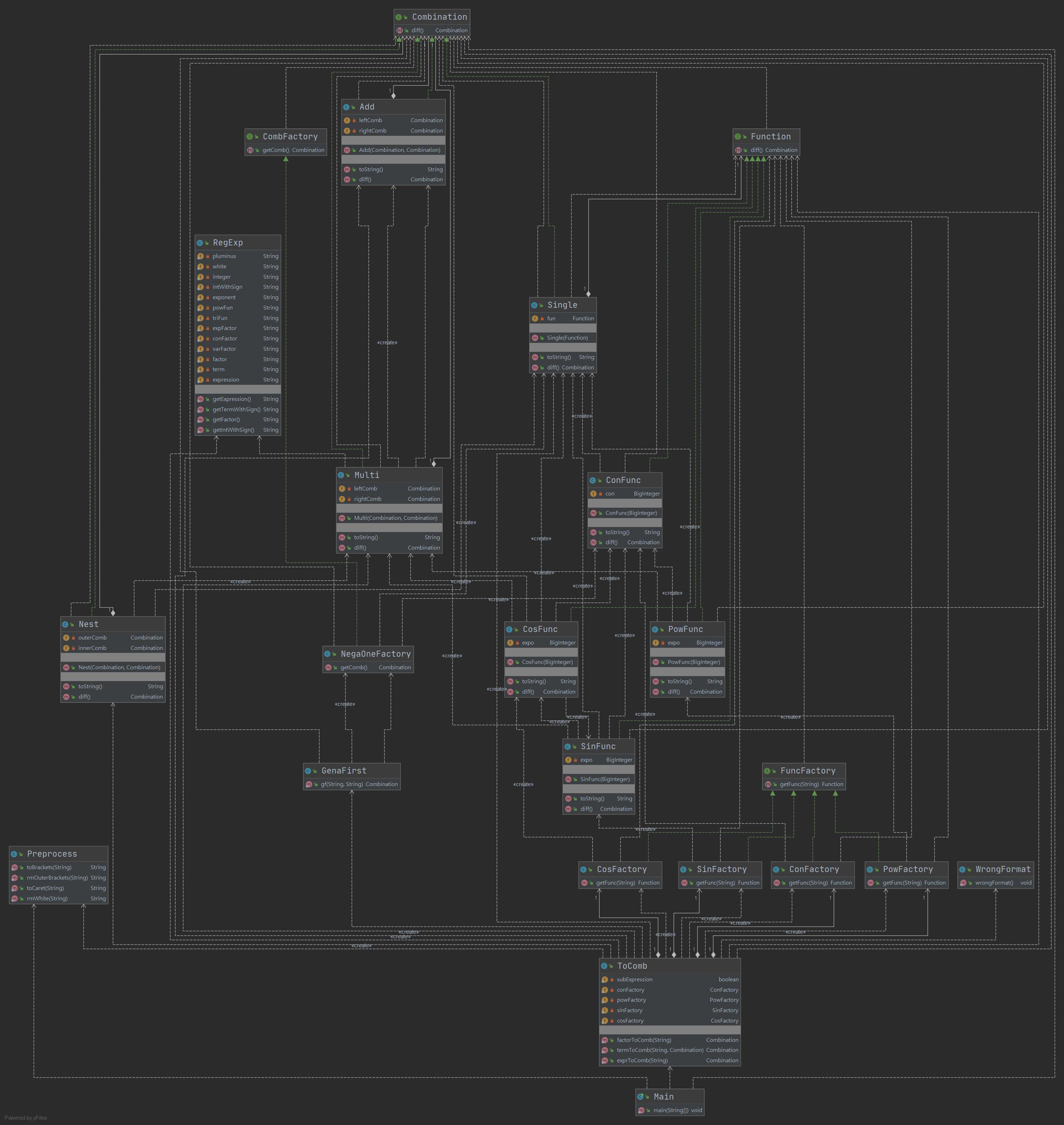
本次作業應用了接口功能,爲不同類型的函數類規範了一個統一的求導接口。本次作業中表達式本質上是一個Combination類型的數據,它的下層是不同Combination類型的組合。值得一提的是,其中Combination的一個具體實現——Single類型,是對Function類型的封裝,即實現簡單函數的Function類套了個殼,從而其可以按照Combination的方式來使用。在對頂層的求導接口進行調用的時候,會遞歸調用下層的求導接口,而每層的求導接口都將其自身求導的結果維護好,從而很方便地確保了求導功能的正確性。
下圖爲方法複雜度分析
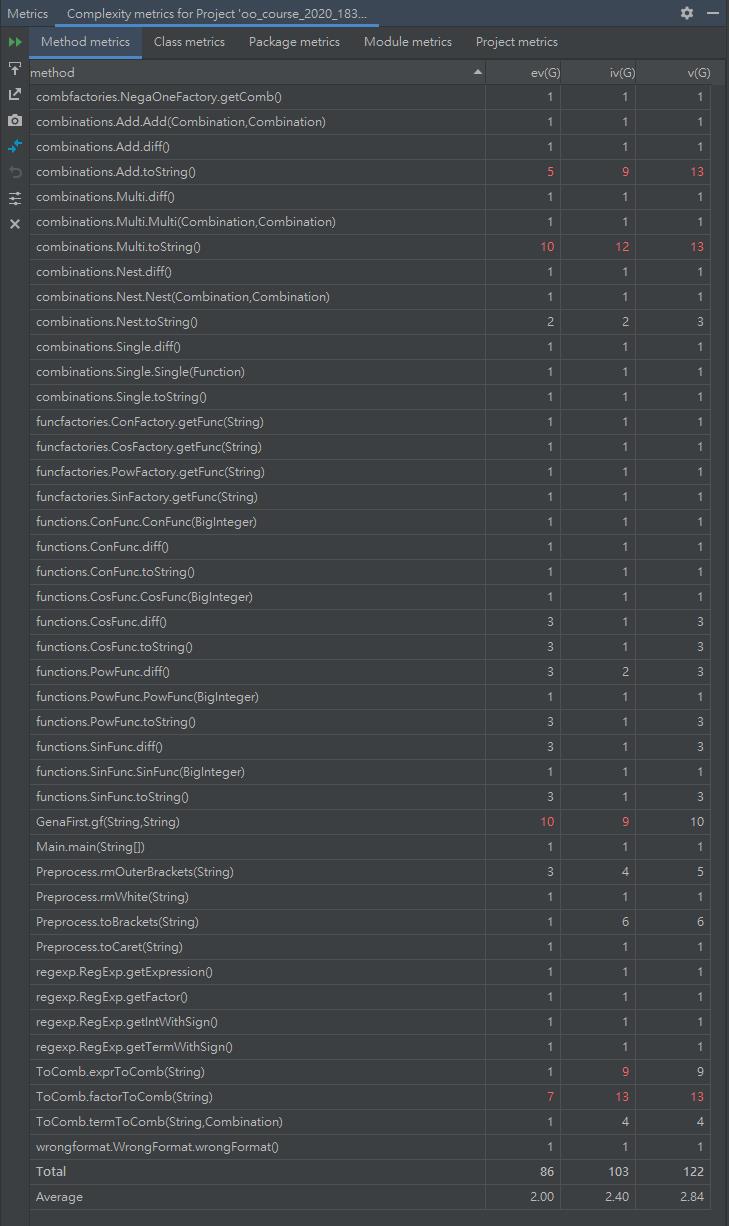
上圖中複雜的方法主要是由輸入字符串向存儲結構轉化的過程(toComb)、和存儲結構向輸出字符串的轉化過程(toString),作業的難點也正在於此。此外GenaFirst.gf方法是根據項的符號創建第一個是-1或+1的因子,由於項前面的符號可能會有多個,因此涉及了較多的判斷。
下圖爲類複雜度分析
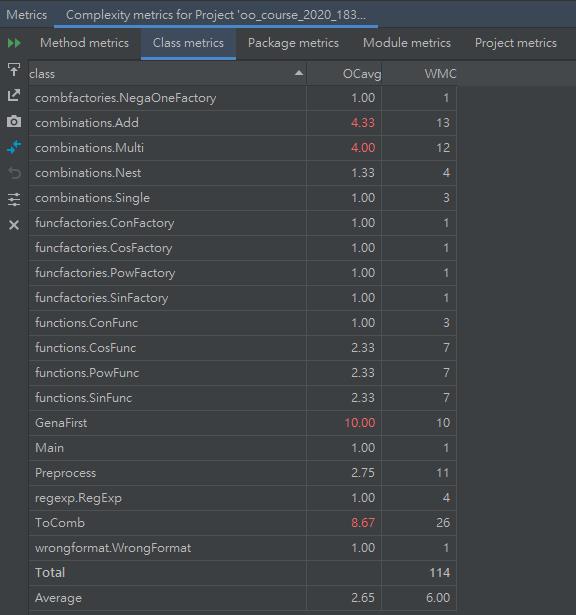
可以看出,類複雜度與方法複雜度是對應的。
二、Bug分析
作業1、作業2
作業1、作業2在中測、強測、互測中均未被測出bug。
作業3
作業3在強測中被測出了一類bug,在互測中被測出了另外一類bug。
# Bug 1 - TLE Bug
測試數據:+cos(sin(cos(cos((-cos(sin(sin(cos(cos(sin(x**2)))))))))))
數據特徵:涉及到了較多層次的嵌套,時間複雜度較高。
錯誤原因:在toString方法中使用"+"對字符串進行拼接,導致在多層遞歸調用的時候程序速度較慢。
解決辦法:將toString方法中使用"+"進行字符串拼接的代碼修改爲使用StringBuilder.append()方法,解決了程序可能存在的超時問題。
反映問題:習慣於使用String與"+"進行字符串拼接,沒有考慮到字符串拼接可能會造成的性能影響。
# Bug 2 - Remove OuterBrackets Bug
測試數據:+- sin(((5+sin(x)) * (5+sin(x))))
數據特徵:在表達式因子的首位出現了不同的表達式因子。
錯誤原因:在預處理過程中會根據棧的思想將表達式因子最外層的'('、')'變換爲'['、']',而在循環去除表達式因子最外層的括號時,僅判斷了第一個字符與最後一個字符是否爲'['和']',而沒有判斷這兩個括號是否是成對的括號,造成了會對具有上述數據特徵的數據誤判爲WrongFormat。
解決辦法:在判斷首尾是否爲'['、']'的條件中添加判斷字符串除第一個字符之外的子串中是否存在'['字符的條件,即添加!trim.substring(1).contains("[")條件。
反映問題:考慮問題不全面,也沒有做足測試。
三、互測階段發現他人bug采用策略
作業1互測時尚未掌握自動對拍程序的編寫與使用,因此自行構造了一些邊界樣例,但是沒有hack到其他同學的bug。作業1整個房間的同學都沒有hack到其他同學的bug。
作業2互測時使用了自行搭建的基於Python的Xeger包、Sympy包與Windows批處理程序的自動對拍程序,找到了三名同學的不同bug。
作業3的測試數據自動生成較爲複雜,因此沒有使用自動對拍程序,而是測試了自行構造的一些邊界數據,找到了一名同學的bug。
應當檢討的是,我沒有结合被测程序的代码设计结构来设计测试用例。大多數情況下我並沒有從閲讀其他同學的代碼中找到明顯的bug,經常是先得知了某個測試數據測出了某個同學程序的bug,進而依據該數據找到該同學程序結構上的不足。這恰恰是反過來的邏輯。
四、應用對象創建模式
對象創建模式包括構造函數模式、原型模式、工廠模式、單例模式等。
在作業1和作業2中,我基本上都在使用構造函數模式進行對象構造;在作業3中,我使用了工廠模式和構造函數模式共同進行對象構造。
對於構造函數模式,使用起來很方便,最自然,當需要構造對象時直接new一個即可。構造函數模式也是最基本的對象構造模式。當程序中的類較少的時候,應用構造函數模式較爲方便。
原型模式,即對應於C++的拷貝構造、Java的clone方法。原型模式主要在需要對對象進行拷貝操作時使用,使用的機會比較特定。
工廠模式,可以將繼承自同一個父類或實現了同一個接口的不同類的構造方式整合到一起。當有較多的類需要管理的時候,可以采用工廠模式,將所有類的構造部分的代碼封裝到一起,這樣的代碼較爲簡潔。
誠然工廠模式有很多好處,但工廠模式也不是萬能的。其實很多情況下使用工廠模式并不一定會使代碼更加簡潔。如當構造兩個類的對象所需的參數個數、參數類型不相同時,就難以對這兩個類使用同一個工廠(可以使用可變長度參數、或HashSet,但如果兩個類差別很大的時候就應當考慮到底是否應該使用同一個工廠)。此外當整個程序沒有特別多的類、或者說只有一個類需要用來構造,這種情況下額外爲這一個類使用工廠模式可能不如直接new來得簡單。
如果要將工廠模式應用到我的作業1與作業2,就需要對整個程序進行重構,依照因子設計各個類而不是依照項。而如果按照現在我的作業1與作業2的情況,只有一個類或者只有兩個類,則沒有必要使用工廠模式。事實上,雖然我的作業2無法擴展迭代得到作業3,但單獨使用四元組處理作業2的問題就很容易,要考慮的内容不多,測試中不容易出現問題,也比較容易進行性能優化。所以我想作業2中沒有使用工廠模式也不見得就不好,還是要看具體應用場景。
五、心得體會
- Java很好用
- IDEA也很好用
- 面向對象真的很有意思
- 面向對象很難,有時候壓力很大
- 但是當做出來作業的時候又會很開心
- 個人認爲面向對象這個譯名不如物件導向
- 不過正則表達式聽起来要比規則運算式更加舒服
- 沒事別瞎寫README文檔,作業1就不小心把姓名學號寫上去了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号