


机器学习第八13次作业
1.读取
import csv # 用csv读取邮件数据,分解出邮件类别及邮件内容
file_path = r"E:\data\SMSSpamCollection.txt"
sms = open(file_path,"r", encoding = "utf - 8")
sms_data = []
sms_label = []
csv_reader = csv.reader(sms, delimiter="\t")
for line in csv_reader:
sms_label.append(line[0])
sms_data.append(line[1])
sms.close()
2.数据预处理
def preprocessing(text):
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
stops = stopwords.words('english')
tokens = [token for token in tokens if token not in stops]
tokens = [token.lower() for token in tokens if len(token) >= 3]
lmtzr = WordNetLemmatizer()
tokens = [lmtzr.lemmatize(token) for token in tokens]
preprocessed_text ="".join(tokens)
return preprocessed_text
3.数据划分—训练集和测试集数据划分
import numpy as np
sms_data = np.array(sms_data)
sms_label = np.array(sms_label)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(sms_data, sms_label, test_size=0.3, random_state=0,
stratify=sms_label) # 训练集,测试集
4.模型选择
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB().fit(X_train, y_train)
y_nb_pred = clf.predict(X_test)
因为MultinomialNB需估计的参数很少,对缺失数据不太敏感,算法也比较简单
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
print(y_nb_pred.shape, y_nb_pred) # x_test预测结果
print("nb_confusion_matrik:")
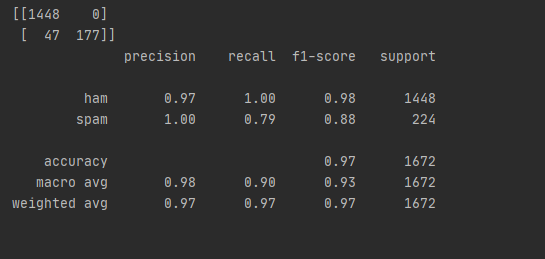
cm = confusion_matrix(y_test, y_nb_pred) # 混淆矩阵
print(cm)
print("nb_classification_report:")
cr = classification_report(y_test, y_nb_pred) # 主要分类指标的文本报告
print(cr)
feature_names = vectorizer.get_feature_names() # 出现过的单词列表
coefs = clf.coef_ # 先验概率 P(x_i|y),6034 feature_log_prob_
intercept = clf.intercept_ # P(y),class_log_prior_:array,shape(n_classes,)
coefs_with_fns = sorted(zip(coefs[0], feature_names)) # 对数概率P(x_i|y)与单词x_i映射
n = 10
top = zip(coefs_with_fns[:n], coefs_with_fns[:-(n + 1):-1])
for (coef_1, fn_1), (coef_2, fn_2) in top:
print("\t % .4f\t % -15s\t\t % .4f\t % -15s" % (coef_1, fn_1, coef_2, fn_2))
sms_label
print(len(x_train), len(x_test))
print(X_train.shape, X_test.shape)
x_train
X_train
a = X_train.toarray()
a
for i in range(1000):
for j in range(5984):
if a[i, j] != 0:
print(i, j, a[i, j])
vectorizer.get_feature_names()[1610]
上面是矩阵,下面是分析报告
6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获得所有文本的关键词,通过toarray()可看到词频矩阵的结果。
TfidfTransformer用于统计vectorizer中每个词语的TFIDF值。
将原始文档的集合转化为tf-idf特性的矩阵,相当于CountVectorizer配合TfidfTransformer使用的效果。
即TfidfVectorizer类将CountVectorizer和TfidfTransformer类封装在一起。
作者:卷心菜呀
链接:https://www.jianshu.com/p/caa4b923117c
来源:简书
