


机器学习第三次作业
2.鸢尾花长度聚类并作散点图代码
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
iris = load_iris()
#print(iris)
data = iris['data']
data1 = data[:,:1]
data1.shape
#print(data1.shape)
data2 = list(range(0,150))
n = len(data1)
m = data1.shape[1]
print(m)
k = 3
dist = np.zeros([n, k+1])#初始化数据
#1选中心
center = data1[:k, :]#初始类中心,即选取前3个样本作为初始类中心
centerNew = np.zeros([k, m])
while True:
#2求距离
for i in range(n):
for j in range(k):
dist[i, j] = np.sqrt(sum((data1[i, :]-center[j,:])**2))
dist[i,k] = np.argmin(dist[i, :k])#3归类
#4求新类中心
for i in range(k):
index = dist[:, k] == i
centerNew[i,:] = data1[index, :].mean(axis=0)
#5判断结果
if (np.all(center == centerNew)):
break
else:
center = centerNew
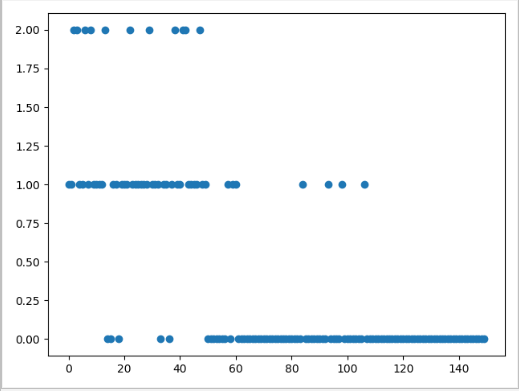
plt.scatter(data2,dist[:, k])
plt.show()
print('150个样本的归类:', dist[:, k])
截图
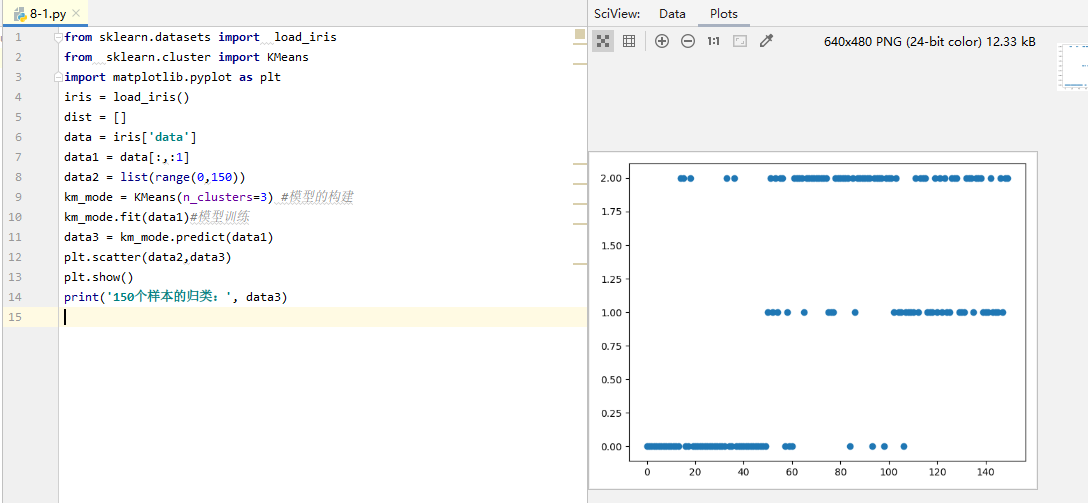
3、用from sklearn.cluster import KMeans库编写
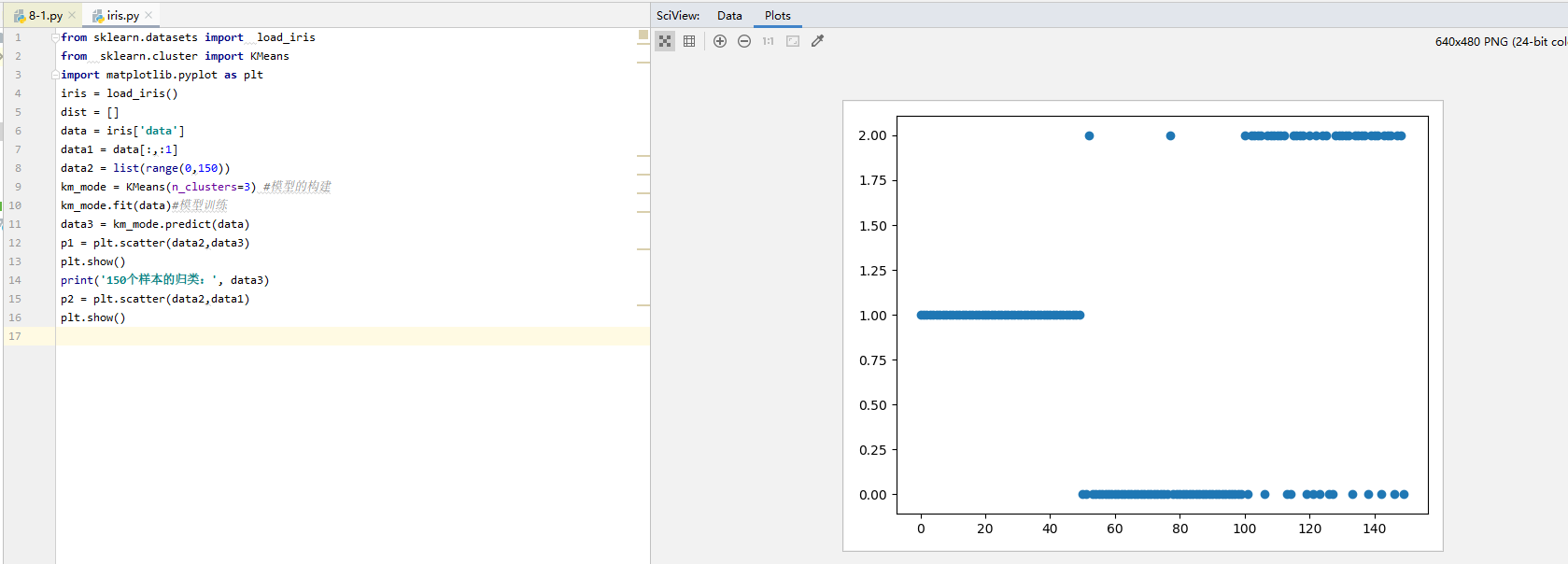
4、用完整的iris数据画散点图
5、想想k均值算法中以用来做什么
K均值用来做大数据的分类统计,比如及不及格,哪些人是中年人等等。通过分析得出哪些有共性的特性
