测试代码性能
输入相同,3 个函数的输出结果也相同。尽管如此,它们的性能差异还是很明显。为
了揭示性能差异,我们需要一些工具来测试每段代码的运行时间。最简单的便是
system.time( ) 函数。
测试任意表达式的运行时间,只需将代码封装在函数内。这里,我们测试 my_
cumsum1( ) 函数计算包含 100 个元素的数值向量所需的时间:
x <- rnorm(100)
system.time(my_ _cumsum1(x))
## user system elapsed
## 0 0 0
计时结果显示为 3 列:user、system 和 elapsed。我们关注的是用户时间。它衡
量的是代码运行所需的 CPU 时间。想要获得更详细的信息,可以运行 ?proc.time 查看
不同测量方法的差异。
上面的结果说明代码运行速度很快,以至于无法测量。再接着测试 my_cumsum2( ),
结果几乎是一样的:
system.time(my_ _cumsum2(x))
## user system elapsed
## 0.000 0.000 0.001
用内置函数 cumsum( ) 也会得到同样的结果:
system.time(cumsum(x))
## user system elapsed
## 0 0 0
计时结果没有达到我们的目的,因为输入的数据量太小,所耗费的时间小到无法测量。
现在,我们生成一个长度为 1000 的向量,再重复之前的步骤:
x <- rnorm(1000)
system.time(my_ _cumsum1(x))
## user system elapsed
## 0.000 0.000 0.003
system.time(my_ _cumsum2(x))
## user system elapsed
## 0.000 0.000 0.001
system.time(cumsum(x))
## user system elapsed
## 0 0 0
现在,可以肯定的是 my_cumsum1( ) 和 my_cumsum2( ) 确实需要花一点时间计
算出结果,但是差别并不明显。然而,cumsum( ) 的运行速度仍然很快,无法衡量。
我们继续用一个数据量更大的输入来看看能否揭示这 3 个函数的性能差异:
x <- rnorm(10000)
system.time(my_ _cumsum1(x))
## user system elapsed
## 0.208 0.000 0.211
system.time(my_ _cumsum2(x))
## user system elapsed
## 0.012 0.004 0.013
system.time(cumsum(x))
## user system elapsed
## 0 0 0
这下结果就很明显了:my_cumsum1( ) 要比 my_cumsum2( ) 慢 10 倍多,而内置
函数 cumsum( ) 仍然比我们编写的函数快很多。
需要注意的是,性能差异可能不是恒定的,尤其是当我们提供一个更大的输入时:
x <- rnorm(100000)
system.time(my_ _cumsum1(x))
## user system elapsed
## 25.732 0.964 26.699
system.time(my_ _cumsum2(x))
## user system elapsed
## 0.124 0.000 0.123
system.time(cumsum(x))
## user system elapsed
## 0 0 0
这个结果给出了一个惊人的对比:在输入向量长度数量级在 10 万时,my_cumsum1( )
比 my_cumsum2( ) 慢了 200 倍。而 cumsum( ) 函数则始终保持着极快的速度。
system.time( ) 函数可以测试一段代码的运行时间,但不是很精确。一方面,每
次测试的结果可能不同,我们需要重复足够多次才能做出有效对比。另一方面,计时器的
分辨率可能不够高,不足以说明我们感兴趣的代码的性能之间真正的差异。
microbenchmark 包则提供了比较不同表达式性能的更为精确的方法。请运行以下
代码来安装这个包:
install.packages("microbenchmark")
安装好之后,加载这个包,然后直接调用函数microbenchmark( )比较3 个函数的性能:
library(microbenchmark)
x <- rnorm(100)
microbenchmark(my_ _cumsum1(x), my_ _cumsum2(x), cumsum(x))
## Unit: nanoseconds
## expr min lq mean median uq
## my_cumsum1(x) 58250 64732.5 68353.51 66396.0 71840.0
## my_cumsum2(x) 120150 127634.5 131042.40 130739.5 133287.5
## cumsum(x) 295 376.5 593.47 440.5 537.5
## max neval cld
## 88228 100 b
## 152845 100 c
## 7182 100 a
需要注意的是,microbenchmark( ) 会默认将表达式运行 100 次,以便提供更多
运行时间的分位数。你可能会对此感到惊讶,当输入向量有 100 个元素时,我们编写的函
数中,my_cumsum1( ) 要比 my_cumsum2( ) 快一点。另外,时间的单位是纳秒(1
秒是 1000000000 纳秒)。
接下来,我们尝试将输入 1000 个数据:
x <- rnorm(1000)
microbenchmark(my_ _cumsum1(x), my_ _cumsum2(x), cumsum(x))
## Unit: microseconds
## expr min lq mean median
## my_cumsum1(x) 1600.186 1620.5190 2238.67494 1667.5605
## my_cumsum2(x) 1034.973 1068.4600 1145.00544 1088.4090
## cumsum(x) 1.806 2.1505 3.43945 3.4405
## uq max neval cld
## 3142.4610 3750.516 100 c
## 1116.2280 2596.908 100 b
## 4.0415 11.007 100 a
这次 my_cumsum2( ) 的运行速度比 my_cumsum1( ) 快一点。但是这两个函数都
比内置函数 cumsum( ) 慢很多。注意到,这里的时间单位变成了毫秒。
对于 5000 个数据的输入,my_cumsum1( ) 和 my_cumsum2( ) 的性能差异就更加
明显了:
x <- rnorm(5000)
microbenchmark(my_ _cumsum1(x), my_ _cumsum2(x), cumsum(x))
## Unit: microseconds
## expr min lq mean median
## my_cumsum1(x) 42646.201 44043.050 51715.59988 44808.9745
## my_cumsum2(x) 5291.242 5364.568 5718.19744 5422.8950
## cumsum(x) 10.183 11.565 14.52506 14.6765
## uq max neval cld
## 46153.351 135805.947 100 c
## 5794.821 10619.352 100 b
## 15.536 37.202 100 a
对于 10000 个数据的输入,对比结果亦是如此:
x <- rnorm(10000)
microbenchmark(my_ _cumsum1(x), my_ _cumsum2(x), cumsum(x), times = 10)
## Unit: microseconds
## expr min lq mean median
## my_cumsum1(x) 169609.730 170687.964 198782.7958 173248.004
## my_cumsum2(x) 10682.121 10724.513 11278.0974 10813.395
## cumsum(x) 20.744 25.627 26.0943 26.544
## uq max neval cld
## 253662.89 264469.677 10 b
## 11588.99 13487.812 10 a
## 27.64 29.163 10 a
前面所有的基准测试中,cumsum( ) 的性能看起来非常稳定,而且,随着输入向量
长度的增加,运行时间并没有明显变化。
为了更好地理解这 3 个函数性能的变化情况,我们创建以下可视化函数,输入不同长
度的向量,分别测试并查看函数的运行情况:
library(data.table)
benchmark <- function(ns, times = 30) {
results <- lapply(ns, function(n) {
x <- rnorm(n)
result <- microbenchmark(my_ _cumsum1(x), my_ _cumsum2(x), cumsum(x),
times = times, unit = "ms")
data <- setDT(summary(result))
data[, n := n]
data
})
rbindlist(results)
}
这个函数的逻辑很简单:ns 是一个数值向量,其中的元素就是输入向量的长度。注意
到,函数 microbenchmark( ) 以数据框的形式返回所有的测试结果,而函数 summary
(microbenchmark( )) 则返回之前的汇总表。用 n 来标记每条汇总情况,并逐行叠加
存储测试结果,然后用 ggplot2 包将结果进行可视化。
首先,用 100 到 3000,步长为 100 的序列来做基准测试:
benchmarks <- benchmark(seq(100, 3000, 100))
然后,创建一个图来显示 3 个函数的性能对比:
library(ggplot2)
ggplot(benchmarks, aes(x = n, color = expr)) +
ggtitle("Microbenchmark on cumsum functions") +
geom_ _point(aes(y = median)) +
geom_ _errorbar(aes(ymin = lq, ymax = uq))
图 13-1 展示了我们想要比较的 3 个版本的 cumsum 函数的性能差异:
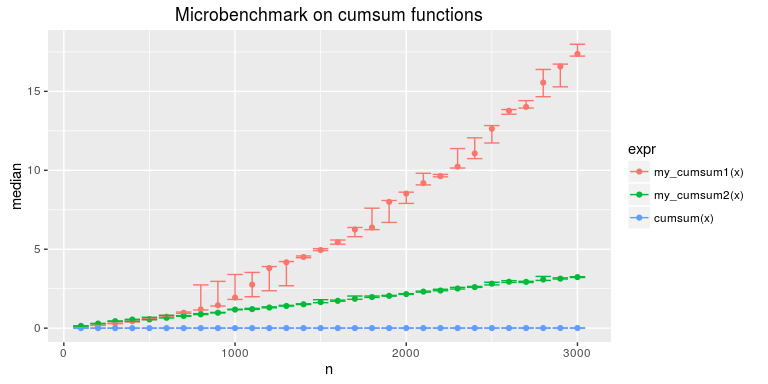
图 13-1
在图 13-1 中,我们把 3 个函数的结果放在一起。其中的点表示中位数,误差条表示 75%
和 25%分位数。
很明显,对于更长的输入来说,my_cumsum1( ) 的性能下降得更快,而 my_
cumsum2( )的性能几乎是随着输入长度的增加呈线性递减。但 cumsum( ) 的运行速度
一直非常快,其性能似乎并没有随着输入的增加而出现明显的衰减。
正如前面演示的那样,对于数据量比较小的输入,my_cumsum1( ) 要比 my_
cumsum2( )快一点。我们可以测试一下输入数据量比较小的情况:
benchmarks2 <- benchmark(seq(2, 600, 10), times = 50)
这次,我们将输入向量的长度限制在 2~600 之间,步长为 10。由于函数需要执行的
次数几乎是之前的两倍,为了保持总时间不变,我们把 benchmark( ) 中执行次数的参
数 times 由默认值 100 改为 50:
ggplot(benchmarks2, aes(x = n, color = expr)) +
ggtitle("Microbenchmark on cumsum functions over small input") +
geom_ _point(aes(y = median)) +
geom_ _errorbar(aes(ymin = lq, ymax = uq))
图 13-2 显示了输入数据量较小的情况下,函数的性能差异。
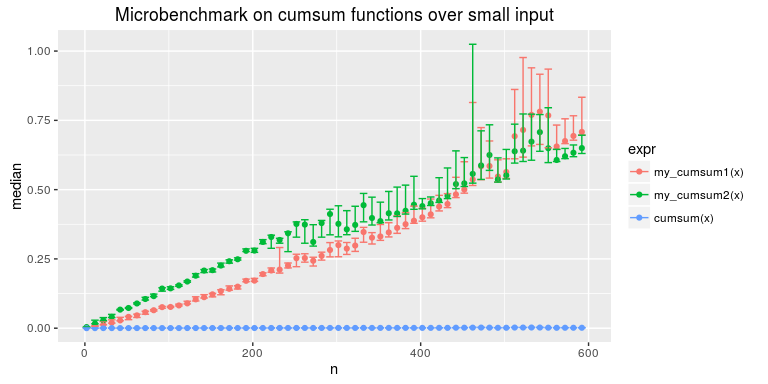
图 13-2
由图13-2可以看出,当输入的长度小于400左右时,my_cumsum1( ) 的运行速度比 my_
cumsum2( ) 快。然而,随着输入的数据量的增加,my_cumsum1( ) 性能的衰减速度要
比 my_ cumsum2( ) 快得多。
用数据量从 10~800 的输入可以更好地测试函数性能的动态评级:
benchmarks3 <- benchmark(seq(10, 800, 10), times = 50)
ggplot(benchmarks3, aes(x = n, color = expr)) +
ggtitle("Microbenchmark on cumsum functions with break even") +
geom_ _point(aes(y = median)) +
geom_ _errorbar(aes(ymin = lq, ymax = uq))
如图 13-3 所示:
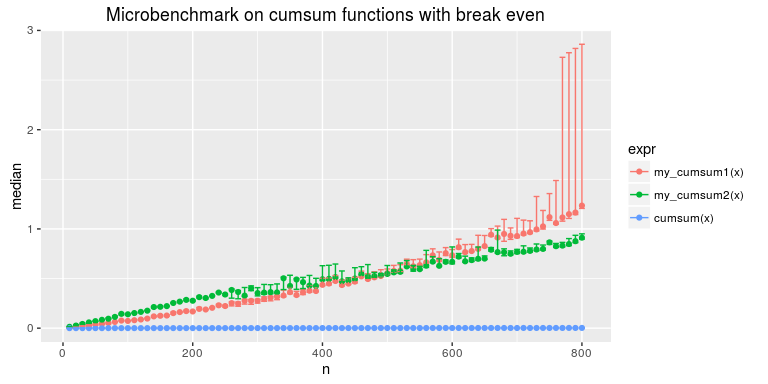
图 13-3
总之,不同函数实现过程中的一点小差别就有可能导致性能上的巨大差异。对于小数
据量的输入,差异通常不明显,但当数据量变大时,性能差异会变得非常显著,因此不该
被忽略。为了比较多个表达式的性能,我们可以使用 microbenchmark( )来代
替 system.time( )以获得更精确、更有用的结果。
