
data.table 中的动态作用域
data.table 中最常用的语法就是 data[i, j, by],其中 i、j 和 by 都是在动态
作用域中被计算的。换句话说,我们不仅可以直接使用列,也可以提前定义诸
如 .N 、.I 和 .SD 来指代数据中的重要部分。
演示之前,我们先创建一个新的 data.table ,并命名为 market_data,其中 date 列
是连续的。
market_data <- data.table(date = as.Date("2015-05-01") + 0:299)
head(market_data)
## date
## 1: 2015-05-01
## 2: 2015-05-02
## 3: 2015-05-03
## 4: 2015-05-04
## 5: 2015-05-05
## 6: 2015-05-06
就像调用函数一样,我们调用 := 向 market_data 中添加两列:
set.seed(123)
market_data[, `:=`(
price = round(30 * cumprod(1 + rnorm(300, 0.001, 0.05)), 2),
volume = rbinom(300, 5000, 0.8)
)]
注意到,price 是一个简单的随机游走过程,volume 是服从二项分布的随机数:
head(market_data)
## date price volume
## 1: 2015-05-01 29.19 4021
## 2: 2015-05-02 28.88 4000
## 3: 2015-05-03 31.16 4033
## 4: 2015-05-04 31.30 4036
## 5: 2015-05-05 31.54 3995
## 6: 2015-05-06 34.27 3955
然后,我们将数据以图形的方式展示出来,如图 12-3 所示。
plot(price ~ date, data = market_data,
type = "l",
main = "Market data")
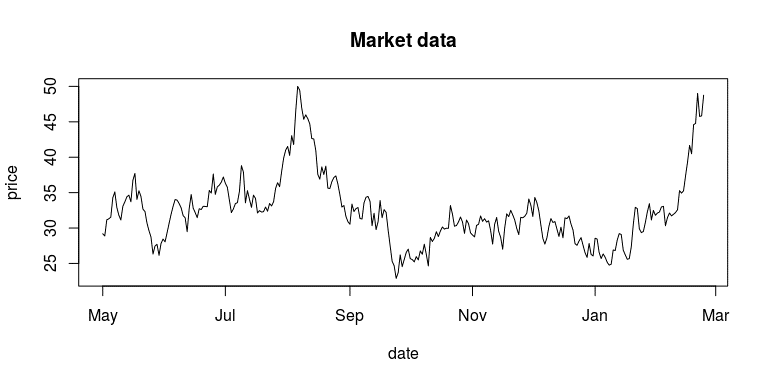
图 12-3
数据准备好之后,就可以通过聚合数据并发现动态作用域怎样让事情变得更简单。
首先,看一下 date 这一列的时间范围:
market_data[, range(date)]
## [1] "2015-05-01" "2016-02-24"
该数据也可以被整合缩减为 open-high-low-close(OHLC)的月度数据:
monthly <- market_data[,
.(open = price[[1]], high = max(price),
low = min(price), close = price[[.N]]),
keyby = .(year = year(date), month = month(date))]
head(monthly)
## year month open high low close
## 1: 2015
## 2: 2015
## 3: 2015
## 4: 2015
## 5: 2015
## 6: 2015
5 29.19 37.71 26.15 28.44
6 28.05 37.63 28.05 37.21
7 36.32 40.99 32.13 40.99
8 41.52 50.00 30.90 30.90
9 30.54 34.46 22.89 27.02
10 25.68 33.18 24.65 29.32
上述代码的含义是:先将数据按照 year 和 month 进行分组(根据 keyby 分组),然
后每一组生成一条 OHLC 记录(执行 j 表达式)。最后,不管 j 表达式返回的是一个 list,
或者 data.frame,还是 data.table,都会被堆叠在一起(成为列),最终生成一
个 data.table。
事实上,即使已经指定 by,j 表达式也可以是任意的。更确切地说,先根据 by 表达
式将原始数据分割,分割后的每个部分都是原始数据的一个子集,并且原始数据和子集都
是 data.table。然后,在每个子集 data.table 的语义中计算 j 表达式。例如,以下
代码没有按组聚合数据,而是画出了每一年的价格图,如图 12-4 所示。
oldpar <- par(mfrow = c(1, 2))
market_data[, {
plot(price ~ date, type = "l",
main = sprintf("Market data (%d)", year))
}, by = .(year = year(date))]
par(oldpar)
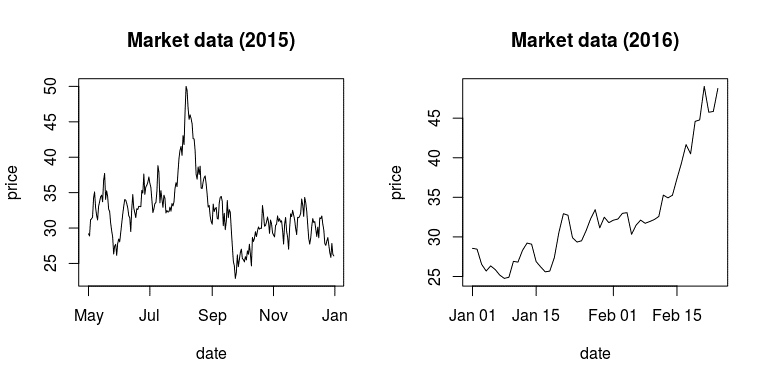
图 12-4
注意到,我们并没有为 plot( ) 设定 data 参数,图形也成功地画出来了。这是因为
plot( ) 是在子集 data.table 的语义中进行的,而这里的子集 data.table 就是原始
数据 data.table(即 market_data)按照 year 分组后得到的,其中 price 和 date 已
经被定义好了。
此外,j 表达式还可以是用于构建模型的代码。这里有一个批量拟合线性模型的例子。
首先,我们要从 ggplot2 包中载入 diamonds 数据集:
data("diamonds", package = "ggplot2")
setDT(diamonds)
head(diamonds)
## carat cut color clarity depth table price x y z
## 1: 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2: 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3: 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4: 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
## 5: 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6: 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
该数据集包含 53940 条钻石信息的记录,每条记录有 10 个属性。这里,我们对 cut 列
中的每种切割类型都拟合一个线性回归模型,由此观察每种切割类型中 carat 和 depth
是如何反映关于 log(price) 的信息。
在接下来的代码中,j 表达式拟合了一个线性模型,并将回归系数强制转换成一个列表。
注意到,针对 keyby 表达式的每个值都计算了 j 表达式。回归系数以列表形式返回,并且
都被储存在一个 data.table 中:
diamonds[, {
m <- lm(log(price) ~ carat + depth)
as.list(coef(m))
}, keyby = .(cut)]
## cut (Intercept) carat depth
## 1: Fair 7.730010 1.264588 -0.014982439
## 2: Good 7.077469 1.973600 -0.014601101
## 3: Very Good 6.293642 2.087957 -0.002890208
## 4: Premium 5.934310 1.852778 0.005939651
## 5: Ideal 8.495409 2.125605 -0.038080022
动态作用域也允许我们组合使用 data.table 内部或外部预定义的符号。举个例子,
我们定义一个函数,计算 market_data 中由用户定义的列的年度均值:
average <- function(column) {
market_data[, .(average = mean(.SD[[column]])),
by = .(year = year(date))]
}
在上述的 j 表达式中,.SD 表示按 year 分组后的所有子集 data.table。我们可以
使用 .SD[[x]] 来提取 x 列的值,这与通过名字从列表中提取成分或元素相同。
然后,运行以下代码,计算每年的平均价格:
average("price")
## year average
## 1: 2015 32.32531
## 2: 2016 32.38364
只需将参数变为 volume,就可以计算每年的平均数量:
average("volume")
## year average
## 1: 2015 3999.931
## 2: 2016 4003.382
我们也可以使用此包专门发明的语法,创造一个列数动态变化的组合,并且组合中的
列是由动态变化的名称决定的。
假设我们添加了额外的 3 列价格,每一列都是由原有的价格值加了随机噪声生成的。
不用重复调用 market_data[, price1 := ...] 和 market_data[, price2 := ...],而是
使用 market_ data[, (columns) := list(...)] 来动态地设定列,其中 columns
是一个包含列名的字符向量,list(...) 是 columns 中每个列的对应值:
price_cols <- paste0("price", 1:3)
market_data[, (price_cols) := lapply(1:3
function(i) round(price + rnorm(.N, 0, 5), 2))]
head(market_data)
## date price volume price1 price2 price3
## 1: 2015-05-01 29.19 4021 30.55 27.39 33.22
## 2: 2015-05-02 28.88 4000 29.67 20.45 36.00
## 3: 2015-05-03 31.16 4033 34.31 26.94 27.24
## 4: 2015-05-04 31.30 4036 29.32 29.01 28.04
## 5: 2015-05-05 31.54 3995 36.04 32.06 34.79
## 6: 2015-05-06 34.27 3955 30.12 30.96 35.19
另一方面,如果得到的表格有很多列,并且需要对它们的子集进行一些计算,也可以
用类似的语法来解决。想象一下,和价格相关的列中可能存在缺失值。我们需要对每个价
格列调用 zoo::na.locf( )。首先,我们使用正则表达式来获取所有的价格列:
cols <- colnames(market_data)
price_cols <- cols[grep("^price", cols)]
price_cols
## [1] "price" "price1" "price2" "price3"
然后,我们使用类似的语法,并且添加了一个参数.SDcols = price_cols,这是
为了使 .SD 中的列就只是我们想要的那些价格列。在以下代码中,对每个价格列调用 zoo::
na.locf( ),对应列的原始值都会被替换:
market_data[, (price_cols) := lapply(.SD, zoo::na.locf),
.SDcols = price_cols]
本节,我们演示了 data.table 的使用方法,体会了它是如何使得数据操作变得更简
便易用。请前往 https://github.com/Rdatatable/data.table/wiki 查看 data.table 的完整功能
列表。要想快速回顾使用方法,可以阅读 data.table 的简要说明 https://www.datacamp.com/
community/ tutorials/data-table-cheat-sheet。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步