
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow ——Chapter 1 Machine Learning Landscape
1.Machine Learning概念:
提到机器学习,很多人会想到机器人管家、终结者等一些不着边际,高大上的事物。实际上,机器学习在很多领域已经存在多年,例如:光学字符识别(OCR)。第一个机器学习应用是垃圾邮件过滤器,随后出现了数百个机器学习程序。本文介绍机器学习的一些重要概念(每位数据科学家都应该清楚):有监督与无监督学习,在线与批处理学习,基于实例与基于模型的学习等等。
机器学习:假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习。 (Tom Mitchell 1997)
以垃圾邮件过滤器为例来说明这个概念。 任务T就是“为新的电子邮件标记垃圾邮件标识” ;E就是训练样本(也就是已经由人工标记完了的邮件列表,也叫做训练集数据);P是绩效指标,程序能够正确分类的电子邮件占比。
1.1 为何使用机器学习?
机器学习的意义是什么呢?这章以垃圾邮件过滤器来例来做说明,对比垃圾邮件筛选器这个应用传统和机器学习方式的处理方法。
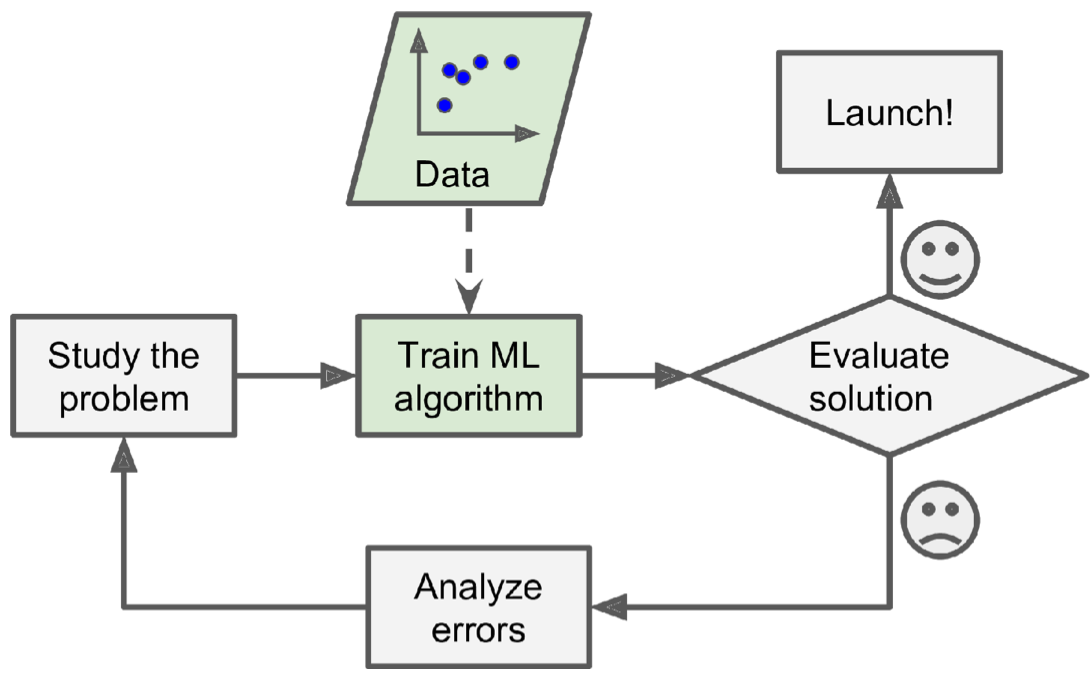
如果使用传统方式来识别一封垃圾邮件,该如何做呢?
首先,你会分析这些问题,并提炼总结一些规则:例如标题里包含某些字符串(信用卡、卖房等等)、某些人发的邮件(例如某电商网站)、邮件内容包含某些内容(成人视频等)。现在,你编写一个程序,一个邮件过来后,如果匹配了一个或者多个你前边提炼的模式规则,你就判断这封邮件是垃圾邮件。当然,你需要不断重复上边2个步骤,以达到你的程序能够覆盖更多的模式情况。这种方式不好的地方显而易见,你的规则会十分复杂(而且是越来越复杂,难以维护)。整体流程如下图所示:

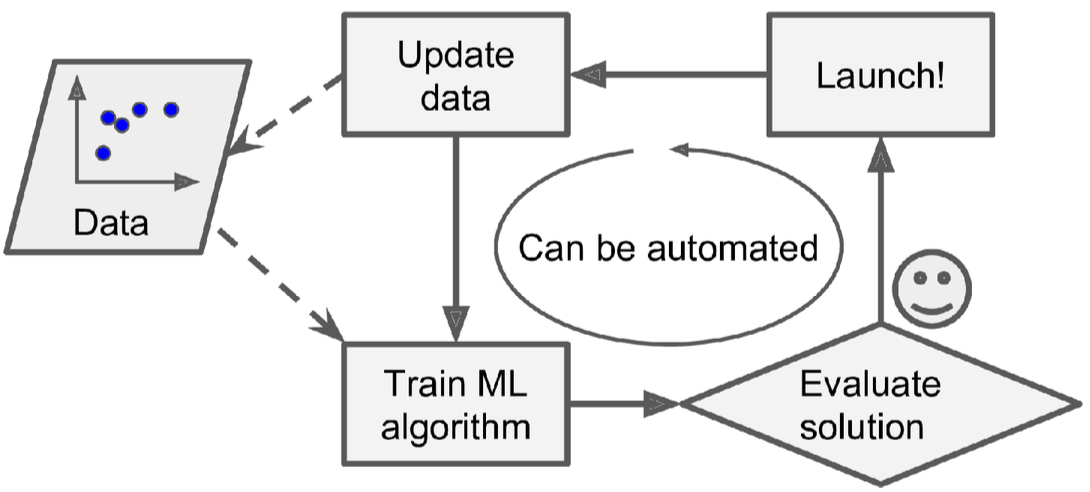
机器学习的程序则很简洁,机器学习程序自动学习识别出哪些词语更加能够标识出一封垃圾邮件,程序十分简洁。同时,如果邮件发送者发现自己某些带某字符串(例如“4U”)的邮件经常被标记为垃圾邮件,他们可能会修改为“For U”而逃过过滤器拦截,那么传统方式就需要修改程序了(因为需要增加一个pattern)。而机器学习程序能够根据用户标记为垃圾邮件的数据,自动学习出哪些词语在垃圾邮件中高频出现,并将包含这些词语的邮件标记为垃圾邮件,很容易维护。应用机器学习技术来挖掘大量数据可以帮助发现并非立即可见的模式。这称为数据挖掘。
 ,
, 
2.Machine Learning的类别:
2.1 监督、无监督、半监督和强化学习:
根据是否是在人的监督下学习,将ML分为了监督,无监督,半监督和强化学习。
2.1.1 监督学习:
所有训练集都有标签。
监督学习的训练集中包含最终结果(称为标签)。垃圾邮件过滤器是一个典型监督学习,另外回归任务房价预测(根据房子大小,卧室数量等特征)也是监督学习。一些回归算法也可以用于分类,反之亦然。以下是一些最重要的监督学习算法:
- k近邻
- 线性回归
- Logistic回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
2.1.2 无监督学习:
所有训练集都没有标签。
无监督学习中,训练数据集中不包含最终结果标签。常见聚类算法都是无监督学习。
聚类算法:
- K-均值
- DBSCAN
- 层次聚类分析(HCA)
一个相关的任务是降维,其目的是简化数据而不会丢失太多信息。 一种方法是将多个相关功能合并为一个。 例如,汽车的行驶里程可能与汽车的寿命密切相关,因此降维算法会将其合并为一个代表汽车磨损的特征。 这称为特征提取。另一个重要的无人监督任务是异常检测, 另外啤酒尿片的挖掘例子也是无监督学习的例子。
2.1.3 半监督学习:
部分训练集有标签。
由于标记数据通常很耗时且成本很高,因此您通常会拥有大量未标记的实例,而标记的实例却很少。 某些算法可以处理部分标记的数据。 这称为半监督学习。
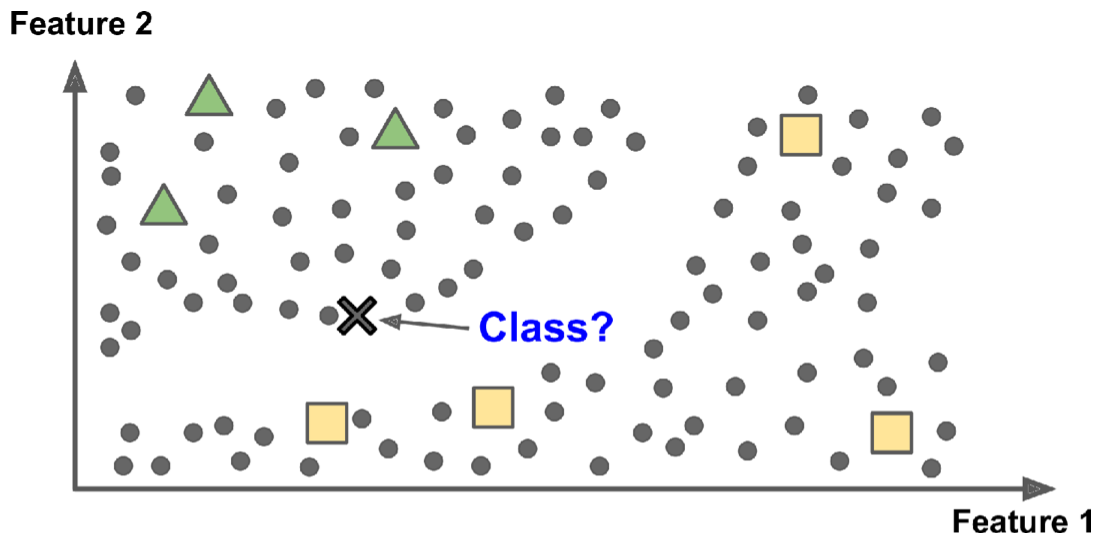
下图是一个半监督学习的例子,三角形和方形的示例是有标签的训练样本,圆形的点是无标签的点。该例子利用这些无标记的点,把心的点归类为三角形,而不是方形(虽然这个点离方形的样本点最近)。大多数半监督学习算法是无监督算法和有监督算法的组合。
2.1.4 强化学习:
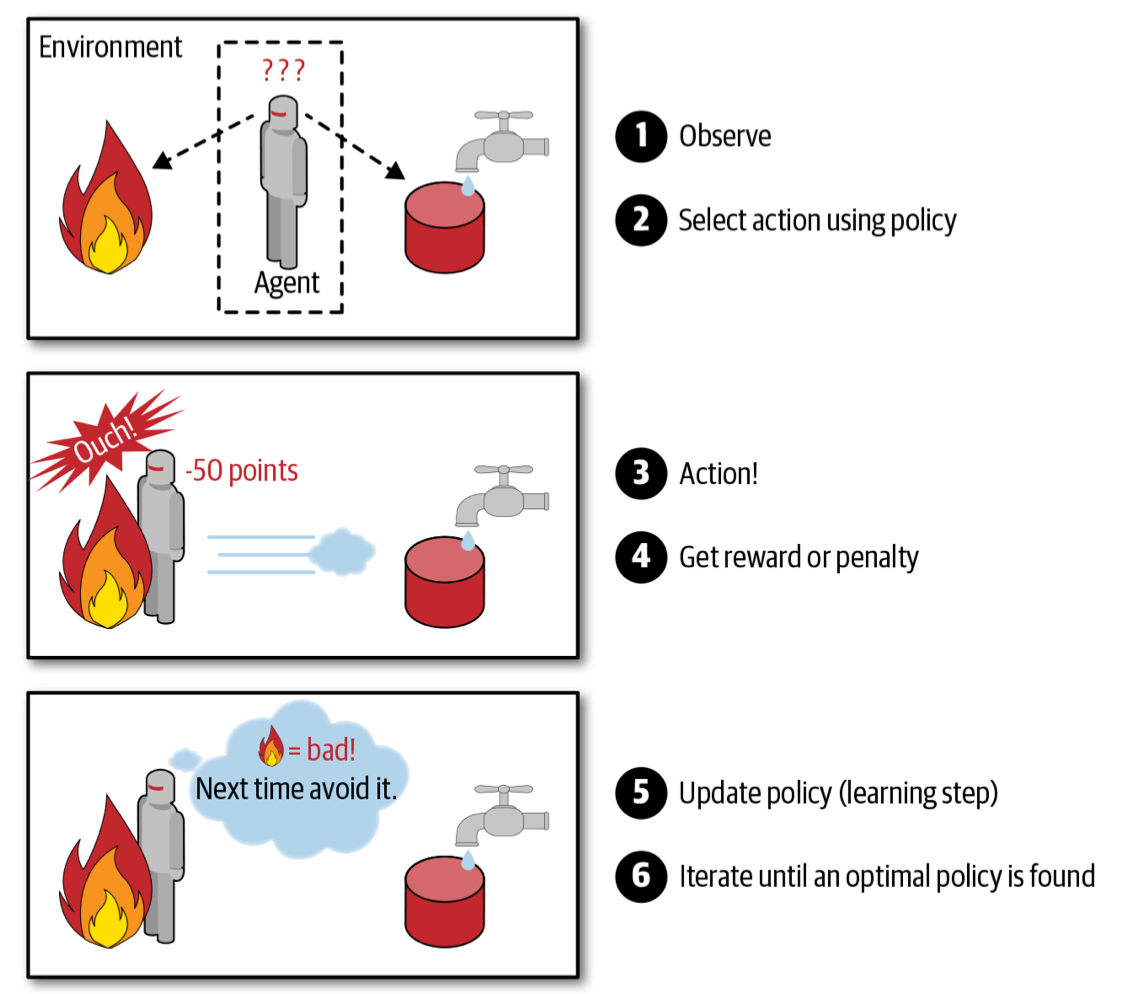
学习系统自己观察环境,并作出自己的选择,在作出正确选择时会获得奖励,在作出错误选择时,会获得惩罚。随着时间推移,强化学习系统必须找到一个策略,来获得最多的奖励。DeepMind的AlphaGo就是强化学习的例子,AlphaGo通过分析数百万场比赛,来学习获胜策略,之后AlphaGo和自己来对弈。
2.2 批量和在线学习:
用于对机器学习系统进行分类的另一个标准是: 系统是否可以从传入数据流中逐步学习。
2.2.1 批量学习(Batch Learning)
在批处理学习(Batch Learning)中,系统无法进行增量学习,所以需要获取所有的训练数据,对模型进行训练,产出后投入生产并运行。一般可以离线运行,并且该模型只适用于其所学习的样本。这种方式比较简单,但是需要耗费较多的CPU和其他资源。
如果希望批处理学习系统了解新的数据(例如新型垃圾邮件),则需要从头开始在整个数据集上训练系统的新版本(不仅是新数据,还包括旧数据),然后停止旧系统并用新系统替换它。
2.2.2 在线学习(Online learning)
在线学习以连续的小批量数据来逐步训练模型。在线学习非常适合那些连续不断地接收数据(例如股票价格)并且需要适应快速或自主变化的系统。
在线学习系统的一个重要参数是模型适应变化数据的速度,称为学习率。如果设置较高的学习率,那么系统将迅速适应新数据,但也往往会很快忘记旧数据。相反,将学习率设置得较低,则系统将具有更大的惯性,也就是说,它将学习得更慢,但对新数据中的噪声或非代表性数据点序列(异常值)的敏感性也将降低。
下图表示:online learning模型先上生产环境,再源源不断地学习小批量数据:
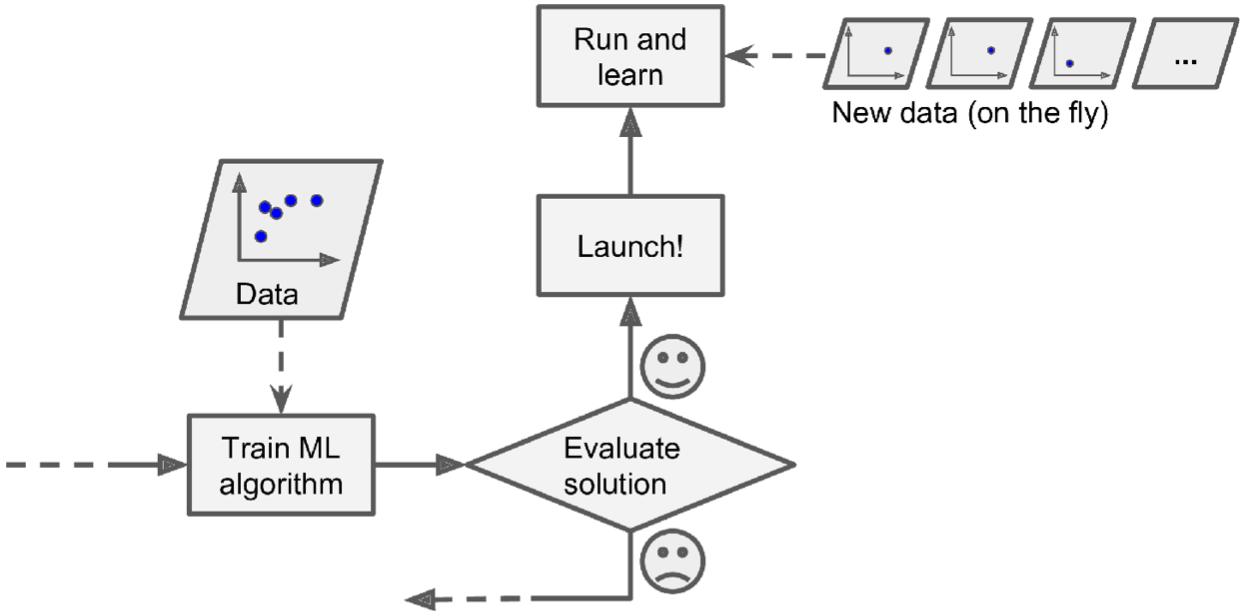
下图表示:使用online learning来处理大批量训练数据(模型训练 机器无法存储这么巨大的训练数据集):
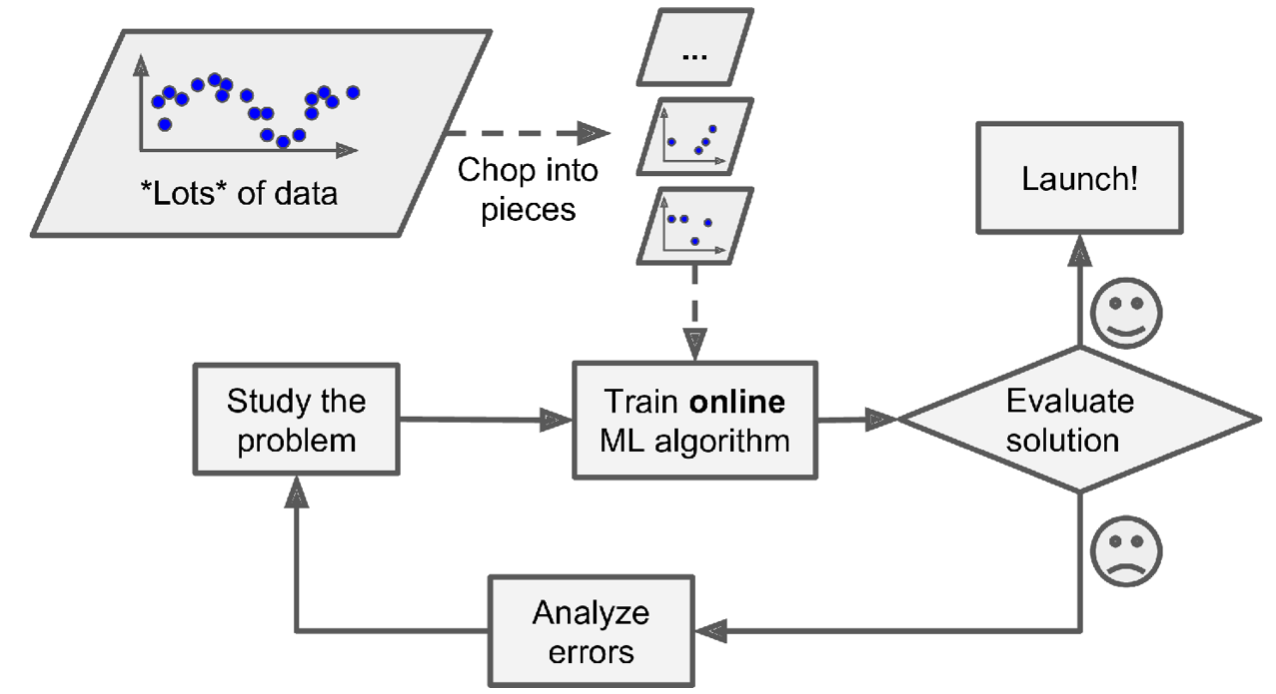
通过以上描述,会发现Online learning的一个比较大的挑战和问题是,如果新来的小批数据中包含过多噪声数据,会严重影响模型训练效果。如果发现新数据中有大量杂质,应该立即停止学习过程。
2.3 基于实例与基于模型的学习
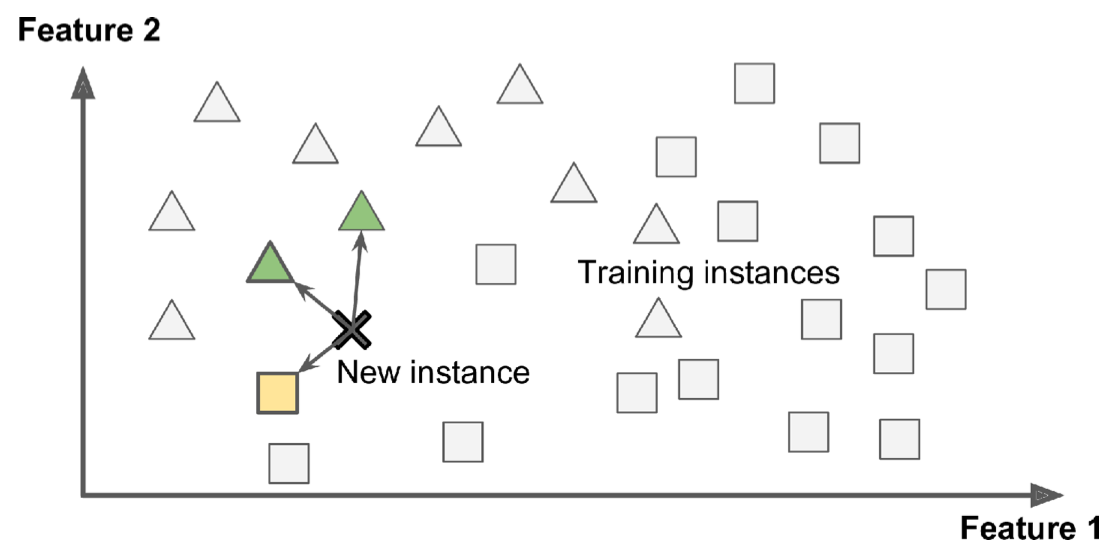
下面简单描述下基于实例和基于模型学习的区别。首先,机器学习的最终目的,肯定是使模型具有更好的泛化能力,也就是该模型对一个新的样本的预测准确能力更强。在对一个新的示例来分类时,我们有2种方式,第一种是比较与该新示例最相似的几个训练样本,并取这些样本的分类标签作为该新的样本的归类标签,这就是基于实例的学习。
下图描述了基于实例的学习,找出与new instance相似度最高的三个样本,其中2个归类三角形,一个归类方形,那么new instance归类为三角形。
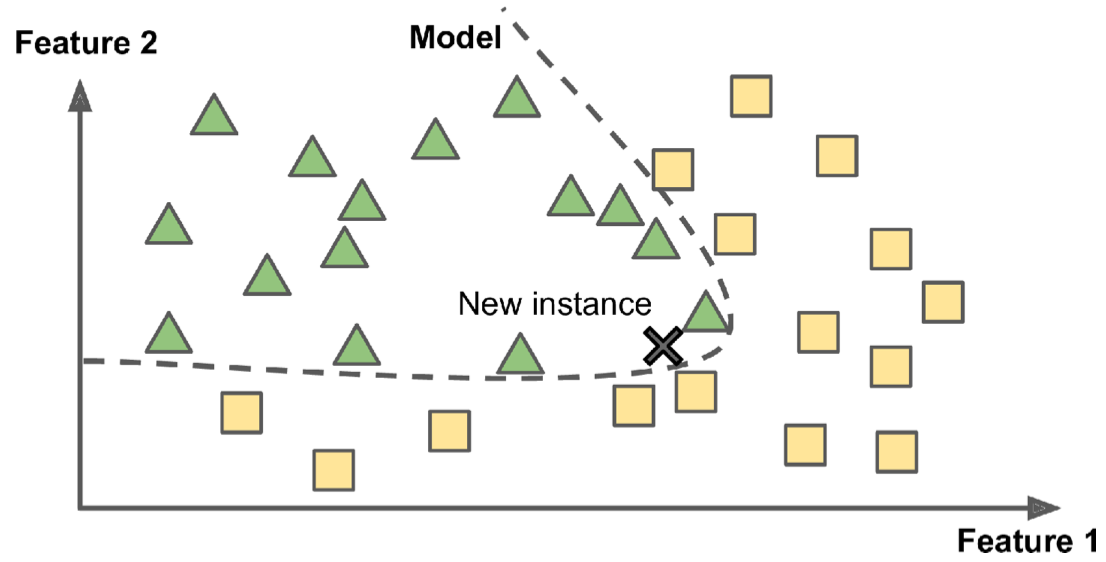
下图描述了基于模型的学习,与上边方法不同,这种方法训练出一个模型,再利用new instance带入模型,发现new instance属于三角形类别。
3. 使用Scikit-Learn训练和使用线性模型:
下边代码使用python3,使用scikit-learn包的线性回归模型,做线性回归。


1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn import linear_model 5 6 7 def prepare_country_stats(oecd_bli, gdp_per_capita): 8 oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"] 9 oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value") 10 gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True) 11 gdp_per_capita.set_index("Country", inplace=True) 12 full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita, 13 left_index=True, right_index=True) 14 full_country_stats.sort_values(by="GDP per capita", inplace=True) 15 remove_indices = [0, 1, 6, 8, 33, 34, 35] 16 keep_indices = list(set(range(36)) - set(remove_indices)) 17 return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices] 18 19 20 if __name__ == '__main__': 21 # Load Data 22 oecd_bli = pd.read_csv("dataset/oecd_bli_2015.csv", thousands=",") 23 gdp_per_capita = pd.read_csv("dataset/gdp_per_capita.csv", thousands=",", delimiter="\t", encoding="latin1", na_values="n/a") 24 25 # Gen Statics dat 26 country_stats = prepare_country_stats(oecd_bli, gdp_per_capita) 27 X = np.c_[country_stats["GDP per capita"]] 28 y = np.c_[country_stats["Life satisfaction"]] 29 30 # Visualize the data 31 country_stats.plot(kind="scatter", x="GDP per capita", y="Life satisfaction") 32 plt.show() 33 34 model = linear_model.LinearRegression() 35 model.fit(X, y) 36 37 testX = [[22587]] 38 print(model.predict(testX))
4.机器学习的挑战:
机器学习的主要任务是选择一种学习算法并在某些数据上对其进行训练,所以出错的可能包括:“错误算法” 和 “错误数据”。
4.1 错误数据:
先考虑数据问题,总结起来,数据问题可以分为以下几点:
- 数据样本量不足;
- 训练数据采样偏差(也就是训练样本不能完全反映全量数据的分布情况);
- 数据质量较差(值得花大量时间来去除离群值和噪声);
- 不相关特征,ML成功的关键是训练数据尽量包含相关特征,而尽量不包含不相关特征。
- 这里涉及到了一个重要工作就是特征工程。包括特征选择、特征提取(也就是之前说的降维,创建新的特征)、通过收集新数据来创建新特征。
4.2 错误算法:
算法问题常见有以下一些:
- 模型过拟合:模型对训练数据拟合的很好,但是泛化能力很差;
- 模型欠拟合;
5.测试和验证:
为了保证算法模型的质量,需要将样本集划分为训练集和测试集

