
性能度量之Confusion Matrix
例子:一个Binary Classifier
假设我们要预测图片中的数字是否为数字5。如下面代码。
X_train为训练集,每一个instance为一张28*28像素的图片,共784个features,每个feature代表某个像素的颜色强度(0-255之间)。y_train_5为label, boolean类型的向量。
from sklearn.linear_model import SGDClassifier sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
784个features:
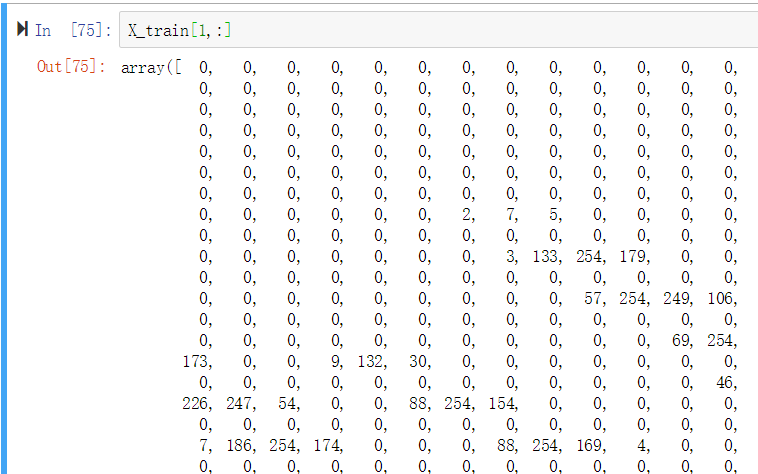
label,True代表是5,False代表非5.

使用Cross-Validation计算精确度
我们使用sklearn的cross validation,对训练集进行分层抽样为3份,每次对不同的抽样进行评估(训练则是使用其他另外2份抽样)。

我们发现,准确率非常高,高的让人怀疑。 如果图片中10%都是5的话,那么我们可以自定义一个模型,不用训练,只是在predict的时候,输出false,即一直认为所有图片里的数字都不是5,那么达到的准确率也是90%,如下所示: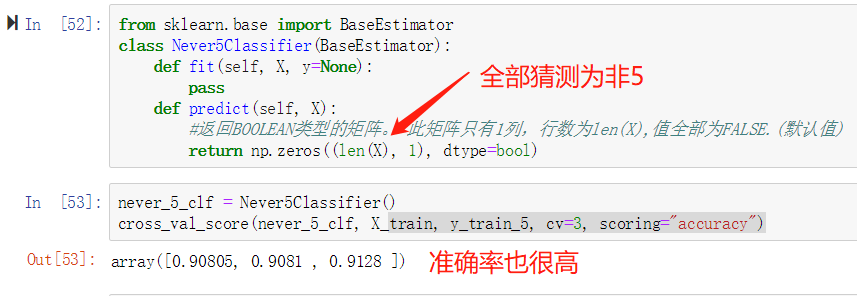
所以,从上面的例子说明,评估模型的性能不能单单看准确率,特别是面对倾斜数据(skewed datasets)的时候(某些类别的频率很高的情况)。
Confusion Matrix
Confusion Matrix背后的思想是计算Class A的实例被归类为Class B的次数。我们的例子使用的是二元分类(confusion matrix矩阵包含两行两列),但是对多元分类同样适用。
前面,我们使用cross validation计算的是准确性(scoring="accuracy"),为求出confusion matrix,我们需要得到具体的预测值,而不是score="accuracy"。我们通过cross_val_predict求出训练集的预测值y_train_pred。True, False分别表示判断出对应的图片/实例是5后者不是5
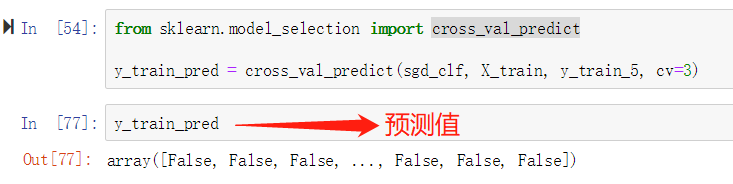
然后通过使用confusion_matrix计算出confusion matrix如下。另外,我们还看到,如果将预测值修改为实际值,左下右上的值都为0,下面我们将详细介绍其含义。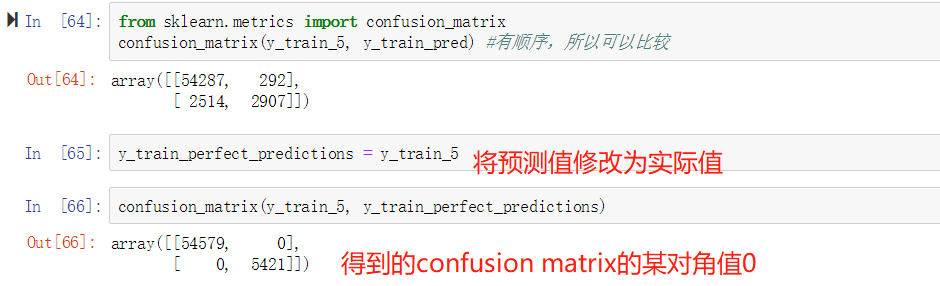
在上面的confusion矩阵中,每行表示真实的分类(actual class),而每列代表预测的分类(predicted class)。第一行全部为非5的图片(nagative class),第二行全部为5的图片(positive class)。因为是二元分类,所以矩阵的shape是(2,2)即两行两列。第一行中,第一列的值代表54287张图片被正确地判断为非5(真阴性,Ture Nagative),第二列的值代表292张图片被错误地判断为5(假阳性, False Positive)。第二行中,第一列的值代表2514张图片被错误地判断为非5(False Nagative),第二列的值2907张图片被正确地判断为5(True Positive). 所以,完美的分类算法是只有True Natative 和 True Positive的。Confusion Matrix包含的信息很多,我们可以求出精确度:Precision = TP/(TP+FP)。但是仅仅精确度是没法衡量模型性能的,我们同时也要看reacall:Recall = TP/(TP+FN)。希望下面这张图能能更清楚地表达Conofusion Matrix。
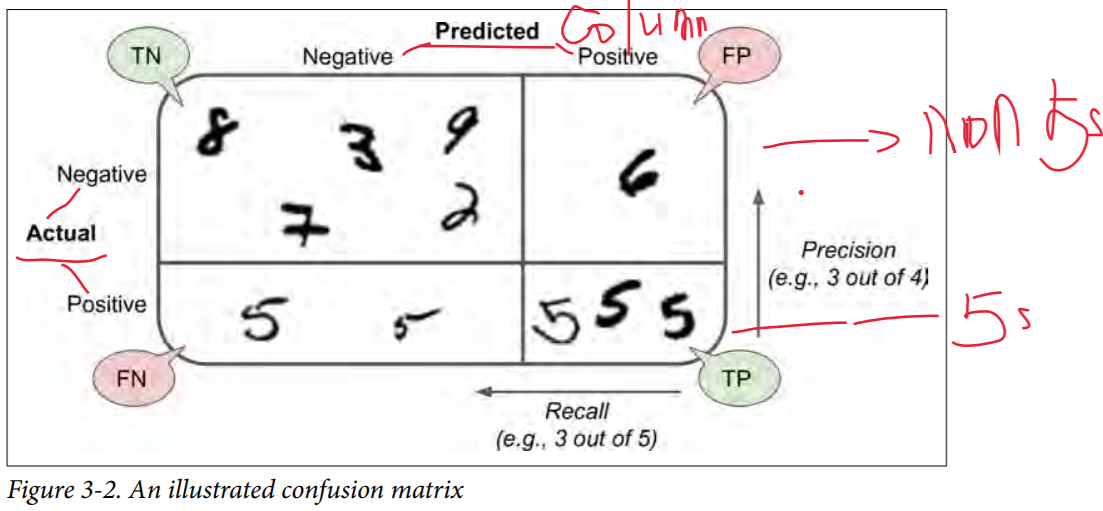
Precision精确度 , Recall(Also sensitivity, TPR-true positive rate) 召回率
我们通过sklearn求出的precision和recall和我们之前得到的confusion matrix一致。precision表示当模型识别一张图片为5时,正确率在90%以上。但是,它只识别了53%为5的图片,很差劲对吧?
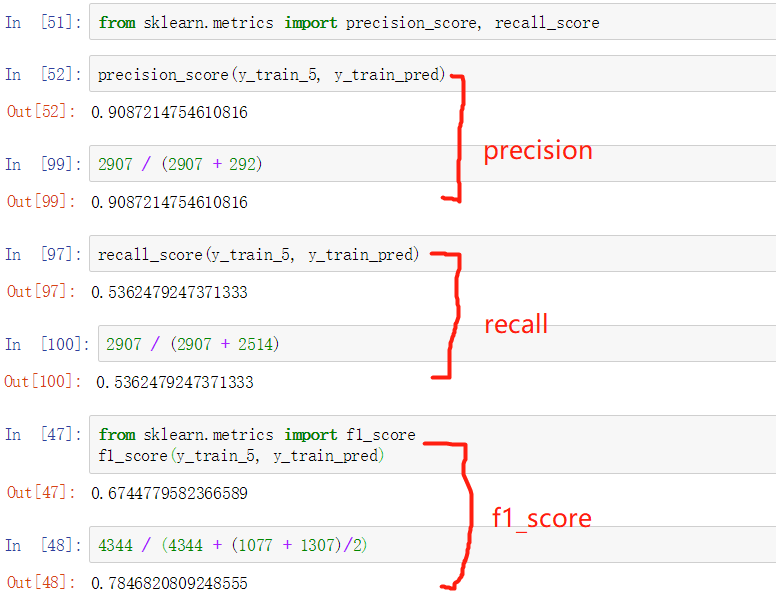
我们可以将两者的调和平均数(harmonic mean) F1 score作为单独的度量来使用。因为当两者值都高时,F1 score才会高。公式如3-3所示。
也有一些时候,我们可能并不关心F1 score(两者的综合得分)。可能更关心precision或者更关心recall. 比如,我们需要过滤掉少儿不宜的视频(识别有害视频),这个时候,我们应该看重的是precision。(模型宁可把正常的视频当成有害的,也不能把有害的当成正常的). 再比如,超市的监控系统通过画面识别偷窃行为,那可能更需要关注recall。(我们宁可多一些误报,也不想放过真正的小偷造成损失)。不幸的是,我们不能同时提高两者,增加一个,势必减小另一个,如同某个算法的空间复杂度和时间复杂度一样需要平衡。这叫做precision/recall tradeoff。下面我们详细说明。
Precision / Recall Tradeoff
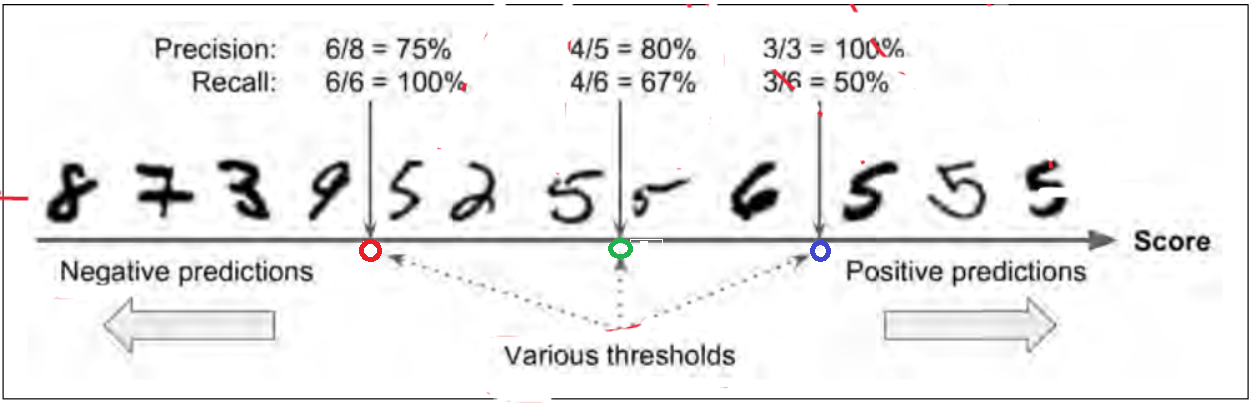
对于每个实例,模型会根据一个decision function计算出score,凡是score大于某个阈值(threshold),就归为positive 类,小于则归为nagative类。此例子中的SDGClassifier使用0作为默认的阈值。下图中,score从左至右增大。如果我们将阈值设置为绿圈所在值,那么绿圈右边全被判断为5,左边全部被识别成非5. precision=4/(4+5)=80%, recall=4/(4+2)=67%。 如果我们将阈值向右移动到蓝圈处(增大阈值),我们计算的precision=3/(3+0)=100%, recall=3/(3+3)=50%。通过增大阈值,我们增大了precision,减小了recall. 同样,我们如果将阈值移到红圈的地方(减小阈值),则增大了recall,减小了precision。
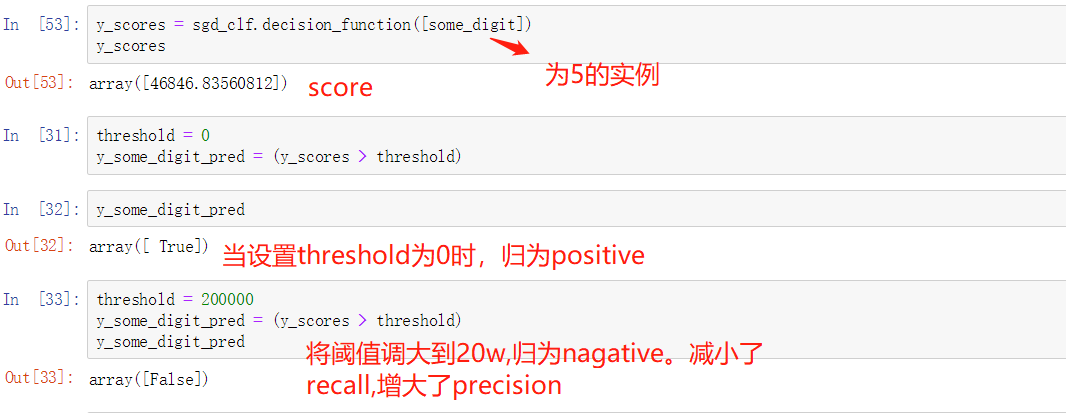
sklearn没有直接设置阈值去predict的方法,不过,我们可以通过decision_function计算出score来调整结果。如下所示,some_digit是某个实际值为5的图片。
为了设置阈值,我们需要通过cross validation先计算出所有实例的score(而不是预测结果),然后通过sklearn的precision_recall_curve画出precision和recall随着不同阈值变化的曲线图
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") from sklearn.metrics import precision_recall_curve precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
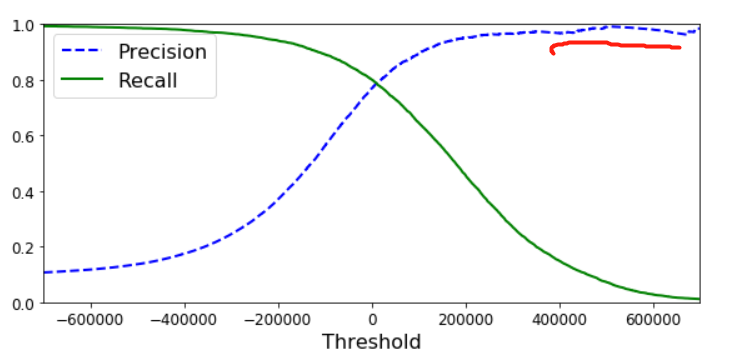
你是否注意到precision的曲线并不像recall那样平滑,事实上,当增加threshold的时候,precision是不一定增加的,而recall一定不会增加。比如,我们将之前的阈值从绿圈向右移动到绿圈蓝圈之间(数字5,6之间),相比绿圈,其precision=3/(3+1)=75%,反而下降了。recall=3/(3+3)=50%,下降属于正常。这就解释了为什么precision曲线不一定很平滑。现在,你可以选择阈值达到precision/recall平衡来适应你的需求了。我们也可以直接画出两者的关系,来选择平衡点。
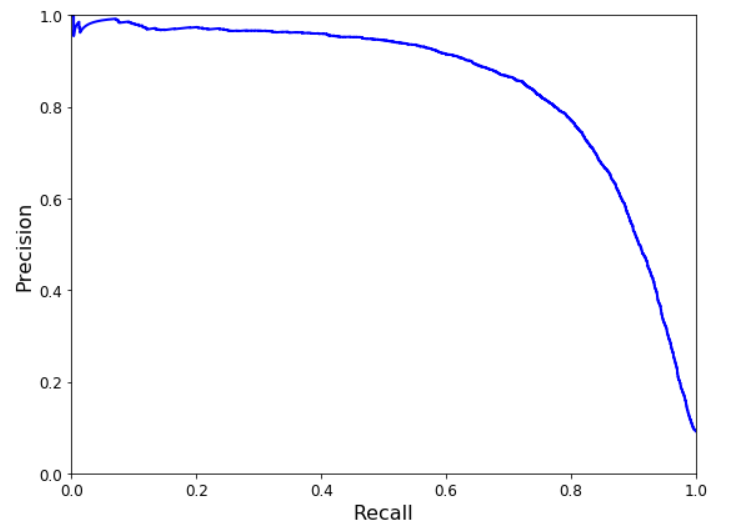
我们可以看到,precision在80%后,下降的很厉害(recall上升的很厉害),所以,你可能想选择有一个在大幅度下降之前的值,recall为60% 。 我们可以通过上一张图确定阈值大概为70000(需要zoom),运行如下代码得到新的预测值。
y_train_pred_90 = (y_scores > 70000)
验证precision/recall
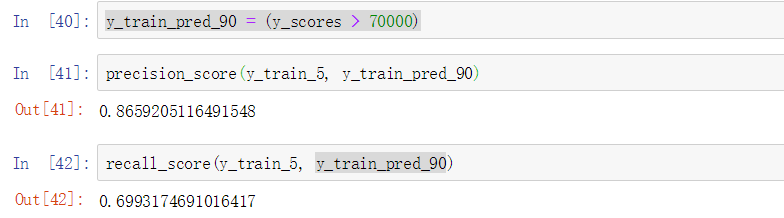
了解了confusion matrix后,如果某某声称其模型的precision很高时,我们应该问模型的recall是多少。因为任何一个很低的时候,模型大多情况下是没有太大意义的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号