
一、确认情况:
1、mrp进程等待gap:
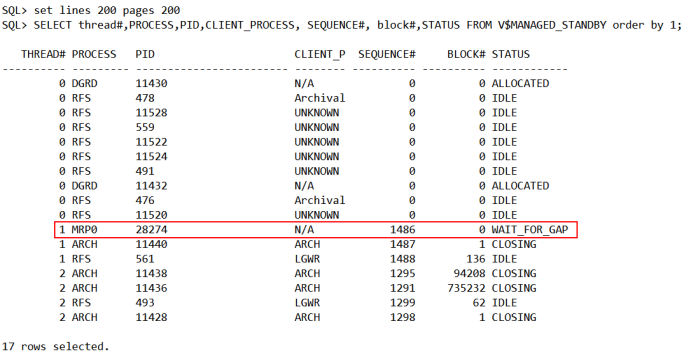
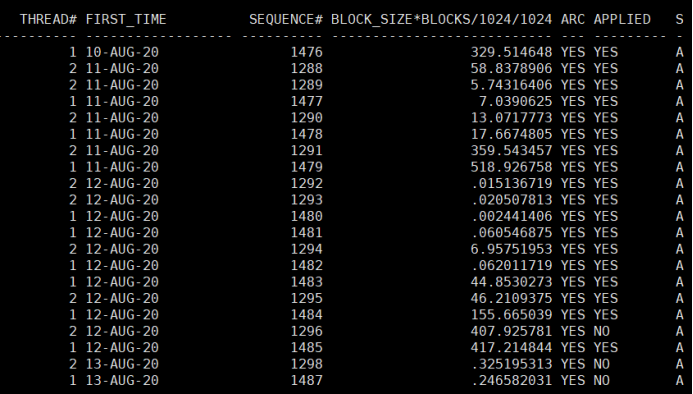
2、确认日志应用情况:
|
select thread#,first_time,SEQUENCE#,block_size*blocks/1024/1024,archived,applied,statu from v$archived_log where first_time>sysdate-10 order by 2 |
3、确认gap:
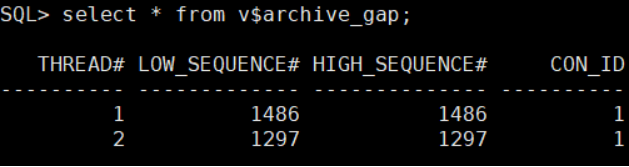
确认产生了gap,且在源端确认,确实的归档已经不存在,且nub没有备份。
基于如上结论,得知归档产生了gap,备端db需要恢复。
二、进行恢复
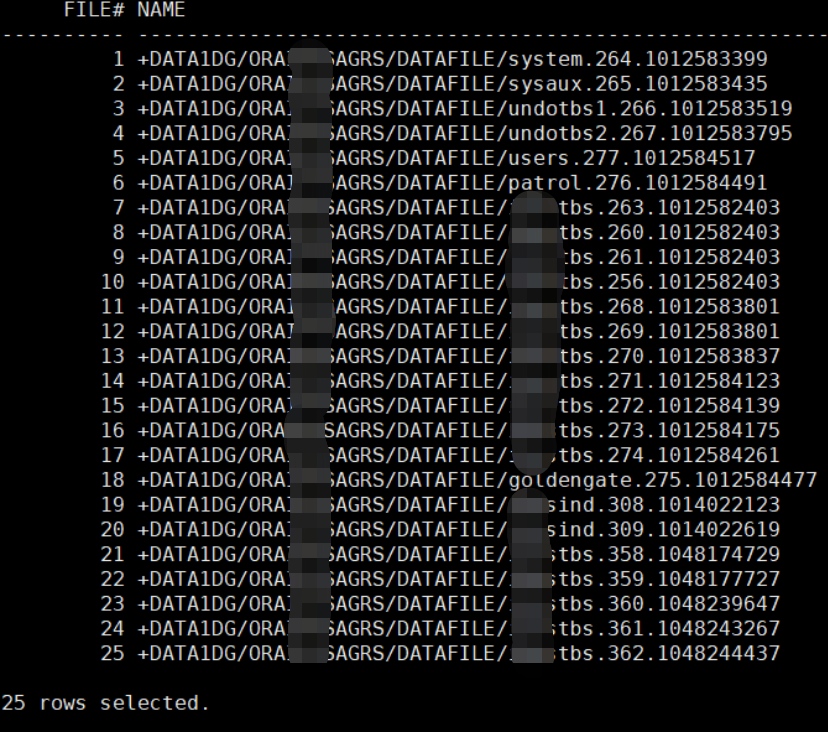
1、 备份数据文件信息:
|
col name for a70 set lines 200 pages 200 Select file#,name from v$datafile; |
主库:
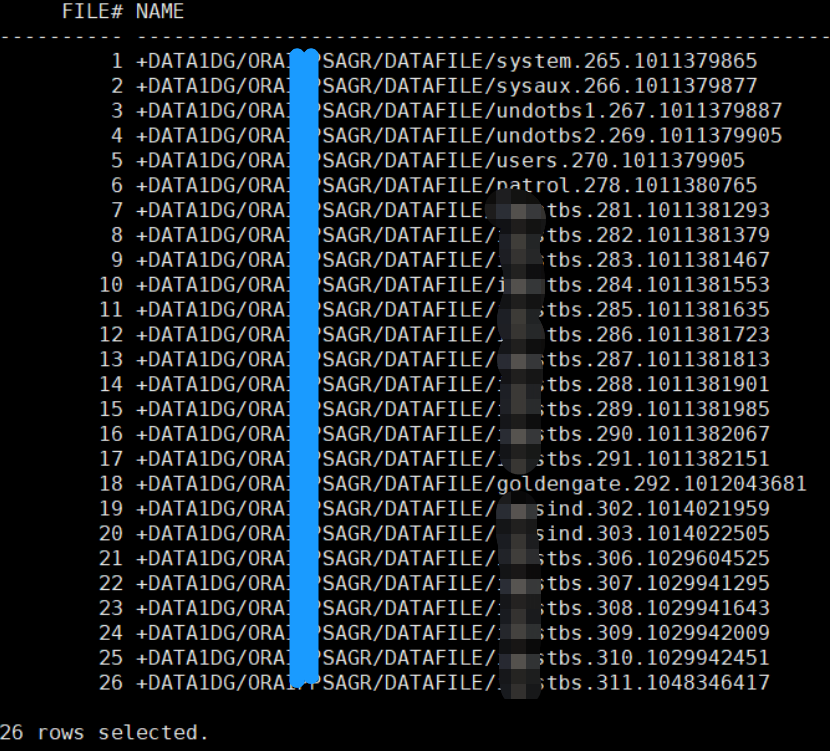
备库:
2、 备份standby db 当前控制文件:
SQL> alter database backup controlfile to '/tmp/control.bak20200813';
3、 获取备库最后的scn,以下面最小的scn
|
col current_scn format 99999999999999999 select current_scn from v$database;SQL>
CURRENT_SCN ------------------ 226206611
SQL> Select min(fhscn) from x$kcvfh;
MIN(FHSCN) -------------------- 226206612 |
4、 确认主库是否添加了新的数据文件:
|
set linesize 300 col name for a70 select file#,name from v$datafile where creation_change#>=226206611;SQL> SQL>
FILE# NAME ---------- ---------------------------------------------------------------------- 26 +DATA1DG/ORAxxxxAGR/DATAFILE/xxxxtbs.311.1048346417
|
5、主库基于scn备份,并传输到备库1节点:
|
rman target / run{ allocate channel c1 device type disk; allocate channel c2 device type disk; allocate channel c3 device type disk; allocate channel c4 device type disk; backup as compressed backupset INCREMENTAL FROM SCN 226206611 database format '/oracle/backup/db_inc_%U.bak'; backup current controlfile for standby format '/oracle/backup/standby_controlfile.ctl'; release channel c1; release channel c2; release channel c3; release channel c4; }
cd /oracle/backup scp * 22.XX.XX.99:/nocopy/oracle_backup/backup |
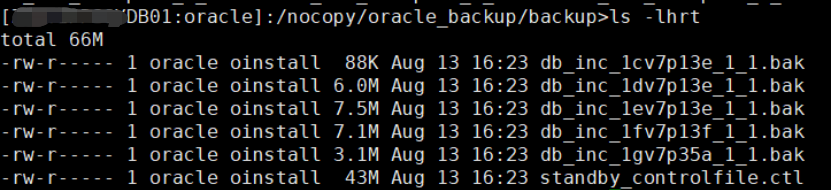
400多G的主库备份出来只有不到100M
(增量全备虽然量比较小,但是也要将所有数据文件都扫描一遍,所以如果主库较大,会占用较多的物理IO,且速度不会太快)
6、关闭备库2节点。
7、备库1节点停止mrp,更改standby_file_management为manual,启动到no
mount状态:
|
alter database recover managed standby database cancel; alter system set standby_file_management=manual; shutdown immediate; startup nomount; |
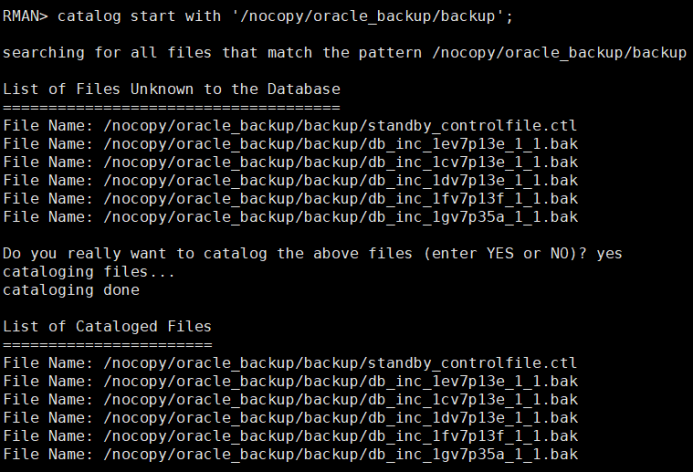
8、备库1节点恢复控制文件并注册备份集:
|
rman target /
restore standby controlfile from '/nocopy/oracle_backup/backup/standby_controlfile.ctl';
alter database mount;
catalog start with '/nocopy/oracle_backup/backup';
|
9、使用增量备份恢复备库与主库差别的数据文件(主库未新建文件可跳过):
|
run { allocate channel c0 type disk; set newname for datafile 26 to '+DATA1DG'; restore datafile 26; release channel c0; } |
10、向新控制文件中注册datafile:
在使用omf时,重建备库控制文件之后,记录的数据文件路径和名字会变为 MUST_RENAME_THIS_DATAFILE,此时无法使用alter database rename file 'AAAA' to 'BBBB'; 无论将AAAA写成源端的数据文件路径,还是当前备库转换的数据文件路径,都不会识别会报ORA-01516。需要将备库的数据文件路径,catalog进控制文件,注册所有数据文件,并进行switch to copy操作
查看当前控制文件中记录的datafile信息:
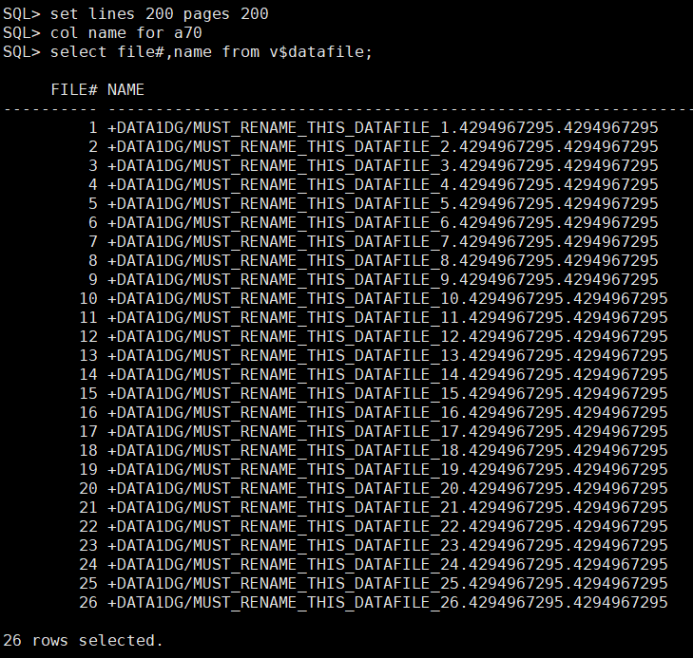

(当前控制文件中显示的路径为MUST_RENAME_THIS_DATAFILE,且alert中报错)
向新控制文件中注册datafile:
|
catalog start with '+DATA1DG/ORAIPPSAGRS/DATAFILE'; |

进行switch:
|
Switch database to copy; |
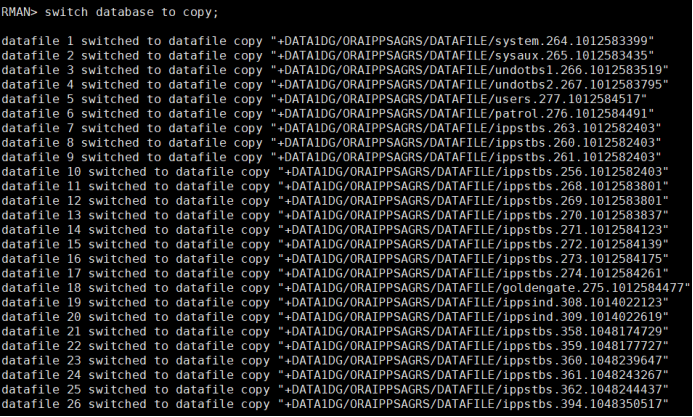
11、恢复数据库:
|
recover database noredo; |
12、重新格式化所有log:
(1)查看log file
|
Select * from v$logfile order by 1; |
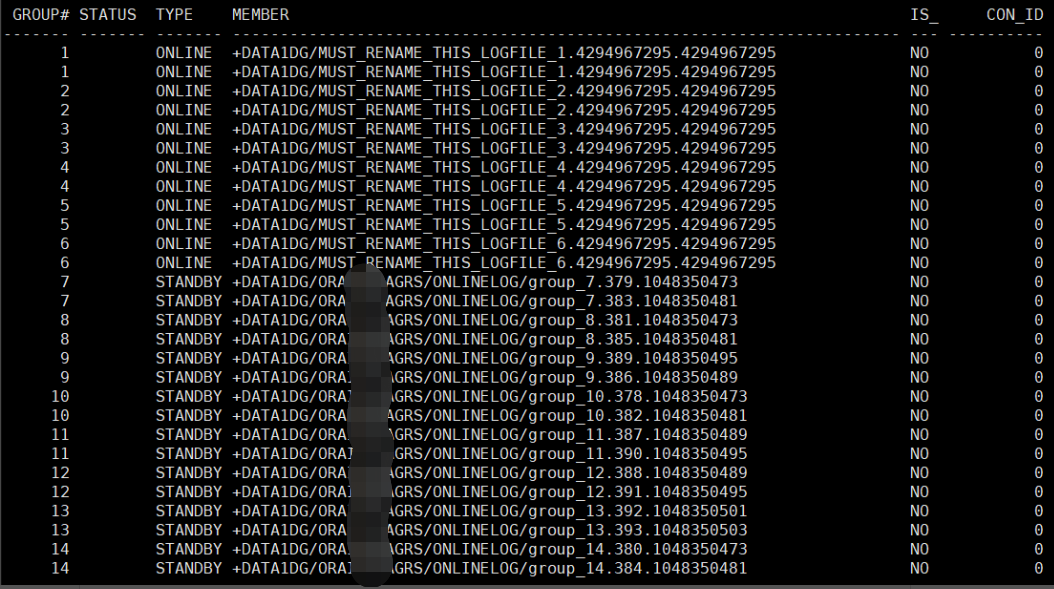
(2)格式化所有online log(格式化时会重新创建日志文件,因此你会发现磁盘组中的日志文件变多了,原来的不需要,直接rm掉即可):

|
Alter database clear logfile group 1; Alter database clear logfile group 2; Alter database clear logfile group 3; Alter database clear logfile group 4; Alter database clear logfile group 5; Alter database clear logfile group 6; |
(3) 格式化所有standby log
|
Alter database clear logfile group 7; Alter database clear logfile group 8; Alter database clear logfile group 9; Alter database clear logfile group 10; Alter database clear logfile group 11; Alter database clear logfile group 12; Alter database clear logfile group 13; Alter database clear logfile group 14; |
(4)再次查看log file:
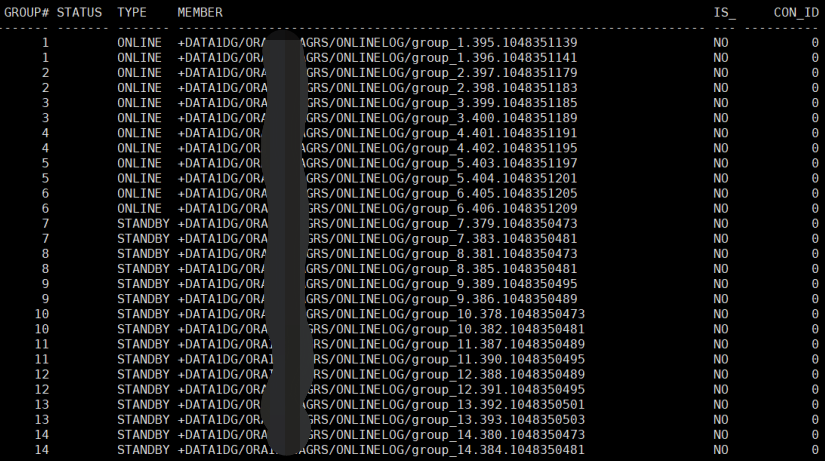
13、启动mrp:
|
alter database recover managed standby database using current logfile disconnect from session; |
14、检查ADG状态:
|
SELECT thread#,PROCESS,PID,CLIENT_PROCESS, SEQUENCE#, block#,STATUS FROM V$MANAGED_STANDBY order by 1; |
|
select thread#,first_time,SEQUENCE#,block_size*blocks/1024/1024,archived,applied,status from v$archived_log where first_time>sysdate-1 order by 2 |
|
select * from v$dataguard_stats; |
15、在lag日志追平以后,更改standby_file_management为auto:
|
alter system set standby_file_management=AUTO; |
16、停掉1节点mrp,启动备库1节点和2节点到open,再在1节点启动mrp:
17、最后一次检查数据库和ADG同步状态:
|
select database_role,protection_mode,protection_level from v$database; |
|
set linesize 300 |
|
SELECT thread#,PROCESS,PID,CLIENT_PROCESS, SEQUENCE#, block#,STATUS FROM V$MANAGED_STANDBY order by 1; |
|
select thread#,first_time,SEQUENCE#,block_size*blocks/1024/1024,archived,applied,status from v$archived_log where first_time>sysdate-1 order by 2; |
|
select * from v$dataguard_stats; |
至此,所有恢复工作完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号