



预备知识:
索引是针对于列提出来的概念。
假设对object_id建立索引,就要将这一列的‘值’和‘rowid’一起放到索引中去。rowid就是表中某一行的物理地址(rowid=数据文件号+块号 【一个extent中rowid的值是递增的】)。
Oracle中表是堆表,表中的数据是无序的,但是索引中的数据是排序的。索引排序是根据键值来排序的。
集群因子是针对于索引提出来的概念。
集群因子:
集群因子是什么?集群因子是怎么算出来的?
索引中存放的是键值+rowid,我们来模拟一个索引的结构:

集群因子:
从排好序的第一行开始,clustering=0
第二行如果和第一行在同一个块中,clustering=0
第三行如果到了第二个块中,clustering=1
第四行如果和第三行在同一个块中,clustering=1
第五行和第四行相比如果又到了另外一个块中,clustering=2
第六行和第五行相比如果又到了另外一个块中,clustering=3
以此类推,直到最后一个块为止。。。
这就是集群因子。
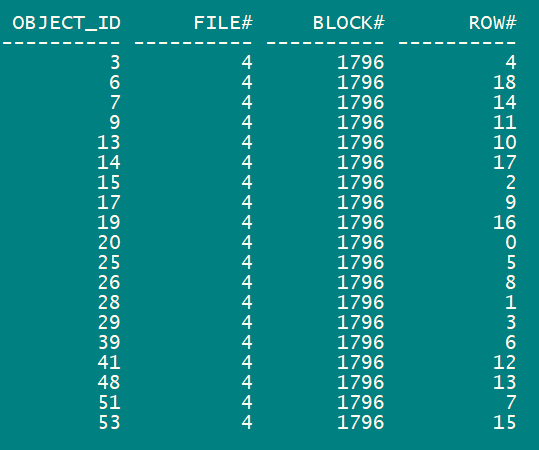
下面的sql能得到每一行的数据文件号、块号:
select
object_id,
dbms_rowid.rowid_relative_fno(rowid) file#,
dbms_rowid.rowid_block_number(rowid) block#,
dbms_rowid.rowid_row_number(rowid) row#
from test where rownum < 20 order by object_id;
集群因子介于表的总行数和表的总块数之间。
集群因子越接近于总行数,说明列在表中分布的很散乱。
集群因子越接近于总块数,说明列在表中的分布很集中,相当于是排过序的。
例如 select * from test where object_id < 1000 这个sql走索引的话需要回表,
最理想的情况下, 2,3,4 .... 999所在的行都在同一个块中,这时候只需要把一个块读到buffer中,只有第一次回表需要物理IO,之后的回表都是逻辑IO
最糟糕的情况下,2,3,4 。。。 999 所在的行都在不同的块中,这时候每次回表都需要将不同的块读取到buffer中,发生物理IO
集群因子的作用:
集群因子是用来衡量 通过索引回表需要多少物理IO的。
怎么消除集群因子的影响呢?
1、把整个的表都放在buffer cache中
2、集群因子对返回数据少的条件没有影响
3、集群因子影响的时范围扫描。
怎么改变集群因子:
由于一张表中,我们经常在多个列上简历索引,改善了一个索引的集群因子,很有可能导致另外一个索引的集群因子变得更差,因此集群因子基本上是无解的。
既然集群因子是无解的,我们为什么还要了解他呢?
这就涉及到了sql优化的核心思想,sql优化的核心思想就是<<<减少物理IO的扫描次数>>>。
怎么得到一个索引的集群因子:
select index_name,clustering_factor from user_indexes;


