
从下往上看--新皮层资料的读后感 第四部分 来自神经元的设计-perceptron 感知机
搬地方了,其他的部分看知乎:https://zhuanlan.zhihu.com/p/22114481
直到50年代,perceptron被Frank Rosenblatt搞了出来。perceptron的想法和pitts的路子就不大一样,perceptron关注MP神经元(MPN)本身的,而不是神经元在大脑中存在的复杂拓扑,所以其中除了MPN以外,没有其他的生物学含义。 按照Pitts的证明,一个开环的正向网络是可以满足所有的计算需求的。Rosenblatt沿着这条思路挖下去,发明了一套直接使用神经元数学特性的方法---perceptron。
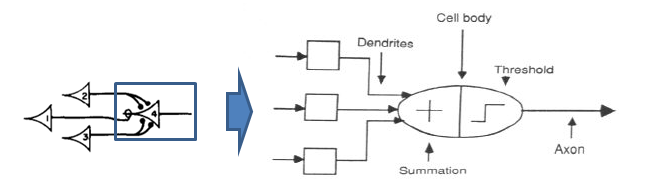
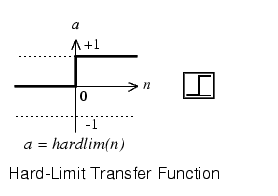
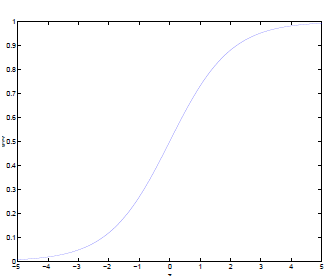
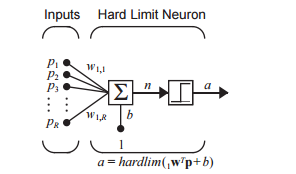
第一步得复习一下MPN,pitts画的时候系统框图还不流行,所以后来大家通常把MPN画成右边的样子,内在的数学表达式一致的。左边是加法,图片那个阶跃是个hardlim右边带刻度的是sigmoid这两个东西可以互换,我喜欢简单的,下面我只说hardlim的情况。按下图连接多个输入到一个MPN就得到一个perceptron(单细胞感知机)。是不是感觉被骗了,这是什么鬼,啥都没弄嘛。下面就来细说下一。

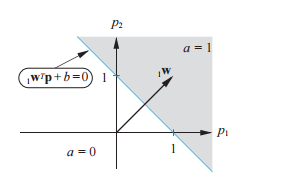
这里面一共是四个变量p1,p2,w1,w2,b是常数(threshold)。画出来特性就是右边的样子。顿时明白了吧,其实这个单元提供了一种能力,在w1,w2确定的时候,可以把输出为1的输入组合分离出来。这玩意用模拟电路制造起来十分简单,所以可以拿来“鉴定”p1,p2的组合是否符合w1,w2约束的要求(是不是落在灰色的部分)。要改变要求怎么办?拿2个可调电阻改变一下w1,w2就可以了。所以这玩意不只是放在数字计算机上写代码来用,也可以直接做模拟计算机。其中的箭头方向是w1,w2组成的向量,这个向量可以调节内容进行旋转。分割线的刚好是这个向量的正交线,按b(threshold)偏移。如果这个时候把b搞成变量(加个可调电阻?),很自然的就可以在平面上各种平移。顿时在[p1,p2]和b的共同作用下这条线就可以随便跑了。有兴趣的可以自己动手焊一个,都不用coding哈哈。这条线叫做超平面hyperplane(是不是搞高大上),出于简化我就管他叫线。

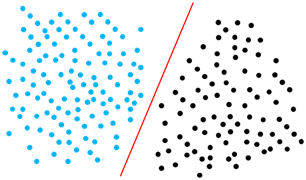
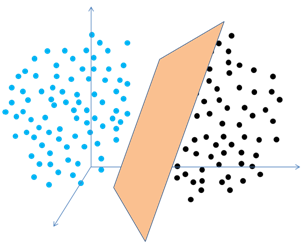
下面开始往里面多拉点输入进去改变输入的数量为R,向量规则依然管用,只是在改变图的维度。这么说比较抽象,多数教材都喜欢搞升维我来做个相反的例子,看看右边R=2的时候分割线是条线,R=1(单个输入)的时候分割就变成了点,同理可推,三维的时候是个面。四维的时候不知是什么鬼,但这个分类(具体的输入对应在分割的哪边,输出是0还是1)的功能依然被保留下来。从这个例子可以学到向量是个好东西,它能帮你把问题拉到你认识的维度来思考,对我这种粗糙的人来说绝对不想搞那堆复杂的数学,这就是个降维工具。所以后面我们所有的讨论和全部都在2维的角度来考虑你要升维降维的事情就不反复了。好了,这貌似和网络没啥关系啊,不着急,他们下面就进一步往下堆这种结构。
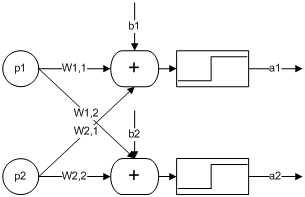
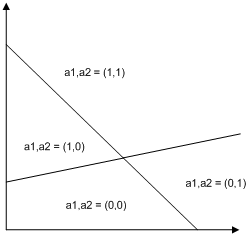
先看竖着堆堆看吧,一堆就发现,直接效果是可以标记出来分割出来的区域变多了,检查最后的输出结果a1,a2就可以知道满足两个节点的情况。于是就开始拿它做点更复杂的事情。拿它做加法?简单啊,通过设计参数搞定。沿着这条路推啊推,发现大多数计算都能搞定,唯独搞不定xor计算。倒回去看看Pitts的文章,马上哦一下。原来多几层堆下去就能搞定。这就是早年的perceptron,这玩意当时不只是个算法,而是一套模拟计算机框架。这种基本的MPN结构很容易用模拟电子做出来。如果把MPN简化成个圈,既可以看到类似下面的结构,这个结果就是MLP。perceptron的基本思路是在分类器框架下来用这些圈圈,在网络结构下使用分类功能在后来的几十年里面走了很远。也实现了大量的复杂分类算法(普通的Deep Learning也需要用到一层这样的结构)。但事实上这么横向搭出来以后其功能远不止能做分类,它同时还有计算的功能所以也发展出另外一条路子---不管它内部怎么工作的,丢一堆参数进去,直接获得某些特定的功能(这里面肯定有鬼...)。这后来也成了ANN发展的另外一条路子-不问为何,直接用(Deep Learning也有好多层这样的东西)。
有了perceptron 这么个宝贝,Rosenblatt顿时就无敌了,拿一台IBM 704模拟成功以后。找美国海军要了一堆钱造了一台出来,名字叫做Mark I。(原计划Mark I是拿来做图像识别用的,还以为是佳能单反呢)。后来这玩意就不造了,原因很简单尽管逻辑上整体是靠谱的,但是单个感知机需要调整三个参数才能用Mark I又造得这么复杂,试问谁去调这些参数,具体又怎么调,调参就成了coding的问题。问题是这玩意还不是数字结构的,逻辑的路子,全都可以按照if else 的基本模式来步步进行。这玩意整个coding过程都必须算成人看不懂的参数出来。所以有了Mark I当时就开始,做自动调参事情,所以到此为止,你别以为perceptron 就是人工智能,这还差最最核心的一步---让机器自己coding。尽管这算是一个整体失败的机会作为对前人敬仰,我们还是上图瞻仰一下。

所以需要清醒的认识一点,perceptron本质上是一套计算架构,MPN在这套架构中才节点足够多的情况下可以实现所有的计算功能(数字计算机也可以)。之后几十年的时间我们面临的问题事实上perceptron的自coding问题。只有具备了coding自身的能力在perceptron的网络框架下才能说具备初步的智能。同时和Pitts追求模型这里面有几点显著的不同。
1。perceptron 关注分割模型,Pitts关注算术本身的完备性,出发点不同。
2. perceptron关注开环计算,数据是单向的开环的,Pitts的思路是不仅仅限于单向的,环装通路的考量也在其中。
3. perceptron没有引入更多的生物特征, Pitts希望以生物样本为蓝图来构建大脑的仿生行为。
这不是说perceptron本身没有优点,仅仅表示它本身不是大脑的逆向工程产物。perceptron是历史性的,数值化的coding模式(参数设定)提供了一条结合传统数学和机器编程的路径,相比较而言基于数字逻辑的冯式机就很难做到这一点。这是为何现Deep Learning这些先进智能算法得以发展的基础。在后来的几十年内perceptron分类和统计学结合到一起构建出一条新的路径。
本节里面我刻意忽略了perceptron在处理数据中需要面对的三个重要问题:
1.不可分问题。
2.非线性分割的需求。
3.MLP框架下的perceptron特性。这个另外挖坑说。
4.只谈了MNP的线性特性,使用不同的传输函数MPN还具备一系列其他的性质。
并不是说这些问题不重要,这些问题会牵涉到perceptron在80年代以后发展的核函数等一系列核心问题。但这份笔记主要观察维度是如何理解生物设计和算法细节之间可能存在的关联。因此仅与算法相关的部分,这里特意单独分离出来以助于思路的简化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号