数论专题
数论专题
编者:czh(大的,弱的那个),lhy
矩阵
认识矩阵
矩阵就是一个数字阵列,一个 \(n\) 行 \(r\) 列的矩阵可以表示为:
\(\begin{bmatrix}a_{1,1}&a_{1,2}&\cdots&a_{1,r}\\a_{2,1}&a_{2,2}&\cdots&a_{2,r}\\\cdots\\a_{n,1}&a_{n,2}&\cdots&a_{n,r}\end{bmatrix}\)
我们称上面的矩阵为 \(n\times r\) 的矩阵。
特别的,如果一个行数和列数相等的矩阵,我们称其为方阵,例如下面就是一个 \(3\times3\) 的方阵:
\(\begin{bmatrix}1&4&3\\2&6&7\\9&7&6\end{bmatrix}\)
其实矩阵对我们来说也并不是那么陌生,因为它类似于我们程序中的二维数组。
还有一种矩阵在矩阵乘法中起着重要的作用,它叫单位矩阵,它就只有对角线是 \(1\),其他都是 \(0\),它在矩阵乘法中相当于乘法中的 \(1\),例如下面是一个单位矩阵:
\(\begin{bmatrix}1&0&0\\0&1&0\\0&0&1\end{bmatrix}\)
矩阵的运算
矩阵加减法
矩阵的加减法非常简单,只要把两个矩阵对应位置的元素加减即可。要求是两个矩阵的行、列数相等。
矩阵乘法
- 一个整数 \(k\) 乘矩阵 \(A\),把 \(k\) 乘以矩阵中的每个元素即可。
- 两个矩阵 \(A\) 和 \(B\) 相乘,要求 \(A\) 的列数等于 \(B\) 的行数,设 \(A\) 为 \(m\times n\) 的矩阵,\(B\) 为 \(n\times u\) 的矩阵,那么 \(C=A\times B\) 的尺寸为 \(m\times u\),计算公式为 \(\begin{aligned}C_{i,j}=\sum_{k=1}^n a_{i,k}\times b_{k,j}\end{aligned}\),复杂度为 \(O(m\times n\times u)\)。
根据矩阵乘法的定义,可以推出:
- 矩阵乘法有结合律。\((AB)C=A(BC)\)。
- 矩阵乘法有分配率。\((A+B)C=AC+BC\)。
- \(\color{red}{矩阵乘法没有交换律}\),即 \(AB\neq BA\)。
快速幂
整数的快速幂非常简单,对于 \(a^n\) 一个个乘要 \(O(n)\),这实在是太慢了。
快速幂的一个解法就是分治算法,就是先算 \(a^2\),再计算 \((a^2)^2,\cdots\),一直到 \(a^n\)。
具体实现就是首先先将指数 \(n\) 二进制拆分,将其拆为 \(2\) 的次幂的和,然后再一个个乘起来就可以了。
下面简单的举个例子。
\(a^{13}=a^{8+4+1}=a^8\times a^4\times a^1\),其中 \(a^1,a^4,a^8\) 的幂次都是 \(2\) 的次幂,可以逐级递推来实现。
下面给出代码实现(我还特意不压行了,正常这只在我的代码中占一行)
ll ksm(ll a, ll b){
ll res=1;//一定是1
while(b){
if(b&1) res=res*a;
a=a*a;
b>>=1;
}
return res;
}
矩阵快速幂
矩阵快速幂就相当于把矩阵看成一个整数来,原理和正常快速幂一模一样。
最后基本的运算都讲完了,如果想了解其他(如矩阵的逆)可自行查询,下面给出这些运算的代码。(抽象马蜂不喜勿喷)
class matrix{
public:
ll g[85][85];ll k=85;
matrix(){for(int i=0; i<k; i++) for(int j=0; j<k; j++)g[i][j]=0;}
void clear(){for(int i=0; i<k; i++) for(int j=0; j<k; j++)g[i][j]=0;}
void print(){for(int i=0; i<k; i++){for(int j=0; j<k; j++)cout<<g[i][j]<<' ';cout<<endl;}}
matrix& operator = (const matrix& x){for(int i=0; i<k; i++) for(int j=0; j<k; j++) g[i][j]=x.g[i][j];return *this;}
matrix operator + (const matrix& x){matrix c;for(int i=0; i<k; i++) for(int j=0; j<k; j++) c.g[i][j]=g[i][j]+x.g[i][j];return c;}
matrix operator * (const matrix& x){matrix c;for(int i=0; i<k; i++) for(int j=0; j<k; j++) for(int l=0; l<k; l++) c.g[i][j]+=g[i][l]*x.g[l][j];return c;}
matrix operator ^ (const ll& x){matrix res,a=*this;ll b=x;for(int i=0; i<k; i++) res.g[i][i]=1;while(b){if(b&1)res=res*a;a=a*a;b>>=1;}return res;}
};
\(k\) 为矩阵的边长,可自行调整,因为这是我从某一题复制过来的,所以是 \(85\),没有特殊意义。
矩阵的应用
矩阵乘法的精妙之处就在于:
- 很容易将有用的状态存储在一个矩阵中。
- 通过状态矩阵与转移矩阵相乘可以快速得到一次 DP 的值(注意,这个 DP 的状态方程必须是一次的递推式)。
- 求矩阵相乘的结果是要做很多次的乘法,这样的效率有时还不如原来一次的 DP 转移,但是由于矩阵乘法满足结合律,可以先用快速幂算后面的转移矩阵迅速地处理好后面的转移矩阵,再用初始矩阵乘上后面的转移矩阵得到结果,算法复杂度大概就是带个(可能比较大的)常数的 \(O(\log n)\)。
例题
这题也是非常经典。
首先我们知道 \(f\) 的递推式为 \(f_i=f_{i-1}+f_{i-2}\),于是有:
- \(f_i=1\times f_{i-1}+1\times f_{i-2}\)
- \(f_{i-1}=1\times f_{i-1}+0\times f_{i-2}\)
所以可以推出:
\(\begin{bmatrix}f_i\\f_{i-1}\end{bmatrix}=\begin{bmatrix}1&1\\1&0\end{bmatrix}\times\begin{bmatrix}f_{i-1}\\f_{i-2}\end{bmatrix}\)
进而,我们就可以推出:
\(\begin{bmatrix}f_n\\f_{n-1}\end{bmatrix}=\begin{bmatrix}1&1\\1&0\end{bmatrix}^{n-2}\times\begin{bmatrix}f_2\\f_1\end{bmatrix}\)
用矩阵快速幂即可,注意乘法的先后顺序,矩阵乘法不满足交换律。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int mod=1e9+7;
ll n;
class matrix{
public:
ll g[3][3];ll k=3;
matrix(){for(int i=0; i<k; i++) for(int j=0; j<k; j++)g[i][j]=0;}
void clear(){for(int i=0; i<k; i++) for(int j=0; j<k; j++)g[i][j]=0;}
void print(){for(int i=0; i<k; i++){for(int j=0; j<k; j++)cout<<g[i][j]<<' ';cout<<endl;}}
matrix& operator = (const matrix& x){for(int i=0; i<k; i++) for(int j=0; j<k; j++) g[i][j]=x.g[i][j];return *this;}
matrix operator * (const matrix& x){matrix c;for(int i=0; i<k; i++) for(int j=0; j<k; j++) for(int l=0; l<k; l++) (c.g[i][j]+=g[i][l]*x.g[l][j]%mod)%mod;return c;}
matrix operator ^ (const ll& x){matrix res,a=*this;ll b=x;for(int i=0; i<k; i++) res.g[i][i]=1;while(b){if(b&1)res=res*a;a=a*a;b>>=1;}return res;}
}f,a,ans;
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
int main(){
n=read();
if(n<=2){write(1);putchar('\n');return 0;}//特判
a.g[0][0]=a.g[0][1]=a.g[1][0]=1;
f.g[0][0]=f.g[1][0]=1;
a=a^(n-2);f=a*f;
write(f.g[0][0]%mod);putchar('\n');
return 0;
}
首先看完题目很自然的想到可以设 \(dp_{i,j}\) 表示第 \(i\) 个骰子以 \(j\) 面朝上的方案数。
首先对立关系由于总共才 \(6\) 种情况,所以可以直接用一个二维数组 \(mp_{i,j}\) 来存,\(i,j\) 排斥为 \(0\),否则为 \(1\)。
初始化就是 \(dp_1\) 的所有方案数为 \(1\)。
考虑转移,\(\begin{aligned}dp_{i,j}=\sum_{k=1}^6 dp_{i-1,opp_k}\times mp_{j,opp_k}\end{aligned}\)。
其中,\(opp_i\) 表示 \(i\) 的对面。
opp[10]={0,4,5,6,1,2,3}
但是 \(n\leq10^9\),这么做显然是不行的,考虑矩阵加速。
对于样例,我们有如下式子。
\(\begin{bmatrix}dp_{n,1}\\dp_{n,2}\\dp_{n,3}\\dp_{n,4}\\dp_{n,5}\\dp_{n,6}\end{bmatrix}=\begin{bmatrix}1&1&1&1&0&1\\1&1&1&0&1&1\\1&1&1&1&1&1\\1&1&1&1&1&1\\1&1&1&1&1&1\\1&1&1&1&1&1\end{bmatrix}\times\begin{bmatrix}dp_{n-1,1}\\dp_{n-1,2}\\dp_{n-1,3}\\dp_{n-1,4}\\dp_{n-1,5}\\dp_{n-1,6}\end{bmatrix}\)。
\(\begin{bmatrix}dp_{n,1}\\dp_{n,2}\\dp_{n,3}\\dp_{n,4}\\dp_{n,5}\\dp_{n,6}\end{bmatrix}=\begin{bmatrix}1&1&1&1&0&1\\1&1&1&0&1&1\\1&1&1&1&1&1\\1&1&1&1&1&1\\1&1&1&1&1&1\\1&1&1&1&1&1\end{bmatrix}^{n-1}\times\begin{bmatrix}dp_{1,1}\\dp_{1,2}\\dp_{1,3}\\dp_{1,4}\\dp_{1,5}\\dp_{1,6}\end{bmatrix}\)。
统计答案 \(ans\) 非常简单,就直接将最终得到的矩阵的值全部加起来即可。
当然这样子是不行的,因为每一个筛子因为侧边是可以旋转的,都有 \(4\) 种摆法,所以最终得到的 \(ans\) 还得乘上 \(4^n\),快速幂解决即可(记得取模。。。)
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=40;
const int mod=1e9+7;
ll n,m,u,v,mp[MN][MN],ans,opp[MN]={0,4,5,6,1,2,3};
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
struct matrix{
ll g[7][7];
void clear(){memset(g,0,sizeof(g));}
}f1,f2;
inline matrix operator * (matrix a, matrix b){
matrix c;c.clear();
for(int i=1; i<=6; i++) for(int j=1; j<=6; j++) for(int k=1; k<=6; k++) c.g[i][j]=(c.g[i][j]+(a.g[i][k]*b.g[k][j])%mod)%mod;
return c;
}
inline matrix operator ^ (matrix a, ll b){
matrix ans;ans.clear();
for(int i=1; i<=6; i++) ans.g[i][i]=1;
while(b){
if(b&1) ans=ans*a;
a=a*a;
b>>=1;
}
return ans;
}
ll ksm(ll a, ll b){
ll res=1;
while(b){
if(b&1) res=(res*a)%mod;
a=(a*a)%mod;
b>>=1;
}
return res;
}
void init(){
for(int i=1; i<=6; i++) f2.g[i][1]=1;
for(int i=1; i<=6; i++) for(int j=1; j<=6; j++) f1.g[i][j]=mp[i][opp[j]]^1;
}
int main(){
// freopen("1.in","r",stdin);
n=read();m=read();
for(int i=1; i<=m; i++){
u=read();v=read();
mp[u][v]=mp[v][u]=1;
}
init();
matrix res=(f1^(n-1))*f2;
for(int i=1; i<=6; i++) ans=(ans+res.g[i][1])%mod;
ans=(ans*ksm(4,n))%mod;
write(ans);
return 0;
}
矩阵也可以加速 Floyed,比如 这题。
首先,我们设 \(f_{l,i,j}\) 表示 \(i\to j\) 长度为 \(l\) 的路径数量,由乘法原理,有:
\(\begin{aligned}f_{l,i,j}=\sum_{k=1}^n f_{l-1,i,k}\times f_{1,k,j}\end{aligned}\)
其中 \(f_1\) 就是我们输入的矩阵,正常来看,只要一层层推就好了,但是发现 \(k\) 过于大,所以考虑优化。
观察式子发现这和矩阵乘法一模一样,\(f_t=f_{t-1}\times f_1\),于是就有 \(f_k=f_1^k\)。
利用矩阵快速幂即可。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=55;
const int mod=1e9+7;
ll n,k,res;
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
class matrix{
public:
ll g[MN][MN];
matrix(){memset(g,0,sizeof(g));}
void clear(){memset(g,0,sizeof(g));}
matrix& operator = (const matrix& x){for(int i=0; i<n; i++) for(int j=0; j<n; j++) g[i][j]=x.g[i][j];return *this;}
matrix operator * (const matrix& a){matrix res;for(int i=0; i<n; i++) for(int j=0; j<n; j++) for(int l=0; l<n; l++) res.g[i][j]=(res.g[i][j]+g[i][l]*a.g[l][j]%mod)%mod;return res;}
matrix operator ^ (const ll& x){matrix res=*this,a=*this;ll b=x-1;while(b){if(b&1)res=res*a;a=a*a;b>>=1;}return res;}
}f,ans;
int main(){
n=read();k=read();
for(int i=0; i<n; i++) for(int j=0; j<n; j++) f.g[i][j]=read();
ans=f^k;
for(int i=0; i<n; i++) for(int j=0; j<n; j++) res=(res+ans.g[i][j])%mod;
write(res);putchar('\n');
return 0;
}
练习题
GCD 和 LCM
整除
整除定义
\(a\) 能整除 \(b\),记为 \(a|b\)。其中,\(a\) 和 \(b\) 为整数,且 \(a\neq0,b\) 是 \(a\) 的倍数,\(a\) 是 \(b\) 的约数。
性质
- 若 \(a,b,c\) 为整数,且 \(a|b,b|c\),则 \(a|c\)。
- 若 \(a,b,m,n\) 为整数,且 \(c|a,c|b\),则 \(c|(ma+nb)\)。
- 定理:带余除法。如果 \(a\) 和 \(b\) 为整数且 \(b>0\),则存在唯一的整数 \(q,r\),使得 \(a=bq+r,0\leqslant r<b\)。
GCD
定义
\(a\) 和 \(b\) 的最大公约数是指能同时整除 \(a\) 和 \(b\) 的最大整数,记为 \(\gcd(a,b)\)。
注意:由于 \(-a\) 的因子和 \(a\) 的因子相同,因此 \(\gcd(a,b)=\gcd(|a|,|b|)\)。
性质
- \(\gcd(a,b)=\gcd(a,a+b)=gcd(a,ka+b)\)。
- \(\gcd(ka,kb)=k\times\gcd(a,b)\)。
- 定义多个整数的最大公约数,\(\gcd(a,b,c)=\gcd(\gcd(a,b),c)\)。
- 若 \(\gcd(a,b)=d\),则 \(\gcd(\frac{a}{d},\frac{b}{d})=1\),即 \(\frac{a}{d}\) 与 \(\frac{b}{d}\) 互素。
- \(\gcd(a+cb,b)=\gcd(a,b)\)。
GCD 的计算
由于 \(\gcd(a,b)=\gcd(b,a-b)=\gcd(a,a-b)\),所以就有辗转相减法,用较大的数减较小的数,代码如下:
ll gcd(ll a, ll b){
while(a!=b){
if(a>b) a=a-b;
else b=b-a;
}
return a;
}
但是我们发现这样一次次减太慢了,在最劣的情况下会跑到 \(\max(a,b)\) 次,我们发现其实多次减法就相当于一次取模,所以我们就有辗转相除(欧几里得)法:
ll gcd(ll a, ll b){
if(!b) return a;
return gcd(b,a%b);
}
LCM
定义
\(a\) 和 \(b\) 的最小公倍数表示为 \(lcm(a,b)\)。
算数基本定理
任何一个大于 \(1\) 的正整数 \(n\) 都可以唯一分解为有限个素数的乘积:\(n=p_1^{c_1}p_2^{c_2}\cdots p_m^{c_m}\),其中 \(c_i\) 都为正整数 \(p_i\) 都为素数。
LCM 的计算
设 \(a=p_1^{c_1}p_2^{c_2}\cdots p_m^{c_m},b=p_1^{f_1}p_2^{f_2}\cdots p_m^{f_m}\),那么 \(\gcd(a,b)=p_1^{\min(c_1,f_1)}p_2^{\min(c_2,f_2)}\cdots p_m^{\min(c_m,f_m)},lcm(a,b)=p_1^{\max(c_1,f_1)}p_2^{\max(c_2,f_2)}\cdots p_m^{\max(c_m,f_m)}\)。
所以 \(\gcd(a,b)\times lcm(a,b)=ab\),所以就有 \(lcm(a,b)=\frac{ab}{\gcd(a,b)}\)。
ll lcm(ll a, ll b){
return a/gcd(a,b)*b;
}
注意:这里最好先除法再乘法,防止溢出。
裴蜀定理
如果 \(a\) 和 \(b\) 均为整数,则有整数 \(x,y\) 使得 \(ax+by=\gcd(a,b)\)。
证明:分类讨论
若 \(a,b\) 中有一个数位 \(0\),则结论显然成立。
若 \(a,b\) 均不为 \(0\)。
\(\because\gcd(a,b)=\gcd(a,-b)\)
所以不妨设 \(a\geqslant b>0,d=\gcd(a,b)\)
对于 \(ax+by=d\),考虑等式两边同时除以 \(d\) 得
\(a_1x+b_1y=1,\gcd(a_1,b_1)=1\)
问题就转化成了 \(a_1x+b_1y=1\)。
考虑之前说的辗转相除法:\(\gcd(a,b)\to\gcd(b,a\bmod b)\to\cdots\),我们设每次取模的数设为 \(r\),于是有:
不妨令辗转相除法在除到互质的时候退出则 \(r_n=1\) 所以有
即
由倒数第三个式子 \(r_{n-1}=r_{n-3}-x_{n-1}r_{n-2}\) 代入上式,得
然后用同样的办法用它上面的等式逐个地消去 \(r_{n-2},\cdots,r_1,\)
可证得 \(1=a_1x+b_1y\). 这样等于是一般式中 \(d=1\) 的情况。
推论
整数 \(a\) 和 \(b\) 互质当且仅当存在整数 \(x\) 和 \(y\),使得 \(ax+by=1\)。
同余式
同余的定义
同余:设 \(m\) 是正整数,若 \(a\) 和 \(b\) 是整数,且 \(m|(a-b)\),则称 \(a\) 和 \(b\) 模 \(m\) 同余。
剩余系:一个模 \(m\) 完全剩余系是一个整数的集合,使每个整数恰与此集合中的一个元素模 \(m\) 同余。
定理和性质
同余的基本概念:若 \(a\) 和 \(b\) 是整数,\(m\) 为正整数,则 \(a\equiv b\pmod m\) 当且仅当 \(a\bmod m=b\bmod m\)。
同余式转化成等式:若 \(a\) 和 \(b\) 是整数,则 \(a\equiv b\pmod m\) 当且仅当存在整数 \(k\),使得 \(a=b+km\)。
设 \(m\) 为正整数,模 \(m\) 的同余满足以下基本性质:
- 自反性:若 \(a\) 是整数,则 \(a\equiv a\pmod m\)。
- 对称性:若 \(a\) 和 \(b\) 是整数,且 \(a\equiv b\pmod m\),则 \(b\equiv a\pmod m\)。
- 传递性:若 \(a,b,c\) 是整数,且 \(a\equiv b\pmod m,b\equiv c\pmod m\),则 \(a\equiv c\pmod m\)。
关于同余的加减乘除,若 \(a,b,c\) 和 \(m\) 是整数,\(m>0\),且 \(a\equiv b\pmod m,c\equiv d\pmod m\),则有以下性质:
- 加:\(a+c\equiv b+c\pmod m\),更一般的,\(a+c\equiv b+d\pmod m\)。
- 减:\(a-c\equiv b-c\pmod m\),更一般的,\(a+c\equiv b+d\pmod m\)。
- 乘:\(ac\equiv bc\pmod m\),更一般的,\(ac\equiv bd\pmod m\)。
- 除:在同余的两边同时除以一个整数,不一定保持同余,但满足 \(ac\equiv bc\pmod m\rightarrow a\equiv b\pmod{\frac{p}{\gcd(c,p)}}\)
- 同余的幂:若 \(a,b,k\) 和 \(m\) 是整数,\(k>0,m>0\),且 \(a^k\equiv b^k\pmod m\)。
- 若 \(a\bmod p=x,a\bmod q=x\),其中,\(p,q\) 互质,则 \(a\bmod (pq)=x\)。
对于最后一个性质,我们稍微给出证明。
\(\because a\bmod p=x,a\bmod q=x,\gcd(p,q)=1\)
\(\therefore\) 一定存在整数 \(s,t\),使得 \(a=sp+x,a=tq+x\)
\(\therefore sp=tq\)
\(\therefore\) 一定存在一个整数 \(r\) 使得 \(s=rq\)。
\(\therefore a=rpq+x\)
\(\therefore a\bmod (pq)=x\)
除了上面所介绍的这些定理之外,我们还有。
费马小定理
若 p 为素数,\(\gcd(a,p)=1\),则 \(a^{p-1}\equiv1\pmod{p}\)。
引理
设 \(m\) 是一个整数且 \(m>1\),\(b\) 是一个正整数且 \(\gcd(m,b)=1\)。如果 \(a_1,a_2,a_3,\cdots,a_{m-1}\) 是模 \(m\) 的一个完全剩余系,则 \(b\cdot a_1,b\cdot a_2,b\cdot a_3,\cdots,b\cdot a_{m-1}\) 也构成模m的一个完全剩余系。
证明:反证法。
设在 \(b\cdot a_1,b\cdot a_2,b\cdot a_3,\cdots,b\cdot a_{m-1}\) 中存在 \(b\cdot a_i\equiv b\cdot a_j\pmod m(i\neq j,i,j\in(0,m),i,j\in\mathbb{Z})\)。
则 \(a_i\equiv a_j\pmod m\),矛盾。
证明
构造素数 \(m\) 的完全剩余系:\(M=\{1,2,3,\cdots,m-1\}\),再取一个整数 \(a\) 使得 \(\gcd(a,m)=1\)。
由引理得,\(A=\{a,2a,3a,\cdots,(m-1)a\}\) 也为 \(m\) 的完全剩余系。
\(\therefore\begin{aligned}\prod_{i=1}^{m-1}\space A_i\equiv\prod_{i=1}^{m-1}(A_i\times a)\pmod m\end{aligned}\)
令 \(f=(m-1)!\),则有 \(a^{m-1}\times f\equiv f\pmod m\)。
\(\because m\) 是质数
\(\therefore \gcd((m-1)!,m)=1\)
\(\therefore a^{m-1}\equiv 1\pmod m\)。
欧拉定理
若 \(\gcd(a,m)=1\),则 \(a^{\varphi(m)}\equiv1\pmod{m}\)。
证明
证明过程和费马小定理基本一样。
设 \(a_1,a_2,a_3,\cdots,a_{\varphi(m)}\) 为模 \(m\) 意义下的一个简化剩余系,\(\gcd(b,m)=1\),\(b\) 为正整数,则 \(b\cdot a_1,b\cdot a_2,b\cdot a_3,\cdots,b\cdot a_{\varphi(m)}\) 也为模 \(m\) 的一个简化剩余系。
\(\therefore \begin{aligned}\prod_{i=1}^{\varphi(m)}a_i\equiv\prod_{i=1}^{\varphi(m)}b\cdot a_i\pmod m\end{aligned}\)
\(\therefore b^{\varphi(m)}\equiv1\pmod m\)。
线性丢番图方程
二元线性丢番图方程
方程 \(ax+by=c\) 称为二元线性丢番图方程,其中 \(a,b,c\) 是已知整数,\(x,y\) 是变量。
定理
设 \(a,b\) 是整数且 \(\gcd(a,b)=d\)。
- 如果 \(d\) 不能整除 \(c\),那么方程 \(ax+by=c\) 没有整数解。
- 如果 \(d\) 能整除 \(c\),那么存在无穷多个整数解。
另外,若 \((x_0,y_0)\) 是方程的一个特解,那么通解可以表示为 \(x=x_0+\frac{b}{d}\times n,y=y_0+\frac{a}{d}\times n,n\in\mathbb{Z}\)。
扩欧与二元丢番图方程
求解方程 \(ax+by=c\) 的关键就是找到一个特解。根据定理,\(ax+by=\gcd(a,b)\) 有整数解,所以可以用扩欧求一个特解 \((x_0,y_0)\),代码如下:
ll exgcd(ll a, ll b, ll &x, ll &y){
if(!b){x=1,y=0;return a;}
ll d=exgcd(b,a%b,y,x);
y-=a/b*x;
return d;
}
为了方便表述,令 \(d=\gcd(a,b)\)。
求解 \(ax+by=c\) 的步骤大概如下:
- 判断方程 \(ax+by=c\) 是否有整数解,即 \(d\) 是否能整除 \(c\)。
- 用扩欧求出 \(ax+by=d\) 的一个特解 \((x_0,y_0)\)。
- 在 \(ax_0+by_0=d\) 两边同时乘 \(\frac{c}{d}\),得 \(ax_0\times\frac{c}{d}+by_0\times\frac{c}{d}=c\)。
- 对照 \(ax+by=c\),得到 \(x_0'=x_0\times\frac{c}{d},y_0'=y_0\times\frac{c}{d}\)
- 方程的通解为 \(x=x_0'+\frac{b}{d}n,y=y_0'+\frac{a}{d}n\)。
同余方程
一元线性同余方程
设 \(x\) 是未知数,给定 \(a,b,m\),求整数 \(x\),满足 \(ax\equiv b\pmod m\)。
研究线性同余方程有什么用处?\(ax\equiv b\pmod m\) 表示 \(ax-b\) 是 \(m\) 的倍数,设为 \(-y\) 倍,则 \(ax+my=b\),这就是二元线性丢番图方程,所以求解一元线性同余方程就 等价于 求解二元线性丢番图方程。
定理
设 \(a,b,m\) 都是整数,\(m>0,\gcd(a,m)=d\)。
- 若 \(d\) 不能整除 \(b\),则 \(ax\equiv b\pmod m\) 无解。
- 若 \(d\) 能整除 \(b\),则 \(ax\equiv b\pmod m\) 有 \(d\) 个模 \(m\) 不同余的解。
推论
\(a\) 和 \(m\) 互质时,因为 \(d=\gcd(a,m)=1\),所以线性同余方程 \(ax\equiv b\pmod m\) 有唯一的模 \(m\) 不同余的解,换句话说,\(a,m\) 互质的时候,\(a\) 在模 \(m\) 意义下,有且仅有唯一的逆元。
同余方程组
同余方程 \(ax\equiv b\pmod m\) 有解时,即 \(\gcd(a,m)\) 能整除 \(b\) 时,可以解得 \(x\equiv a'\pmod{m'}\),这也是同余方程的一般形式。
接下来我们来讲下同余方程组的求解,即:
\(\left\{\begin{array}{lcl}x\equiv a_1\pmod{m_1}\\x\equiv a_2\pmod{m_2}\\\cdots\\x\equiv a_r\pmod{m_r}\end{array}\right.\)
中国剩余定理
设 \(m_1,m_2,\cdots,m_r\) 是两两互质的正整数,则同余方程组 \(x\equiv a_1\pmod{m_1},x\equiv a_2\pmod{m_2},\cdots,x\equiv a_r\pmod{m_r}\) 有整数解,并且模 \(M=m_1m_2\cdots m_r\) 唯一解为 \(x\equiv (a_1t_1M_1+a_2t_2M_2+\cdots+a_rt_rM_r)\pmod m\)。
其中,\(M_i=\frac{M}{m_i},t_i\) 是 \(M_i\) 在模 \(m_i\) 的逆元。
证明
\(\because\) 对于任一 \(i\in\{1,2,\cdots,r\},\forall j\in\{1,2,\cdots,r\},j\neq i,\gcd(m_i,m_j)=1\)
\(\therefore\) 存在整数 \(t_i\) 使得 \(t_iM_i\equiv 1\pmod{m_i}\)
\(\therefore a_it_iM_i\equiv a_i\cdot1\equiv a_i\pmod{m_i}\)
又 \(\because \forall j\in\{1,2,\cdots,r\},j\neq i,a_it_iM_i\equiv 0\pmod{m_j}\)
\(x=a_1t_1M_1+a_2t_2M_2+\cdots+a_rt_rM_r\) 满足 \(\begin{aligned}\forall i\in\{1,2,\cdots,r\},x=a_it_iM_i+\sum_{j\neq i}a_jt_jM_j\equiv a_i+\sum_{j\neq i} 0\equiv a_i\pmod {m_i}\end{aligned}\)
\(\therefore x\) 为方程组的一个解。
设 \(x_1,x_2\) 都是方程组的解,那么 \(\forall i\in\{1,2,\cdots,r\},x_1-x_2\equiv0\pmod{m_i}\)
而 \(m_1,m_2,\cdots,m_r\) 两两互质,说明 \(\begin{aligned}M=\prod_{i=1}^r m_i\end{aligned}\) 整除 \(x_1-x_2\),所以方程组的任何两个解之间必然相差 \(M\) 的整数倍。
\(\therefore\) 方程组的集合为 \(\begin{aligned}\{kM+\sum_{i=1}^r a_it_iM_i,k\in\mathbb{Z}\}\end{aligned}\)
实现
中国剩余定理的限制条件是 \(m_1,m_2,\cdots,m_r\) 两两互质,如果不互质的话只能用迭代法了。
迭代法的思路很简单,每次合并两个同余式,逐步合并,直到合并完所有等式,只剩下一个,就得到了答案。
合并时,把同余方程转化成等式会更容易。
这里以 \(\left\{\begin{array}{l}x\equiv2\pmod3\\x\equiv3\pmod5\\x\equiv2\pmod7\end{array}\right.\) 为例。
前 \(3\) 步合并了第 \(1\) 个和第 \(2\) 个的同余式,后 \(3\) 步合并第 \(3\) 个等式。
- 把第 \(1\) 个同余式转化为 \(x=2+3t\),带入第 \(2\) 个同余式,得 \(2+3t\equiv3\pmod5\)。
- 移项得 \(3t\equiv1\pmod5\),因为 \(\gcd(3,5)\) 能整除 \(1\),所以方程有解 \(t\equiv2\pmod5\),转化成 \(t=2+5u\)。
- 把 \(t=2+5u\) 代入 \(x=2+3t\) 得 \(x=8+15u\),即 \(x\equiv8\pmod{15}\)。
- 把 \(x=8+15u\) 代入第 \(3\) 个同余式,得 \(8+15u\equiv2\pmod7\)
- 移项得 \(15u\equiv-6\pmod7\),因为 \(\gcd(15,7)\) 能整除 \(-6\),所以方程有解 \(u\equiv1\pmod7\),转化成 \(u=1+7v\)。
- 把 \(u=1+7v\) 代入 \(x=8+15u\) 得 \(x=23+105v\),即 \(x\equiv23\pmod{105}\)。
形式化的:
| 步骤 | 例子 |
|---|---|
| 合并两个等式 \(x=a_1+Xm_1,x=a_2+Ym_2\) | \(x=2+3X,x=3+5Y\) |
| 两个等式相等:\(a_1+Xm_1=a_2+Ym_2\) \(\\\) 移项得 \(Xm_1+(-Y)m_2=a_2-a_1\) | \(2+3X=3+5Y\\3X+5(-Y)=1\) |
| 用扩欧求出其特解 \(X_0\) | \(X_0=2\) |
| \(X\) 的通解是 \(X=X_0\times\frac{c}{d}+\frac{b}{d}\times n\\\) 最小值 \(t=(X_0\times\frac{c}{d})\bmod(\frac{b}{d})\) | \(t=(X_0\times\frac{c}{d})\bmod(\frac{b}{d})\\=(2\times1/1)\bmod(5/1)=2\) |
| 把 \(X=t\) 代入 \(x=a_1+X_{m_1}\),求出原方程的一个特解 \(x'\) | \(x'=2+2\times3=8\) |
| 合并后的新 \(x=a+Xm\\m=\frac{m_1m_2}{\gcd(m_1,m_2)}\\a=x'\) | \(m=3\times5/1=15\\a=8\\\) 合并后的新方程为 \(x=8+15X\\\) 即 \(x\equiv8\pmod{15}\) |
例题
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll __int128
using namespace std;
const int MN=1e5+5;
ll n,a[MN],m[MN];
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
ll exgcd(ll a, ll b, ll &x, ll &y){
if(!b){x=1;y=0;return a;}
ll d=exgcd(b,a%b,y,x);
y-=a/b*x;
return d;
}
ll excrt(){
ll x,y,m1=m[1],a1=a[1],ans=0;
for(int i=2; i<=n; i++){
ll a2=a[i],m2=m[i];
ll a=m1,b=m2,c=(a2-a1%m2+m2)%m2;
ll d=exgcd(a,b,x,y);
if(c%d!=0) return -1;
x=x*(c/d)%(b/d);
ans=a1+x*m1;m1=m2/d*m1;
ans=(ans%m1+m1)%m1;
a1=ans;
}
return ans;
}
int main(){
n=read();
for(int i=1; i<=n; i++) m[i]=read(),a[i]=read();
write(excrt());putchar('\n');
return 0;
}
练习题
威尔逊定理
若 \(p\) 为素数,则 \(p\) 可以整除 \((p-1)!+1\)。
即:
- \(((p-1)!+1)\bmod p=0\)
- \((p-1)!\bmod p=p-1\)
- \((p-1)!=pq-1,q\in\mathbb{N}\)
- \((p-1)!\equiv -1\pmod p\)
证明
这是来自外国语2023届景润班一位数竞生的证明
首先,当 \(p=2\) 的时候显然定理成立。
所以就只要考虑 \(p\) 为奇素数的情况。
取 \(p\) 的原根 \(g\),则 \(1,g,g^2,g^3,\cdots g^{p-1}\) 除以 \(p\) 的余数为 \(1,2,3,\cdots p-1\)。
\(\therefore (p-1)!=g^{0+1+2+\cdots+p-2}=g^{\frac{(p-2)(p-1)}{2}}\pmod p\)
设 \(p=2k+1\),则 \((p-1)!=g^{k(2k-1)}\pmod p\)
由费马小定理,\(\because (g^k)^2=g^{2k}=g^{p-1}\equiv 1\pmod p\)
\(\therefore g^k\equiv \pm 1\pmod p\)
\(\because k<p\)
\(\therefore g^k\equiv -1\pmod p\)
\(\therefore (p-1)!=g^{k(2k-1)}\equiv (-1)^{2k-1}\equiv -1\pmod p\)
例题
设 \(p=3k+7\),记 \(f(k)=[\frac{(p-1)!+1}{p}-[\frac{(p-1)!}{p}]]\)
- 若 \(p\) 为合数,\((p-1)\) 能被 \(p\) 整除,\(f(k)=0\)。
- 若 \(p\) 为素数,\((p-1)!=pq-1\),有 \(f(k)=[\frac{pq-1+1}{p}-[\frac{pq-1}{p}]]=[q-[q-\frac{1}{p}]]=[q-(q-1)]=1\)
所以 \(\begin{aligned}S_n=\sum_{k=1}^n f(k)\end{aligned}\) 转换为求 \(1\sim n\) 内的素数个数,线性筛即可。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=4e6+5;
ll ans[MN];
class prime{
public:
ll p[MN],cnt;
bool vis[MN];
prime(){cnt=0;memset(vis,false,sizeof(vis));}
void clear(){cnt=0;memset(vis,false,sizeof(vis));}
void init(){
for(int i=2; i<=MN; i++){
if(!vis[i]) p[++cnt]=i;
for(int j=1; j<=cnt&&i*p[j]<=MN; j++){
vis[i*p[j]]=true;
if(i%p[j]==0) break;
}
}
}
}p;
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
int main(){
p.init();
for(int i=2; i<MN; i++) ans[i]=ans[i-1]+(!p.vis[3*i+7]);
ll T=read();while(T--){ll x=read();write(ans[x]);putchar('\n');}
return 0;
}
笔者因为懒甚至直接把线性筛放到类里复制过来。。。
康托展开
正向康托展开
题意很简单,就是求长度为 \(n\) 的数组 \(a\) 在全部 \(n\) 的排列中按字典序排序的排名。
先那一组数据来手玩:
求 4 2 3 5 1 的排名。
- 第一位是 \(4\),在这这个排列中,还会有以 \(1,2,3\) 作为第一位,所以它会增加 \(3\times(5-1)!=72\) 的排名。
- 第二位是 \(2\),在以
4为第一位的排列中,还会有 \(1\) 作为第二位,所以它会增加 \(1\times(5-2)!=6\) 的排名。 - 第三位是 \(3\),在以
4 2为前两位的排列中,还会有 \(1\) 作为第三位,所以他会增加 \(1\times(5-3)!=2\) 的排名。 - 第四位是 \(5\),在以
4 2 3为前三位的排列中,还会有 \(1\) 作为第四位,所以它会增加 \(1\times(5-4)!=1\) 的排名。 - 第五位无需考虑
所以,该排列的排名为 \(72+6+2+1+1=82\) 名,记得最后要加 \(1\),因为我们算的是该排列前面有多少个排列。
形式化的,记 \(s_i\) 为 \(\begin{aligned}\sum_{j=i+1}^n a_j<a_i\end{aligned}\),则 \(a\) 的排名就为 \(\begin{aligned}\sum_{i=1}^n s_i\times(n-i)!\end{aligned}\)。
如果暴力求这个数组的话是 \(O(n^2)\),会超时,所以考虑用树状数组优化,就可以达到 \(O(n\log n)\),原理和树状数组求逆序对一样。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int mod=998244353;
const int MN=1e6+5;
ll n,a[MN],t[MN],fac[MN]={1},ans;
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
ll lowbit(ll x){return x&-x;}
void change(ll x, ll v){while(x<=n){t[x]=(t[x]+v)%mod;x+=lowbit(x);}}
ll query(ll x){ll res=0;while(x){res=(res+t[x])%mod;x-=lowbit(x);}return res;}
int main(){
n=read();
for(int i=1; i<=n; i++){fac[i]=fac[i-1]*i%mod;change(i,1);}
for(int i=1; i<=n; i++){
a[i]=read();
ans=(ans+(query(a[i]-1)*fac[n-i])%mod)%mod;
change(a[i],-1);
}
write(ans+1);putchar('\n');
return 0;
}
逆向康托展开
把本题的题面对比下正向康托展开发现式子一模一样,所以也就知道这题中的 \(S_i\) 就是 \(\begin{aligned}\sum_{j=i+1}^n a_j<a_i\end{aligned}\),所以问题就转化成了已知每个数后面有几个小于自己的数,求这个序列。
这个很好办,用树状数组加二分,我们可以从前往后一个一个确定 \(a\)。
\(S_i\) 就为比 \(i\) 小并且未被确定的数的个数。
在逐步确定 \(a\) 过程中,对于每个 \(i\in\{1,2,\cdots,n\}\),比 \(i\) 小并且未被确定的数的个数满足单调性,于是就可以二分求 \(a_i\),然后标上 \(a_i\) 已被标记(在树状数组中把 \(a_i\) 位置减一)。
时间复杂度为 \(O(n\log^2 n)\),用线段树上二分可以优化到 \(O(n\log n)\),但是笔者太懒(菜)了,只打了树状数组(反正能过就行)。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=5e4+5;
ll n,t[MN],a[MN];
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
ll lowbit(ll x){return x&-x;}
void change(ll x, ll v){while(x<=n){t[x]+=v;x+=lowbit(x);}}
ll query(ll x){ll res=0;while(x){res+=t[x];x-=lowbit(x);}return res;}
ll get(ll x){
ll l=1,r=n+1,res;
while(l<r){
ll mid=l+r>>1,num=query(mid-1);
if(num>x) r=mid;
else l=mid+1;
}
return l-1;
}
void solve(){
for(int i=1; i<=n; i++) t[i]=0;
n=read();
for(int i=1; i<=n; i++) change(i,1);
for(int i=1; i<=n; i++){
ll x=read();
a[i]=get(x);
change(a[i],-1);
}
for(int i=1; i<=n; i++){
write(a[i]);
if(i!=n) putchar(' ');
}putchar('\n');
}
int main(){
ll T=read();while(T--) solve();
return 0;
}
高斯消元
一个线性方程组有 \(m\) 个一次方程,\(n\) 个变量,把所有的系数携程一个人 \(m\) 行 \(n\) 列的矩阵,把每个方程等号右侧的常数放在最右列,得到一个 \(m\) 行 \(n+1\) 的增广矩阵,高斯消元本质上就是通过多次变换把方程组转化成多个一元一次方程,变换有以下三种,称为线性方程组的初等变换。
- 交换某两行的位置。
- 让矩阵中的一行乘上一个非零的常数 \(k\),相当于让某个方程左右两边同时乘以一个非零常数 \(k\)。
- 把某行乘以 \(k,k\neq0\) 后加到另一行上,相当于让一个方程加上另一个方程的 \(k\) 倍。
这里给出三个例子,顺便介绍线性方程组的解的 \(3\) 种情况:有唯一解,有无穷多解,无解。
- 有唯一解
\(\left\{\begin{array}{l}3x_1+7x_2-5x_3=47\\x_1+4x_2+x_3=58\\8x_1-3x_2+9x_3=88\end{array}\right.\to\left[\begin{matrix}3&7&-5\\1&4&1\\8&-3&9\end{matrix}\middle|\begin{matrix}47\\58\\88\end{matrix}\right]\)
首先先把左边的方程组写成右边的增广矩阵,然后反复使用初等变换,得(这一段摘抄自算法竞赛,我也不知道这消元能这么丝滑)
\(\left[\begin{matrix}3&7&-5\\1&4&1\\8&-3&9\end{matrix}\middle|\begin{matrix}47\\58\\88\end{matrix}\right]\to\left[\begin{matrix}3&7&-5\\1&4&1\\0&35&-1\end{matrix}\middle|\begin{matrix}47\\58\\376\end{matrix}\right]\to\left[\begin{matrix}3&7&-5\\0&5&8\\0&35&-1\end{matrix}\middle|\begin{matrix}47\\127\\376\end{matrix}\right]\to\left[\begin{matrix}3&7&-5\\0&5&8\\0&0&57\end{matrix}\middle|\begin{matrix}47\\127\\513\end{matrix}\right]\to\left[\begin{matrix}3&7&-5\\0&5&8\\0&0&1\end{matrix}\middle|\begin{matrix}47\\127\\9\end{matrix}\right]\to\left[\begin{matrix}3&7&-5\\0&5&0\\0&0&1\end{matrix}\middle|\begin{matrix}47\\55\\9\end{matrix}\right]\to\left[\begin{matrix}3&7&-5\\0&1&0\\0&0&1\end{matrix}\middle|\begin{matrix}47\\11\\9\end{matrix}\right]\to\left[\begin{matrix}1&0&0\\0&1&0\\0&0&1\end{matrix}\middle|\begin{matrix}5\\11\\9\end{matrix}\right]\)
最后解得 \(\left\{\begin{array}{l}x_1=5\\x_2=11\\x_3=9\end{array}\right.\),这是唯一解,称最后的矩阵为 简化阶梯矩阵,特征是左半边是个 单位矩阵。
- 有无穷多个解
\(\left\{\begin{array}{l}3x_1+7x_2-5x_3=47\\x_1+4x_2+x_3=58\\2x_1+3x_2-6x_3=-11\end{array}\right.\to\left[\begin{array}{l}3&7&-5\\1&4&1\\2&3&-6\end{array}\middle|\begin{array}{l}47\\58\\-11\end{array}\right]\to\left[\begin{array}{l}3&7&-5\\0&5&8\\0&0&0\end{array}\middle|\begin{array}{l}47\\127\\0\end{array}\right]\)
最后的矩阵出现了一个全 \(0\) 的行,说明这一行无效。\(3\) 个未知数只有两个方程,此时有无穷多个解。
- 无解
\(\left\{\begin{array}{l}3x_1+7x_2-5x_3=47\\x_1+4x_2+x_3=58\\2x_1+3x_2-6x_3=5\end{array}\right.\to\left[\begin{array}{l}3&7&-5\\1&4&1\\2&3&-6\end{array}\middle|\begin{array}{l}47\\58\\5\end{array}\right]\to\left[\begin{array}{l}3&7&-5\\0&5&8\\0&0&0\end{array}\middle|\begin{array}{l}47\\127\\16\end{array}\right]\)
最后的矩阵出现了一个 \(0=16\) 的矛盾行,所以无解。
高斯-约当消元法
可以发现上面的式子很难一眼看出来是怎么推出来的(包括我也是摘抄的),所以,这边给出一种简单消元方法。
消元过程如下:
- 从第 \(1\) 列开始,选择一个非 \(0\) 的系数(代码中的实现是选最大的系数,避免转换其他系数时产生过大的数值)所在的行,把这一行移动到第 \(1\) 行,称此时第一行的 \(x_1\) 为主元(参考下面转换中第一个矩阵到第二个矩阵的变换)
- 把 \(x_1\) 的系数转换为 \(1\),参考下面转换的第二个矩阵到第三个矩阵。
- 利用主元 \(x_1\) 的系数,把其他行的这一列的主元消去,参考下面转换的第三个矩阵到第四个矩阵。
- 重复以上步骤,直到可以判断线性方程组的
\(\left[\begin{matrix}3&7&-5\\1&4&1\\8&-3&9\end{matrix}\middle|\begin{matrix}47\\58\\88\end{matrix}\right]\to\left[\begin{matrix}8&-3&9\\1&4&1\\3&7&-5\end{matrix}\middle|\begin{matrix}88\\58\\47\end{matrix}\right]\to\left[\begin{matrix}1&-0.38&1.12\\1&4&1\\3&7&-5\end{matrix}\middle|\begin{matrix}11\\58\\47\end{matrix}\right]\to\left[\begin{matrix}1&-0.38&1.12\\0&4.38&0.12\\0 &8.12&-8.38\end{matrix}\middle|\begin{matrix}11\\47\\14\end{matrix}\right]\to\cdots\to\left[\begin{matrix}1&0&0\\0&1&0\\0&0&1\end{matrix}\middle|\begin{matrix}5\\11\\9\end{matrix}\right]\)
消元过程中的除法可能会产生精度问题,所以我们设置一个很小的 \(eps\),小于 \(eps\) 数则令其为 \(0\),代码中有 \(3\) 层 for 循环,复杂度为 \(O(n^3)\)。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
#define ld long double
using namespace std;
const ld eps=1e-6;
const int MN=105;
ll n,p;
ld a[MN][MN];
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
int main(){
n=read();
for(int i=1; i<=n; i++) for(int j=1; j<=n+1; j++) scanf("%Lf",&a[i][j]);
for(int i=1; i<=n; i++){
p=i;
for(int j=i+1; j<=n; j++) if(fabs(a[j][i])>fabs(a[p][i])) p=j;
for(int j=1; j<=n+1; j++) swap(a[i][j],a[p][j]);
if(fabs(a[i][i])<eps){printf("No Solution\n");return 0;}
for(int j=n+1; j; j--) a[i][j]=(ld)a[i][j]/a[i][i];
for(int j=1; j<=n; j++) if(j!=i){
double tmp=(ld)a[j][i]/a[i][i];
for(int k=1; k<=n+1; k++) a[j][k]-=a[i][k]*tmp;
}
}
for(int i=1; i<=n; i++) printf("%.2Lf\n",a[i][n+1]);
return 0;
}
跟原来的差距是我们记录了有几个方程式可以找到主元,要是能找到 \(n\) 个(即 \(tot=n+1\))那么说明这个线性方程组有解,否则在找不到主元的方程中要是有一个方程等号右边不等于零,那么这个方程组无解,否则,它有无数个解。
实现细节:记得要把除数为 \(0\)(或者说除数无限接近于 \(0\))的判掉。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const double eps=1e-8;
const int MN=105;
ll n,p,tot=1;
double a[MN][MN];
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
int main(){
n=read();
for(int i=1; i<=n; i++) for(int j=1; j<=n+1; j++) scanf("%lf",&a[i][j]);
for(int i=1; i<=n; i++){
p=tot;
for(int j=tot+1; j<=n; j++) if(fabs(a[j][i])>fabs(a[p][i])) p=j;
if(fabs(a[p][i])<eps) continue;
for(int j=1; j<=n+1; j++) swap(a[tot][j],a[p][j]);
for(int j=n+1; j; j--) if(!(fabs(a[tot][i])<eps)) a[i][j]=(double)a[i][j]/a[tot][i];
for(int j=1; j<=n; j++) if(j!=tot&&!(fabs(a[tot][i])<eps)){
double tmp=(double)a[j][i]/a[tot][i];
for(int k=1; k<=n+1; k++) a[j][k]-=a[tot][k]*tmp;
}
tot++;
}
if(tot==n+1) for(int i=1; i<=n; i++) printf("x%d=%.2lf\n",i,a[i][n+1]);
else{
while(tot<=n) if(!(fabs(a[tot++][n+1])<eps)){write(-1);putchar('\n');return 0;}
write(0);putchar('\n');
}
return 0;
}
矩阵求逆
既然都讲了高斯消元,怎么能不讲矩阵求逆呢?(bushi)
矩阵求逆由于讲课人能力有限,所以我就不给出证明了(我也不会)。
这边给出做法:
- 求 \(A\) 的逆矩阵,把 \(A\) 和单位矩阵 \(I\) 放在一个矩阵里。
- 对 \(A\) 进行加减消元使 \(A\) 化成单位矩阵。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int mod=1e9+7;
const int MN=405;
ll n,a[MN][MN<<1];
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
ll ksm(ll a, ll b){ll res=1;while(b){if(b&1)res=res*a%mod;a=a*a%mod;b>>=1;}return res;}
int main(){
n=read();
for(int i=1; i<=n; i++) for(int j=1; j<=n; j++) a[i][j]=read();
for(int i=1; i<=n; i++) a[i][i+n]=1;
for(int i=1; i<=n; i++){
ll p=i;
for(int j=i+1; j<=n; j++) if(a[p][i]<a[j][i]) p=j;
if(i!=p) swap(a[i],a[p]);
if(!a[i][i]){printf("No Solution\n");return 0;}
ll ny=ksm(a[i][i],mod-2);
for(int j=1; j<=n; j++) if(i!=j){
ll num=a[j][i]*ny%mod;
for(int k=i; k<=(n<<1); k++) a[j][k]=((a[j][k]-num*a[i][k]%mod)%mod+mod)%mod;
}
for(int j=1; j<=(n<<1); j++) a[i][j]=a[i][j]*ny%mod;
}
for(int i=1; i<=n; i++){for(int j=n+1; j<=(n<<1); j++) write(a[i][j]),putchar(' ');putchar('\n');}
return 0;
}
P4035
求一个点 \((x_1,x_2,x_3,\cdots,x_n)\) 使得 \(\begin{aligned}\sum^{n+1}_{j=1}(a_{i,j}-x_j)^2=C\end{aligned}\)
但是细心发现有 \(n+1\) 个方程,考虑相邻相减,然后正好消去常数 \(C\)。
于是 \(\begin{aligned}\sum_{j=1}^n(a_{i,j}^2-a_{i+1,j}^2-2x_j(a_{i,j}-a_{i+1,j}))=0\end{aligned}\)
移项,\(\begin{aligned}\sum_{j=1}^n(a_{i,j}^2-a_{i+1,j}^2)=\sum_{j=1}^n2x_j(a_{i,j}-a_{i+1,j})=0\end{aligned}\)
于是可以高斯消元,增广矩阵:
\(\begin{bmatrix}2(a_{1,1}-a_{2,1})&2(a_{1,2}-a_{2,2})&\cdots&2(a_{1,n}-a_{2,n})&\begin{aligned}\sum_{j=1}^n(a_{1,j}^2-a_{2,j}^2)\end{aligned}\\2(a_{2,1}-a_{3,1})&2(a_{2,2}-a_{3,2})&\cdots&2(a_{2,n}-a_{3,n})&\begin{aligned}\sum_{j=1}^n(a_{2,j}^2-a_{3,j}^2)\end{aligned}\\\cdots\\2(a_{n,1}-a_{n+1,1})&2(a_{n,2}-a_{n+1,2})&\cdots&2(a_{n,n}-a_{n+1,n})&\begin{aligned}\sum_{j=1}^n(a_{n,j}^2-a_{n+1,j}^2)\end{aligned}\\\end{bmatrix}\)
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=15;
ll n;
double m[MN][MN],a[MN][MN];
int main(){
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
cin>>n;
for(int i=1; i<=n+1; i++) for(int j=1; j<=n; j++) cin>>a[i][j];
for(int i=1; i<=n; i++) for(int j=1; j<=n; j++){
m[i][j]=(a[i][j]-a[i+1][j])*2;
m[i][n+1]+=a[i][j]*a[i][j]-a[i+1][j]*a[i+1][j];
}
for(int i=1; i<=n; i++){
ll p=i;
for(int j=i+1; j<=n; j++) if(fabs(m[j][i])>fabs(m[p][i])) p=j;
for(int j=1; j<=n+1; j++) swap(m[i][j],m[p][j]);
for(int j=n+1; j; j--) m[i][j]=(double)m[i][j]/m[i][i];
for(int j=1; j<=n; j++) if(j!=i){
double tmp=(double)m[j][i]/m[i][i];
for(int k=1; k<=n+1; k++) m[j][k]-=m[i][k]*tmp;
}
}
for(int i=1; i<=n; i++) printf("%.3lf ",m[i][n+1]);
return 0;
}//250212
例题
容斥原理
德摩根(De Morgan)定理
别看这个定理看得高大尚,其实画个图就可以理解
- \(\overline{A\cup B}=\overline{A}\cap\overline{B}\)
- \(\overline{A\cap B}=\overline{A}\cup\overline{B}\)
严格的证明如下,只给第一个,第二个同理。
证明:设 \(x\in\overline{A\cup B}\),则 \(x\notin A\cup B\)。
\(x\notin A\cup B\) 等价于 \(x\notin A\) 和 \(x\notin B\) 同时成立,所以有
反之,\(x\in\overline{A}\cup\overline{B}\),即 \(x\in\overline{A}\) 同时 \(x\in\overline{B}\),也就是 \(x\notin A\) 同时 \(x\notin B\),即 \(x\notin A\cup B\),所以有 \(x\in\overline{A}\cap\overline{B}\) 的必要条件为 \(x\in\overline{A\cup B}\)。
故 \(x\in\overline{A}\cap\overline{B}\) 的充要条件为 \(x\in\overline{A\cup B}\)。
\(\therefore\overline{A\cup B}=\overline{A}\cap\overline{B}\)
这个定理还可以推广到一般:
- \(\overline{A_1\cup A_2\cup\cdots\cup A_n}=\overline{A_1}\cap\overline{A_2}\cap\cdots\cap\overline{A_n}\)
- \(\overline{A_1\cap A_2\cap\cdots\cap A_n}=\overline{A_1}\cup\overline{A_2}\cup\cdots\cup\overline{A_n}\)
这两个可以用数学归纳法,这里一第一个证明为例,第二个同理。
证明:\(n=2\) 的时候已经证明成立,这里假定 \(\overline{A_1\cup A_2\cup\cdots\cup A_n}=\overline{A_1}\cap\overline{A_2}\cap\cdots\cap\overline{A_n}\) 成立,有
故,定理对 \(n+1\) 为真。
容斥原理
根据加法法则,若 \(A\cap B=\varnothing\),则 \(|A\cup B|=|A|+|B|\),若 \(A\cap B\neq\varnothing\) 是,这是会将 \(|A\cap B|\) 多算一次,所以由上面的图直观地得到:
再给出一张图:
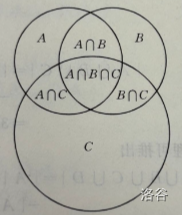
于是我们有:\(|A\cup B\cup C|=|A|+|B|+|C|-|A\cap B|-|A\cap C|-|B\cap C|+|A\cap B\cap C|\)。
证明:
\(|A\cup B\cup C|=|(A\cup B)\cup C|=|A\cup B|+|C|-|(A\cup B)\cap C|\)
又 \(\because(A\cup B)\cap C=(A\cap C)\cup(B\cap C),|A\cup B|=|A|+|B|-|A\cap B|\)
\(\therefore |(A\cap C)\cup(B\cap C)|=|A\cap C|+|B\cap C|-|(A\cap C)\cap(B\cap C)|\)
\(\begin{aligned}\therefore |A\cup B\cup C|&=|A|+|B|-|A\cap B|-|(A\cap C)\cup(B\cap C)|+|C|\\&=|A|+|B|-|A\cap B|-|A\cap C|-|B\cap C|+|(A\cap C)\cap(B\cap C)|+|C|\\&=|A|+|B|+|C|-|A\cap B|-|A\cap C|-|B\cap C|+|A\cap B\cap C|\end{aligned}\)
证毕。
接下来我们可以推广下,得到真正的容斥定理:
假设 \(A_1,A_2,\cdots,A_n\) 是 \(n\) 个有限集合,则有:
\(\begin{aligned}|A_1\cup A_2\cup \cdots\cup A_n|&=(|A_1|+|A_2|+\cdots+|A_n|)\\&-(|A_1\cap A_2|+|A_1\cap A_3|+\cdots+|A_1\cap A_n|\\&+|A_2\cap A_3|+\cdots+|A_{n-1}\cap A_n|)\\&+(|A_1\cap A_2\cap A_3|+\cdots+|A_{n-2}\cap A_{n-1}\cap A_n|)\\&\cdots\\&+(-1)^{n-1}|A_1\cap A_2\cap\cdots\cap A_n|\\&=\sum_{i=1}^n|A_i|-\sum_{i=1}^n\sum_{j>i}|A_i\cap A_j|+\sum_{i=1}^n\sum_{j>i}\sum_{k>j}|A_i\cap A_j\cap A_k|+\cdots\\&+(-1)^{n-1}|A_1\cap A_2\cap\cdots\cap A_n|\end{aligned}\)
证明:还是用数学归纳法证明。
当 \(n=2\) 时,显然成立。
假定 \(n-1\) 时正确,即
\(\begin{aligned}|A_1\cup A_2\cup \cdots\cup A_{n-1}|&=\sum_{i=1}^{n-1}|A_i|-\sum_{i=1}^{n-1}\sum_{j>i}|A_i\cap A_j|+\sum_{i=1}^{n-1}\sum_{j>i}\sum_{k>j}|A_i\cap A_j\cap A_k|+\cdots\\&+(-1)^{n-2}|A_1\cap A_2\cap\cdots\cap A_{n-1}|\end{aligned}\)
\(\begin{aligned}\therefore|A_1\cup A_2\cup\cdots\cup A_n|&=|(A_1\cup A_2\cup\cdots\cup A_{n-1})\cup A_n|\\&=|A_1\cup A_2\cup\cdots\cup A_{n-1}|+|A_n|-|(A_1\cup A_2\cup\cdots\cup A_{n-1})\cap A_n|\\&=\sum_{i=1}^{n-1}|A_i|-\sum_{i=1}^{n-1}\sum_{j>i}|A_i\cap A_j|+\sum_{i=1}^{n-1}\sum_{j>i}\sum_{k>j}|A_i\cap A_j\cap A_k|+\cdots\\&+(-1)^{n-2}|A_1\cap A_2\cap\cdots\cap A_{n-1}|+|A_n|\\&-|(A_1\cup A_2\cup\cdots\cup A_{n-1})\cap A_n|\end{aligned}\)
又 \(\because(A_1\cup A_2\cup\cdots\cup A_{n-1})\cap A_n=(A_1\cap A_n)\cup(A_2\cap A_n)\cup\cdots\cup(A_{n-1}\cap A_n)\)
\(\begin{aligned}\therefore|(A_1\cup A_2\cup\cdots\cup A_{n-1})\cap A_n|&=|(A_1\cap A_n)\cup(A_2\cap A_n)\cup\cdots\cup(A_{n-1}\cap A_n)|\\&=|A_1\cup A_n|+|A_2\cup A_n|+\cdots+|A_{n-1}\cup A_n|\\&-|A_1\cap A_2\cap A_n|-|A_1\cap A_3\cap A_n|-\cdots\\&-|A_{n-2}\cap A_{n-1}\cap A_n|+\cdots\\&+(-1)^{n-2}|A_1\cap A_2\cap \cdots\cap A_n|\\&=\sum_{i-1}^{n-1}|A_i\cap A_n|-\sum_{i=1}^{n-1}\sum_{j>i}|A_i\cap A_j\cap A_n|+\cdots\\&+(-1)^{n-2}|A_1\cap A_2\cap \cdots\cap A_n|\end{aligned}\)
\(\begin{aligned}\therefore|A_1\cup A_2\cup\cdots\cup A_n|&=\sum_{i=1}^n|A_i|-\sum_{i=1}^n\sum_{j>i}|A_i\cap A_j|+\sum_{i=1}^n\sum_{j>i}\sum_{k>j}|A_i\cap A_j\cap A_k|+\cdots\\&+(-1)^{n-1}|A_1\cap A_2\cap \cdots\cap A_n|\end{aligned}\)
容斥原理要记住这些:
(1) 集合 \(S\) 中不具有性质 \(P_1,P_2,\cdots,P_n\) 的对象个数为
\(\begin{aligned}|\overline{A_1}\cap\overline{A_2}\cap\cdots\cap\overline{A_n}|&=|S|-\sum_{i=1}^n|A_i|+\sum_{i=1}^n\sum_{j>i}|A_i\cap A_j|-\sum_{i=1}^n\sum_{j>i}\sum_{k>j}|A_i\cap A_j\cap A_k|\\&+\cdots+(-1)^{n-1}|A_1\cap A_2\cap \cdots\cap A_n|\end{aligned}\)
简记(我的方法):奇减偶加
(2) 集合 \(S\) 中至少具有性质 \(P_1,P_2,\cdots,P_n\) 之一的对象个数为
\(\begin{aligned}|A_1\cup A_2\cup\cdots\cup A_n|&=\sum_{i=1}^n|A_i|-\sum_{i=1}^n\sum_{j>i}|A_i\cap A_j|+\sum_{i=1}^n\sum_{j>i}\sum_{k>j}|A_i\cap A_j\cap A_k|+\cdots\\&+(-1)^{n-1}|A_1\cap A_2\cap \cdots\cap A_n|\end{aligned}\)
简记:奇加偶减
数学例题
【解析 \(1\)】简单容斥原理
首先,\(100\) 以内能被 \(2,3,5\) 中整除的数有:
- \(|A_1|=\lfloor\frac{100}{2}\rfloor=50\)
- \(|A_2|=\lfloor\frac{100}{3}\rfloor=33\)
- \(|A_3|=\lfloor\frac{100}{5}\rfloor=20\)
- \(|A_1\cap A_2|=\lfloor\frac{100}{lcm(2,3)}\rfloor=16\)
- \(|A_1\cap A_3|=\lfloor\frac{100}{lcm(2,5)}\rfloor=10\)
- \(|A_2\cap A_3|=\lfloor\frac{100}{lcm(3,5)}\rfloor=6\)
- \(|A_1\cap A_2\cap A_3|=\lfloor\frac{100}{lcm(2,3,5)}\rfloor=3\)
故答案为 \(\begin{aligned}\sum_{i=1}^3|A_i|-\sum_{i=1}^3\sum_{j>i}|A_i\cap A_j|+|A_1\cap A_2\cap A_3|=50+33+20-16-10-6+3=74\end{aligned}\)。
【解析 \(2\)】简单容斥原理+排列组合
- \(S\) 的全排列个数 \(|S|\) 为 \(6!\)。
- \(S\) 中包含
ace的排列个数 \(|A_1|\) 为 \(4!\)。(捆绑法,把ace看成一个整体) - \(S\) 中包含
bf的排列个数 \(|A_2|\) 为 \(5!\)。 - \(S\) 中既包含
ace又包含bf的排列个数 \(|A_1\cap A_2|\) 为 \(3!\)。
所以,这 \(6\) 个字符构成的全排列中不允许出现 ace 和 bf 的排列数为:
例题
这题看起来像多重背包,但是即使是二进制优化也无法过去。
这题的正解是:完全背包+容斥原理~~~(鼓掌)
其实本题就是求解这个问题:\(\begin{aligned}\sum[\sum_{i=1}^n c_ix_i=s,x_i\leqslant d_i\end{aligned}]\)
其中 \(x_i\) 表示第 \(i\) 种硬币的数量,求 \(x\) 的解有多少个。
但是正着求需要用单调队列优化多重背包,并不是今天的主题,这里不过多提出。
既然不能正这做,那就考虑反着做,没有限制的方案数是好求的,不合法的方案数也是好求的,考虑容斥。
如果没有 \(d_i\) 的限制,那么这题就是一个完全背包,\(dp_j\) 表示支付钱数为 \(j\) 时的支付方案数,则有:
对于不满足要求的方案则是这么一个问题:
因为我们要求的是不合法的方案数,所以我们只要知道第 \(i\) 个硬币要不要取(\(op_i\gets0\) 或 \(op_i\gets1\)),然后取出 \(d_i+1\) 个第 \(i\) 个硬币,那么这种取法不管剩余硬币怎么取,它一定就是不合法的,在此基础上完全背包即可。
变形一下得 \(\begin{aligned}\sum[\sum_{i=1}^nc_ix_i=s-\sum_{i=1}^n(op_i\neq0)\times c_i\cdot(d_i+1)]\end{aligned}\)
枚举那几个硬币是要选的(用二进制枚举第 \(i\) 个硬币选不选),然后去转移,最后这种状态下不合法方案个数就是 \(\begin{aligned}dp[s-\sum_{i=1}^n(op_i\neq0)\times c_i\cdot(d_i+1)]\end{aligned}\),注意,如果这后面一大串已经小于 \(0\),说明你支付的东西已经大于给定的支付面额,不能考虑进去。
这题中,我们求的是合法的方案数,合法,顾名思义,它不满足任何一个不合法的条件,所以,我们用上面所说的奇减偶加。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=100005;
ll dp[MN]={1},c[5],d[5],T,sum,res;
void write(ll n){if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
int main(){
for(int i=1; i<=4; i++) c[i]=read();
for(int i=1; i<=4; i++) for(int j=c[i]; j<MN; j++) dp[j]+=dp[j-c[i]];
T=read();while(T--){
res=0;for(int i=1; i<=4; i++) d[i]=read();sum=read();
for(int i=0; i<=15; i++){
ll num=sum,cnt=0;
for(int j=1; j<=4; j++) if((i>>(j-1))&1) num-=c[j]*(d[j]+1),cnt^=1;
if(num<0) continue;
res+=!cnt?dp[num]:-dp[num];
}
printf("%lld\n",res);
}
return 0;
}
例题
概率和期望
概率
我们通常把对随机现象的研究叫做随机试验。
称随机试验每一个可能的结果为样本点,记作 \(\omega\);所有样本点所组成的集合称为样本空间,记作 \(\Omega\)。
对于样本空间 \(\Omega\),称它的任意子集为随机事件,我们可以用大写字母 \(A,B,C,\cdots\) 表示随机事件。
当随机事件中包含的样本点出现了,则这个随机事件就发生。
若样本点个数有限,记一个随机事件 \(A\) 的样本点个数为 \(n(A)\)。
由于事件是样本点组成的,我们可以把它们看作是集合。
概率是对随机事件发生的可能性的度量。
我们用一个 \([0,1]\) 中的实数表示概率,越接近 \(1\) 越可能发生,反之越不可能。
对于事件 \(A\) ,我们记其发生的概率为 \(P(A)\)。
显然有 \(P(Ω)=1,P(\varnothing)=0\)。
古典概型是一类概率模型,满足样本空间有限,且每种情况出现概率相
等。通常在 OI 中我们碰到的都是古典概型。
在古典概型中,设研究事件 \(A\) 的样本点个数 \(n(A)=K\),同理 \(n(\Omega)=N\),则
(形象点,\(N\) 个事件中有 \(K\) 件发生了 \(A\) 事件,称发生 \(A\) 事件的概率为 \(\frac{K}{N}\))
例如,记事件 \(A\) 摇骰子摇到 \(\leqslant2\) 的数,则 \(A=\{1,2\},n(A)=2\);
\(\Omega=\{1,2,3,4,5,6\},n(\Omega)=6,P(A)=\frac{1}{3}\)。
由此,类似集合之间关系,我们有事件之间的关系。
事件之间的关系
- 并事件(和事件):事件 \(A\) 与 \(B\) 中至少发生了一个,这样的事件为
\(A\) 与 \(B\) 的并事件(和事件),记作 \(A\cup B\) 或 \(A+B\)。 - 交事件(积事件):事件\(A\) 与 \(B\) 同时发生,这样的事件为 \(A\) 与 \(B\)
的交事件(积事件),记作 \(A\cap B\) 或 \(AB\)。 - 互斥事件:两个事件 \(A,B\) 不能同时发生,即 \(A\cap B=\varnothing\)(\(\varnothing\) 表示空集)则事件 \(A,B\) 互斥。
- 对立事件:\(A\) 与 \(B\) 有且仅有一个发生,\(A\cap B=\varnothing\) 且 \(A\cup B=\Omega\),则事件 \(A,B\) 互为对立,记 \(A\) 的对立事件为 \(A\)。
- 独立事件:定义满足 \(P(AB)=P(A)P(B)\) 的事件 \(A,B\) 互相独立,即互不影响。
概率的性质
- 对于事件 \(A,B\),若 \(A,B\) 互为对立事件,则有 \(P(A)+P(B)=1\)。
- 对于事件 \(A,B\),若事件互相独立,则同时发生的概率:\(P(AB)=P(A)\times P(B)\)。
- 对于事件 \(A,B\),则至少一个发生的概率:\(P(A+B)=P(A)+P(B)−P(AB)\)(见前面的容斥。特别地,当 \(A,B\) 互斥时,\(P(AB)=0\),即 \(P(A+B)=P(A)+P(B)\)。
例题
【解析 \(1\)】
记 \(A\) 为“存在两个同学生日相同”
注意到“存在两人生日相同”和“所有人生日不同”是对立事件,而 \(A\) 不好求,就正难则反,考虑求 \(\overline{A}\),即所有人生日不同的概率。
\(n(\overline{A})\):一个一个确定,第一个人有 \(365\) 种可能,后面每个人比前面少 \(1\)(不能重复),即 \(A^{50}_{365}\)。
\(P(\overline{A})=\frac{A^{50}_{365}}{365^{50}}\approx0.03\)
所以 \(P(A)\approx0.97\)。
可以发现其实概率非常大。
期望
通俗的说,随机变量指随机试验各种结果所表示的值。
在数学中,一个随机变量 \(X\) 的数学期望 \(E(X)\) 为试验中每次可能的结果乘以其概率的和。
形式化地讲,
其中 \(x_i\) 表示事件的一种取值,\(p_i\) 即与之对应的概率。
举个例子:投六面骰子投出的点数的期望为:
\(E(X)=1\times\frac{1}{6}+2\times\frac{1}{6}+3\times\frac{1}{6}+4\times\frac{1}{6}+5\times\frac{1}{6}+6\times\frac{1}{6}=3.5\)
对于任意随机变量 \(X,Y\) 我们有:
即期望的可加性(线性性)。证明略。
例题
【解析 \(2\)】
考虑设 \(E(X_i)\) 表示第 \(i\) 个车站停车次数的期望值,停车为 \(1\),否则为 \(0\),则只要计算 \(\begin{aligned}E(X)=\sum^k_{i=1}E(X_i)\end{aligned}\)。
对于每个车站,每个人不在这个车站下车的可能性为 \(\frac{k−1}{k}\),则所有人都不在这里下车的概率为 \((\frac{k−1}{k})^n\),同时每站期望停车次数等于停车概率。则有:
根据期望的可加性:
\(\begin{aligned}E(X)=\sum_{i=1}^kE(Xi)=k\times[1−(\frac{k−1}{k})^n]\end{aligned}\)
期望的其他性质
设随机变量 \(X\) 的取值仅可能是 \(1\sim n\) 的整数,则有下式成立:
证明:
通常,设事件 \(A\) 发生概率为 \(P(A)(P(A)\neq0)\),则不断试验直到 \(A\) 发生,期望次数为 \(E(X)=\frac{1}{P(A)}\)。
例题
很显然直接 dp,设 \(dp_{i,j}\) 表示前 \(i\) 个硬币有 \(j\) 个是朝上的概率。
很基础的转移,首先我们知道两个硬币的正反情况的是互相独立的事件,所以我们有:
- \(\begin{aligned}dp_{i,j}\gets\max_{j=0}^i\{dp_{i-1,j-1\times p[i]}\}\end{aligned}\)
- \(dp_{i,j}\gets\max(dp_{i,j},dp_{i-1,j\times(1-p[i])})\)
实现细节:注意判断边界。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const int MN=3e3+5;
ll n;
double p[MN],dp[MN][MN],ans;
void write(ll n){if(n<0){putchar('-');write(-n);return;}if(n>9)write(n/10);putchar(n%10+'0');}
ll read(){ll x=0,f=1;char ch=getchar();while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return x*f;}
int main(){
n=read();dp[0][0]=1;
for(int i=1; i<=n; i++) scanf("%lf",&p[i]);
for(int i=1; i<=n; i++) for(int j=0; j<=i; j++){
if(j!=0) dp[i][j]+=dp[i-1][j-1]*p[i];
if(j!=i) dp[i][j]+=dp[i-1][j]*(1-p[i]);
}
for(int i=n/2+1; i<=n; i++) ans+=dp[n][i];
printf("%.12lf\n",ans);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号