

Unicode与utf的前世今生
历史上存在两个独立的尝试创立单一字符集的组织,即
- 国际标准化组织(ISO)于1984年创建的通用字符集(英语:Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。JTC1/SC2/WG2,其含义是International Organization for Standardization / International Electrotechnical Commission, Joint Technical Committee #1 [Information Technology], Subcommittee #2 [Coded Character Sets], Working Group #2 [Multi-octet codes]). ISO 10646表示这是ISO 646的扩展。
- 由Xerox、Apple等软件制造商于1988年组成的统一码联盟。Unicode发展由非营利机构统一码联盟负责。
一个是1988年成立的Unicode团队,另一个是1989年成立的UCS团队。1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。
UCS的开发进度快于Unicode,1990年就公布了第一套编码方法UCS-2,使用2个字节表示已经有码点的字符。(那个时候只有一个平面,就是基本平面,所以2个字节就够用了。)UTF-16编码迟至1996年7月才公布,明确宣布是UCS-2的超集,即基本平面字符沿用UCS-2编码,辅助平面字符定义了4个字节的表示方法。两者的关系简单说,就是UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16。所以,现在只有UTF-16,没有UCS-2。
1991年,不包含CJK统一汉字集的Unicode 1.0发布。随后,CJK统一汉字集的制定于1993年完成,发布了ISO 10646-1:1993,即Unicode 1.1。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。但统一码联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在发布的时候,Unicode一般都会采用有关字码最常见的字体,但ISO 10646一般都尽可能采用Century字体。
Unicode往大了说是一个框架,往小了说是一套字符集。unicode是一个标准,utf-8是标准下的一个编码方式。
字符集只是定义了一种映射关系,这个映射关系是抽象的。因此如果我们想要在计算机中实现这张表中抽象的映射关系,就涉及到了编码/解码。将映射关系中的数字变成字节序列的过程就是编码。将字节序列变成映射关系中的数字的过程就是解码。
- unicode代码空间(the Unicode codespace):Unicode标准里面用21个bits表示的空间范围。范围是:0~0x10FFFF。unicode只规定了数字编号,具体存储是由UTF-*来解决的。
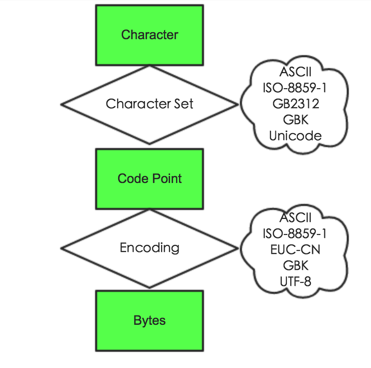
- 字符集(Character Set): 一个字符集,这个字符集里面的每个字符都被赋予一个数值型的码点(code point)。又被称为Coded character set, charset,或者code set。
- 字符(character):字符是文本的最小组成部分。例如
A,B,C...就是不同的字符。同理,中和花也是两个不同的字符。但有时候,字符的含义是和你所处的环境有关的。比如“罗马数字1:Ⅰ”就和小写字母I长得一样,但其实它们是两个不同的字符,它们所表示的含义不一样。 - 码点(code point):(1)字符集里每个字符都对应一个数值,这个数值就是码点。(2)unicode代码空间(the Unicode codespace)里面的任何值都是码点,范围是0~0x10FFFF。不是所有的码点都有对应的字符。一个无符号数字,通常用16进制表示。代码点与字符的一一对应关系称为字符集(Character Set),这种对应关系肯定不止一种,也就导致了不同字符集的出现,像 ASCII、ISO-8859-1、GB2312、GBK、Unicode 等。
- 码元(Code Unit,也称“代码单元”)是指一个已编码的文本中具有最短的比特组合的单元。对于UTF-8来说,码元是8比特长;对于UTF-16来说,码元是16比特长,uft-16还有大端序列和小端序列;对于UTF-32来说,码元是32比特长。码值(Code Value)是过时的用法。
Bytes 二进制字节。其含义为代码点在内存或磁盘中的表示形式。代码点与二进制字节的一一对应关系称为编码(Encoding),当然这种对应关系也不是唯一的,所以编码也有很多种,像 ASCII、ISO-8859-1、ENC-CN、GBK、UTF-8等。
由统一码和通用字符集所构成的现代字符编码模型则没有跟从简单字符集的观点。它们将字符编码的概念分为:有哪些字符、它们的编号、这些编号如何编码成一系列的“码元”(有限大小的数字)以及最后这些单元如何组成八位字节流。区分这些概念的核心思想是创建一个能够用不同方法来编码的一个通用字符集。为了正确地表示这个模型需要更多比“字符集”和“字符编码”更为精确的术语表示。在Unicode Technical Report (UTR) #17中,现代编码模型分为5个层次,所用的术语列在下面:
- 抽象字符表(Abstract character repertoire)是一个系统支持的所有抽象字符的集合,构成字符集。就是你能看到的各种符号,比如a,b,c,1,2,3,中,🦠
- 编码字符集(CCS:Coded Character Set)是将字符集中每个字符映射到1个正整数(code point)。字符集及码位映射称为编码字符集。例如,在一个给定的字符表中,表示大写拉丁字母“A”的字符被赋予整数65、字符“B”是66,如此继续下去。由此产生了编码空间(encoding space)的概念:简单说就是包含所有字符的表的维度。编码空间中的一个位置(position)称为码位(code point)。一个字符所占用的码位称为码位值(code point value)。1个编码字符集就是把抽象字符映射为码位值。
- 字符编码表(CEF:Character Encoding Form),也称为"storage format",是将编码字符集的正整数值(即抽象的码位code point)转换成有限比特长度的整型值(称为码元code units)的序列。这对于定长编码来说是个到自身的映射(null mapping),但对于变长编码来说,该映射比较复杂,把一些码位映射到一个码元,把另外一些码位映射到由多个码元组成的序列。对于UTF-8来说,码元是8比特长,它产生在编码序列可以是1,2,3,4个字节;对于UTF-16来说,码元是16比特长,它只能产生2,4个字节的序列,uft-16还有大端序列和小端序列;对于UTF-32来说,码元是32比特长,它只能产生4个字节的序列,也有大端和小端。这个阶段的方案有ascii(字符集和编码表由于数值相等,很容易产生误会),GBK,utf-8,utf-16,utf-32,ucs-2(和utf-16类似,只不过是iso出的标准),ucs-4(和utf-32类似,iso出的标准)
- 字符编码方案(CES:Character Encoding Scheme),也称作"serialization format"。将定长的整型值(即码元)映射到8位字节序列,以便编码后的数据的文件存储或网络传输。在使用Unicode的场合,使用一个简单的字符来指定字节顺序是大端序或者小端序(但对于UTF-8来说并不需要专门指明字节序)。然而,有些复杂的字符编码机制(如ISO/IEC 2022)使用控制字符转义序列在几种编码字符集或者用于减小每个单元所用字节数的压缩机制(如SCSU、BOCU和Punycode)之间切换。
- 传输编码语法(transfer encoding syntax),用于处理上一层次的字符编码方案提供的字节序列。一般其功能包括两种:一是把字节序列的值映射到一套更受限制的值域内,以满足传输环境的限制,例如Email传输时Base64或者quoted-printable,都是把8位的字节编码为7位长的数据;另一是压缩字节序列的值,如LZW或者行程长度编码等无损压缩技术。
unicode基础平面:统一码的编码方式与 ISO 10646 的通用字符集概念相对应。当前实际应用的统一码版本对应于 UCS-2,使用 16 位的编码空间。也就是每个字符占用 2 个字节。这样理论上一共最多可以表示 216(即 65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这 16 位编码,而是保留了大量空间以作为特殊使用或将来扩展。上述 16 位统一码字符构成基本多文种平面。
unicode辅助平面:最新(但未实际广泛使用)的统一码版本定义了 16 个辅助平面,两者合起来至少需要占据 21 位的编码空间,比 3 字节略少。但事实上辅助平面字符仍然占用 4 字节编码空间,与 UCS-4 保持一致。未来版本会扩充到 ISO 10646-1 实现级别 3,即涵盖 UCS-4 的所有字符。UCS-4 是一个更大的尚未填充完全的 31 位字符集,加上恒为 0 的首位,共需占据 32 位,即 4 字节。理论上最多能表示 231个字符,完全可以涵盖一切语言所用的符号。基本多文种平面的字符的编码为 U+hhhh,其中每个 h 代表一个十六进制数字,与 UCS-2 编码完全相同。而其对应的 4 字节 UCS-4 编码后两个字节一致,前两个字节则所有位均为 0。
我们平时说的 ASCII 其实有两个含义,一个是 ASCII 字符集,另一个是 ASCII 编码。
ASCII 字符集只是定义了字符与字符码(character code,也称 code point 代码点)的对应关系。也就是说这一层面只是规定了字符
A用 65 表示,至于这个 65 在内存或硬盘中怎么表示,它不管,那是 ASCII 编码做的事。
ASCII 编码规定了用 7 个二进制位来保存 ASCII 字符码,即定义了字符集的
存储形式。
我们在互联网上查找编码相关资料时,经常会看到UCS-2、UCS-4编码,它们和UTF-*编码家族是什么关系呢?要想理清它们之间的关系,需要先弄清楚,什么是 UCS。
UCS 全称是 Universal Coded Character Set,是由 ISO/IEC 10646定义的一套标准字符集,是很多字符编码的基础,UCS 中大概包含 100,000 个抽象字符,每一个字符都有一唯一的数字编码,称为 code point。
在19世纪八十年代晚期,有两个组织同时在 UCS 的基础上开发一种与具体语言无关的统一的编码方案,这两个组织分别是 IEEE 与 Unicode Consortium,为了保持这两个组织间编码方案的兼容性,两个组织尝试着合作。早期的两字节编码方案叫做“Unicode”,后来改名为“UCS-2”,在研发过程发,发现 16 位根本不能够囊括所有字符,于是 IEEE 引入了新的编码方案——UCS-4 编码,这种编码每个字符需要 4 个字节,这一行为立刻被 Unicode Consortium 制止了,因为这种编码太浪费空间了,又因为一些设备厂商已经对 2 字节编码技术投入大量成本,所以在 1996 年 7 月发布的 Unicode 2.0 中提出了 UTF-16 来打破 UCS-2 与 UCS-4 之间的僵局,UTF-16 在 2000 年被 IEFE 组织制定为RFC 2781标准。更多可参考:
由此可见,UCS-* 编码是一历史产物,目前来说,统一编码方案最终的赢家是 UTF-* 编码。
这里有个文字游戏,一般我们说“某某字符串是XX编码”,其实这是不合理的,因为字符串压根就没有编码这一说法,只有字符才有,字符串只是字符的一串序列而已。
不过我们平时并没有这么严谨,不过你要明白,当我们说“某某字符串是XX编码”时,知道这其实指的是该字符串中字符的编码就可以了。
