

基准测试基础
基准测试
定义
基准测试是一种用于衡量计算机系统,软件应用或硬件组件性能的测试方法。
基准测试旨在通过运行一系列标准化的任务场景来测量系统的性能表现,从而帮助评估系统的各种指标,如响应时间、并发用户数、TPS、资源利用率、交易成功率等。
特质
① 可重复性: 可进行重复性的测试,这样做有利于比较每次的测试结果,得到性能结果的长期变化趋势,为系统调优和上线前的容量规划做参考。
② 可观测性: 通过全方位的监控(包括测试开始到结束,执行机、服务器、数据库),及时了解和分析测试过程发生了什么。
③ 可展示性: 相关人员可以直观明了的了解测试结果(web界面、仪表盘、折线图树状图等形式)。
④ 真实性:测试的结果反映了客户体验到的真实的情况(真实准确的业务场景+与生产一致的配置+合理正确的测试方法)。
⑤ 可执行性: 相关人员可以快速的进行测试验证修改调优(可定位可分析)。
组成部分
不同的系统具有不同程度的复杂性,并且需要不同的技术来测试应用程序。
基准测试包含3个主要组成部分。
① 工作负载规格: 确定要提交给被测系统的请求的类型和频率。
② 度量规格: 确定要测量的元素,例如; 下载速度
③ 测量规格: 确定如何测量指定的元素以找到合适的值
java的微基准测试工具: jmh
定义
全称Java Microbenchmark Harness (微基准测试框架),是专门用于Java代码微基准测试的一套测试工具API,是由Java虚拟机团队开发的的,一般用于代码的性能调优。
微基准测试
MicroBenchmark就是在method层面上的benchmark,精度可以精确到微秒级、甚至可以达到纳秒级别,适用于 java 以及其他基于 JVM 的语言。与Apache JMeter 不同,JMH 测试的对象可以是任一方法,颗粒度更小,而不仅限于接口以及API层面。
实践
maven依赖
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.33</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.33</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-maven-plugin</artifactId>
<version>1.33</version> <!-- 使用你需要的版本 -->
<executions>
<execution>
<id>run-benchmarks</id>
<phase>integrate-test</phase>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
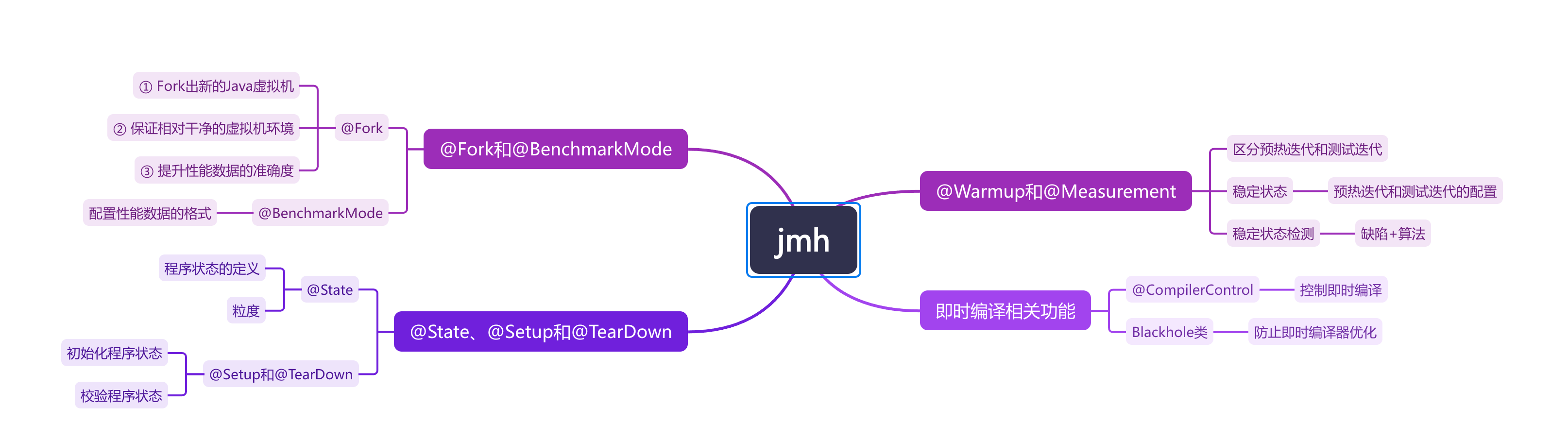
注解
@State
State类注解 -> "状态"类, 指定状态实例的生命周期和共享范围
Scope.Thread:每个测试线程分配一个状态实例
Scope.Benchmark:所有测试线程共享一个状态实例
Scope.Group:每个线程组共享一个状态实例
@Group
Group注解加在方法上,用来把测试方法进行归类。如果你单个测试文件中方法比较多,或者需要将其归类,则可以使用这个注解。
与之关联的 @GroupThreads 注解,会在这个归类的基础上,再进行一些线程方面的设置。这两个注解都很少使用,除非是非常大的性能测试案例。
@Fork
1.正常的 JMH 运行在任何给定时间都有两个进程在运行。第一个(“主机”)进程处理运行。第二个(“ fork ”)进程是运行一个给定的通过实现隔离来实现的用于基准测试的进程。通过注解或命令行(优先于注解)请求 N 个 fork 使得 fork 进程连续调用 N 次。请求零 fork 直接在托管进程本身中运行工作负载。
2.进行 fork 的次数。如果 fork 数是3的话,则 JMH 会 fork 出3个进程来进行测试。
@Fork(value = 3, jvmArgsAppend = {"-Xmx2048m", "-server", "-XX:+AggressiveOpts"})
fork注解有一个参数叫做jvmArgsAppend,我们可以通过它传递一些JVM的参数。
@BenchmarkMode
BenchmarkMode类或方法注解, 指定基准测试的模式。
Throughput(吞吐量) ops/time
AverageTime(平均时间) time/op
SampleTime(随机采样时间) time/op
SingleShotTime(单次执行时间)
All(所有模式) time/op
单位中的 op 代表的是一次操作,默认一次操作指的是执行一次测试方法。但是我们可以指定调用多少次测试方法算作一次操作。在 JMH 中称作操作中的批处理次数,例如我们可以设置执行五次测试方法算作一次操作。
@OutputTimeUnit
OutputTimeUnit类或方法注解, 指定基准测试结果的时间单位。
@Benchmark
Benchmark方法注解 -> 标识基准测试方法
@Param
Param字段注解 -> 指定基准测试的参数, 为基准测试方法提供不同的输入值,以便测试在不同条件下的性能
@Setup
Setup方法注解, 指定在基准测试方法执行之前运行的初始化方法。
@TearDown
与@Setup相对,在所有benchmark 执行结束以后执行,主要用于资源的回收等。
@Setup/@TearDown注解使用Level参数来指定何时调用fixture。
| 名称 | 描述 |
|---|---|
| Level.Trial | 默认level。Benchmark 开始前或结束后执行,如下。Level 为Benchmark 的 Setup 和 TearDown 方法的开销不会计入到最终结果。 |
| Level.Iteration | Benchmark 里每个 Iteration 开始前或结束后执行,Level 为 Iteration 的 Setup 和 TearDown 方法的开销不会计入到最终结果。 |
| Level.Invocation | Iteration 里每次方法调用开始前或结束后执行,如Level 为 Invocation 的 Setup 和 TearDown 方法的开销将计入到最终结果。 |
@WarmUp
WarmUp方法注解, Warmup是指在实际进行 Benchmark 前先进行预热的行为。
预热的目的和意义
|
JVM 的JIT机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译成为机器码从而提高执行速度。为了让 Benchmark 的结果更加接近真实情况就需要进行预热。
由于JVM会使用JIT即时编译器对热点代码进行编译,因此同一份代码可能由于执行次数的增加而导致执行时间差异太大,因此我们可以让代码先预热几轮,预热时间不算入测量计时。 |
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement
@Measurement类或方法, 用于指定测试的次数、时间和批处理数量,提供真正的测试阶段参数,指定迭代的次数,每次迭代的运行时间和每次迭代测试调用的数量。
iterations:测量次数,默认是 5 次。
time:单次测量持续时间,默认是 10。
timeUnit:时间单位,指定 time 的单位,默认是秒。
batchSize:每次操作的批处理次数,默认是 1,即调用一次测试方法算作一次操作。
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) // 先预热5轮publicclassJmhSeample{}
@Warmup和@Measurement分别用于配置预热迭代和测试迭代。其中,iterations用于指定迭代次数,time和timeUnit用于每个迭代的时间,batchSize表示执行多少次Benchmark方法为一个invocation。
@CompilerControl
Java 中方法调用的开销是比较大的,尤其是在调用量非常大的情况下。拿简单的getter/setter 方法来说,这种方法在 Java 代码中大量存在。我们在访问的时候,就需要创建相应的栈帧,访问到需要的字段后,再弹出栈帧,恢复原程序的执行。
如果能够把这些对象的访问和操作,纳入目标方法的调用范围之内,就少了一次方法调用,速度就能得到提升,这就是方法内联的概念。如下图所示,代码经过 JIT 编译之后,效率会有大的提升
用在类或者方法上,能够控制方法的编译行为,常用的有3种模式。
强制使用内联(INLINE),禁止使用内联(DONT_INLINE),甚至是禁止方法编译(EXCLUDE)等。
|
总结:@Fork(进程) -> @Thread(线程) -> @Benchmark(方法) -> Level.Trial(迭代) -> Level.Iteration(迭代) -> Level.Invocation(迭代)
一次基准测试(Trial级别)=多个迭代【iterations】;每次迭代执行时长= time* timeUnit;;一次迭代(Iteration级别)=多次操作【op】;一次操作* batchSize =多次方法调用(Invocation级别)【calls】 |
启动
public static void main(String[] args) throws Exception {
Options opt = new OptionsBuilder()
.include(CacheJmhTest.class.getSimpleName())
.warmupIterations(1)
.measurementIterations(5)
.forks(1)
.build();
new Runner(opt).run();
}
OptionsBuilder.result()
可为使用options方式设置测试结果输出,指定输出路径。
如.result("d:/Demo03.json")
OptionsBuilder.resultFormat()
可为使用options方式设置测试结果输出具体的报告类型,其报告类型有TEXT、CSV、SCSV、JSON、LATEX几种。
如:.resultFormat(ResultFormatType.CSV)
结果输出
JMH支持以下5种格式的结果:
TEXT 导出文本文件。
CSV 导出csv格式文件。
SCSV 导出scsv等格式的文件。
JSON 导出成json文件。
LATEX 导出到latex,一种基于ΤΕΧ的排版系统。
利用导出的报表结果直接(cvs格式)或者间接(json格式)查看结果,如利用
JMH Visualizer(https://jmh.morethan.io/)
jmh-visual-chart(http://deepoove.com/jmh-visual-chart)
对导出json报表展示统计结果。
Profiler
StackProfiler: 输出线程堆栈信息,同时还能统计线程在执行过程中的线程状态数据
GcProfiler: 输出GC信息
ClassLoaderProfiler: 基准方法的执行过程中有多少类被加载或者卸载
CompilerProfiler: 在代码的执行过程中JIT编译器所花费的优化时间
其他Profiler
其他
Interrupts Benchemark
执行某些容器的对鞋操作的时候可能伴随线程的阻塞情况,这种阻塞并非容器本身无法保证线程安全所引起,而是有JMH框架本身机制诱发,JHM运行通过设置Options的timeout来强制让每一个批次的度量超时,超时的基准测试数据也将不会被纳入统计之中。
jvm优化
Dead Code Elimination
DEC是指我们在程序运行时,JVM为我们擦除了一些与上下文无关、甚至于经过计算确认根本用不到的代码
例如:通过计算后没有返回值
JMH给我们提供了一个blackhole类用于接收在不作任何返回的情况下有效避免Deadcode的发生
@Benchmark
public void measureName(Blackhole bh) {
bh.consume(xxxxx)
}
Constant Folding
常量折射不是JMH的概念,在java编译器早期版本针对常量优化中就存在,当我们使用javac命令对源文件进行编译的时候,编译器会通过词法分析发现代码中的某些常量是可以被折射的,即可以将计算结果存放到声明中,注意此时还是编译阶段,而不需要在代码执行阶段才进行运算处理。由此,在使用JMH时候其中一个重要的原则就是测试避免针对已经发生过常量折射的代码来做基准测试。
Loop Unwinding
相交于dead code和Constant Folding分别发生在编码和编译期间而言,循环展开(loop unwinding)则发生在代码运行期间,常见于我们JVM运行阶段后期的优化。如下:当我们尝试对一组自然数循环累加操作
|
解决方案: 可先分析字节码是否有循环展开
① @CompilerControl ② 增加循环的复杂度 ③ 避免使用特定的循环结构(for-each循环更容易被编译器优化) ④ 使用 -XX:MaxLoopUnroll=1 选项 |
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_UNROLL)
public void testMethod() {
// 循环体
}

