
G1系列 - 实践篇 - 白名单膨胀引发的线上gc频繁问题分析
一、问题是怎么发现的
- 早上首页中心出现了多台机器的mdc内存报警,观察mdc内存曲线,发现内存在缓慢增加且较往常增幅稍大。
- 观察jvm的gc和内存情况,没有fullgc,但是yonggc和内存的曲线比较紊乱,且在凌晨仍younggc频繁。
- 打开线上首页,暂未发现明显异常。
二、问题带来的影响
- yonggc和内存的曲线比较紊乱,younggc较往常更为频繁,会影响首页中心的接口性能,进而影响首页用户体验。
三、排查问题的详细过程
3.1 过程
- 观察jvm的gc和内存曲线,往前追溯,发现在前一天18点50分左右曲线出现了异常。
- 首页中心最近并未操作线上发版和配置修改,只有在前一天18点50分上传了一份白名单文件,初步猜测gc异常和上传的文件有关。
- 为了进一步验证猜想,观察预发环境的gc和内存曲线,和线上吻合。关闭预发环境的白名单更新定时任务,预发环境gc和内存曲线恢复正常。
3.2 起因
- 事发前一天18点50分,上传了一份白名单文件到oss,是替换操作,这个白名单文件之前是7W+商家,替换后是11W+商家,文件大小1.1M。
- 白名单更新机制:定时任务每1min下载一次白名单文件,读取文件流获取所有名单,组装集合更新到内存中。
四、如何解决问题
按需更新:
oss下载文件时能获取到更新时间戳。第一次下载时,将该时间戳保存到内存中。后续下载文件时每次都与内存中的时间戳进行比对,如果有更新才会去下载文件流,然后更新内存中的时间戳。否则视为未修改文件,直接关闭文件流下载。
五、问题分析:为什么1.1M的文件定时任务下载会导致gc异常
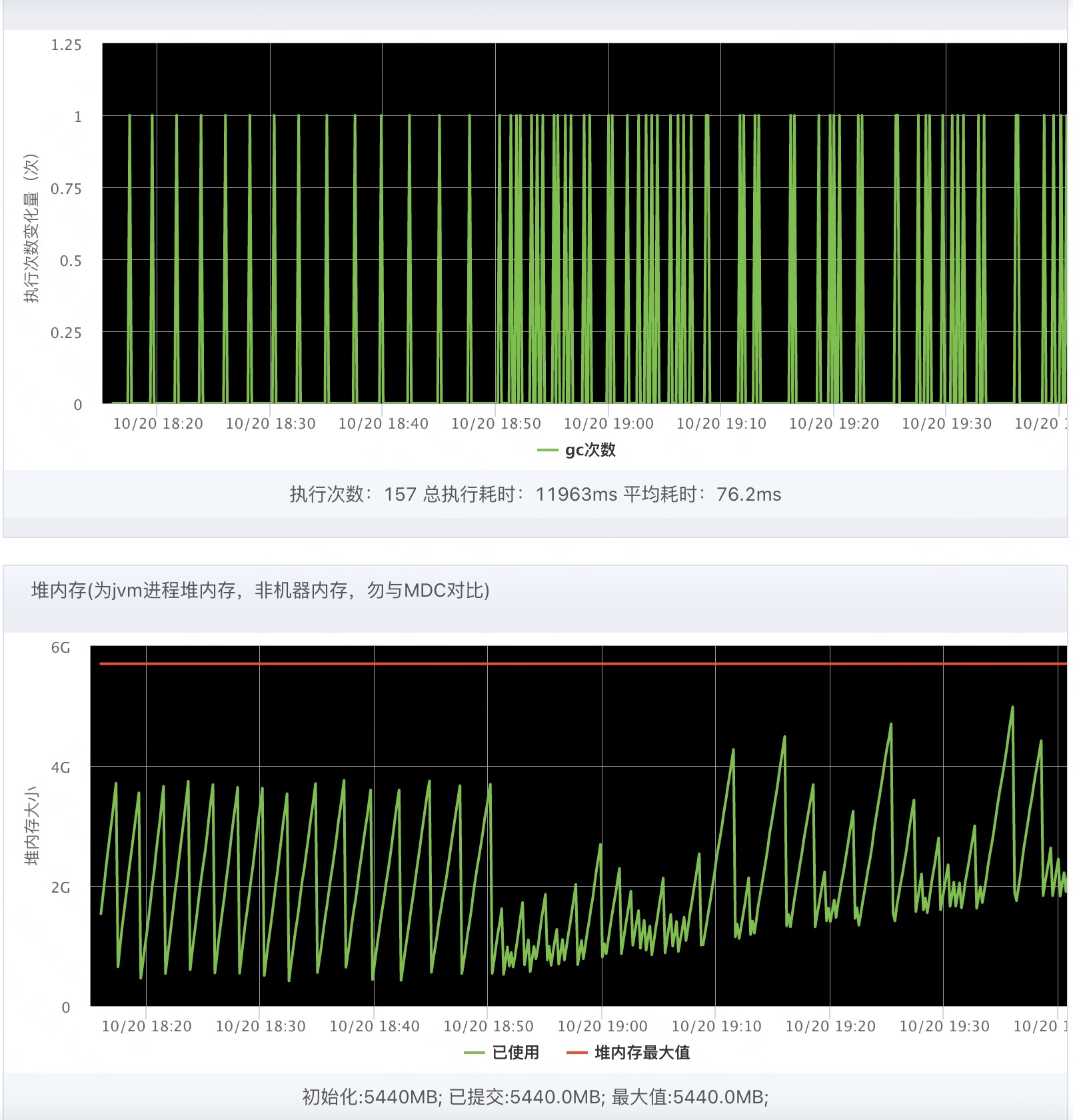
5.1 问题截图
younggc异常开始,内存泄漏?
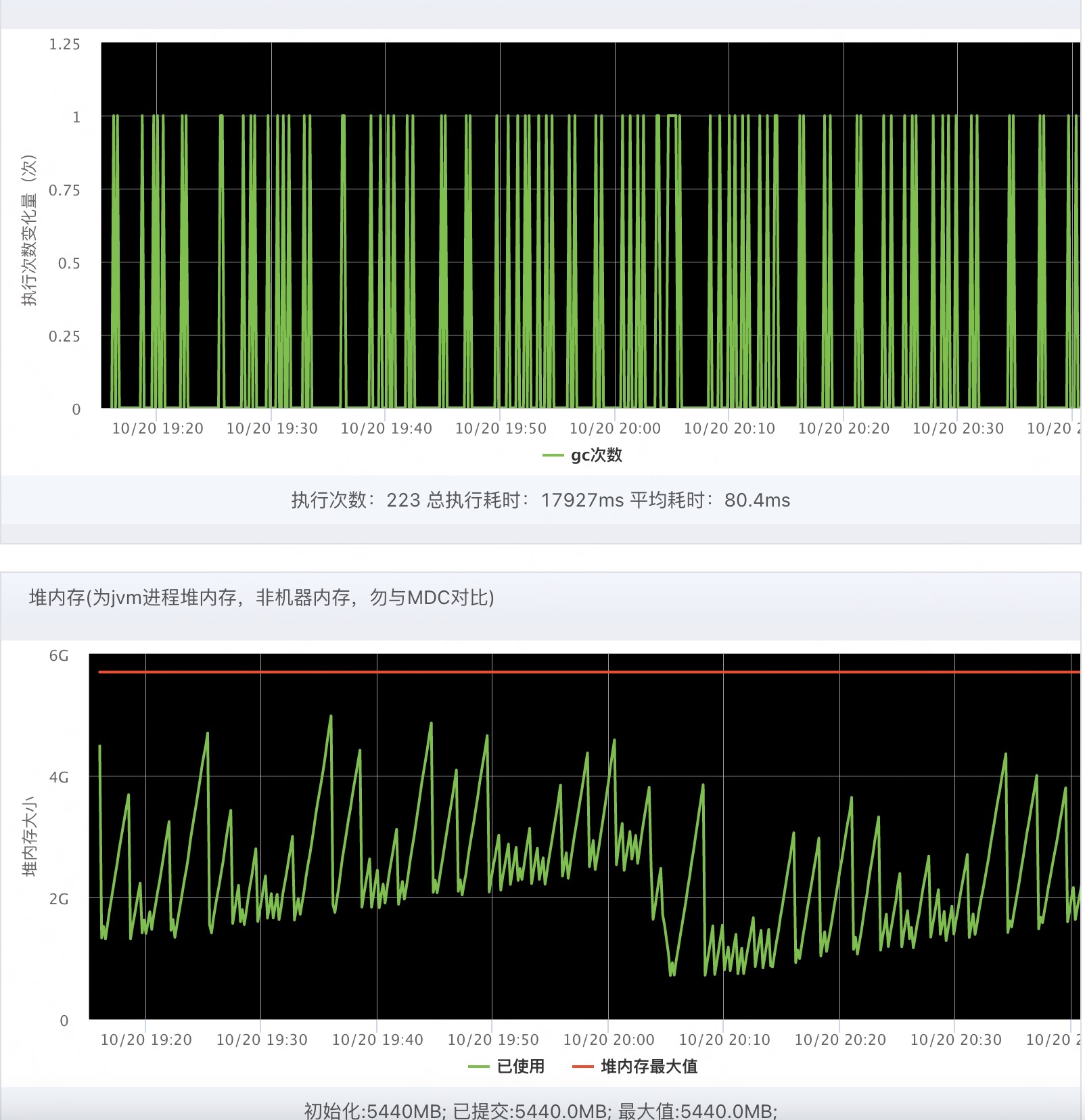
younggc解决了内存泄漏的问题?
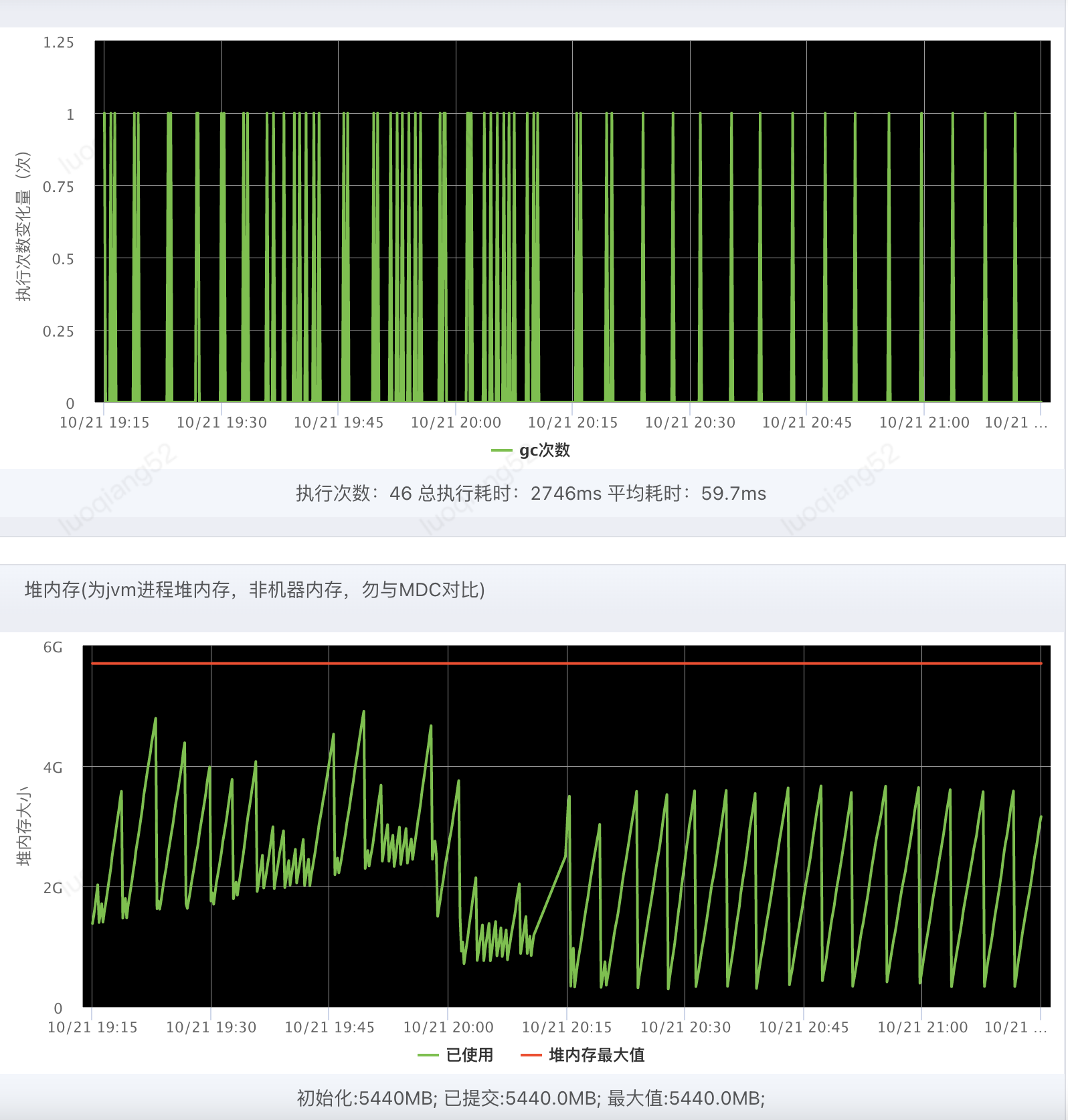
发版后恢复正常
5.2 曲线解释
-Xmx5440M
-Xms5440M
-XX:MaxMetaspaceSize=512M
-XX:MetaspaceSize=512M
-XX:MaxDirectMemorySize=1G
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:+ParallelRefProcEnabled
-XX:ParallelGCThreads=4
-XX:CICompilerCount=3
5.2.1 内存和gc曲线不规律,会周期性地出现多次younggc
分析:
G1垃圾回收器什么时候执行younggc?eden区空间不足时执会行younggc,但是从曲线看在堆内存很低的时候仍会进行younggc,说明G1中的eden区大小是动态变化的。
知识点:
G1为了达到承诺的最大gc停顿时间,会动态调整eden区的大小。
注:G1想要降低停顿时间,就会调低eden区大小,下次younggc要处理的垃圾变少了,自然gc停顿时间就变短了。
问题:那么为什么younggc不和以前一样正常gc,而是变得紊乱了呢?继续往下看
5.2.2 一直有younggc但是gc后留下的内存整体呈上升状,出现内存泄漏的现象
分析1:
内存泄漏,却并没有出现内存溢出。一般这种情况,会出现fullgc清理掉那部分younggc无法处理的垃圾。但是没有出现fullgc,而是在频繁的younggc中内存曲线又回归低位,似乎是进行了一次特殊的younggc?
知识点1:
特殊的younggc叫mixedgc,更准确地说叫并发标记周期,因为实际情况,这里并没有发生mixedgc,而是发生了并发标记周期。(发生mixedgc前置条件是发生了并发标记周期,发生并发标记周期前置条件是发生了younggc)
分析2:
1.1M的文件下载存储到了内存中,或者说产生了1.1M的对象,然后就出现了gc异常,而且是产生了质变,但是0.7M的对象却没事?那么咱们可以猜测异常和对象的大小有关系,0.7M和1.1M中间的1M是否就是一个阈值呢?
知识点2:
region大小计算:region=max((xmx+xms)/2*2048,1m),同时region大小必须是2的次幂,最终得到首页中心region大小为2M。
G1认为只要大小超过了一个Region容量一半的对象即为大对象,大对象在G1里面单独存放区域是Humongous Region。Humongous Region可以认为是一系列连续的region,一般来说也被当做老年代,是不会被younggc清理的(有实验性质的参数可以让younggc清理Humongous region)。
5.2.3 结论:
① 定时任务产生的1.1M的大对象,无法被younggc清理,所以会呈现内存泄漏的现象。
② 没有发生内存溢出,是因为在并发标记周期过程中,会进行Humongous Region的清理,所以可以看到内存曲线恢复正常。
③ younggc变得紊乱:一方面,无法被younggc清理的Humongous Region被视作老年代,本身就积压了eden区的大小。另一方面,因为1.1M的大对象里面的string对象被引用,所以这部分没有被放到Humongous Region,但是younggc也无法清理,只能是younggc后被复制到S0或S1区,这导致了younggc的时间变长,所以g1会调整eden区大小来使下一次younggc时间变短。
注:这里1.1M的大对象有多个,每个1.1M的大对象都会占用一个2M的region,也浪费了内存。
④ 没有发生fullgc是因为发生的并发标记周期最后一个阶段cleanup清理了Humongous Region中的垃圾,也清理了部分老年代的垃圾(要求老年代region中全部是可清理的垃圾)。当然,g1中并发标记周期后面的mixedgc才是清理老年代的主力军。正常情况下,g1其实很难出现fullgc或者说几乎不会出现fullgc。
六、总结反思:是否可以更快发现问题?如何再次避免等。
6.1 是否可以更快发现问题
① jvm的younggc次数设置不敏感,MDC的内存报警无法直观的体现问题
② jvm的gc监控目前并不能区分G1的younggc和并发标记周期,是否可以针对不同垃圾回收器给出不同的监控面板
6.2 如何再次避免
① 极少改动的文件,通过定时任务每次都下载然后替换的方式更新并不合理,功能设计之初就应该把好关。
② 作为灰度使用的黑白名单,难免会出现大对象的情况,既然出现了大对象,那就应该考虑其对GC的影响。
6.3 技术思考
① java应用g1的jvm参数有通用的推荐配置,但是针对不同类型的应用还是要根据实际情况"因地制宜",比如上面的问题就还可以通过手动修改region大小的方式来解决
-XX:G1HeapRegionSize=4M,1.1M的对象小于2M,不为大对象,能正常被younggc清理
② G1为了达到目标停顿时间,支持动态调整eden区的大小,也是这个问题里younggc紊乱的原因之一。但倘若我们手动设置了eden区大小,则G1目标停顿时间的设置就失效了,所谓鱼与熊掌不可兼得。
③ 碎片化、大对象问题是所有垃圾回收器都需要考虑的问题,不同垃圾回收器的处理方式和侧重点都不一样。咱们能做的就是认真对待项目,优化好数据结构和内存,不待将来。
