
数据表锁
前言
生活中用到的锁,用途都比较简单粗暴,上锁基本是为了防止外人进来、电动车被偷等等。
但生活中也不是没有 BUG 的,比如加锁的电动车在「广西 - 窃·格瓦拉」面前,锁就是形同虚设,只要他愿意,他就可以轻轻松松地把你电动车给「顺走」,不然打工怎么会是他这辈子不可能的事情呢?牛逼之人,必有牛逼之处。
那在编程世界里,「锁」更是五花八门,多种多样,每种锁的加锁开销以及应用场景也可能会不同。
如何用好锁,也是程序员的基本素养之一了。
高并发的场景下,如果选对了合适的锁,则会大大提高系统的性能,否则性能会降低。
所以,知道各种锁的开销,以及应用场景是很有必要的。
接下来,就谈一谈常见的这几种锁:
正文
多线程访问共享资源的时候,避免不了资源竞争而导致数据错乱的问题,所以我们通常为了解决这一问题,都会在访问共享资源之前加锁。
最常用的就是互斥锁,当然还有很多种不同的锁,比如自旋锁、读写锁、乐观锁等,不同种类的锁自然适用于不同的场景。
如果选择了错误的锁,那么在一些高并发的场景下,可能会降低系统的性能,这样用户体验就会非常差了。
所以,为了选择合适的锁,我们不仅需要清楚知道加锁的成本开销有多大,还需要分析业务场景中访问的共享资源的方式,再来还要考虑并发访问共享资源时的冲突概率。
对症下药,才能减少锁对高并发性能的影响。
那接下来,针对不同的应用场景,谈一谈「互斥锁、自旋锁、读写锁、乐观锁、悲观锁」的选择和使用。
互斥锁与自旋锁:谁更轻松自如?
最底层的两种就是会「互斥锁和自旋锁」,有很多高级的锁都是基于它们实现的,你可以认为它们是各种锁的地基,所以我们必须清楚它俩之间的区别和应用。
加锁的目的就是保证共享资源在任意时间里,只有一个线程访问,这样就可以避免多线程导致共享数据错乱的问题。
当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁对于加锁失败后的处理方式是不一样的:
-
互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
-
自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
互斥锁是一种「独占锁」,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为「睡眠」状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执行。如下图:
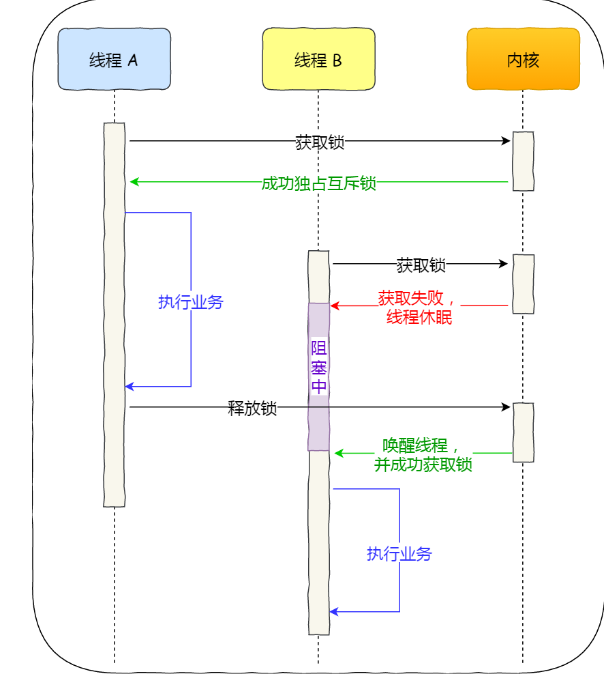
所以,互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮我们切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本。
那这个开销成本是什么呢?会有两次线程上下文切换的成本:
-
当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
-
接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
线程的上下文切换的是什么?当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下切换的耗时有大佬统计过,大概在几十纳秒到几微秒之间,如果你锁住的代码执行时间比较短,那可能上下文切换的时间都比你锁住的代码执行时间还要长。
所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
自旋锁是通过 CPU 提供的 CAS 函数(Compare And Swap),在「用户态」完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。
一般加锁的过程,包含两个步骤:
-
第一步,查看锁的状态,如果锁是空闲的,则执行第二步;
-
第二步,将锁设置为当前线程持有;
CAS 函数就把这两个步骤合并成一条硬件级指令,形成原子指令,这样就保证了这两个步骤是不可分割的,要么一次性执行完两个步骤,要么两个步骤都不执行。
使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这里的「忙等待」可以用 while 循环等待实现,不过最好是使用 CPU 提供的 PAUSE 指令来实现「忙等待」,因为可以减少循环等待时的耗电量。
自旋锁是最比较简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
自旋锁开销少,在多核系统下一般不会主动产生线程切换,适合异步、协程等在用户态切换请求的编程方式,但如果被锁住的代码执行时间过长,自旋的线程会长时间占用 CPU 资源,所以自旋的时间和被锁住的代码执行的时间是成「正比」的关系,我们需要清楚的知道这一点。
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。
它俩是锁的最基本处理方式,更高级的锁都会选择其中一个来实现,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。
读写锁:读和写还有优先级区分?
读写锁从字面意思我们也可以知道,它由「读锁」和「写锁」两部分构成,如果只读取共享资源用「读锁」加锁,如果要修改共享资源则用「写锁」加锁。
所以,读写锁适用于能明确区分读操作和写操作的场景。
读写锁的工作原理是:
-
当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为「读锁」是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
-
但是,一旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
所以说,写锁是独占锁,因为任何时刻只能有一个线程持有写锁,类似互斥锁和自旋锁,而读锁是共享锁,因为读锁可以被多个线程同时持有。
知道了读写锁的工作原理后,我们可以发现,读写锁在读多写少的场景,能发挥出优势。
另外,根据实现的不同,读写锁可以分为「读优先锁」和「写优先锁」。
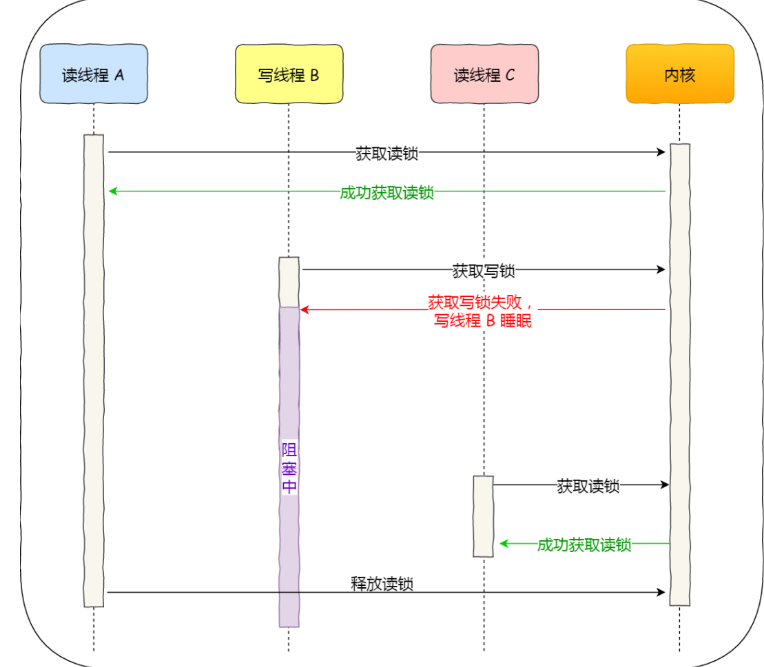
读优先锁期望的是,读锁能被更多的线程持有,以便提高读线程的并发性,它的工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取读锁。如下图:
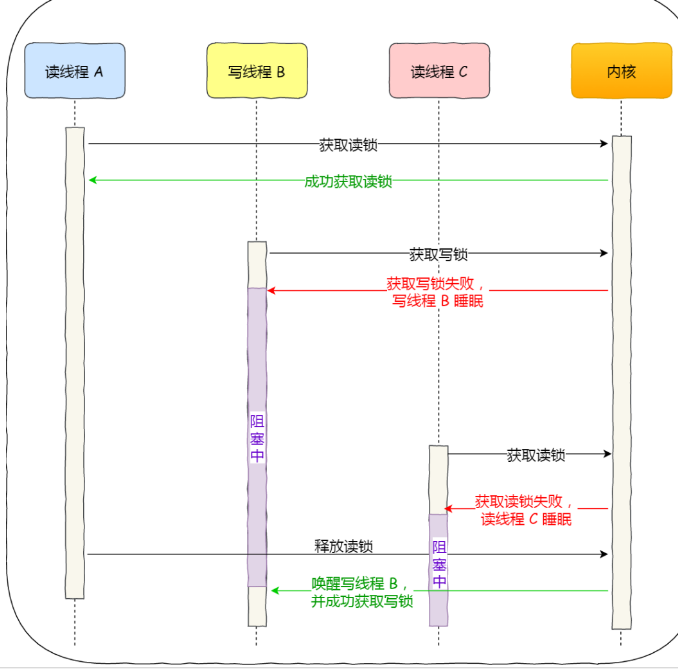
而写优先锁是优先服务写线程,其工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取读锁。如下图:
读优先锁对于读线程并发性更好,但也不是没有问题。我们试想一下,如果一直有读线程获取读锁,那么写线程将永远获取不到写锁,这就造成了写线程「饥饿」的现象。
写优先锁可以保证写线程不会饿死,但是如果一直有写线程获取写锁,读线程也会被「饿死」。
既然不管优先读锁还是写锁,对方可能会出现饿死问题,那么我们就不偏袒任何一方,搞个「公平读写锁」。
公平读写锁比较简单的一种方式是:用队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现「饥饿」的现象。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
乐观锁与悲观锁:做事的心态有何不同?
前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
放弃后如何重试,这跟业务场景息息相关,虽然重试的成本很高,但是冲突的概率足够低的话,还是可以接受的。
可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。
这里举一个场景例子:在线文档。
我们都知道在线文档可以同时多人编辑的,如果使用了悲观锁,那么只要有一个用户正在编辑文档,此时其他用户就无法打开相同的文档了,这用户体验当然不好了。
那实现多人同时编辑,实际上是用了乐观锁,它允许多个用户打开同一个文档进行编辑,编辑完提交之后才验证修改的内容是否有冲突。
怎么样才算发生冲突?这里举个例子,比如用户 A 先在浏览器编辑文档,之后用户 B 在浏览器也打开了相同的文档进行编辑,但是用户 B 比用户 A 提交改动,这一过程用户 A 是不知道的,当 A 提交修改完的内容时,那么 A 和 B 之间并行修改的地方就会发生冲突。
服务端要怎么验证是否冲突了呢?通常方案如下:
-
由于发生冲突的概率比较低,所以先让用户编辑文档,但是浏览器在下载文档时会记录下服务端返回的文档版本号;
-
当用户提交修改时,发给服务端的请求会带上原始文档版本号,服务器收到后将它与当前版本号进行比较,如果版本号一致则修改成功,否则提交失败。
实际上,我们常见的 SVN 和 Git 也是用了乐观锁的思想,先让用户编辑代码,然后提交的时候,通过版本号来判断是否产生了冲突,发生了冲突的地方,需要我们自己修改后,再重新提交。
乐观锁虽然去除了加锁解锁的操作,但是一旦发生冲突,重试的成本非常高,所以只有在冲突概率非常低,且加锁成本非常高的场景时,才考虑使用乐观锁。
总结
开发过程中,最常见的就是互斥锁的了,互斥锁加锁失败时,会用「线程切换」来应对,当加锁失败的线程再次加锁成功后的这一过程,会有两次线程上下文切换的成本,性能损耗比较大。
如果我们明确知道被锁住的代码的执行时间很短,那我们应该选择开销比较小的自旋锁,因为自旋锁加锁失败时,并不会主动产生线程切换,而是一直忙等待,直到获取到锁,那么如果被锁住的代码执行时间很短,那这个忙等待的时间相对应也很短。
如果能区分读操作和写操作的场景,那读写锁就更合适了,它允许多个读线程可以同时持有读锁,提高了读的并发性。根据偏袒读方还是写方,可以分为读优先锁和写优先锁,读优先锁并发性很强,但是写线程会被饿死,而写优先锁会优先服务写线程,读线程也可能会被饿死,那为了避免饥饿的问题,于是就有了公平读写锁,它是用队列把请求锁的线程排队,并保证先入先出的原则来对线程加锁,这样便保证了某种线程不会被饿死,通用性也更好点。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
另外,互斥锁、自旋锁、读写锁都属于悲观锁,悲观锁认为并发访问共享资源时,冲突概率可能非常高,所以在访问共享资源前,都需要先加锁。
相反的,如果并发访问共享资源时,冲突概率非常低的话,就可以使用乐观锁,它的工作方式是,在访问共享资源时,不用先加锁,修改完共享资源后,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
但是,一旦冲突概率上升,就不适合使用乐观锁了,因为它解决冲突的重试成本非常高。
不管使用的哪种锁,我们的加锁的代码范围应该尽可能的小,也就是加锁的粒度要小,这样执行速度会比较快。再来,使用上了合适的锁,就会快上加快了。
本文来自博客园,作者:南鱼羁荒渡,转载请注明原文链接:https://www.cnblogs.com/nanyu/p/17023664.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号