汇编语言的学习
寄存器
在DOSBox里面有ax,bx,cx,dx,sp,ip,ds,之类的,如下图

寄存器的种类
可以分为数据类和指令类
AX(AH、AL):累加器
BX(BH、BL):基址寄存器
CX(CH、CL):计数寄存器
DX(DH、DL):数据寄存器 //不过这些都可以修改,一般就数据和指令。
指令
指令的选择是通过cs:ip来选择的。
其中cs代表段地址,ip代表偏移地址
选择该地址内容的数据做为指令。例如:
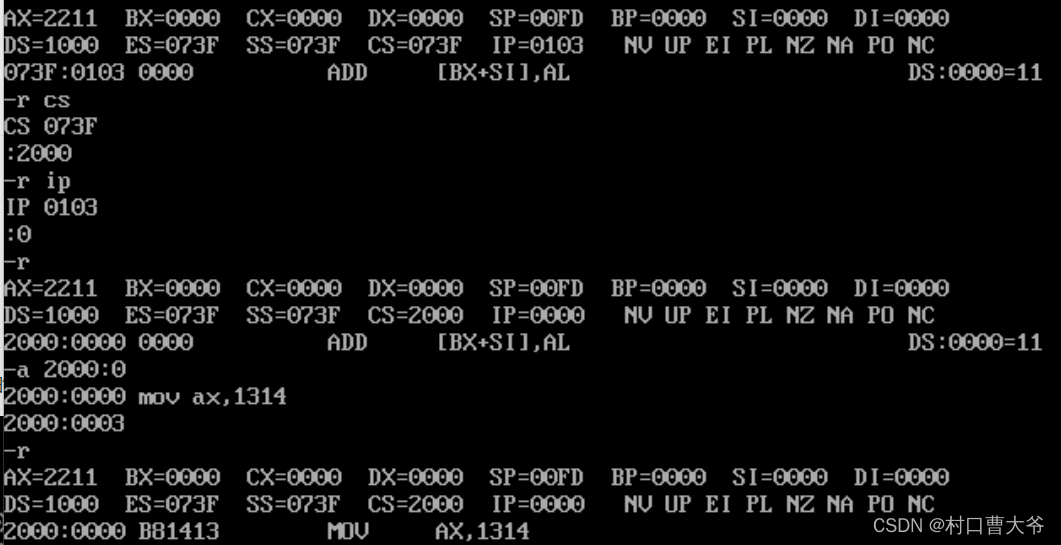
数据
数据的选择是通过ds:偏移量来确定的,例如:
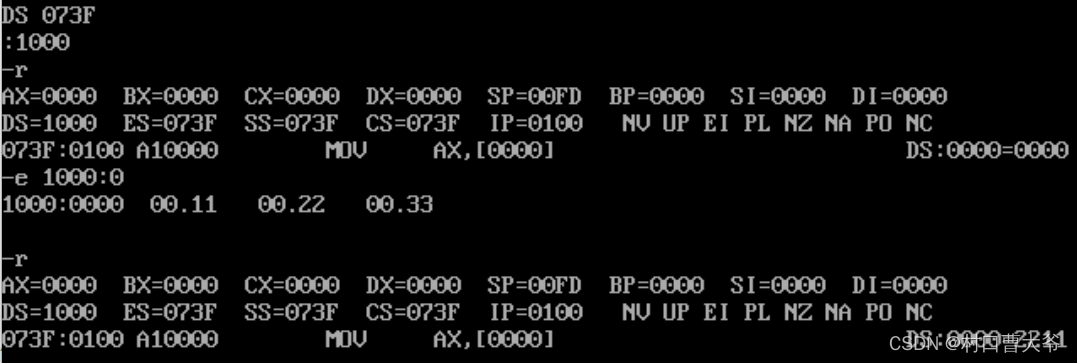 这里我修改了ds的值,让ds指向1000的地址,在将ax赋值1000:0000地址的值
这里我修改了ds的值,让ds指向1000的地址,在将ax赋值1000:0000地址的值

从这里就可以知道了,数据的选择是ds决定的。
段地址*10H +偏移地址=物理地址

这里可以看到,这两块的地址是一模一样的,类似于:2000+2000和4000的内容是一模一样的,地址含义也一样
我一般认为是绝对地址和相对地址。就比如说这个,1*10H+0=10H,所以绝对地址是0000:0010,而0001就是段地址,0001:0000就是相对地址,有什么问题可以发出来。
call指令
call指令的作用,就是跳转,但是和jmp的区别是会将下一条指令的ip存到栈中
后面使用ret指令回来(将ip修改回来)
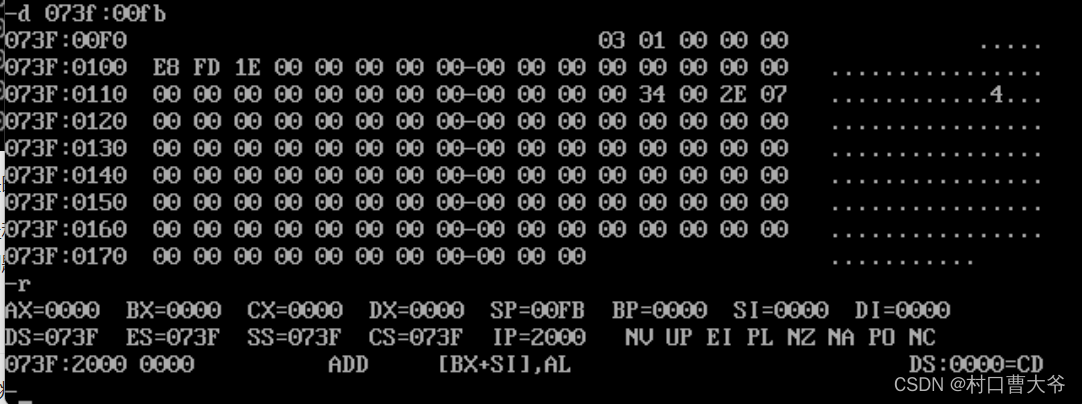
这里是运行了call指令,原先ip=100,后面栈中存放下一条指令也就是103。
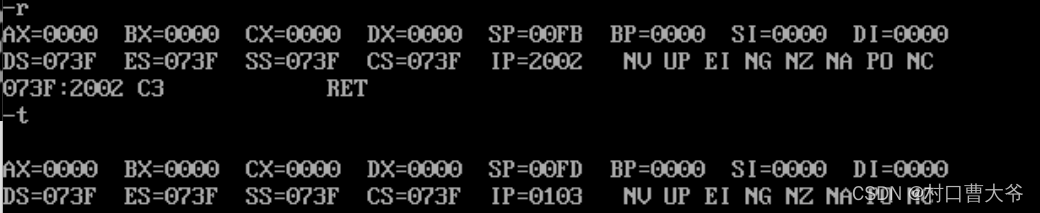
这里用了ret,将ip修改回来了(通过栈)
栈
汇编里面的栈是通过ss:sp来指向的,用这里面的内存来存储数据
栈是先进后出,每次加进来的都要在标记的前面。
在这里面的内存形式0000:0000------->ffff:ffff ,所以每次入栈(push)sp=sp-2,而每次出栈就是(pop)sp=sp+2
栈的最大内存是sp=0时,因为sp=0-2=fffh,所以sp=0时栈内存最大
栈的内存表示,sp的起始到sp被我修改的值,其实是人为的认为,最常见认为sp的起始为0,sp的终止是10h,所以栈内存为10H
具体格式:push ax //是将ax里面的值存入ss:sp内存中
pop bx //是将栈里面的内容存入到bx寄存器中
类似的。
psp区
开始的256个字节是psp区,其作用是为了程序与系统进行通信的
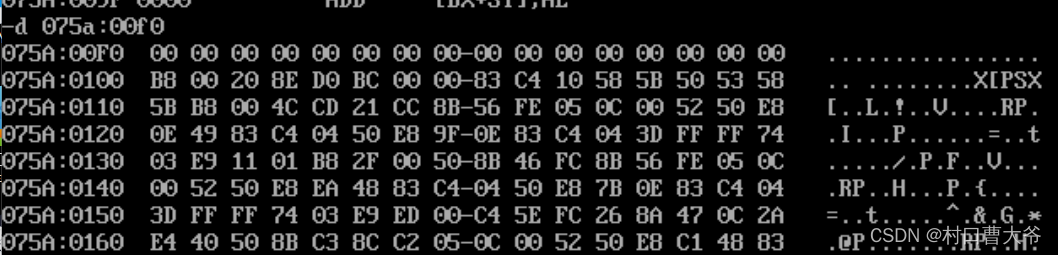
ds是取数据的,ds:0的数据并不是我写的程序的数据,一直到ds:0100才是,所以开始的256个字节是系统与程序进行通信的

一个标准的asm(汇编)文件格式
assume cs:code
code segment
mov ax,2000H ;在汇编语言中,;代表注释,mov代表赋值,add代表相加,pop出栈,push入栈,sub相减,jmp跳转,call
mov ss,ax ;,号右边给左边,这个,号类似于等号
mov sp,0 ;等等
add sp,10H
pop ax
pop bx
push ax
push bx ;交换ax,bx数据
pop ax
pop bx
;inc为增加的英文,inc bx,就是将bx加1,为了节约内存
mov ax,4C00H ;程序返回
int 21H
code ends
end
loop循环以及用jmp实现类型loop
loop比jmp多了一个次数操作,用cx来保存次数
jmp可以实现跳转
-p 可以直接执行完loop指令
-g 类似于go 后面要加地址

loop也可以实现,但是loop需要注意的是cx=1,和cx=0的情况
cx=0时,会出现溢出。
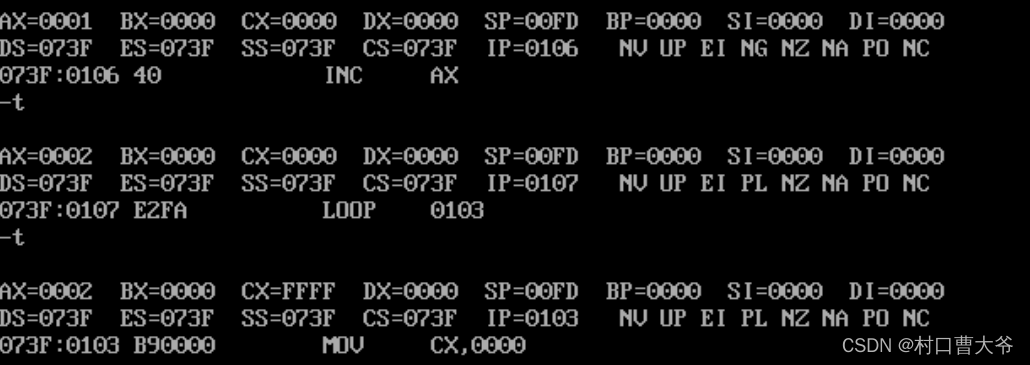
当cx=1时,可以看出并没有循环,原因是走了一遍就算循环了一次,当cx=0时跳出循环,如果还没有走cx已经为0了,cx-1=FFFF,就要循环FFFF次。

用汇编指令写234*145
assume cs:code
code segment
mov ax,0
mov cx,145
addnumber: add ax,234 ;jmp也是和loop一个格式,除开cx次数
loop addnumber
mov ax,4C00H
int 21H
code ends
end


debug的缺陷:有英文字母开头时,前面要加0
比如:mov ax,0ffffH
不加H时表示十进制。
通过es和ds数据寄存器来交换数据实操
assume cs:code
code segment
mov ax,0fffH
mov ds,ax
mov ax,2000H
mov es,ax
mov cx,10H
mov bx,0
adderten: mov al,ds:[bx]
mov es:[bx],al ;es:[bx]是一个字节数据类型,不是字型数据类型
inc bx
loop adderten
mov ax,4C00H
int 21H
code ends
end
通过栈来复制两个地方的数据
assume cs:code
code segment
mov bx,0
mov cx,10H
adderten: mov ax,0fffH
mov ds,ax
mov ax,0
mov al,ds:[bx]
push ax
mov ax,2000H
mov ds,ax
pop ds:[bx]
inc bx
loop adderten
mov ax,4C00H
int 21H
code ends
end
dw 操作数据
assume cs:code code segment dw 1,2,3,4,5,6,7,8,9 start: mov ax,0 mov bx,0 addax: add ax,cs:[bx] ;start 指定操作开始的位置 add bx,2 ;不用start在开头用jmp指令也行 loop addax mov ax,4C00H int 21H code ends end start

dw和栈联用
assume cs:code code segment dw 1122H,2233H,3344H,4455H,5566H,6677H,7788H,8899H,9900H dw 0,0,0,0,0,0,0,0 dw 0,0,0,0,0,0,0,0 start: mov ax,cs mov ss,ax mov sp,32H ;栈内存是看字节形数据,所以应该是32H mov bx,0 mov cx,9 addax: push cs:[bx] add bx,2 loop addax mov ax,4C00H int 21H code ends end start
数据段,指令段,stack段
这样写可能会出一个bug,就是设置sp的大小就一定要和栈段一致,不然就会执行不知道什么的指令,那个时候就是严重型bug
assume cs:code,ds:data,ss:stack data segment dw 1122H,2233H,3344H,4455H,5566H,6677H,7788H,8899H,9900H data ends stack segment dw 0,0,0,0,0,0,0,0 dw 0,0,0,0,0,0,0,0 stack ends code segment start: mov ax,stack mov ss,ax ;设置栈 mov sp,32 ;如果这样写了,设置栈的大小就一定要和栈段里面的要一致 mov ax,data mov ds,ax ;设置数据段 mov bx,0 ;这样做就会将ds寄存器当作数据,ss:sp数据当作栈。 mov cx,9 addax: push data:[bx] add bx,2 loop addax mov ax,4C00H int 21H code ends end start
段的位置
第一段一般是数据,第二段一般是栈,第三段则是指令
第一和第二段可以换位置,但是第三段不能换,涉及到数据覆盖问题
数据段位置:

栈段位置:

指令段:

段的空间大小

就是16的倍数,如果比如9个字节长度,大小就是16个字节,如果说是23个字节长度,大小就是32个字节。
向大号取整。
比如说这个例子:就是数据是9个字型性长度,所以用了32个字节型长度。
段的练习1:将两个数据段的数据相加,放到另外一个段中
assume cs:code a segment db 1,2,3,4,5,6,7,8 a ends b segment db 1,2,3,4,5,6,7,8 ;因为数据段寄存器不够了,所以先用栈保存一下位置,然后直接修改es寄存器将es寄存器改成c段那边,然 ;后赋值,后面pop掉es,就行了 b ends c segment db 0,0,0,0,0,0,0,0 c ends code segment start: mov ax,a mov ds,ax mov cx,8 mov ax,b mov es,ax mov bx,0 mov ax,0 addax: push es mov ax,ds:[bx] add ax,es:[bx] mov dx,c mov es,dx mov es:[bx],ax inc bx pop es loop addax mov ax,4C00H int 21H code ends end start
段的练习2:将a段中的前8个字型数据,逆序复制到b段中
assume cs:code a segment dW 1,2,3,4,5,6,7,8,0AH,0BH,0CH,0DH,0FH,0FFH a ends b segment dW 0,0,0,0,0,0,0,0 b ends code segment start: mov ax,b mov ss,ax mov sp,16 mov ax,a mov ds,ax mov bx,0 mov cx,8 adder: push ds:[bx] add bx,2 loop adder mov ax,4C00H int 21H code ends end start
bx,si,di都为偏移地址寄存器
assume cs:code a segment dW 1,2,3,4,5,6,7,8,0AH,0BH,0CH,0DH,0FH,0FFH a ends b segment dW 0,0,0,0,0,0,0,0 b ends code segment start: mov ax,a mov ds,ax mov si,1 mov di,2 mov bx,0 mov ax,ds:[bx+si] ;唯一的缺点就是不能用减法 add ax,ds:[di] code ends end start
and,or运算符
assume cs:code a segment dW 1,2,3,4,5,6,7,8,0AH,0BH,0CH,0DH,0FH,0FFH a ends b segment dW 0,0,0,0,0,0,0,0 b ends code segment start: mov ax,00001111B and ax,11110000B code ends end start
assume cs:code a segment dW 1,2,3,4,5,6,7,8,0AH,0BH,0CH,0DH,0FH,0FFH a ends b segment dW 0,0,0,0,0,0,0,0 b ends code segment start: mov ax,00001111B or ax,11110000B mov ax,'a' mov bx,'b' code ends end start
字符


同个字母的大写字母比小写字母要小32
将数据段nihao中的i变成大写I
assume cs:code a segment db 'nihao,I am you ' a ends b segment dW 0,0,0,0,0,0,0,0 b ends code segment start: mov ax,a mov ds,ax mov bx,1 mov al,ds:[bx] and al,11011111B ;注意不能在数据段进行and or操作 mov ds:[bx],al mov ax,4C00H int 21H code ends end start

将数据段中的所有数据变成大写
assume cs:code a segment db 'nihao,I am you ' a ends b segment dW 0,0,0,0,0,0,0,0 b ends code segment start: mov ax,a mov ds,ax mov bx,0 mov cx,14 adder: mov al,ds:[bx] and al,11011111B mov ds:[bx],al inc bx loop adder mov ax,4C00H int 21H code ends end start
使用si和di偏移地址寄存器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号