

机器学习——住房价格预测
一、选题背景
房价问题事关国计民生,已经成为全民关注的焦点议题之一。房地产更是我国最大的产业之一,对每个人对至关重要。本文主要对房价的合理性进行分析,根据测试集中各个房屋特征对销售价格的影响。并对此进行分析。估测了房价未来走势。同时进一步探讨使得房价合理的具体措施,根据分析结果,定量分析可能对经济发展产生的影响。
二、设计方案
本次机器学习设计具体方案,通过网上收集数据集,对数据集进行数据探索分析。然后对数据进行适当的数据清洗:异常值处理和缺失值处理。
1. 对数据做数据探索分析
2. 适当的数据清洗(异常值处理和缺失值处理)
3. 适当的特征工程
4. 用线性回归模型对房价进行预测
本次涉及的技术难点,本次作业用到线性回归模型(最小二乘、岭回归、Lasso)对房价进行预测,需要自己补充一下这方面的知识。#网上下载的测试集没有saleprice,只有将训练集ames_train分割成训练和测试集,随机采样20%的数据构建测试样本,其余作为训练样本。数据分析过程中对部分特征的分析不理解。解决方案是对看看别人的按理,学习一下其他人对数据的分析。
数据集来源:kaggle:https://www.kaggle.com/competitions/plant-pathology-2021-fgvc8/data
kaggle:https://www.kaggle.com/competitions/plant-pathology-2020-fgvc7/data
参考案例:kaggle讨论区,csdn的kaggle房价预测项目https://blog.csdn.net/ttt123456uuu/article/details/119383848
三、实现步骤
获取数据集

(1)导入数据与工具包

1 import numpy as np # 矩阵操作 2 import pandas as pd # SQL数据处理 3 from sklearn.metrics import r2_score #评价回归预测模型的性能 4 import matplotlib.pyplot as plt #画图 5 import seaborn as sns 6 #忽略警告 7 import warnings 8 warnings.filterwarnings('ignore') 9 %matplotlib inline 10 #获取训练数据集 11 dpath = './data/' 12 ames_train = pd.read_csv(dpath+"Ames_House_train.csv") 13 #获取测试数据集 14 ames_test = pd.read_csv(dpath+"Ames_House_test.csv") 15 #观察训练集数据 16 ames_train.head()

训练集总共有81个特征
1 #观察测试集数据 2 ames_test.head()

80个特征,没有SalePrice,估计是要预测的集。最后可能只有从训练集抽一部分作为测试集
1 ames_train.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1460 entries, 0 to 1459 Data columns (total 81 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 1460 non-null int64 1 MSSubClass 1460 non-null int64 2 MSZoning 1460 non-null object 3 LotFrontage 1201 non-null float64 4 LotArea 1460 non-null int64 5 Street 1460 non-null object 6 Alley 91 non-null object 7 LotShape 1460 non-null object 8 LandContour 1460 non-null object 9 Utilities 1460 non-null object 10 LotConfig 1460 non-null object 11 LandSlope 1460 non-null object 12 Neighborhood 1460 non-null object 13 Condition1 1460 non-null object 14 Condition2 1460 non-null object 15 BldgType 1460 non-null object 16 HouseStyle 1460 non-null object 17 OverallQual 1460 non-null int64 18 OverallCond 1460 non-null int64 19 YearBuilt 1460 non-null int64 20 YearRemodAdd 1460 non-null int64 21 RoofStyle 1460 non-null object 22 RoofMatl 1460 non-null object 23 Exterior1st 1460 non-null object 24 Exterior2nd 1460 non-null object 25 MasVnrType 1452 non-null object 26 MasVnrArea 1452 non-null float64 27 ExterQual 1460 non-null object 28 ExterCond 1460 non-null object 29 Foundation 1460 non-null object 30 BsmtQual 1423 non-null object 31 BsmtCond 1423 non-null object 32 BsmtExposure 1422 non-null object 33 BsmtFinType1 1423 non-null object 34 BsmtFinSF1 1460 non-null int64 35 BsmtFinType2 1422 non-null object 36 BsmtFinSF2 1460 non-null int64 37 BsmtUnfSF 1460 non-null int64 38 TotalBsmtSF 1460 non-null int64 39 Heating 1460 non-null object 40 HeatingQC 1460 non-null object 41 CentralAir 1460 non-null object 42 Electrical 1459 non-null object 43 1stFlrSF 1460 non-null int64 44 2ndFlrSF 1460 non-null int64 45 LowQualFinSF 1460 non-null int64 46 GrLivArea 1460 non-null int64 47 BsmtFullBath 1460 non-null int64 48 BsmtHalfBath 1460 non-null int64 49 FullBath 1460 non-null int64 50 HalfBath 1460 non-null int64 51 BedroomAbvGr 1460 non-null int64 52 KitchenAbvGr 1460 non-null int64 53 KitchenQual 1460 non-null object 54 TotRmsAbvGrd 1460 non-null int64 55 Functional 1460 non-null object 56 Fireplaces 1460 non-null int64 57 FireplaceQu 770 non-null object 58 GarageType 1379 non-null object 59 GarageYrBlt 1379 non-null float64 60 GarageFinish 1379 non-null object 61 GarageCars 1460 non-null int64 62 GarageArea 1460 non-null int64 63 GarageQual 1379 non-null object 64 GarageCond 1379 non-null object 65 PavedDrive 1460 non-null object 66 WoodDeckSF 1460 non-null int64 67 OpenPorchSF 1460 non-null int64 68 EnclosedPorch 1460 non-null int64 69 3SsnPorch 1460 non-null int64 70 ScreenPorch 1460 non-null int64 71 PoolArea 1460 non-null int64 72 PoolQC 7 non-null object 73 Fence 281 non-null object 74 MiscFeature 54 non-null object 75 MiscVal 1460 non-null int64 76 MoSold 1460 non-null int64 77 YrSold 1460 non-null int64 78 SaleType 1460 non-null object 79 SaleCondition 1460 non-null object 80 SalePrice 1460 non-null int64 dtypes: float64(3), int64(35), object(43) memory usage: 924.0+ KB
object(43)型比较多,就是数据特征类别数据占了大多数吧
(2)数据探索
1 #分析SalePrice的情况 2 ames_train['SalePrice'].describe()

1460个样本,最大值似乎有点高
1 #样本的SalePrice作正态分布曲线 2 sns.distplot(ames_train['SalePrice'])

总体来看还算正常,集中分布在100000到250000这个区间,但是一直往右边延伸,说明最好的房子的价格是非常高的
1 #看看偏度(skewness)和峰度(peakedness) 2 print("Skewness: %f" % ames_train['SalePrice'].skew()) 3 print("Kurtosis: %f" % ames_train['SalePrice'].kurt())

(1)偏度:正态分布的偏度为0,两侧尾部长度对称。若以bs表示偏度。bs小于0称分布具有负偏离,也称左偏态,bs大于0称 分布具有正偏离,也称右偏态。
(2)峰度: 峰度为0表示该总体数据分布与正态分布的陡缓程度相同;峰度大于0表示该总体数据分布与正态分布相比较为陡 峭,为尖顶峰;峰度小于0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。
因为小尾巴的存在,所以右偏,峰值也比较陡峭,saleprice比较集中
找几个感兴趣的特征来和SalePrice做散点图,首先看看数值型的特征:
1 #作散点图 2 #LotArea:土地的大小 3 var = 'LotArea' 4 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 5 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

这里的土地应该是包括花园、操场空地的,大部分都比较小,估计是城区里的房子,LotArea比较大的可能是大农村,房价 高的房子一般土地都不小~
1 #作散点图 2 #GrLivArea:地上居住面积 3 var = 'GrLivArea' 4 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 5 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

地上居住面积和价格,除了右下几个点以外,似乎呈线性分布,右下角的两个房子估计也是在农村,居住面积大,但是不值钱。
分析地下室面积:
1 #作散点图 2 #TotalBsmtSF:地下室总面积 3 var = 'TotalBsmtSF' 4 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 5 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

除了极个别农村的房子,大部分还是呈线性分布,地下室越大价格越高,也注意到有些房子没有地下室。
分析类别型特征:
首先看看市区内的物理位置:
1 #Neighborhood:市内物理位置 2 var = 'Neighborhood' 3 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 4 f, ax = plt.subplots(figsize=(20, 8)) 5 fig = sns.boxplot(x=var, y="SalePrice", data=data) 6 fig.axis(ymin=0, ymax=800000);

看不出来什么明显趋势,大概只知道NoRideg、NridgHt和StoneBr这三地的房子要稍微贵一点吧 再来看看总体条件评级
1 #OverallQual:整体材质和完成品质 2 var = 'OverallQual' 3 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 4 f, ax = plt.subplots(figsize=(16, 8)) 5 fig = sns.boxplot(x=var, y="SalePrice", data=data) 6 fig.axis(ymin=0, ymax=800000);

既然是完成品质,肯定等级高的就越贵,所以这个趋势还是正常的
1 #OverallCond:总体条件评级 2 var = 'OverallCond' 3 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 4 f, ax = plt.subplots(figsize=(16, 8)) 5 fig = sns.boxplot(x=var, y="SalePrice", data=data) 6 fig.axis(ymin=0, ymax=800000);

总体评价等级,也基本能看出等级高价格贵,但是奇怪的是大部分价格高的房子集中再等级5。
1 #YearBuilt:最初建造日期 2 var = 'YearBuilt' 3 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 4 f, ax = plt.subplots(figsize=(20, 8)) 5 fig = sns.boxplot(x=var, y="SalePrice", data=data) 6 fig.axis(ymin=0, ymax=800000); 7 plt.xticks(rotation=90);

从建造日期来看,价格还算均匀分布,最老的房子和最新的房子价格较。 接下来构建一个相关性矩阵:
1 #correlation matrix热图,corr()计算相关性 2 corrmat = ames_train.corr() 3 f, ax = plt.subplots(figsize=(20, 12)) 4 #vmax 能显示的最大值 vmin能显示的最小值 5 sns.heatmap(corrmat, vmax=0.9, square=True);

通过热图,发现两组相关性比较高的属性
(1)地下室总面积(TotalBsmtSF)和第一层面积(1stFlrSF),难道国外第一层指的是地下室
(2)车库停放数量(GarageCars)和车库大小(GarageArea),车库大停车多,这个好理解。
选择10个与SalePrice最相关的属性作heatmap分析
1 k = 10 #相关属性数量 2 cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index 3 cm = np.corrcoef(ames_train[cols].values.T) 4 sns.set(font_scale=1.25) 5 hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, 6 yticklabels=cols.values, xticklabels=cols.values) 7 plt.show()

首先,GarageCars和GarageArea相关性达到了0.88,嗯车库越大停车越多,因此咱们去掉一个属性。考虑到GarageArea 和SalePrice的相关性比GarageCars和SalePrice的相关性低,那就把这个属性去掉吧。
GrLiveArea(地上居住面积)和TotRmsAbvGrd(地上房间总数)相关性也有0.83,房间多,居住面积就大,所以去掉 TotRmsAbvGrd。
TotalBsmtSF和1stFloor相关性0.82,同理去掉1stFloor
1 #去掉GarageArea(车库大小)、TotRmsAbvGrd(地上房间总数)、1stFlrSF(第一层面积) 2 ames_train = ames_train.drop('GarageArea', axis = 1) 3 ames_train = ames_train.drop('TotRmsAbvGrd', axis = 1) 4 ames_train = ames_train.drop('1stFlrSF', axis = 1) 5 ames_train.shape
(1460, 78)
降了三个维度
(3)数据缺失值处理
1 #数据缺失值处理 2 #首先看看哪些特征缺失的最多 3 total = ames_train.isnull().sum().sort_values(ascending=False) 4 percent = (ames_train.isnull().sum()/ames_train.isnull().count()).sort_values(ascending=False) 5 missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) 6 missing_data.head(20)

来看看哪些特征缺失的比较多,首先是5个缺失最多特征:PoolQC、MiscFeature、Alley、Fence、FireplaceQu(有个百 分之80原则,若缺失80以上,就去掉该特征,但是这里缺失百分之50的也去掉了)
分别对应:游泳池质量、没被包含在其他类别的杂项功能 、所在巷通道的类型 、 围栏质量 、壁炉质量。
我想除了游泳池质量,很少有人会在乎后面四个特征吧,估计这也是信息缺失的原因。对于游泳池来讲,估计大多数房子都 没有游泳池,所以更不会有游泳池质量了,索性就先确定把这5个特征去掉吧。
1 #去掉PoolQC 2 ames_train = ames_train.drop(['PoolQC','MiscFeature','Alley','Fence','FireplaceQu'], axis = 1)
又去掉了5个特征。再来看看MasVnrArea(表明砌体面积)、MasVnrType(表明砌体类型)、Electrical(电气系统),注 意到这三个特征缺失值并不多,只有1个或者8个,所以直接把这几个含有缺失值的样本去掉。
1 #去掉Electrical有缺失值的样本 2 ames_train = ames_train.drop(ames_train.loc[ames_train['Electrical'].isnull()].index) 3 #去掉MasVnrArea有缺失值的样本 4 ames_train = ames_train.drop(ames_train.loc[ames_train['MasVnrArea'].isnull()].index) 5 #去掉MMasVnrType有缺失值的样本 6 ames_train = ames_train.drop(ames_train.loc[ames_train['MasVnrType'].isnull()].index) 7 ames_train.shape 8 (1451, 73)
经过以上处理以后,就只剩下缺失37个值到259个值的属性。
(1)如果直接删除这些属性,可能会造成大量有用的信息被浪费。
(2)如果删除包含缺失值的样本,就会导致样本数量下降259个,占了总样本的七分之一,更会丢失大量信息。
所以,综上所述,将剩余有缺失值的样本进行插值:
(1)对于数值型特征,考虑到平均数可能会被离群点拉高或者拉低,因此选择中位数来进行插值。
(2)对于类别型特征,直接将出现最多的类别填充到缺失值中另外,查资料还发现利用已有样本数据作回归,再将缺失值利用回归模型进行填充,在此就暂不作这样处理
1 #strategy : ①若为mean时,用特征列的均值替换 ②若为median时,用特征列的中位数替换 ③若为most_frequent时,用特征 2 列的众数替换 3 #from sklearn.preprocessing import Imputer 4 #imputer=Imputer(missing_values='NaN', strategy='median', axis=0, verbose=0, copy=True) 5 #ames_train =imputer.fit_transform(ames_train) 6 #处理数值型特征,缺失值用中位数填补 7 ames_train=ames_train.fillna(ames_train.median()) 8 #处理类别型特征,缺失值用该类别众数填补 9 #GarageType属性 10 ames_train['GarageType']=ames_train['GarageType'].fillna(ames_train['GarageType'].describe().top) 11 #GarageCond属性 12 ames_train['GarageCond']=ames_train['GarageCond'].fillna(ames_train['GarageCond'].describe().top) 13 #GarageFinish属性 14 ames_train['GarageFinish']=ames_train['GarageFinish'].fillna(ames_train['GarageFinish'].describe().t 15 op) 16 #GarageQual属性 17 ames_train['GarageQual']=ames_train['GarageQual'].fillna(ames_train['GarageQual'].describe().top) 18 #BsmtExposure属性 19 ames_train['BsmtExposure']=ames_train['BsmtExposure'].fillna(ames_train['BsmtExposure'].describe().t 20 op) 21 #BsmtFinType2属性 22 ames_train['BsmtFinType2']=ames_train['BsmtFinType2'].fillna(ames_train['BsmtFinType2'].describe().t 23 op) 24 #BsmtFinType1属性 25 ames_train['BsmtFinType1']=ames_train['BsmtFinType1'].fillna(ames_train['BsmtFinType1'].describe().t 26 op) 27 #BsmtCond属性 28 ames_train['BsmtCond']=ames_train['BsmtCond'].fillna(ames_train['BsmtCond'].describe().top) 29 #BsmtQual属性 30 ames_train['BsmtQual']=ames_train['BsmtQual'].fillna(ames_train['BsmtQual'].describe().top) 31 ames_train.shape 32 (1451, 73) 33 #观察下是否还有存在缺失值的特征 34 ames_train.isnull().sum().max() 35 0
显示为0,已经不存在缺失值了
ok,到这里缺失值就全部处理完了,接下来将类别标签进行编码
引入sklearn下的LabelEncoder包,用于对标签进行编码,编写一个类,用于对一个dataframe下的所有类别标签编码
1 from sklearn.pipeline import Pipeline 2 from sklearn.preprocessing import LabelEncoder 3 #定义一个类,可以将类别标签进行编码,e.g 假设四个标签,分别标为【1,2,3,4】 4 class MultiColumnLabelEncoder: 5 def __init__(self,columns = None): 6 self.columns = columns # array of column names to encode 7 8 def fit(self,X,y=None): 9 return self # not relevant here 10 11 def transform(self,X): 12 output = X.copy() 13 if self.columns is not None: 14 for col in self.columns: 15 output[col] = LabelEncoder().fit_transform(output[col]) 16 else: 17 for colname,col in output.iteritems(): 18 output[colname] = LabelEncoder().fit_transform(col) 19 return output 20 21 def fit_transform(self,X,y=None): 22 return self.fit(X,y).transform(X) 23 24 #获取列类型为object的列,获取类别列 25 object_columns=[] 26 for col in ames_train.columns: 27 if ames_train[col].dtypes=='object': 28 object_columns.append(col) 29 30 #将类别特征string转化为数值型(0,1,2,3,4......) 31 ames_train=MultiColumnLabelEncoder(columns = object_columns).fit_transform(ames_train)
观察是否类别特征都已经转化成为数值
1 ames_train.head(20)

(4)离群值处理
离群值(outlier),也称逸出值,是指在数据中有一个或几个数值与其他数值相比差异较大。chanwennt准则规定,如果一个 数值偏离观测平均值的概率小于等于1/(2n),则该数据应当舍弃(其中n为观察例数,概率可以很据数据的分布进行估计)。
----- ----摘自百度
首先来看看地面居住面积和房价的散点图,看是否存在离群
1 #地上居住面积 2 var = 'GrLivArea' 3 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 4 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

可以看出数据主体依然呈线性关系,但是右下角的两个点比较碍眼,正如前面分析过的,可能是农村的房屋,所以面积大却 不值钱,由于偏离了主体,对线性回归模型会造成影响,所以就去掉右下角的两个样本。
右上方的两个点,看似离主群很远,但是实际上也在主群的方向上,所以不作处理
1 ames_train[(ames_train.GrLivArea>4500)]

1 #找到这两个离群点,删除他们 2 ames_train = ames_train.drop(ames_train[ames_train['Id'] == 1299].index) 3 ames_train = ames_train.drop(ames_train[ames_train['Id'] == 524].index) 4 ames_train.shape 5 (1449, 73) 6 #地下室总面积 7 var = 'TotalBsmtSF' 8 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 9 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

右边的几个点虽然离主群较远,但总体来看依然呈线性分布的,所以也不作处理。
1 #低质量完成的面积 2 var = 'LowQualFinSF' 3 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 4 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

可以看出大部分房屋,低质量完成的面积都是0。而最右边那个点,低质量完成面积那么大,反而价格还很高,我们把他提 取出来单独分析。
1 ames_train[(ames_train.LowQualFinSF>550)]

1 #取出该样本的总面积 2 lowQuaHouse=ames_train[ames_train.Id==186] 3 lowQuaHouse[['GrLivArea','TotalBsmtSF']]

得出结论:低质量面积大概占总面积的8分之1,估计是大房子有部分没有装修完成,所以价格是合理的,这里就暂时不作处 理。
数据能符合统计学假设,作以下分析:
(1)正态性。(服从正态分布)
(2)方差齐性。(使独立变量在误差项相同)
(3)线性。
(4)无相关性错误。(特征之间正相关的误差造成负相关的误差)
首先是正态性
1 #histogram and normal probability plot 2 from scipy.stats import norm 3 from scipy import stats 4 sns.distplot(ames_train['SalePrice'], fit=norm); 5 fig = plt.figure() 6 res = stats.probplot(ames_train['SalePrice'], plot=plt)
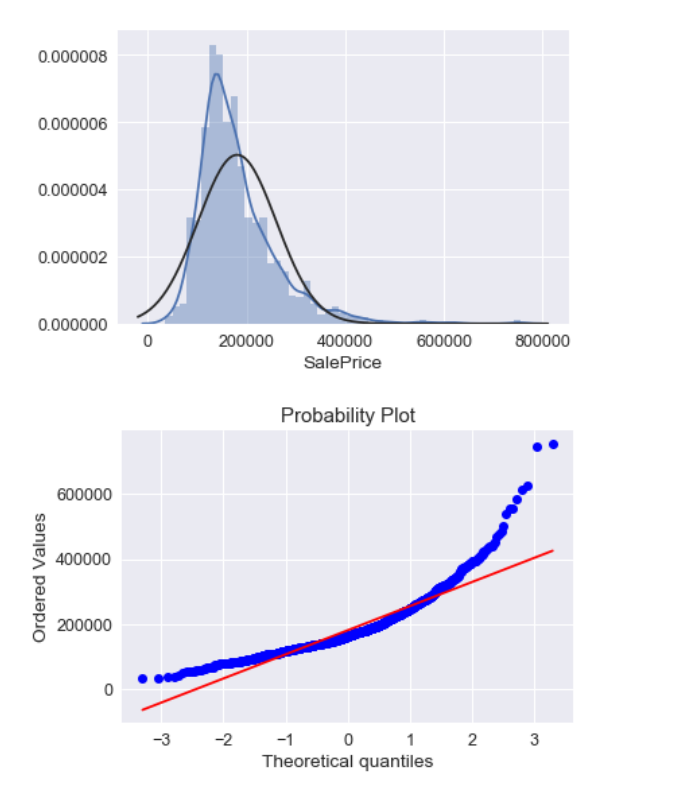
SalePrice的分布不是标准正态型的,它呈现出来了峰度比较陡。
偏度也没有和对角线一致(不太明白这里的对角线是什么意思)
1 #使用log变换 2 ames_train['SalePrice'] = np.log(ames_train['SalePrice']) 3 sns.distplot(ames_train['SalePrice'], fit=norm); 4 fig = plt.figure() 5 res = stats.probplot(ames_train['SalePrice'], plot=plt)

经过变换以后,峰度和偏度的问题都得到较好的修正。
接下来是GrLivArea(地上面积)特征:
1 sns.distplot(ames_train['GrLivArea'], fit=norm); 2 fig = plt.figure() 3 res = stats.probplot(ames_train['GrLivArea'], plot=plt)

峰度比较符合正态分布,但是偏度稍微有点右偏。
1 #使用log变换 2 ames_train['GrLivArea'] = np.log(ames_train['GrLivArea']) 3 sns.distplot(ames_train['GrLivArea'], fit=norm); 4 fig = plt.figure() 5 res = stats.probplot(ames_train['GrLivArea'], plot=plt)
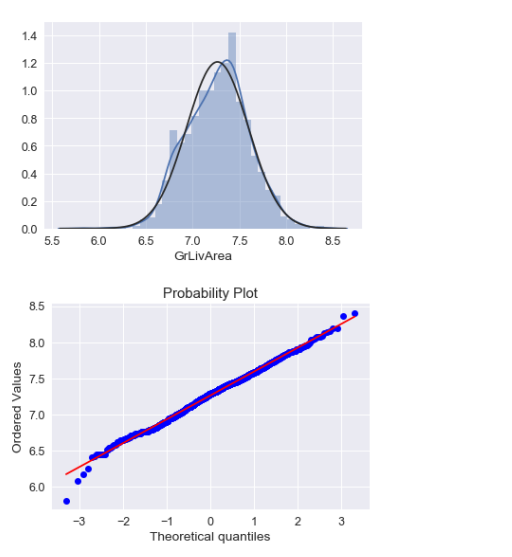
log变换以后效果还不错。
1 #TotalBsmtSF正态分布特征 2 sns.distplot(ames_train['TotalBsmtSF'], fit=norm); 3 fig = plt.figure() 4 res = stats.probplot(ames_train['TotalBsmtSF'], plot=plt)
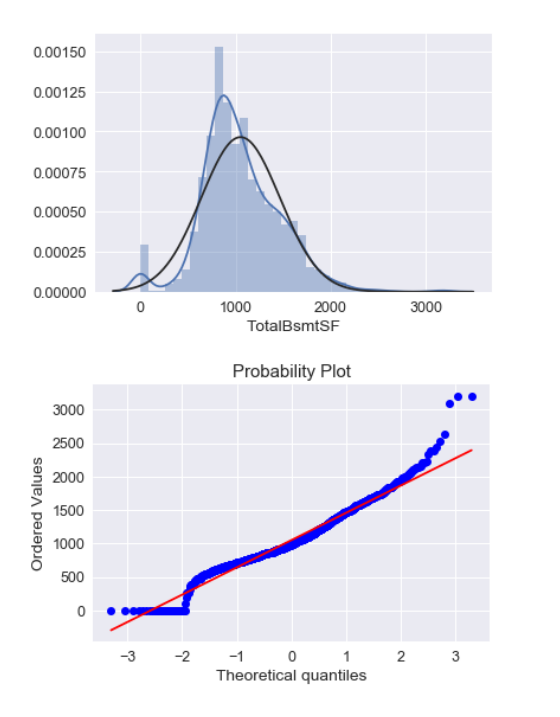
问题出现了,有一些样本没有地下室,所以在TotalBsmtSF(地下室面积)这一项为0,为0那就不能使用log对数了啊 所以在这里对于地下室为0的样本就不作log处理,让它依然保持为0
1 #重新定义一项BsmtFlag,为0表示没有地下室,为1表示有地下室 2 ames_train['BsmtFlag'] = pd.Series(len(ames_train['TotalBsmtSF']), index=ames_train.index) 3 ames_train['BsmtFlag'] = 0 4 ames_train.loc[ames_train['TotalBsmtSF']>0,'BsmtFlag'] = 1 5 #log变换 6 ames_train.loc[ames_train['BsmtFlag']==1,'TotalBsmtSF'] = np.log(ames_train['TotalBsmtSF']) 7 #只列出了有地下室情况的正态分布特征 8 sns.distplot(ames_train[ames_train['TotalBsmtSF']>0]['TotalBsmtSF'], fit=norm); 9 fig = plt.figure() 10 res = stats.probplot(ames_train[ames_train['TotalBsmtSF']>0]['TotalBsmtSF'], plot=plt)

转换后都样本的正态性都体现出来了 但是为什么在对角线上,总有一些点在首尾部分都偏移对角线很远呢?
1 #把新增的BsmtFlag列去掉 2 ames_train=ames_train.drop('BsmtFlag', axis = 1) 3 ames_train.shape 4 (1449, 73)
方差齐性探索
解决了正态性问题,再来看看方差齐性
1 plt.scatter(ames_train['GrLivArea'], ames_train['SalePrice']);

1 plt.scatter(ames_train[ames_train['TotalBsmtSF']>0]['TotalBsmtSF'], 2 ames_train[ames_train['TotalBsmtSF']>0]['SalePrice']);

在作log转换处理前,样本分布呈圆锥型(可以查看前面特征与SalePrice的关系散点图),在低值处收于一小区域,在高值 处具有发散的特点。作log转换处理后,高值处的离散程度得到降低,两个样本的均值偏离程度变小,使其分布更集中,更符合 线性分布。
总结一下:
(1)log变换可以使数据分布更靠近正态分布模型;
(2)log变化可以使数据分布呈现方差齐性
(5)特征工程
1 #网上下载的测试集没有saleprice,只有将训练集ames_train分割成训练和测试集。。。。 2 #另外当数据较少时,可以考虑使用交叉验证,来扩充数据大小 3 # 从原始数据中分离输入特征x和输出y 4 y = ames_train['SalePrice'].values 5 #还要去掉编号ID 6 X = ames_train.drop(['SalePrice','Id'], axis = 1) 7 #将数据分割训练数据与测试数据 8 from sklearn.model_selection import train_test_split 9 # 随机采样20%的数据构建测试样本,其余作为训练样本 10 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33, test_size=0.2)
查阅了一下标准化和归一化的区别:
(1)归一化特点 对不同特征维度的伸缩变换的目的是使各个特征维度对目标函数的影响权重是一致的,即使得那些扁平分布的数据伸缩变换 成类圆形。这也就改变了原始数据的一个分布。
好处: 1 提高迭代求解的收敛速度 2 提高迭代求解的精度
(2)标准化特点 对不同特征维度的伸缩变换的目的是使得不同度量之间的特征具有可比性。同时不改变原始数据的分布。
好处:
1 使得不同度量之间的特征具有可比性,对目标函数的影响体现在几何分布上,而不是数值上
2 不改变原始数据的分布
归一化会改变原始数据分布,似乎有些不妥。所以使用标准化吧
1 # 数据标准化 2 from sklearn.preprocessing import StandardScaler 3 # 分别初始化对特征和目标值的标准化器 4 ss_X = StandardScaler() 5 ss_y = StandardScaler() 6 # 分别对训练和测试数据的特征以及目标值进行标准化处理 7 X_train = ss_X.fit_transform(X_train) 8 X_test = ss_X.transform(X_test) 9 #对y做标准化不是必须 10 #对y标准化的好处是不同问题的w差异不太大,同时正则参数的范围也有限 11 y_train = ss_y.fit_transform(y_train.reshape(-1, 1)) 12 y_test = ss_y.transform(y_test.reshape(-1, 1))
(6)确定模型类型
引入线性回归模型
1 columns = X.columns 2 # 线性回归 3 #class sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, 4 n_jobs=1) 5 from sklearn.linear_model import LinearRegression 6 # 使用默认配置初始化 7 lr = LinearRegression() 8 # 训练模型参数 9 lr.fit(X_train, y_train) 10 # 预测 11 y_test_pred_lr = lr.predict(X_test) 12 y_train_pred_lr = lr.predict(X_train) 13 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 14 fs = pd.DataFrame({"columns":list(columns), "coef":list((lr.coef_.T))}) 15 fs.sort_values(by=['coef'],ascending=False)

影响比较大的特征:
(1)GrLivArea(地上居住面积):房子越大越值钱,这个权值肯定最大的。
(2)BsmtFinSF1( 第一类型完成面积):虽然不太清楚第一类型是什么,但是跟面积有关,也算是越大越之前。
(3)OverallQual(整体材质和完成品质 ):完成品质高的房屋当然值钱。
(4)BsmtUnfSF (未完成的地下室总面积):没有装修的地下室更受欢迎,可能是人们喜欢自己布置地下室
(N)TotalBsmtSF (地下室总面积): 这个竟然成了负值
1 # 使用r2_score评价模型在测试集和训练集上的性能,并输出评估结果 2 #测试集 3 print ('The r2 score of LinearRegression on test is') 4 print(r2_score(y_test, y_test_pred_lr)) 5 #训练集 6 print ('The r2 score of LinearRegression on train is') 7 print(r2_score(y_train, y_train_pred_lr)) 8 The r2 score of LinearRegression on test is 9 0.9217323743543604 10 The r2 score of LinearRegression on train is 11 0.9176913214680575
在测试集竟然比在训练集表现要好?感觉在划分测试集和训练集时有点问题,划分的训练集分布可能不具有普片性~~
1 #在训练集上观察预测残差的分布,看是否符合模型假设:噪声为0均值的高斯噪声 2 f, ax = plt.subplots(figsize=(7, 5)) 3 f.tight_layout() 4 ax.hist(y_train - y_train_pred_lr,bins=40, label='Residuals Linear', color='b', alpha=.5); 5 ax.set_title("Histogram of Residuals") 6 ax.legend(loc='best');

残差分布符合基本正态分布特征,有点右skew,左边的残差接近2,可能是噪声造成的影响。
1 #还可以观察预测值与真值的散点图 2 plt.figure(figsize=(4, 3)) 3 plt.scatter(y_train, y_train_pred_lr) 4 plt.plot([-3, 3], [-3, 3], '--k') #数据已经标准化,3倍标准差即可 5 plt.axis('tight') 6 plt.xlabel('True price') 7 plt.ylabel('Predicted price') 8 plt.tight_layout()

在两端的值稍微有点偏差,推测也是噪声引起的
引入随机梯度下降优化模型
随机梯度下降一次迭代只会计算一个维度的下降方向,而梯度下降会综合所有维度,找出下降最快的方向。所以在多维度情 况下,随机梯度下降会比梯度下降收敛速度更快,这样做的坏处就是失去了精度。
1 # 线性模型,随机梯度下降优化模型参数 2 # 随机梯度下降一般在大数据集上应用,其实本项目不适合用 3 from sklearn.linear_model import SGDRegressor 4 # 使用默认配置初始化线 5 sgdr = SGDRegressor(max_iter=1000) 6 # 训练:参数估计 7 sgdr.fit(X_train, y_train) 8 # 预测 9 sgdr_y_predict_train = sgdr.predict(X_train) 10 sgdr_y_predict_test = sgdr.predict(X_test) 11 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 12 fs = pd.DataFrame({"columns":list(columns), "coef":list((sgdr.coef_.T))}) 13 fs.sort_values(by=['coef'],ascending=False) 14 # sgdr.coef_



TotalBsmtSF (地下室总面积): 这个仍然是负值!!!看来买房的人们不太在意地下室情况。
1 # 使用SGDRegressor模型自带的评估模块(评价准则为r2_score),并输出评估结果 2 print('The value of default measurement of SGDRegressor on test is ') 3 print(sgdr.score(X_test, y_test)) 4 #训练集 5 print('The value of default measurement of SGDRegressor on train is') 6 print(sgdr.score(X_train, y_train)) 7 8 #在训练集上观察预测残差的分布,看是否符合模型假设:噪声为0均值的高斯噪声 9 f, ax = plt.subplots(figsize=(7, 5)) 10 f.tight_layout() 11 ax.hist(y_train - sgdr_y_predict_train.reshape(-1, 1),bins=40, label='Residuals Linear', color='r', alpha=.5); 12 ax.set_title("Histogram of Residuals") 13 ax.legend(loc='best');


残差分布符合基本正态分布特征,和线性回归分布模型类型,左边的残差接近2,可能是噪声造成的影响。
引入L2正则化的线性回归模型(岭回归)
1 #岭回归/L2正则 2 #class sklearn.linear_model.RidgeCV(alphas=(0.1, 1.0, 10.0), fit_intercept=True, 3 # normalize=False, scoring=None, cv=None, gcv_mode=None, 4 # store_cv_values=False) 5 from sklearn.linear_model import RidgeCV 6 #设置超参数(正则参数)范围 7 #alphas = [ 0.01, 0.1, 1, 10,100] 8 n_alphas = 20 9 alphas = np.logspace(-5,2,n_alphas) 10 #生成一个RidgeCV实例 11 ridge = RidgeCV(alphas=alphas, store_cv_values=True) 12 #模型训练 13 ridge.fit(X_train, y_train) 14 #预测 15 y_test_pred_ridge = ridge.predict(X_test) 16 y_train_pred_ridge = ridge.predict(X_train) 17 # 评估,使用r2_score评价模型在测试集和训练集上的性能 18 print ('The r2 score of RidgeCV on test is', r2_score(y_test, y_test_pred_ridge)) 19 print ('The r2 score of RidgeCV on train is', r2_score(y_train, y_train_pred_ridge))

可视化
1 mse_mean = np.mean(ridge.cv_values_, axis = 0) 2 plt.plot(np.log10(alphas), mse_mean.reshape(len(alphas),1)) 3 #这是为了标出最佳参数的位置,不是必须 4 plt.plot(np.log10(ridge.alpha_)*np.ones(3), [0.099, 0.1, 0.101]) 5 plt.xlabel('log(alpha)') 6 plt.ylabel('mse') 7 plt.show() 8 print ('alpha is:', ridge.alpha_)


使L2正则的目标函数最小的alpha取值为18.32980710832434
1 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 2 fs = pd.DataFrame({"columns":list(columns), "coef_lr":list((lr.coef_.T)), 3 "coef_ridge":list((ridge.coef_.T))}) 4 fs.sort_values(by=['coef_lr'],ascending=False)

总结一下:
(1)对比线性回归和L2正则的线性回归来看,在权值分布上,差别并不是太大
(2)L2正则会使权值趋于非常小,但是在这个例子上似乎没有体现出来
(3)带L2正则的线性回归在测试集上略好于一般线性回归,但是在训练集上又略差与一般线性回归,这体现了L2正则消除 过拟合的特点,即降低训练集表现,提高测试集表现
引入L1正则化的线性回归模型(Lasso)
1 #### Lasso/L1正则 2 # class sklearn.linear_model.LassoCV(eps=0.001, n_alphas=100, alphas=None, fit_intercept=True, 3 # normalize=False, precompute=’auto’, max_iter=1000, 4 # tol=0.0001, copy_X=True, cv=None, verbose=False, n_jobs=1, 5 # positive=False, random_state=None, selection=’cyclic’) 6 from sklearn.linear_model import LassoCV 7 8 #设置超参数搜索范围 9 #alphas = [ 0.01, 0.1, 1, 10,100] 10 n_alphas = 20 11 alphas = np.logspace(-5,2,n_alphas) 12 #生成一个LassoCV实例 13 lasso = LassoCV(alphas=alphas) 14 #lasso = LassoCV() 15 16 #训练(内含CV) 17 lasso.fit(X_train, y_train) 18 19 #测试 20 y_test_pred_lasso = lasso.predict(X_test) 21 y_train_pred_lasso = lasso.predict(X_train) 22 23 24 # 评估,使用r2_score评价模型在测试集和训练集上的性能 25 print ('The r2 score of LassoCV on test is', r2_score(y_test, y_test_pred_lasso)) 26 print ('The r2 score of LassoCV on train is', r2_score(y_train, y_train_pred_lasso))

可视化
1 mses = np.mean(lasso.mse_path_, axis = 1) 2 plt.plot(np.log10(lasso.alphas_), mses) 3 #plt.plot(np.log10(lasso.alphas_)*np.ones(3),[0.1, 0.2, 0.3]) 4 plt.xlabel('log(alpha)') 5 plt.ylabel('mse') 6 plt.show() 7 print ('alpha is:', lasso.alpha_)

alpha is: 0.008858667904100823
使L1正则的目标函数最小的alpha取值为0.008858667904100823
1 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 2 fs = pd.DataFrame({"columns":list(columns), "coef_lr":list((lr.coef_.T)), 3 "coef_ridge":list((ridge.coef_.T)), "coef_lasso":list((lasso.coef_.T))}) 4 fs.sort_values(by=['coef_lr'],ascending=False)

总结一下:
(1)对比线性回归和L2正则的线性回归来看,L1正则线性回归在权值分布上,和前两者有相对较大的区别
(2)L1正则产生了稀疏性,许多权值都为0,据说这样的训练速度相对较快(没有亲测过)。
(3)带L1正则的线性回归在整体表现上要比L2正则和一般线性回归都要差一点。
四、总结
整个作业算是对线性回归有了总体的认识,从最开始的数据的分析、清洗,到最后模型的比较都需要仔细的研究。
(1)知道了正态分布的峰度和偏度,并对其有了初步的理解。
(2)了解了相关性矩阵,可以据此将相关性较大的属性去掉,降低特征工程的维度
(3)掌握了数据缺失值的方法,比如较多缺失值的可以直接删除该属性,较少缺失值的可以删除该样本,其余的进行插值 处理,可以用众数、中位数、平均数待敌缺失值,还有线性分析插值以及拉格朗日插值方法需要去探索学习。
(4)掌握了类别特征的编码,将期类别属性转化为数值属性。
(5)log变换使属性呈正态分布以及方差齐性的特点,有助于数据处理。
(6)了解了标准化和归一化的优缺点。
(7)对线性回归模型以及正则化防止过拟合有了一定的认识
结论
(1)GrLivArea(地上居住面积):房子越大越值钱,这个权值肯定最大的。
(2)BsmtFinSF1( 第一类型完成面积):虽然不太清楚第一类型是什么,但是跟面积有关,也算是越大越之前。
(3)OverallQual(整体材质和完成品质 ):完成品质高的房屋当然值钱。
(4)BsmtUnfSF (未完成的地下室总面积):没有装修的地下室更受欢迎,可能是人们喜欢自己布置地下室
(N)TotalBsmtSF (地下室总面积): 这个竟然成了负值。
通过线性回归模型得到了房屋销售价格中房屋各个特征的权重,以此了解了影响房屋销售价格的各种因素。可以凭此估测了房价未来走势。同时将来进一步探讨使得房价合理的具体措施。
以下附上完整代码:
1 import numpy as np # 矩阵操作 2 import pandas as pd # SQL数据处理 3 from sklearn.metrics import r2_score #评价回归预测模型的性能 4 import matplotlib.pyplot as plt #画图 5 import seaborn as sns 6 7 #忽略警告 8 import warnings 9 warnings.filterwarnings('ignore') 10 11 #获取训练数据集 12 dpath = './data/' 13 ames_train = pd.read_csv(dpath+"Ames_House_train.csv") 14 #获取测试数据集 15 ames_test = pd.read_csv(dpath+"Ames_House_test.csv") 16 17 #观察训练集数据 18 ames_train.head() 19 #观察测试集数据 20 ames_test.head() 21 22 ames_train.info() 23 #分析SalePrice的情况 24 ames_train['SalePrice'].describe() 25 #样本的SalePrice作正态分布曲线 26 sns.distplot(ames_train['SalePrice']); 27 28 #看看偏度(skewness)和峰度(peakedness) 29 print("Skewness: %f" % ames_train['SalePrice'].skew()) 30 print("Kurtosis: %f" % ames_train['SalePrice'].kurt()) 31 32 #作散点图 33 #LotArea:土地的大小 34 var = 'LotArea' 35 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 36 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)); 37 38 #作散点图 39 #GrLivArea:地上居住面积 40 var = 'GrLivArea' 41 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 42 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)); 43 44 #作散点图 45 #TotalBsmtSF:地下室总面积 46 var = 'TotalBsmtSF' 47 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 48 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)); 49 50 #Neighborhood:市内物理位置 51 var = 'Neighborhood' 52 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 53 f, ax = plt.subplots(figsize=(20, 8)) 54 fig = sns.boxplot(x=var, y="SalePrice", data=data) 55 fig.axis(ymin=0, ymax=800000); 56 57 #OverallQual:整体材质和完成品质 58 var = 'OverallQual' 59 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 60 f, ax = plt.subplots(figsize=(16, 8)) 61 fig = sns.boxplot(x=var, y="SalePrice", data=data) 62 fig.axis(ymin=0, ymax=800000); 63 64 #OverallCond:总体条件评级 65 var = 'OverallCond' 66 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 67 f, ax = plt.subplots(figsize=(16, 8)) 68 fig = sns.boxplot(x=var, y="SalePrice", data=data) 69 fig.axis(ymin=0, ymax=800000); 70 71 #YearBuilt:最初建造日期 72 var = 'YearBuilt' 73 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 74 f, ax = plt.subplots(figsize=(20, 8)) 75 fig = sns.boxplot(x=var, y="SalePrice", data=data) 76 fig.axis(ymin=0, ymax=800000); 77 plt.xticks(rotation=90); 78 79 #correlation matrix热图,corr()计算相关性 80 corrmat = ames_train.corr() 81 f, ax = plt.subplots(figsize=(20, 12)) 82 #vmax 能显示的最大值 vmin能显示的最小值 83 sns.heatmap(corrmat, vmax=0.9, square=True); 84 85 k = 10 #相关属性数量 86 cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index 87 cm = np.corrcoef(ames_train[cols].values.T) 88 sns.set(font_scale=1.25) 89 hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values) 90 plt.show() 91 92 #去掉GarageArea(车库大小)、TotRmsAbvGrd(地上房间总数)、1stFlrSF(第一层面积) 93 ames_train = ames_train.drop('GarageArea', axis = 1) 94 ames_train = ames_train.drop('TotRmsAbvGrd', axis = 1) 95 ames_train = ames_train.drop('1stFlrSF', axis = 1) 96 ames_train.shape 97 98 #数据缺失值处理 99 #首先看看哪些特征缺失的最多 100 total = ames_train.isnull().sum().sort_values(ascending=False) 101 percent = (ames_train.isnull().sum()/ames_train.isnull().count()).sort_values(ascending=False) 102 missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) 103 missing_data.head(20) 104 105 #去掉PoolQC 106 ames_train = ames_train.drop(['PoolQC','MiscFeature','Alley','Fence','FireplaceQu'], axis = 1) 107 108 #去掉Electrical有缺失值的样本 109 ames_train = ames_train.drop(ames_train.loc[ames_train['Electrical'].isnull()].index) 110 #去掉MasVnrArea有缺失值的样本 111 ames_train = ames_train.drop(ames_train.loc[ames_train['MasVnrArea'].isnull()].index) 112 #去掉MMasVnrType有缺失值的样本 113 ames_train = ames_train.drop(ames_train.loc[ames_train['MasVnrType'].isnull()].index) 114 115 ames_train.shape 116 117 #strategy : ①若为mean时,用特征列的均值替换 ②若为median时,用特征列的中位数替换 ③若为most_frequent时,用特征列的众数替换 118 119 #处理数值型特征,缺失值用中位数填补 120 ames_train=ames_train.fillna(ames_train.median()) 121 122 #处理类别型特征,缺失值用该类别众数填补 123 #GarageType属性 124 ames_train['GarageType']=ames_train['GarageType'].fillna(ames_train['GarageType'].describe().top) 125 #GarageCond属性 126 ames_train['GarageCond']=ames_train['GarageCond'].fillna(ames_train['GarageCond'].describe().top) 127 #GarageFinish属性 128 ames_train['GarageFinish']=ames_train['GarageFinish'].fillna(ames_train['GarageFinish'].describe().top) 129 #GarageQual属性 130 ames_train['GarageQual']=ames_train['GarageQual'].fillna(ames_train['GarageQual'].describe().top) 131 #BsmtExposure属性 132 ames_train['BsmtExposure']=ames_train['BsmtExposure'].fillna(ames_train['BsmtExposure'].describe().top) 133 #BsmtFinType2属性 134 ames_train['BsmtFinType2']=ames_train['BsmtFinType2'].fillna(ames_train['BsmtFinType2'].describe().top) 135 #BsmtFinType1属性 136 ames_train['BsmtFinType1']=ames_train['BsmtFinType1'].fillna(ames_train['BsmtFinType1'].describe().top) 137 #BsmtCond属性 138 ames_train['BsmtCond']=ames_train['BsmtCond'].fillna(ames_train['BsmtCond'].describe().top) 139 #BsmtQual属性 140 ames_train['BsmtQual']=ames_train['BsmtQual'].fillna(ames_train['BsmtQual'].describe().top) 141 142 ames_train.shape 143 144 #观察下是否还有存在缺失值的特征 145 ames_train.isnull().sum().max() 146 147 from sklearn.pipeline import Pipeline 148 from sklearn.preprocessing import LabelEncoder 149 #定义一个类,可以将类别标签进行编码,e.g 假设四个标签,分别标为【1,2,3,4】 150 class MultiColumnLabelEncoder: 151 def __init__(self,columns = None): 152 self.columns = columns # array of column names to encode 153 154 def fit(self,X,y=None): 155 return self # not relevant here 156 157 def transform(self,X): 158 output = X.copy() 159 if self.columns is not None: 160 for col in self.columns: 161 output[col] = LabelEncoder().fit_transform(output[col]) 162 else: 163 for colname,col in output.iteritems(): 164 output[colname] = LabelEncoder().fit_transform(col) 165 return output 166 167 def fit_transform(self,X,y=None): 168 return self.fit(X,y).transform(X) 169 170 #获取列类型为object的列,获取类别列 171 object_columns=[] 172 for col in ames_train.columns: 173 if ames_train[col].dtypes=='object': 174 object_columns.append(col) 175 176 #将类别特征string转化为数值型(0,1,2,3,4......) 177 ames_train=MultiColumnLabelEncoder(columns = object_columns).fit_transform(ames_train) 178 179 ames_train.head(20) 180 181 #地上居住面积 182 var = 'GrLivArea' 183 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 184 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)); 185 186 ames_train[(ames_train.GrLivArea>4500)] 187 188 #找到这两个离群点,删除他们 189 ames_train = ames_train.drop(ames_train[ames_train['Id'] == 1299].index) 190 ames_train = ames_train.drop(ames_train[ames_train['Id'] == 524].index) 191 ames_train.shape 192 193 #地下室总面积 194 var = 'TotalBsmtSF' 195 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 196 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)); 197 198 #低质量完成的面积 199 var = 'LowQualFinSF' 200 data = pd.concat([ames_train['SalePrice'], ames_train[var]], axis=1) 201 data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)); 202 203 ames_train[(ames_train.LowQualFinSF>550)] 204 205 #取出该样本的总面积 206 lowQuaHouse=ames_train[ames_train.Id==186] 207 lowQuaHouse[['GrLivArea','TotalBsmtSF']] 208 209 #histogram and normal probability plot 210 from scipy.stats import norm 211 from scipy import stats 212 sns.distplot(ames_train['SalePrice'], fit=norm); 213 fig = plt.figure() 214 res = stats.probplot(ames_train['SalePrice'], plot=plt) 215 216 #使用log变换 217 ames_train['SalePrice'] = np.log(ames_train['SalePrice']) 218 219 sns.distplot(ames_train['SalePrice'], fit=norm); 220 fig = plt.figure() 221 res = stats.probplot(ames_train['SalePrice'], plot=plt) 222 223 sns.distplot(ames_train['GrLivArea'], fit=norm); 224 fig = plt.figure() 225 res = stats.probplot(ames_train['GrLivArea'], plot=plt) 226 227 #使用log变换 228 ames_train['GrLivArea'] = np.log(ames_train['GrLivArea']) 229 230 sns.distplot(ames_train['GrLivArea'], fit=norm); 231 fig = plt.figure() 232 res = stats.probplot(ames_train['GrLivArea'], plot=plt) 233 234 #TotalBsmtSF正态分布特征 235 sns.distplot(ames_train['TotalBsmtSF'], fit=norm); 236 fig = plt.figure() 237 res = stats.probplot(ames_train['TotalBsmtSF'], plot=plt) 238 239 #重新定义一项BsmtFlag,为0表示没有地下室,为1表示有地下室 240 ames_train['BsmtFlag'] = pd.Series(len(ames_train['TotalBsmtSF']), index=ames_train.index) 241 ames_train['BsmtFlag'] = 0 242 ames_train.loc[ames_train['TotalBsmtSF']>0,'BsmtFlag'] = 1 243 #log变换 244 ames_train.loc[ames_train['BsmtFlag']==1,'TotalBsmtSF'] = np.log(ames_train['TotalBsmtSF']) 245 246 #只列出了有地下室情况的正态分布特征 247 sns.distplot(ames_train[ames_train['TotalBsmtSF']>0]['TotalBsmtSF'], fit=norm); 248 fig = plt.figure() 249 res = stats.probplot(ames_train[ames_train['TotalBsmtSF']>0]['TotalBsmtSF'], plot=plt) 250 251 #把新增的BsmtFlag列去掉 252 ames_train=ames_train.drop('BsmtFlag', axis = 1) 253 ames_train.shape 254 255 plt.scatter(ames_train['GrLivArea'], ames_train['SalePrice']); 256 257 plt.scatter(ames_train[ames_train['TotalBsmtSF']>0]['TotalBsmtSF'], ames_train[ames_train['TotalBsmtSF']>0]['SalePrice']); 258 259 #网上下载的测试集没有saleprice,只有将训练集ames_train分割成训练和测试集。。。。 260 #另外当数据较少时,可以考虑使用交叉验证,来扩充数据大小 261 262 # 从原始数据中分离输入特征x和输出y 263 y = ames_train['SalePrice'].values 264 265 #还要去掉编号ID 266 X = ames_train.drop(['SalePrice','Id'], axis = 1) 267 268 #将数据分割训练数据与测试数据 269 from sklearn.model_selection import train_test_split 270 271 # 随机采样20%的数据构建测试样本,其余作为训练样本 272 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33, test_size=0.2) 273 274 # 数据标准化 275 from sklearn.preprocessing import StandardScaler 276 277 # 分别初始化对特征和目标值的标准化器 278 ss_X = StandardScaler() 279 ss_y = StandardScaler() 280 281 # 分别对训练和测试数据的特征以及目标值进行标准化处理 282 X_train = ss_X.fit_transform(X_train) 283 X_test = ss_X.transform(X_test) 284 285 #对y做标准化不是必须 286 #对y标准化的好处是不同问题的w差异不太大,同时正则参数的范围也有限 287 y_train = ss_y.fit_transform(y_train.reshape(-1, 1)) 288 y_test = ss_y.transform(y_test.reshape(-1, 1)) 289 290 columns = X.columns 291 # 线性回归 292 #class sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1) 293 from sklearn.linear_model import LinearRegression 294 295 # 使用默认配置初始化 296 lr = LinearRegression() 297 298 # 训练模型参数 299 lr.fit(X_train, y_train) 300 301 # 预测 302 y_test_pred_lr = lr.predict(X_test) 303 y_train_pred_lr = lr.predict(X_train) 304 305 306 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 307 fs = pd.DataFrame({"columns":list(columns), "coef":list((lr.coef_.T))}) 308 fs.sort_values(by=['coef'],ascending=False) 309 310 # 使用r2_score评价模型在测试集和训练集上的性能,并输出评估结果 311 #测试集 312 print ('The r2 score of LinearRegression on test is') 313 print(r2_score(y_test, y_test_pred_lr)) 314 #训练集 315 print ('The r2 score of LinearRegression on train is') 316 print(r2_score(y_train, y_train_pred_lr)) 317 318 #在训练集上观察预测残差的分布,看是否符合模型假设:噪声为0均值的高斯噪声 319 f, ax = plt.subplots(figsize=(7, 5)) 320 f.tight_layout() 321 ax.hist(y_train - y_train_pred_lr,bins=40, label='Residuals Linear', color='b', alpha=.5); 322 ax.set_title("Histogram of Residuals") 323 ax.legend(loc='best'); 324 325 #还可以观察预测值与真值的散点图 326 plt.figure(figsize=(4, 3)) 327 plt.scatter(y_train, y_train_pred_lr) 328 plt.plot([-3, 3], [-3, 3], '--k') #数据已经标准化,3倍标准差即可 329 plt.axis('tight') 330 plt.xlabel('True price') 331 plt.ylabel('Predicted price') 332 plt.tight_layout() 333 334 # 线性模型,随机梯度下降优化模型参数 335 # 随机梯度下降一般在大数据集上应用,其实本项目不适合用 336 from sklearn.linear_model import SGDRegressor 337 338 # 使用默认配置初始化线 339 sgdr = SGDRegressor(max_iter=1000) 340 341 # 训练:参数估计 342 sgdr.fit(X_train, y_train) 343 344 # 预测 345 sgdr_y_predict_train = sgdr.predict(X_train) 346 sgdr_y_predict_test = sgdr.predict(X_test) 347 348 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 349 fs = pd.DataFrame({"columns":list(columns), "coef":list((sgdr.coef_.T))}) 350 fs.sort_values(by=['coef'],ascending=False) 351 # sgdr.coef_ 352 353 # 使用SGDRegressor模型自带的评估模块(评价准则为r2_score),并输出评估结果 354 print('The value of default measurement of SGDRegressor on test is ') 355 print(sgdr.score(X_test, y_test)) 356 #训练集 357 print('The value of default measurement of SGDRegressor on train is') 358 print(sgdr.score(X_train, y_train)) 359 360 #在训练集上观察预测残差的分布,看是否符合模型假设:噪声为0均值的高斯噪声 361 f, ax = plt.subplots(figsize=(7, 5)) 362 f.tight_layout() 363 ax.hist(y_train - sgdr_y_predict_train.reshape(-1, 1),bins=40, label='Residuals Linear', color='r', alpha=.5); 364 ax.set_title("Histogram of Residuals") 365 ax.legend(loc='best'); 366 367 #岭回归/L2正则 368 #class sklearn.linear_model.RidgeCV(alphas=(0.1, 1.0, 10.0), fit_intercept=True, 369 # normalize=False, scoring=None, cv=None, gcv_mode=None, 370 # store_cv_values=False) 371 from sklearn.linear_model import RidgeCV 372 373 #设置超参数(正则参数)范围 374 #alphas = [ 0.01, 0.1, 1, 10,100] 375 376 n_alphas = 20 377 alphas = np.logspace(-5,2,n_alphas) 378 379 #生成一个RidgeCV实例 380 ridge = RidgeCV(alphas=alphas, store_cv_values=True) 381 382 #模型训练 383 ridge.fit(X_train, y_train) 384 385 #预测 386 y_test_pred_ridge = ridge.predict(X_test) 387 y_train_pred_ridge = ridge.predict(X_train) 388 389 390 # 评估,使用r2_score评价模型在测试集和训练集上的性能 391 print ('The r2 score of RidgeCV on test is', r2_score(y_test, y_test_pred_ridge)) 392 print ('The r2 score of RidgeCV on train is', r2_score(y_train, y_train_pred_ridge)) 393 394 mse_mean = np.mean(ridge.cv_values_, axis = 0) 395 plt.plot(np.log10(alphas), mse_mean.reshape(len(alphas),1)) 396 397 #这是为了标出最佳参数的位置,不是必须 398 plt.plot(np.log10(ridge.alpha_)*np.ones(3), [0.099, 0.1, 0.101]) 399 400 plt.xlabel('log(alpha)') 401 plt.ylabel('mse') 402 plt.show() 403 404 print ('alpha is:', ridge.alpha_) 405 406 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 407 fs = pd.DataFrame({"columns":list(columns), "coef_lr":list((lr.coef_.T)), "coef_ridge":list((ridge.coef_.T))}) 408 fs.sort_values(by=['coef_lr'],ascending=False) 409 410 #### Lasso/L1正则 411 # class sklearn.linear_model.LassoCV(eps=0.001, n_alphas=100, alphas=None, fit_intercept=True, 412 # normalize=False, precompute=’auto’, max_iter=1000, 413 # tol=0.0001, copy_X=True, cv=None, verbose=False, n_jobs=1, 414 # positive=False, random_state=None, selection=’cyclic’) 415 from sklearn.linear_model import LassoCV 416 417 #设置超参数搜索范围 418 #alphas = [ 0.01, 0.1, 1, 10,100] 419 n_alphas = 20 420 alphas = np.logspace(-5,2,n_alphas) 421 #生成一个LassoCV实例 422 lasso = LassoCV(alphas=alphas) 423 #lasso = LassoCV() 424 425 #训练(内含CV) 426 lasso.fit(X_train, y_train) 427 428 #测试 429 y_test_pred_lasso = lasso.predict(X_test) 430 y_train_pred_lasso = lasso.predict(X_train) 431 432 433 # 评估,使用r2_score评价模型在测试集和训练集上的性能 434 print ('The r2 score of LassoCV on test is', r2_score(y_test, y_test_pred_lasso)) 435 print ('The r2 score of LassoCV on train is', r2_score(y_train, y_train_pred_lasso)) 436 437 mses = np.mean(lasso.mse_path_, axis=1) 438 plt.plot(np.log10(lasso.alphas_), mses) 439 440 # plt.plot(np.log10(lasso.alphas_)*np.ones(3),[0.1, 0.2, 0.3]) 441 plt.xlabel('log(alpha)') 442 plt.ylabel('mse') 443 plt.show() 444 445 print('alpha is:', lasso.alpha_) 446 447 # 看看各特征的权重系数,系数的绝对值大小可视为该特征的重要性 448 fs = pd.DataFrame({"columns":list(columns), "coef_lr":list((lr.coef_.T)), "coef_ridge":list((ridge.coef_.T)), "coef_lasso":list((lasso.coef_.T))}) 449 fs.sort_values(by=['coef_lr'],ascending=False)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报