

树链剖分
一、树链剖分的概念和写法
1.1概念
定义:树链剖分用于将树分割成若干条链的形式,以维护树上路径的信息。具体来说,将整棵树剖分为若干条链,使它组合成线性结构,然后用其他的数据结构维护信息。
树链剖分(树剖/链剖)有多种形式,如 重链剖分,长链剖分 和用于 Link/cut Tree 的剖分(有时被称作「实链剖分」),大多数情况下(没有特别说明时),「树链剖分」都指「重链剖分」。
树链剖分一般可以做:路径修改\查询,子树修改\查询
一些定义:
定义 重儿子节点 表示其子节点中子树最大的子结点。如果有多个子树最大的子结点,取其一。如果没有子节点,就无重子节点。
定义 轻儿子节点 表示剩余的所有子结点。
从这个结点到重子节点的边为 重边。
到其他轻子节点的边为 轻边。
若干条首尾衔接的重边构成 重链。
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链。
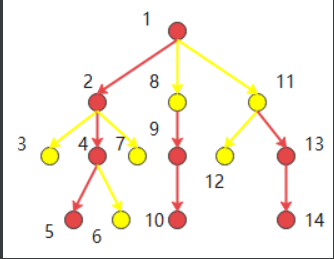
我们观察图中,重链是以轻儿子或整棵树的根为起点,依次向下连接所有重儿子组成的链。而轻链是以重链为主干链,其分支的链为轻链的,且向外扩展长度为1。
轻链的本质就是一些长度为1的边,将他们作为桥梁连接下一个重链。同时还可以看出,轻儿子(除去叶子结点)都是下一条重链的起始结点。
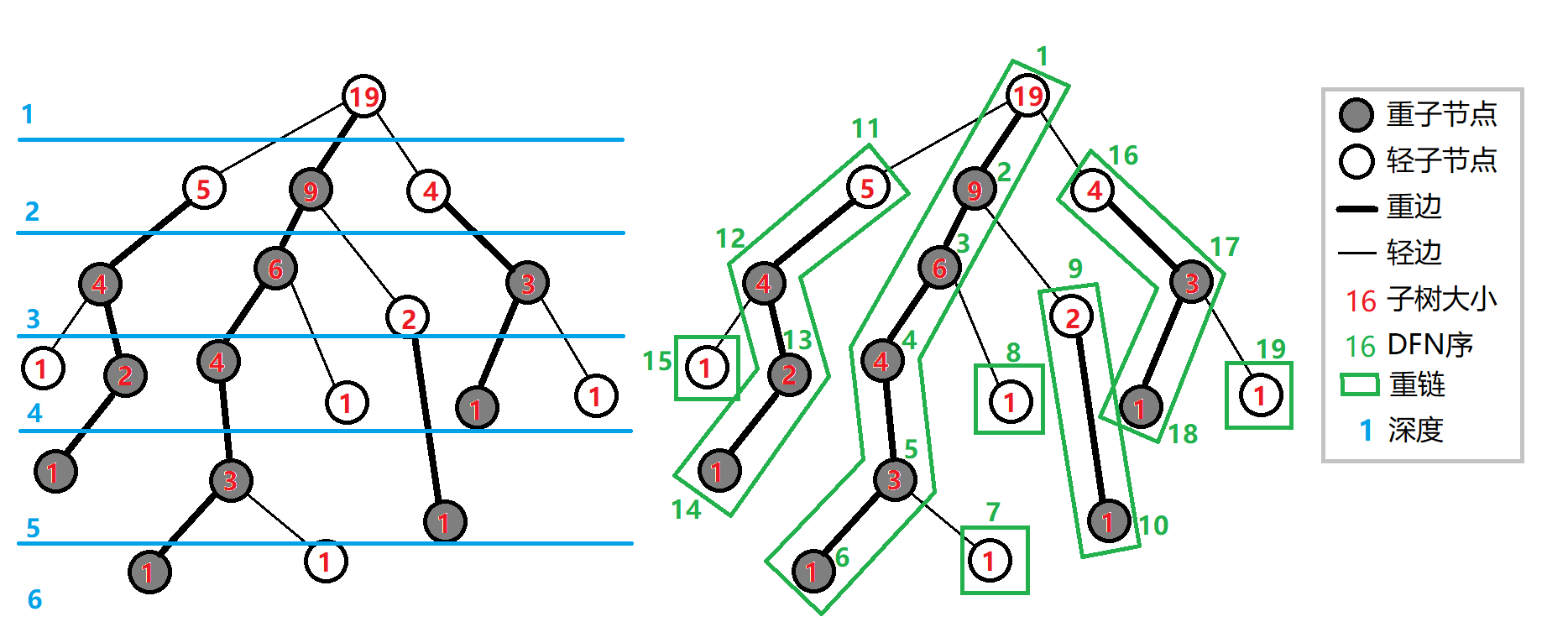
两遍dfs就是树链剖分的主要处理,通过dfs我们已经保证一条重链上各个节点dfs序连续,那么可以想到,我们可以通过数据结构(以线段树为例)来维护一条重链的信息
第一遍
第二遍
❗关于第二遍
首先根据
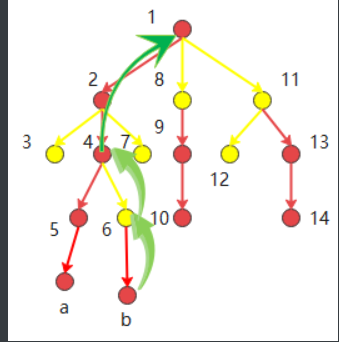
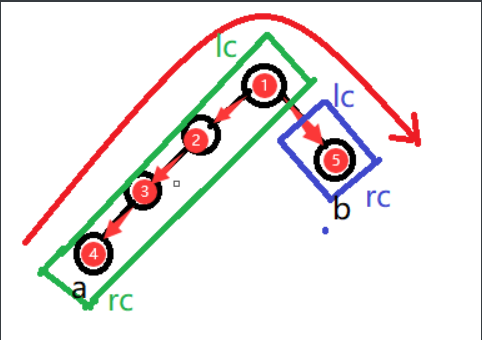
为什么要记录链头元素?(该部分引用自)
我们得到了一系列的重链,如何对它们快速操作?那么就是记录链头元素。这样我们就可以直接跳到链头元素。但是我们遇到了一个问题:在同一条重链上可以直接跳到头部,如果不是在同一条链上呢?方法是:从这条重链的头部再往上跳,到他的父亲结点,必定在另外一条重链上,然后根据需求继续跳。如图所示,b结点跳跃的过程:
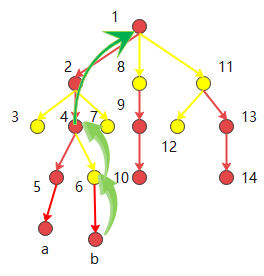
b在{6 b}这条重链,跳至6号结点,从6号再跳到{1 2 4 5 a}这条重链,再跳就是1根节点。到这里,再想想什么是轻链,理解会更深刻“将他们作为“桥梁”连接下一个重链”。
1.2 (重要)性质
经过轻边,子树大小翻倍。一个点往上走,最多走
1.3基本实现
#include<bits/stdc++.h> using namespace std; const int N = 1e5+10; vector<int>e[N]; int l[N],r[N],id[N],sz[N],hs[N],tot,dep[N],f[N],top[N]; //第一遍dfs处理每个点的重儿子,节点大小,深度,每个点的父亲 void dfs1(int u,int fa) { sz[u] = 1; hs[u] = -1; dep[u] = dep[fa]+1; f[u] = fa for(auto v:e[u]) { if(v==fa)continue; dfs1(v,u); sz[u]+=sz[v]; if(hs[u]==-1||sz[v]>sz[hs[u]])hs[u] = v; } } //第二步dfs,求出每个点的dfs序,重链上的链头的元素 void dfs2(int u,int t)//keep表示需不需要保留当前信息 { top[u] = t; l[u] = ++tot; id[tot] = u; if(hs[u]!=-1) dfs2(hs[u],t);//重儿子的集合 for(auto v:e[u]) { if(v!=fa[u]&&v!=hs[u])//v是轻儿子,它的链头就是它本身 { dfs2(v,v); } } r[u] = tot; } int main() { cin>>n; for(int i = 1;i<=n;i++) { int u,v; cin>>u>>v; e[u].push_back(v); e[v].push_back(u); } dfs1(1,0); dfs2(1,1); return 0; }
1.4 简单应用:树链剖分求
预处理时间复杂度
以上图为例,求
首先思考两个问题:
-
谁先跳?
深度大的先跳。这时候你会想,那
-
什么时候能判断出
如果两个点在同一重链上,那么深度较小的,为
例题:树上LCA2
#include<bits/stdc++.h> using namespace std; const int N = 1e5+10; vector<int>e[N]; int l[N],r[N],id[N],sz[N],hs[N],tot,dep[N],f[N],top[N]; int n,m; //第一遍dfs处理每个点的重儿子,节点大小,深度,每个点的父亲 void dfs1(int u,int fa) { sz[u] = 1; hs[u] = -1; dep[u] = dep[fa]+1; f[u] = fa; for(auto v:e[u]) { if(v==fa)continue; dfs1(v,u); sz[u]+=sz[v]; if(hs[u]==-1||sz[v]>sz[hs[u]])hs[u] = v; } } //第二步dfs,求出每个点的dfs序,重链上的链头的元素 void dfs2(int u,int t)//keep表示需不需要保留当前信息 { l[u] = ++tot; id[tot] = u; top[u] = t; if(hs[u]!=-1) dfs2(hs[u],t);//重儿子的集合 for(auto v:e[u]) { if(v!=f[u]&&v!=hs[u])//v是轻儿子,它的链头就是它本身 { dfs2(v,v); } } r[u] = tot; } int LCA(int u,int v) { while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]])v = f[top[v]]; else u = f[top[u]]; } if(dep[u]<dep[v])return u; else return v; } int main() { cin>>n; for(int i = 1;i<n;i++) { int u,v; cin>>u>>v; e[u].push_back(v); e[v].push_back(u); } dfs1(1,0); dfs2(1,1); cin>>m; for(int i = 1;i<=m;i++) { int u,v; cin>>u>>v; cout<<LCA(u,v)<<"\n"; } return 0; }
二、树链剖分的路径查询
根据上面第一点中所说的,在第二遍
此时我们考虑对整个
考虑一个点
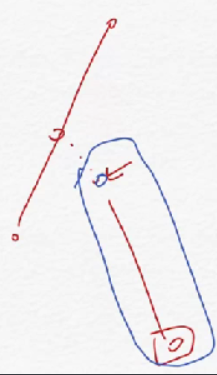
例题:SDOI2011, 染色
题意:
给定一棵
- 将节点
- 询问节点
颜色段的定义是极长的连续相同颜色被认为是一段。例如 112221 由三段组成:11、222、1。
思路:考虑从
注意点如下图:
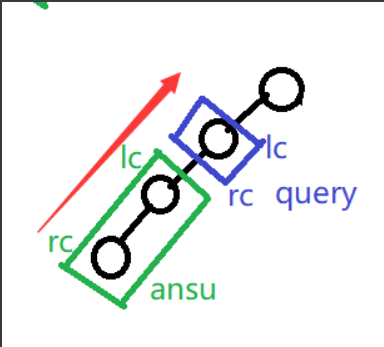
注意拼接顺序❗
#include<bits/stdc++.h> using namespace std; typedef long long ll; const int N = 1e5+10; vector<int>e[N]; int l[N],r[N],idx[N],sz[N],hs[N],tot,dep[N],f[N],top[N],w[N]; int n,m; struct info { int lc,rc,seg; }; info operator+(const info &l,const info &r) { return (info){l.lc,r.rc,l.seg+r.seg+(l.rc!=r.lc)}; } struct node{ info val; int t; }seg[N*4]; void settag(int id,int t) { seg[id].val = {t,t,0}; seg[id].t = t; } void pushdown(int id) { if(seg[id].t!=0) { settag(id*2,seg[id].t); settag(id*2+1,seg[id].t); seg[id].t = 0; } } void update(int id) { seg[id].val = seg[id*2].val+seg[id*2+1].val; } void build(int id,int l,int r) { if(l==r) { //l号点,dfs序中第l个点,而不是a[l],这里要注意❗ //seg[id].val = {a[l],a[l]}; seg[id].val = {w[idx[l]],w[idx[l]],0}; } else { int mid = (l+r)>>1; build(id*2,l,mid); build(id*2+1,mid+1,r); update(id); } } void modify(int id,int l,int r,int x,int y,int t){ if(l==x&&r==y) { settag(id,t); return; } int mid = (l+r)/2; pushdown(id); if(y<=mid) modify(id*2,l,mid,x,y,t); else if(x>mid) modify(id*2+1,mid+1,r,x,y,t); else{ modify(id*2,l,mid,x,mid,t),modify(id*2+1,mid+1,r,mid+1,y,t); } update(id); } //O(logn) info query(int id,int l,int r,int x,int y) { if(l==x&&r==y)return seg[id].val; int mid = (l+r)/2; pushdown(id); if(y<=mid)return query(id*2,l,mid,x,y); else if(x>mid)return query(id*2+1,mid+1,r,x,y); else{ return query(id*2,l,mid,x,mid)+query(id*2+1,mid+1,r,mid+1,y); } } //第一遍dfs处理每个点的重儿子,节点大小,深度,每个点的父亲 void dfs1(int u,int fa) { sz[u] = 1; hs[u] = -1; dep[u] = dep[fa]+1; f[u] = fa; for(auto v:e[u]) { if(v==fa)continue; dfs1(v,u); sz[u]+=sz[v]; if(hs[u]==-1||sz[v]>sz[hs[u]])hs[u] = v; } } //第二步dfs,求出每个点的dfs序,重链上的链头的元素 void dfs2(int u,int t)//keep表示需不需要保留当前信息 { l[u] = ++tot; idx[tot] = u; top[u] = t; if(hs[u]!=-1) dfs2(hs[u],t);//重儿子的集合 for(auto v:e[u]) { if(v!=f[u]&&v!=hs[u])//v是轻儿子,它的链头就是它本身 { dfs2(v,v); } } r[u] = tot; } int LCA(int u,int v) { while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]])v = f[top[v]]; else u = f[top[u]]; } if(dep[u]<dep[v])return u; else return v; } int query(int u,int v) { info ansu = {0,0,-1},ansv={0,0,-1}; while(top[u]!=top[v]) { if(dep[top[u]]<dep[top[v]]){ ansv = query(1,1,n,l[top[v]],l[v]) + ansv;//在前面加一段 v = f[top[v]]; } else{ ansu = query(1,1,n,l[top[u]],l[u]) + ansu; u = f[top[u]]; } } if(dep[u]<=dep[v])ansv = query(1,1,n,l[u],l[v])+ansv; else ansu = query(1,1,n,l[v],l[u])+ansu; return ansu.seg+ansv.seg+(ansu.lc!=ansv.lc)+1; } void modify(int u,int v,int c) { // while(top[u]!=top[v]) // { // if(dep[top[u]]<dep[top[v]]){ // modify(1,1,n,l[top[v]],l[v],c); // v = f[top[v]]; // } // else{ // modify(1,1,n,l[top[u]],l[u],c); // u = f[top[u]]; // } // } // if(dep[u]<=dep[v])modify(1,1,n,l[u],l[v],c); // else modify(1,1,n,l[v],l[u],c); while(top[u]!=top[v]) { if(dep[top[u]]>dep[top[v]])swap(u,v); modify(1,1,n,l[top[v]],l[v],c); v = f[top[v]]; } if(dep[u]>dep[v])swap(u,v); modify(1,1,n,l[u],l[v],c); } int main() { cin>>n>>m; for(int i = 1;i<=n;i++) cin>>w[i]; for(int i = 1;i<n;i++) { int u,v; cin>>u>>v; e[u].push_back(v); e[v].push_back(u); } dfs1(1,0); dfs2(1,1); build(1,1,n); for(int i = 1;i<=m;i++) { char op; cin>>op; if(op=='Q') { int u,v; cin>>u>>v; cout<<query(u,v)<<endl; } else { int u,v,c; cin>>u>>v>>c; modify(u,v,c); } } return 0; }
三、树链剖分的子树查询
例题:NOI2015, 软件包管理器
题意:要下载某一个软件,就要把该软件到根路径上的所有没下载的软件都下载了。问每次操作完,有多少个软件包状态发生改变(从安装到没安装,或者从没安装到安装)。
#include<bits/stdc++.h> using namespace std; typedef long long ll; const int N = 1e5+10; vector<int>e[N]; int l[N],r[N],idx[N],sz[N],hs[N],tot,dep[N],f[N],top[N],w[N]; int n,m; struct node{ int cnt; int sz; int t; }seg[N*4]; void settag(int id,int t) { if(t==1) seg[id].cnt = seg[id].sz; else seg[id].cnt = 0; seg[id].t = t; } void pushdown(int id) { if(seg[id].t!=-1) { settag(id*2,seg[id].t); settag(id*2+1,seg[id].t); seg[id].t = -1; } } void update(int id) { seg[id].cnt= seg[id*2].cnt+seg[id*2+1].cnt; } void build(int id,int l,int r) { seg[id].sz = (r-l+1); seg[id].t = -1; if(l==r) { seg[id].cnt = 0; } else { int mid = (l+r)>>1; build(id*2,l,mid); build(id*2+1,mid+1,r); update(id); } } void modify(int id,int l,int r,int x,int y,int t){ if(l==x&&r==y) { settag(id,t); return; } int mid = (l+r)/2; pushdown(id); if(y<=mid) modify(id*2,l,mid,x,y,t); else if(x>mid) modify(id*2+1,mid+1,r,x,y,t); else{ modify(id*2,l,mid,x,mid,t),modify(id*2+1,mid+1,r,mid+1,y,t); } update(id); } //第一遍dfs处理每个点的重儿子,节点大小,深度,每个点的父亲 void dfs1(int u,int fa) { sz[u] = 1; hs[u] = -1; dep[u] = dep[fa]+1; f[u] = fa; for(auto v:e[u]) { if(v==fa)continue; dfs1(v,u); sz[u]+=sz[v]; if(hs[u]==-1||sz[v]>sz[hs[u]])hs[u] = v; } } //第二步dfs,求出每个点的dfs序,重链上的链头的元素 void dfs2(int u,int t)//keep表示需不需要保留当前信息 { l[u] = ++tot; idx[tot] = u; top[u] = t; if(hs[u]!=-1) dfs2(hs[u],t);//重儿子的集合 for(auto v:e[u]) { if(v!=f[u]&&v!=hs[u])//v是轻儿子,它的链头就是它本身 { dfs2(v,v); } } r[u] = tot; } void install(int x) { while(x!=0) { modify(1,1,n,l[top[x]],l[x],1); x = f[top[x]]; } } void uninstall(int x) { modify(1,1,n,l[x],r[x],0); } int main() { ios::sync_with_stdio(false),cin.tie(0),cout.tie(0); cin>>n; for(int i = 2;i<=n;i++) { cin>>f[i]; ++f[i]; e[f[i]].push_back(i); } dfs1(1,0); dfs2(1,1); build(1,1,n); cin>>m; int pre = 0; for(int i = 1;i<=m;i++) { string op; int x; cin>>op>>x; x++; if(op=="install") { install(x); } else { uninstall(x); } cout<<abs(seg[1].cnt-pre)<<"\n"; pre = seg[1].cnt; } return 0; }
四、总结
树链剖分把路径问题转为为


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】