Faster RCNN模型精度
论文题目:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文连接:https://arxiv.org/pdf/1506.01497.pdf
Faster RCNN是为了改进Fast R-CNN而提出来的。因为在Fast R-CNN文章中的测试时间是不包括search selective时间的,而在测试时很大的一部分时间要耗费在候选区域的提取上。
1.输入测试图像;
2.将整张图片输入CNN,进行特征提取;没有再对region proposal做特殊处理,直接无脑将图片输入backbone CNN提取特征即feacture map。
3.用RPN网络生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
4.把region proposal映射到CNN的最后一层卷积feature map上;
5.通过ROI pooling层使每个ROI生成固定尺寸的feature map;
6.利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比Fast-RCNN,主要两处不同:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生region proposal;
(2)产生建议窗口的CNN和目标检测的CNN共享
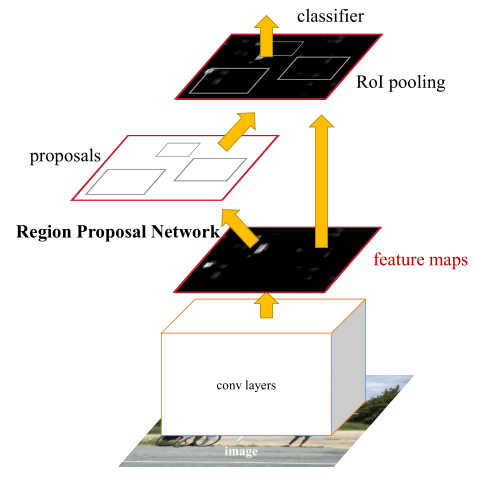
总体网络宏观如图
如果放大细节来看如下图
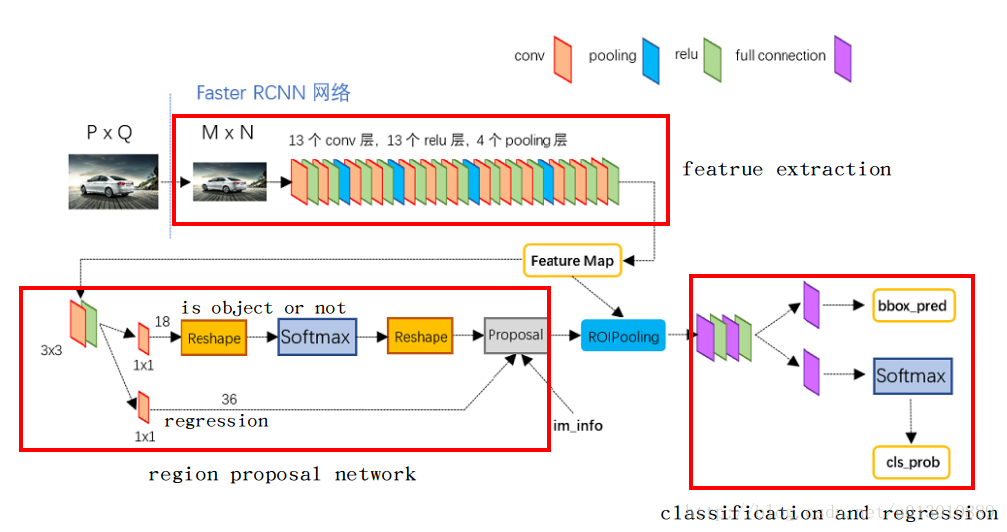
注:图片引用自MichaelLiu_dev
1)卷积层(conv layers),用于提取图片的特征,输入为整张图片,输出为提取出的特征称为feature maps
2)RPN网络(Region Proposal Network),用于推荐候选区域region proposal,这个网络是用来代替之前的selective search的。输入为图片(因为这里RPN网络和Fast R-CNN共用同一个CNN,所以这里输入也可以认为是featrue maps),输出为多个候选区域,这里的细节会在后面详细介绍。
3)ROI pooling,和Fast R-CNN一样,将不同大小的输入转换为固定长度的输出,输入输出和Faste R-CNN中ROI pooling一样。
4)分类和回归,这一层的输出是最终目的,输出候选区域所属的类,和候选区域在图像中的精确位置。
1. RPN网络(Region Proposal Networks)
原文中RPN网络为CNN后面接一个3×3的卷积层,再接两个1×1的卷积层(原文称这两个卷积层的关系为sibling),其中一个是用来给softmax层进行分类,另一个用于给候选区域精确定位。
到这里其实有个疑问没有说清楚,也算是理解这篇文章的重点,通过CNN得到的feature map怎么可以通过RPN得到与原图对应的候选区域的,换句话说,RPN输出的候选区域和softmax的结构怎么与原图中的区域进行对应的。要解决这个疑问就得先理解anchors的概念。
2. Anchors
[[ -84. -40. 99. 55.] [-176. -88. 191. 103.] [-360. -184. 375. 199.] [ -56. -56. 71. 71.] [-120. -120. 135. 135.] [-248. -248. 263. 263.] [ -36. -80. 51. 95.] [ -80. -168. 95. 183.] [-168. -344. 183. 359.]]
因为提出的候选区域是在原图上的区域,所以要清楚anchors在原图中的位置。假设CNN得到的feature map大小为w×h,那总的anchors个数为9×w×h,9为上述的9种anchors。假设原图大小为W×H,由SPP-net文章详细解读知W=S×w, H=S×h,S为之前所有层的stride size相乘,所以feature map上的点乘以S即为anchors的原点位置,得到所有框的原点位置以及大小就可以得到原图上的anchors区域了。
那RPN的输出跟anchors是什么关系呢,如下图
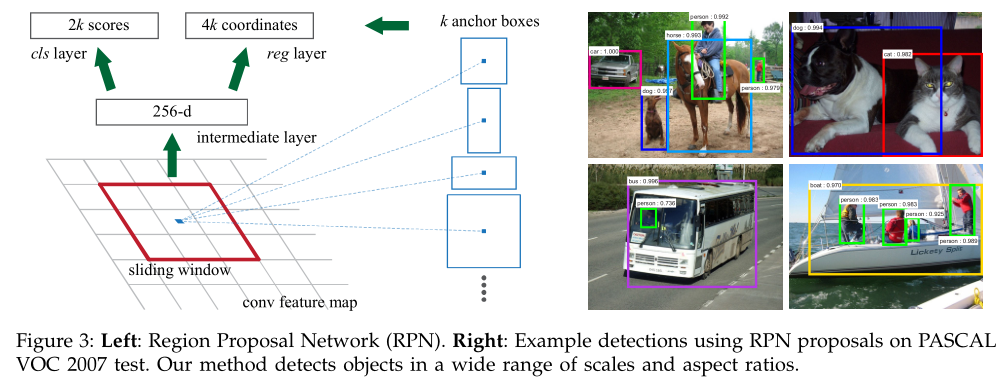
解释一下上面这张图:
1)在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图(feature maps),所以相当于feature map每个点都是256-dimensions
2)在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息),同时256-d不变
3)假设在conv5 feature map中每个点上有k个anchor(原文如上k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates(scores和coordinates为RPN的最终输出)
4)补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(至于什么是合适的anchors接下来RPN的训练会讲)
注意,在tf版本的代码中使用的VGG conv5 num_output=512g,所以是512d,其他类似。
RPN训练中对于正样本文章中给出两种定义。第一,与ground truth box有最大的IoU的anchors作为正样本;第二,与ground truth box的IoU大于0.7的作为正样本。文中采取的是第一种方式。文中定义的负样本为与ground truth box的IoU小于0.3的样本。
训练RPN的loss函数定义如下:
$L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{*} L_{r e g}\left(t_{i}, t_{i}^{*}\right)$
看过Fast R-CNN文章详细解读文章的会发现,这部分的loss函数和Fast R-CNN一样,除了正负样本的定义不一样,其他表示时一样的。
RPN最终目的是得到候选区域,但在目标检测的最终目的是为了得到最终的物体的位置和相应的概率,这部分功能由Fast R-CNN做的。因为RPN和Fast R-CNN都会要求利用CNN网络提取特征,所以文章的做法是使RPN和Fast R-CNN共享同一个CNN部分。
Faster R-CNN的训练方法主要分为两个,目的都是使得RPN和Fast R-CNN共享CNN部分,如下图所示

一个是迭代的,先训练RPN,然后使用得到的候选区域训练Fast R-CNN,之后再使用得到的Fast R-CNN中的CNN去初始化RPN的CNN再次训练RPN(这里不更新CNN,仅更新RPN特有的层),最后再次训练Fast R-CNN(这里不更新CNN,仅更新Fast R-CNN特有的层)。
[3] https://web.cs.hacettepe.edu.tr/~aykut/classes/spring2016/bil722/slides/w05-FasterR-CNN.pdf
[4] https://zhuanlan.zhihu.com/p/31426458

 浙公网安备 33010602011771号
浙公网安备 33010602011771号