
Python如何查看网站的robots协议
在官网后缀添加robots.txt 网站的根路径/robots.txt

User-agent: * Disallow: /?* Disallow: /pop/*.html Disallow: /pinpai/*.html?* User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow: / User-agent: WochachaSpider Disallow: /
第一行*表示所有的,也就是说,对于所有的网络爬虫,它都定义为User-agent
意思就是说对于所有的网络爬虫,都应该遵守这个协议。
第二行什么意思呢?disallow表示不允许,?后面是*,表示?后面所有的东西,也就是说,它不允许任何爬虫访问任何以?开头的路径。
第三行表示任何爬虫都不允许访问pop/开头的路径。
第四行同理,符合这类的路径也不允许访问。
后面的又写了四个爬虫,EtaoSpider等等
他们被禁止的是根目录。这四种爬虫不允许爬取京东的任何资源。
也就是说这四种爬虫被京东定义为恶意爬虫,非法的获取过京东的资源,所以京东不允许这四类爬虫获取京东的任何资源了。
对于不遵守robots协议的爬虫,可能会存在法律风险。
不是所有网站都有robots协议,比如一些网站就没有robots协议,它就默认为所有网络爬虫都可以无限制的去爬取这个网站。
import requests def getHTTPXML(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "产生异常" if __name__ == "__main__": url = "https://www.taobao.com/robots.txt" print(getHTTPXML(url))
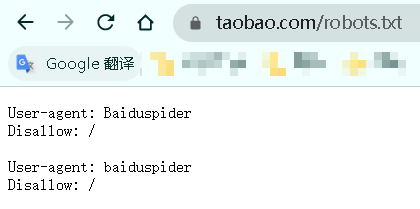
淘宝


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗